Linux_红帽8学习笔记分享_8(文件系统管理FS Management)
文章目录
- Linux_红帽8学习笔记分享_8(文件系统管理FS Management)
- 1.操作系统的两种启动模式: Legacy BIOS和UEFI
- 1.1 Legacy BIOS
- 1.2 UEFI
- 2.磁盘分区表的两种类型: MBR和GPT
- 2.1 MBR(Master Boot Record,主引导记录或主引导扇区)
- 2.2 GPT(GUID Partition Table,全局唯一标识磁盘分区表)
- 3.Linux下的磁盘分区及其表示方法
- 3.1磁盘的表示方法
- 3.2分区的表示方法
- 3.3 MBR类型中的主分区,扩展分区和逻辑分区
- 4.为虚拟机添加一块磁盘的方法(需要提前关闭虚拟机)
- 5.使用新磁盘的整体流程
- 6.分区的步骤:
- 6.1分区命令的使用技巧
- 6.1.1输入m
- 6.1.2输入p
- 6.1.3输入n
- 6.1.4输入d
- 6.1.5输入l
- 6.1.6输入t
- 6.1.7输入w,q
- 7.更新磁盘分区表的方法
- 8.格式化磁盘分区的方法
- 8.1格式化类型一:格式化为xfs
- 8.2验证方法一
- 8.3验证方法二
- 8.4格式化类型二:格式化为ext4
- 8.5格式化类型三:格式化为vfat
- 8.5格式化类型四:格式化为swap
- 9.挂载
- 9.1通过mount命令实现手动挂载
- 10.使用
- 11.卸载
1.操作系统的两种启动模式: Legacy BIOS和UEFI
1.1 Legacy BIOS
它的全称是Basic Input/Output System即基本输入/输出系统,是比较老的传统的操作系统启动方式,如果笔记本电脑是win7之前的,红帽企业6之前的,那么它采用的启动方式都是BIOS启动方式。它在开机时需要进行自检,启动过程较复杂,时间较长。它无法识别GPT分区表,只能识别MBR分区表。
1.2 UEFI
UEFI是一个全新的操作系统启动方式,它的全称是Unified Extensible Firmware Interface,即统一可扩展固件接口,它直接从预启动的操作环境加载操作系统,启动速度很快。它可以同时识别GPT和MBR。
2.磁盘分区表的两种类型: MBR和GPT
2.1 MBR(Master Boot Record,主引导记录或主引导扇区)
MBR是计算机开机后必须读取的首个扇区(硬盘中扇区的大小一般为512个字节),它在硬盘上的三维地址为(0柱面,O磁头,1扇区)。
本地硬盘启动会读取硬盘的第一个扇区(512 Bytes),存放着主引导记录MBR(Master Boot Record),头446字节的启动加载程序是Bootloader。第二个部分是64字节的磁盘分区表,由于存放每个分区信息需要16个字节, 最多只能有4个主分区。第三部最后2字节的结束标志。它局限在MBR分区方案无法支持超过2TB的磁盘容量,因为MBR分区方案使用4个字节存储分区的总扇区数,512*2的32次方=2TB
注意:MBR分区的两点局限性,它分区的个数最多只能有4个分区,在MBR分区方案无法支持超过2TB的磁盘容量。
2.2 GPT(GUID Partition Table,全局唯一标识磁盘分区表)
是一种更先进的磁盘组织方案,是UEFI启动的磁盘组织方式,GPT有自己的分区表,且在GPT分区表的头部可自定义分区数量的最大值,例如Windows设定的GPT最大分区数量为128个。GPT分区方案中逻辑地址采用64位二进制位表示,可以表示2的64次方个地址。GPT分区方案在磁盘的末端还有一个备份分区表,保证了分区信息不容易丢失。
注意:GPI分区的两个优点,主分区个数突破4个,它能够识别的硬盘的大小远远超过2TB。GPT分区方案在磁盘的末端还有一个备份分区表,保证了分区信息不容易丢失。
3.Linux下的磁盘分区及其表示方法
3.1磁盘的表示方法
/dev/sda是第一块磁盘(Linux识别出来是SCSI回或串口磁盘),其中a表示序号、第几块,所以/dev/sdb是第二块磁盘/dev/sdc是第三块磁盘。
/dev/hda,/dev/hdb,/dev/hdc( Linux识别出来是传统的IDE磁盘)
/dev/vda,/dev/vdb,/dev/vdc,( Linux识别出来是虚拟磁盘)
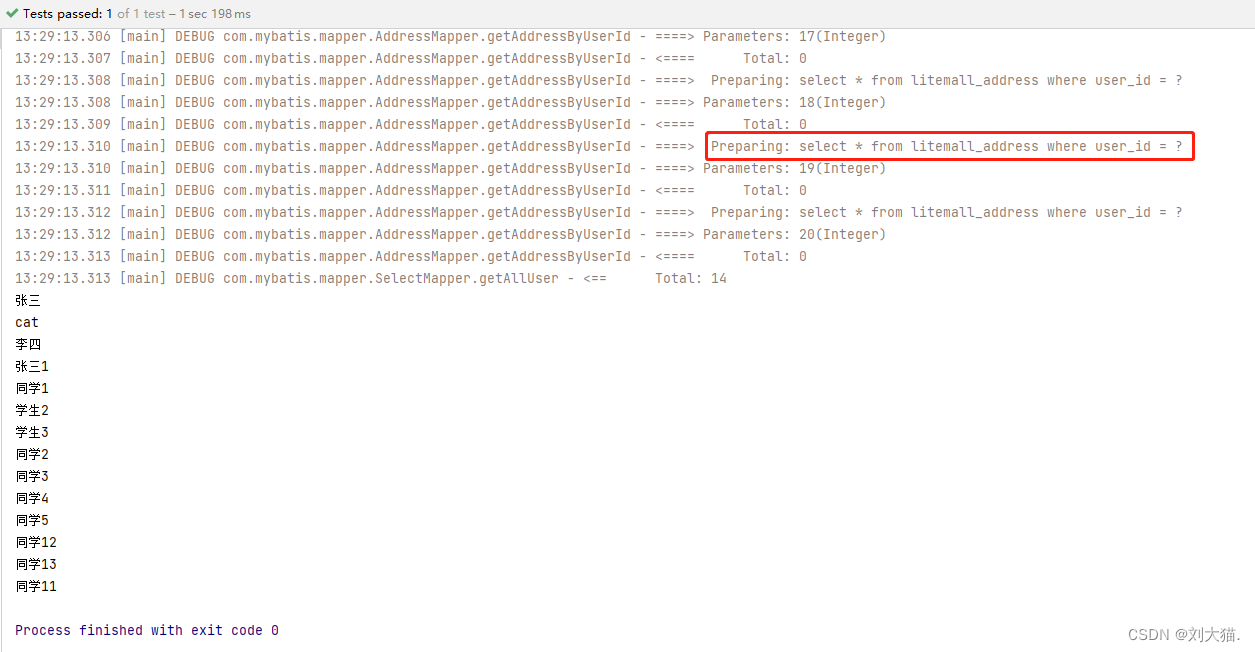
我们使用fdisk –l查看我们foundation0虚拟机上的磁盘信息,如下图所示。


