CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
Subjects: cs.CV
1.DataComp: In search of the next generation of multimodal datasets

标题:DataComp:寻找下一代多模态数据集
作者:Samir Yitzhak Gadre, Gabriel Ilharco, Alex Fang, Jonathan Hayase, Georgios Smyrnis, Thao Nguyen, Ryan Marten, Mitchell Wortsman
文章链接:https://arxiv.org/abs/2304.14108
项目代码:https://github.com/mlfoundations/datacomp


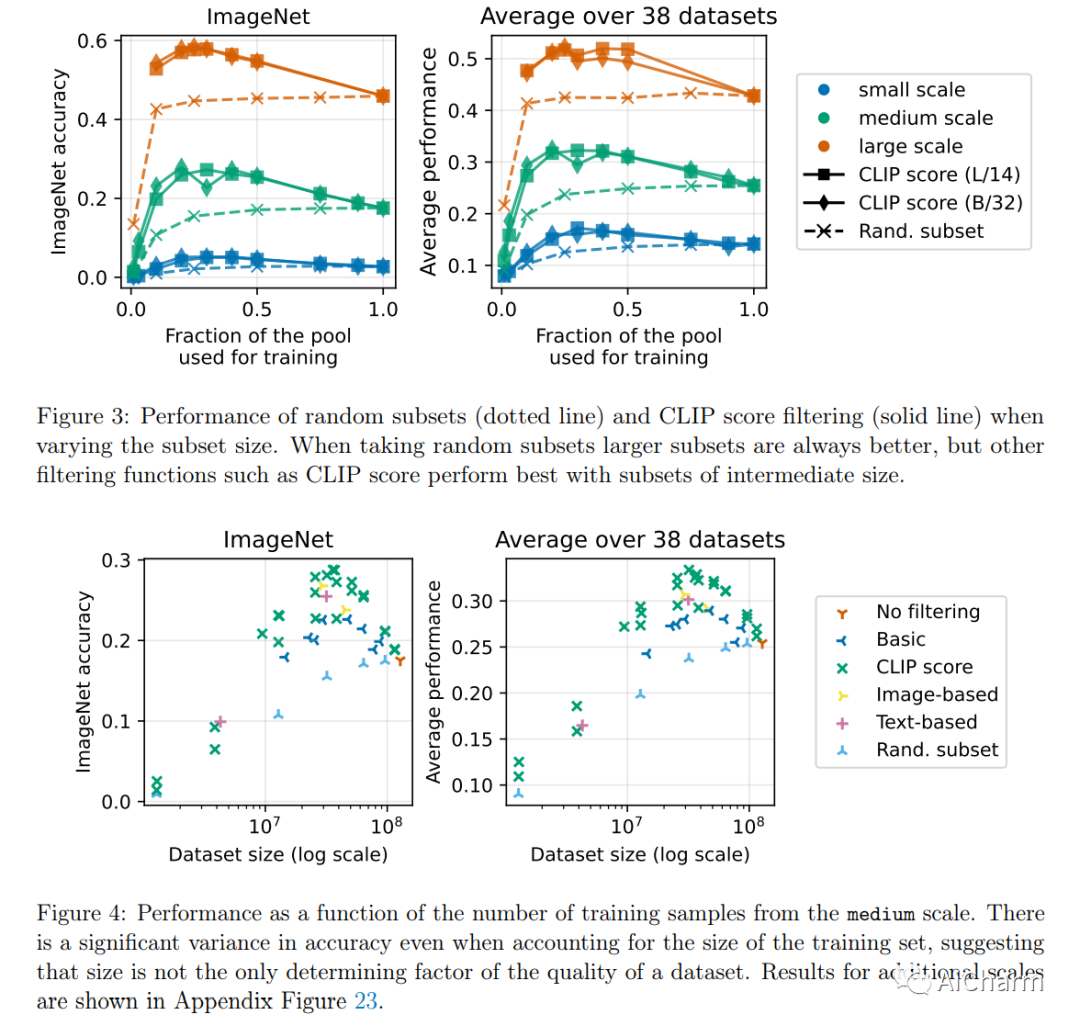
摘要:
