Leetcode
- Leetcode -405.数字转换为十六进制数
- Leetcode - 409.最长回文串
Leetcode -405.数字转换为十六进制数
题目:给定一个整数,编写一个算法将这个数转换为十六进制数。对于负整数,我们通常使用 补码运算 方法。
注意 :
十六进制中所有字母(a - f)都必须是小写。
十六进制字符串中不能包含多余的前导零。如果要转化的数为0,那么以单个字符’0’来表示;对于其他情况,十六进制字符串中的第一个字符将不会是0字符。 给定的数确保在32位有符号整数范围内。
不能使用任何由库提供的将数字直接转换或格式化为十六进制的方法。
示例 1:
输入 :
26
输出 :
“1a”
示例 2:
输入 :
-1
输出 :
“ffffffff”
我们的思路是将这个数num的二进制转换成十六进制,num的二进制中,每四位就会转换为十六进制的一位数,所以每次我们用num按位与上0xf,即是15,因为15的二进制形式为 1111 ,按位与上0xf就能得到num二进制的后四位,然后将按位与得到的数进行判断处理,放入数组中;最后将num向右移四位,进行下一次循环;
以26为例:

向右移四位后按位与如下图,所以最终结果为 " 1a ";
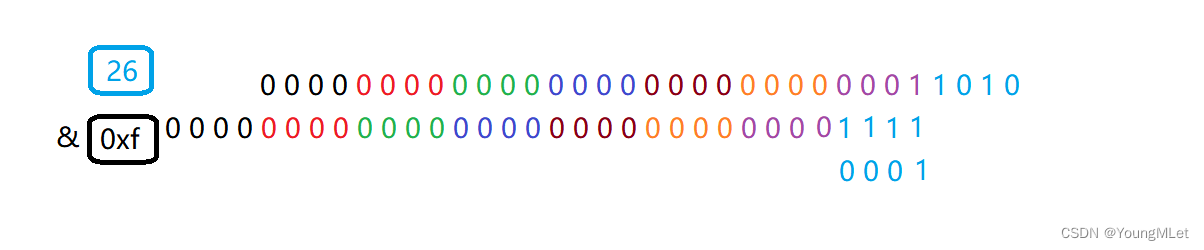
char* toHex(int num)
{
//开辟9个char空间,因为整型的十六进制最长的长度为8,加上'\0'就9个
char* nums = (char*)malloc(sizeof(char) * 9);
//对于负数,将它强转成无符号数处理
unsigned newnum = (unsigned int)num;
int i = 0;
//如果数组中只有一个0,就在0后面加上'\0',返回数组
if (num == 0)
{
nums[0] = '0';
nums[1] = '\0';
return nums;
}
//当这个数转成无符号数之后不为0,进入循环
while (newnum > 0)
{
//0xf即为15,15的二进制为 1111
//即将这个数按位与上 1111 ,得到这个数的二进制的后四位,存放到flag中
//因为二进制表示的数,每四位二进制就表示一为十六进制的数
int flag = newnum & 0xf;
//如果小于10,就将它转成字符放到数组中,然后i++
if (flag < 10)
{
nums[i++] = flag + '0';
}
//如果大于等于10,先减去10,再加上字符a,使它转换成十六进制的字符
else
{
nums[i++] = flag - 10 + 'a';
}
//然后将这个数向右移四位,判断下一个十六进制的位数
newnum >>= 4;
}
//循环结束后在i处加上'\0'
nums[i] = '\0';
//最后将数组逆置,因为放进去的时候是这个数二进制的尾部开始放,所以读的时候要倒过来读
int left = 0, right = i - 1;
while (left < right)
{
char tmp = nums[left];
nums[left++] = nums[right];
nums[right--] = tmp;
}
return nums;
}
Leetcode - 409.最长回文串
题目:给定一个包含大写字母和小写字母的字符串 s ,返回 通过这些字母构造成的 最长的回文串 。
在构造过程中,请注意 区分大小写 。比如 “Aa” 不能当做一个回文字符串。
示例 1:
输入:s = “abccccdd”
输出 : 7
解释 :
我们可以构造的最长的回文串是"dccaccd", 它的长度是 7。
示例 2 :
输入 : s = “a”
输出 : 1
示例 3:
输入 : s = “aaaaaccc”
输出 : 7
我们的思路是,用一个hash数组记录字符串中字符出现的次数,count记录回文串的长度,只要某个字符出现了两次,就证明可以构成回文串,就将2加到count中,然后再将这个字符的位置置0;对于奇数个的字符,对于上述的处理之后,现在hash数组中的位置对应的数值只能是0或者1,0的话不管,1的话只保留一个,因为在回文串中是对称的,只能有一个奇数的字符;具体的代码和注释如下:
int longestPalindrome(char* s)
{
//创建一个hash数组,长度为58,因为字符串中含有大小写字母的字符,从'A'到'z'一共就58个字符
int hash[58] = { 0 };
//count统计最长的回文串
int count = 0;
//遍历字符串,以字符作为hash数组的下标记录这个字符出现的次数,每次出现就++
//当这个位置出现了两次,证明可以构成回文串,就使count加2,并将这个位置置0
for (int i = 0; i < strlen(s); i++)
{
hash[s[i] - 'A']++;
if (hash[s[i] - 'A'] > 1)
{
count += 2;
hash[s[i] - 'A'] = 0;
}
}
//遍历以'A'到'z'作为hash数组的下标,现在它们的位置的数值只能是0或者1
//奇数个的字符在回文串中只能出现一个,所以其他奇数个的字符都不算入count中,用count += hash[i] - 1处理,本来hash[i]是1,减去1后就是0
int flag = 0;
for (int i = 0; i < 58; i++)
{
if (hash[i] % 2)
{
flag = 1;
count += hash[i] - 1;
}
}
//最后留下来的奇数个的字符算入count中
if (flag)
count++;
//最后返回回文串长度
return count;
}