我们使用fdisk –l查看我们servera虚拟机上的磁盘信息,如下图所示。

3.2分区的表示方法
/dev/sda1—第一块磁盘的第一个分区
/dev/sda2—第一块磁盘的第二个分区
/dev/sdb1—第二块磁盘的第一个分区
/dev/hda1—第一块磁盘的第一个分区,/dev/hdc6—第三块磁盘的第六个分区
我们的磁盘分区表如下图所示。

Device表示磁盘分区名,Boot表示该磁盘分区是否为引导分区(如果是引导分区就填写*号)(引导分区是用来引导操作系统的),Start End表示起始扇区的位置和结束扇区的位置,Sectors表示你包含的扇区的个数,Size表示该磁盘分区容量大小,Id表示该磁盘分区的十六进制编码(不同的文件系统类型有不同的16进制编码),Type表示该磁盘分区的文件系统类型。
而其他没有分区表的磁盘,说明它是一块新磁盘,还未划分磁盘分区。
3.3 MBR类型中的主分区,扩展分区和逻辑分区
透明性:他是将计算机系统的一些细节复杂东西封装起来,让使用者通过简单的方法达到他的目的。
MBR分区表中的几个结论: 扩展分区可以理解为是一个特殊的主分区,它是一个容器,其中可以包含多个逻辑分区,扩展分区的大小=各个逻辑份区大小之和+未划分的扩展分区大小,真正能使用的数据分区只能是主分区和逻辑分区,分区个数少于4个时:磁盘的剩余空间=磁盘的总容量已划分出的主分区容量综合;分区个数超过4个时:磁盘的剩余空间=扩展分区-各逻辑分区之和。
4.为虚拟机添加一块磁盘的方法(需要提前关闭虚拟机)
在servera的界面上输入poweroff,去KVM管理器上看一下,确定它被关闭了,如下图所示。