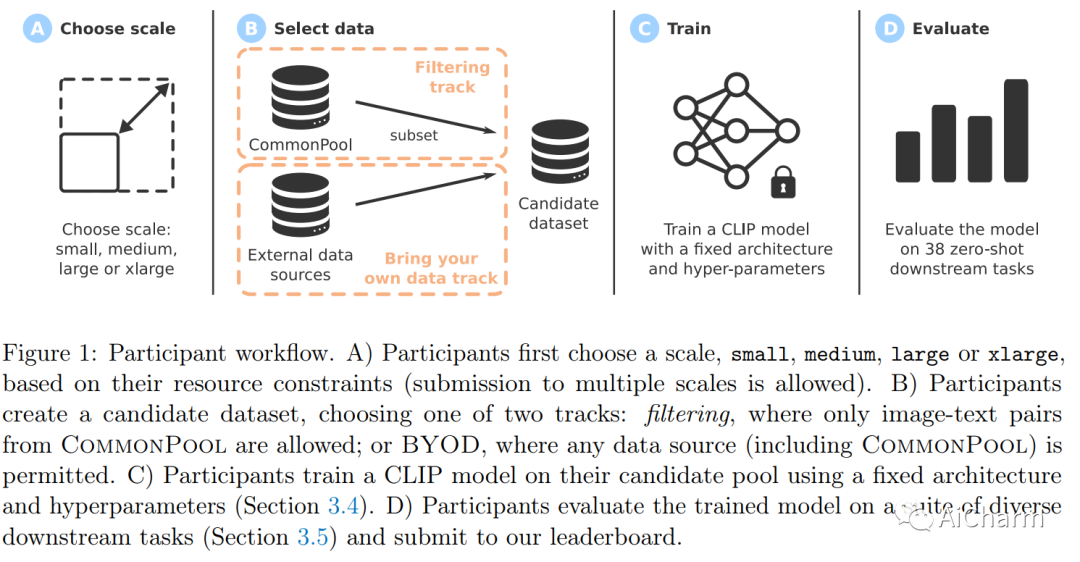
大型多模态数据集在最近的突破中发挥了重要作用,例如 CLIP、Stable Diffusion 和 GPT-4。同时,数据集很少受到与模型架构或训练算法相同的研究关注。为了解决机器学习生态系统中的这一缺点,我们引入了 DataComp,这是一种基准,其中训练代码是固定的,研究人员通过提出新的训练集来进行创新。我们为数据集实验提供了一个测试平台,该实验以来自 Common Crawl 的 12.8B 图像文本对的新候选池为中心。我们基准测试的参与者设计新的过滤技术或管理新的数据源,然后通过运行我们标准化的 CLIP 训练代码并在 38 个下游测试集上进行测试来评估他们的新数据集。我们的基准测试由多个尺度组成,具有四个候选池大小和相关的计算预算,范围从训练期间看到的 12.8M 到 12.8B 个样本。这种多尺度设计有助于研究尺度趋势,并使具有不同资源的研究人员可以访问基准。我们的基线实验表明,DataComp 工作流是改进多模态数据集的一种很有前途的方法。我们介绍了 DataComp-1B,这是一个通过对 12.8B 候选池应用简单过滤算法创建的数据集。由此产生的 1.4B 子集使 CLIP ViT-L/14 能够在 ImageNet 上从头开始训练到 79.2% 的零样本准确率。我们新的 ViT-L/14 模型比在 LAION-2B 上训练的更大的 ViT-g/14 高出 0.7 个百分点,同时需要的训练计算减少 9 倍。我们的表现也比 OpenAI 的 CLIP ViT-L/14 高出 3.7 个百分点,它是使用与我们的模型相同的计算预算进行训练的。这些收益突出了通过精心策划训练集来提高模型性能的潜力。我们将 DataComp-1B 视为第一步,并希望 DataComp 为下一代多模式数据集铺平道路。
2.Text-to-Audio Generation using Instruction-Tuned LLM and Latent Diffusion Model

标题:使用指令调整的 LLM 和潜在扩散模型生成文本到音频
作者:Deepanway Ghosal, Navonil Majumder, Ambuj Mehrish, Soujanya Poria
文章链接:https://arxiv.org/abs/2304.13731
项目代码:https://github.com/declare-lab/tango

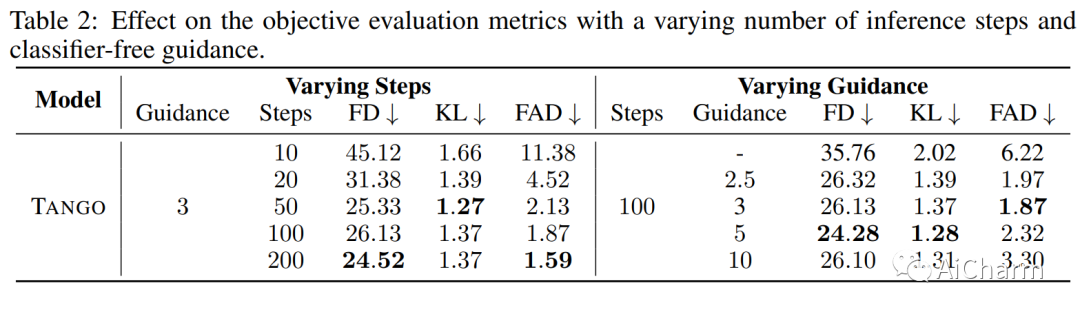
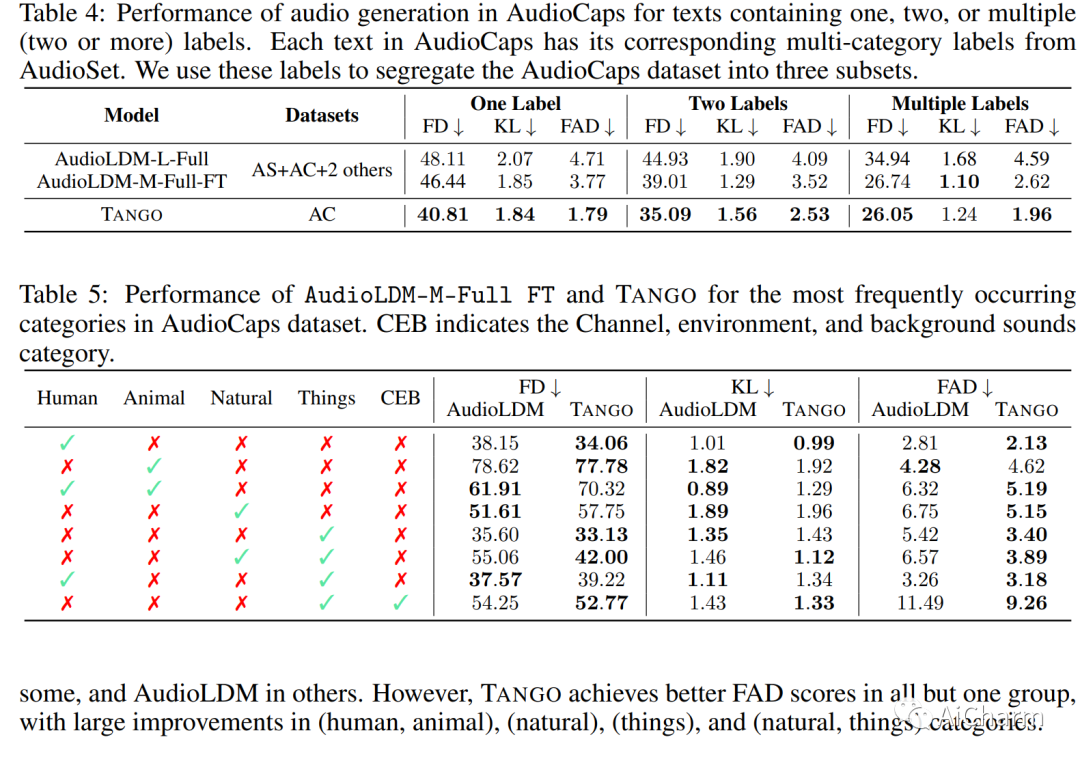
摘要:
最近大型语言模型 (LLM) 的巨大规模允许许多有趣的特性,例如基于指令和思想链的微调,这在许多自然语言处理中显着提高了零样本和少样本性能(NLP) 任务。受这些成功的启发,我们采用这种指令调优的 LLM Flan-T5 作为文本编码器,用于文本到音频 (TTA) 生成——目标是根据文本描述生成音频的任务。