之后我们双击servera虚拟机,点击灯泡按钮,点击VirtIO Disk 1,点击左下角Add Hardware

进入界面后,确定我们要添加的磁盘大小为1G,确定虚拟机类型为VirtIO,再点击右下角的Finish,如下图所示。

点击完分类之后运行servera,我们再在servera的界面中查看它的磁盘,最后一项1GB的vde磁盘就是刚刚添加的磁盘,如下图所示。

5.使用新磁盘的整体流程
分区—更新磁盘分区表—格式化—挂载—使用
6.分区的步骤:
我们发现VDB还没有被划分磁盘,如下图所示。

所以我们用VDB来做划分实验,如下图所示,我们进入了交互式模式。

要记住进入了交互状态后,退格删除按键是ctrl+Backspace
6.1分区命令的使用技巧
6.1.1输入m
在交互模式下,输入m进入帮助手册,展示一个命令清点,如下图所示。

6.1.2输入p
输入p打印现在的磁盘的分区表,如下图所示。

其中Disklabel type表示当前这个磁盘的类型,dos表示现在这个磁盘是MBR磁盘分区表类型的磁盘(没有对磁盘做过任何设置默认是dos),gpt表示现在这个磁盘是GPT磁盘分区表类型的磁盘
6.1.3输入n
输入n创建分区,必须从前往后一个一个创建,之后它会问我们是要创建主分区还是扩展分区(我们创建分区的时候,默认头三个都是创建主分区),如下图所示。

我们输入P,之后提示我们磁盘分区序号,输入1回车,提示我们输入起始位置,我们按照默认的来,直接回车即可,提示我们输入结束位置,我们要创建一个100MB大小的,我们就输入+100M,再回车解创建完成了,如下图所示。

同样我们在创建第2个磁盘分区,大小为200兆,如下图所示。

我们再去创建第3个磁盘分区,大小为300兆,如下图所示。

我们再去创建第4个磁盘分区,大小为400兆,如下图所示。

可是在当我们想创建第5个磁盘分区时,会发现报错情况,如下图所示。

这个原因是因为我们主分区只能做4个,做够4个主分区之后,便不能再做其他分区,接下来我们把第4个主分区删掉,把它设置为扩展分区。
6.1.4输入d
输入d删除现在的磁盘的指导分区,必须从后往前一个一个删除,如下图所示。

在如上图所示,因为分区个数少于4个时:磁盘的剩余空间=磁盘的总容量-已划分出的主分区容量综合,这个时候的磁盘的剩余空间=4.4G。
我们再去创建第4个分区,这个时候我们将剩下的4.4G都给它,我们就在提示输入结束位置的时候,直接回车即可,如下图所示。

接下来我们创建第5个分区,大小为400M,如下图所示。

在创建的时候,它自动将分区定位为逻辑分区,相当于从4号扩展分区里面剥离出来逻辑分区了。此时因为分区个数超过4个时:磁盘的剩余空间=扩展分区-各逻辑分区之和,所以磁盘的剩余空间=4G。
接下来我们创建第6个分区,大小为500M,如下图所示。

此时磁盘的剩余空间=3.5G。
6.1.5输入l
输入m会列出磁盘分区的十六进制编码,如下图所示。

其中83表示Linux文件系统类型,它又分为四种小类型:xfs(表示红帽企业8的文件系统类型)、ext4(表示红帽企业7的文件系统类型)、ext3(表示红帽企业6的文件系统类型)、ext2(表示红帽企业5以及5之前的文件系统类型),在之后我们对83的十六进制编码的分区进行格式化的时候可以格式化成这四种小类型的任何一种,都是可以的。
其中5表示扩展分区。7 表示Windows的HPFS/NTFS。b表示Windows的W95 FAT32。82表示 Linux的交换分区类型的磁盘分区。8e表示 Linux的逻辑卷类型的磁盘分区。
6.1.6输入t
我们使用T可以修改磁盘分区的16进制编码,修改的分区序号不要求按照正逆序顺序修改,我们将1号的十六进制编码修改为Windows的W95 FAT32,如下图所示。