TTA 的先前工作要么预训练联合文本音频编码器,要么使用非指令调优模型,例如 T5。因此,尽管在小 63 倍的数据集上训练 LDM 并保持文本编码器冻结。这种改进也可能归因于采用基于音频压力水平的混音来增强训练集,而之前的方法采用随机混音。
3.ChatVideo: A Tracklet-centric Multimodal and Versatile Video Understanding System

标题:ChatVideo:以 Tracklet 为中心的多模态多功能视频理解系统
作者:Junke Wang, Dongdong Chen, Chong Luo, Xiyang Dai, Lu Yuan, Zuxuan Wu, Yu-Gang Jiang
文章链接:https://arxiv.org/abs/2304.14407
项目代码:https://www.wangjunke.info/ChatVideo/
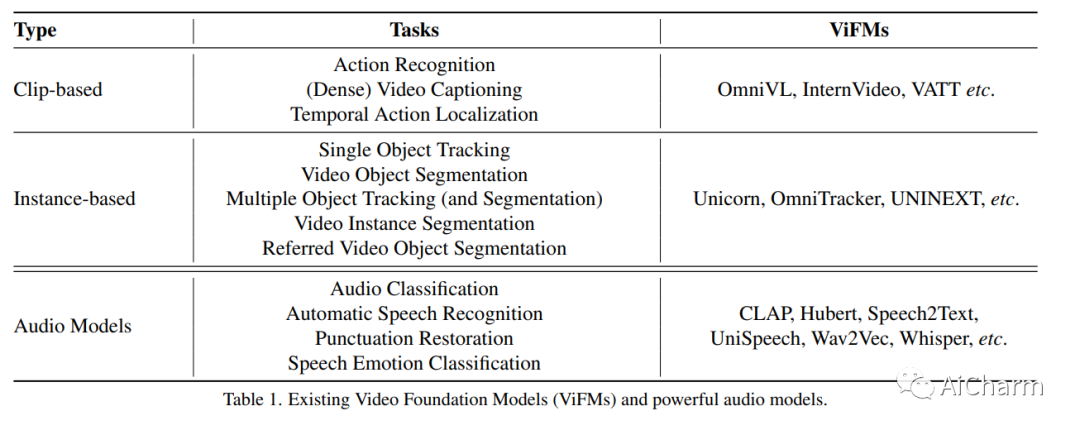
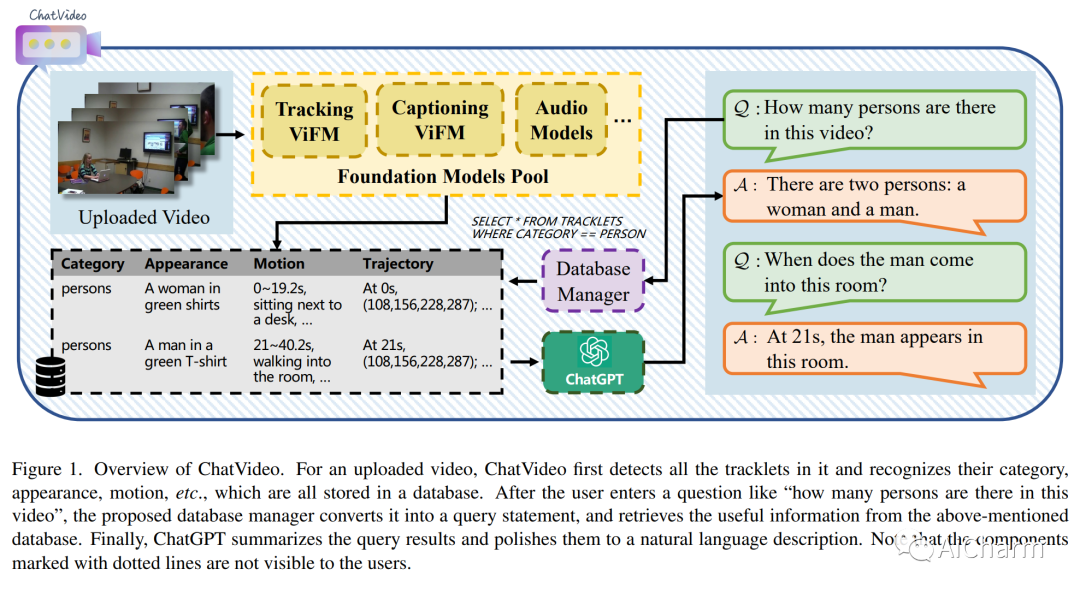
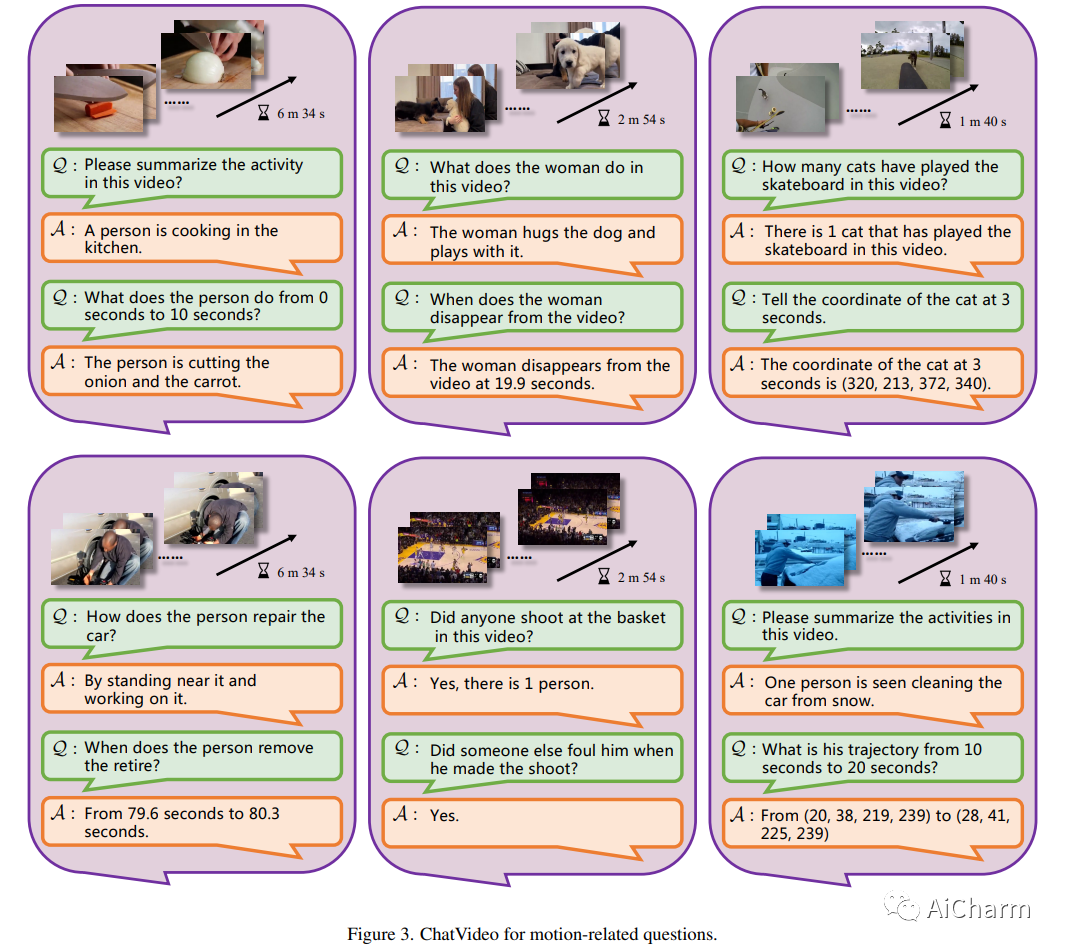
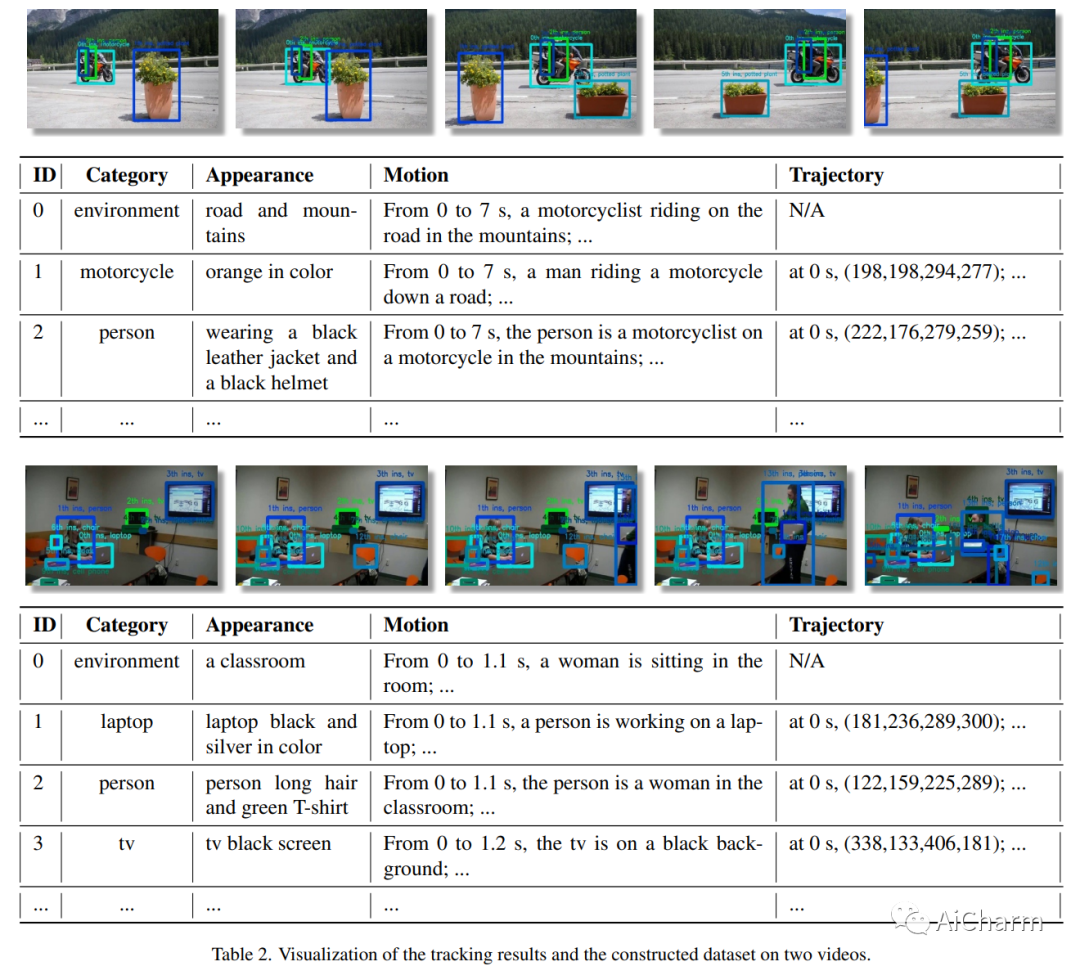
摘要:
现有的深度视频模型受限于特定任务、固定的输入输出空间和较差的泛化能力,难以在真实场景中部署。在本文中,我们提出了我们对多模态和多功能视频理解的愿景,并提出了一个原型系统 \system。我们的系统建立在以 tracklet 为中心的范例之上,它将 tracklet 视为基本视频单元,并使用各种视频基础模型 (ViFM) 来注释它们的属性,例如外观、运动等。所有检测到的轨迹都存储在数据库中,并通过数据库管理器与用户交互。我们对不同类型的野外视频进行了广泛的案例研究,证明了我们的方法在回答各种视频相关问题方面的有效性。
更多Ai资讯:公主号AiCharm