我们将2号的十六进制编码修改为交换分区类型,为如下图所示。

我们将5号的十六进制编码修改为逻辑卷类型,为如下图所示

6.1.7输入w,q
输入w代表写入并退出,如下图所示。

输入q代表直接退出,如下图所示。

7.更新磁盘分区表的方法
我们直接输入partprobe,它的目的是为了让Linux内核重新读取一下底层的磁盘分区表,**注意:这步操作是在fdisk分区之后做的。**如下图所示。

如果提示需要重启才能生效,那么我们就输入reboot即可。
接下来我们输入cat /proc/partitions 来查看即时内存,如下图所示。

发现我们刚刚创建的分区都在,说明这些分区都成功了,更新成功。
8.格式化磁盘分区的方法
8.1格式化类型一:格式化为xfs
我们格式化一下vdb3,如下图所示。

8.2验证方法一
接下来我们验证一下是否格式化成功,如下图所示。

:后跟着UUID则表示格式化完毕。
8.3验证方法二

如上图所示,使用lsblk –fs也可以查看是否格式化成功,上图中的vdb3就格式化成功了。
8.4格式化类型二:格式化为ext4
我们去格式化vdb6,如下图所示,格式化成功。

8.5格式化类型三:格式化为vfat
我们去格式化vdb1,如下图所示,格式化成功。

8.5格式化类型四:格式化为swap
我们去格式化vdb2,如下图所示,格式化成功。

注意:在格式化vfat的时候,如果提示-bash: mkfs.vfat: command not found,我们追根溯源使用yum provides mkfs.vfat或者yum whatprovides mkfs.vfat找一下mkfs.vfat依赖于哪个包,然后使用yum -y install dosfstools.x86_64命令把这个dosfstools包安装一下。
9.挂载
9.1通过mount命令实现手动挂载
首先我们新建三个目录,查看其关联情况,会发现这三个创建的目标目录并没有某一个原始对象关联,如下图所示。

我们接下来进行挂载,我们把 vdb3挂载到###g1目录上,如下图所示。

也可以加入参数-t 分类文件类型,如下图所示。

我们同样可以把vdb1挂载到###g3上,如下图所示。

如果要查看挂载情况,我们除了可以使用df –Th,还可以使用lsblk –fs,如下图所示

10.使用
我们在相应的目录下创建文件与子目录即可,如下图所示。

11.卸载
我们可以使用umount进行卸载操作,如下图所示。

要注意,当你在使用过程中是不能够进行卸载的,如下图所示。

以上就是本文全部内容,如果它对您有帮助,请您帮我点个赞,这对我真的很重要

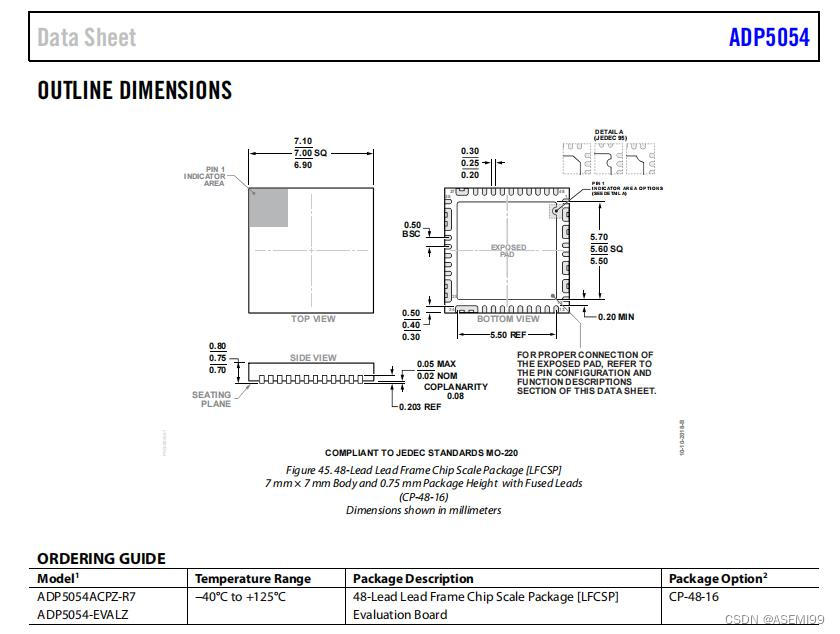
![[2023-DAS x SU战队2023开局之战] crypto-sign1n](https://img-blog.csdnimg.cn/ffaa9d0b9f984ad889432e4da1d052cb.png)