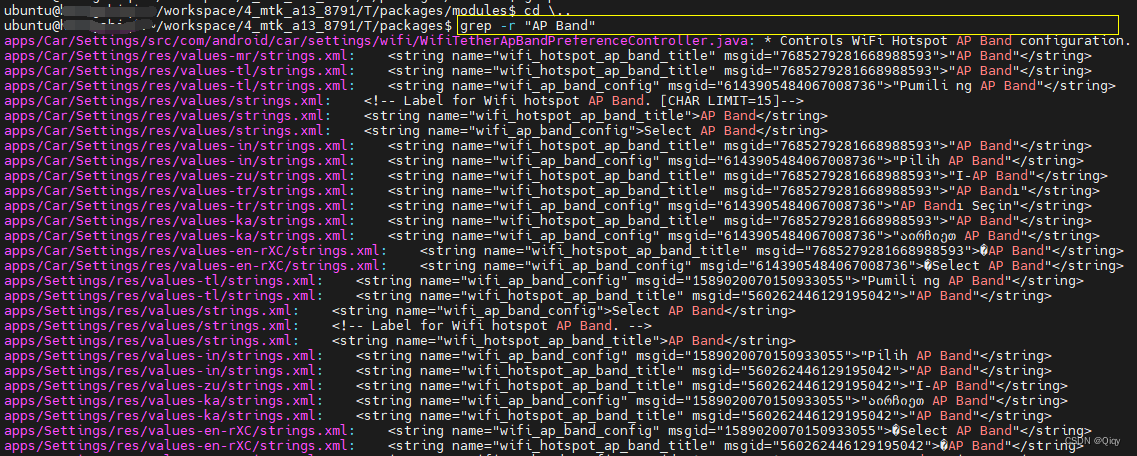
Flink Metrics简介
Flink Metrics是Flink集群运行中的各项指标,包含机器系统指标,比如:CPU、内存、线程、JVM、网络、IO、GC以及任务运行组件(JM、TM、slot、作业、算子)等相关指标。
Flink Metrics包含两大作用:
(1)实时采集监控数据。在Flink的UI界面上,用户可以看到自己提交的任务状态、时延、监控信息等等
(2)对外提供数据手机接口。用户可以将整个Flink集群的监控数据主动上报至第三方监控系统,如:prometheus、Grafana等
一、Flink Metrics Types
Flink一共提供了四种监控指标,分别为:Counter、Gauge、Histogram、Meter。
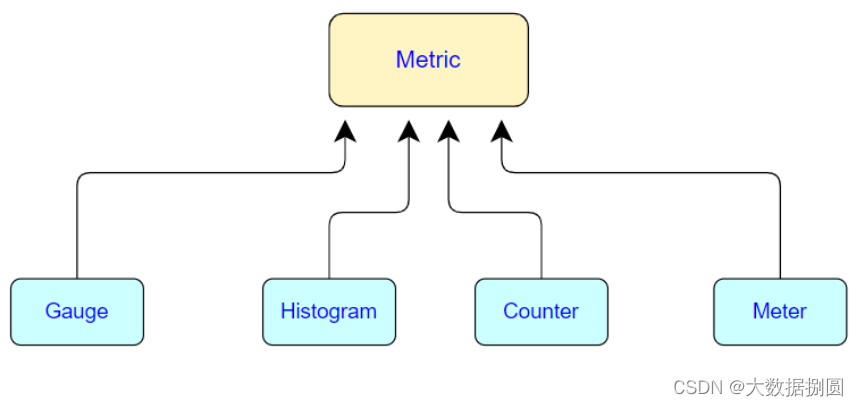
1.Count计数器
统计一个指标的总量。写过MapReduce的开发人员就应该很熟悉Counter,其实含义都是一样的,就是对一个计数器进行累加,即对于多条数据和多兆数据一直往上加的过程。其中Flink算子的接收记录总数(numRecordsIn)和发送记录总数(numRecordsOut)属于Counter类型。
使用方式:可以通过调用counter(String name)来创建和注册MetricGroup

2.Gauge指标瞬时值
Gauge是最简单的Metrics,它反映一个指标的瞬时值。比如要看现在TaskManager的JVM heap内存用了多少,就可以每次实时的暴露一个Gauge,Gauge当前的值就是heap使用的量。
使用前首先创建一个实现org.apache.flink.metrics.Gauge接口的类。返回值的类型没有限制。你可以通过在MetricGroup上调用Gauge。

3.Meter平均值
用来记录一个指标在某个时间段内的平均值。Flink中的指标有Task算子中的numRecordsInPerSecond,记录此Task或者算子每秒接收的记录数。
使用方式:通过markEvent()方法注册事件的发生。通过markEvent(long n)方法注册同时发生的多个事件。

4.Histogram直方图
Histogram用于统计一些数据的分布,比如说Quantile、Mean、StdDev、Max、Min等,其中最重要一个是统计算子的延迟。此项指标会记录数据处理的延迟信息,对任务监控起到很重要的作用。
使用方式:通过调用histogram(String name, Histogram histogram)来注册一个MetricGroup。

二、Scope(域)
每个Metric都会分配一个标识符和一组键值对,用来报告Metric。
标识符基于3个组成部分:注册时的用户定义名称、可选的用户定义Scope和系统提供的Scope。例如:如果A.B是系统Scope,C.D是用户Scope,E是名称,那么标识符将是A.B.C.D.E。
可以通过在conf/flink-conf.yaml中设置metrics.scope.delimiter键来配置用于标识符的分隔符(默认值:.)
Flink的指标体系按树形结构划分,域相当于树上的顶点分支,表示指标大的分类。每个指标都会分配一个标识符,该标识符将基于3个组件进行汇报:
(1)注册指标时用户提供的名称
(2)可选的用户自定义域
(3)系统提供的域
例如,如果A.B是系统域,C.D是用户域,E是名称,那么指标的标识符将是A.B.C.D.E。
举例说明:以算子的指标组结构为例,其默认为:
.taskmanager.<tm_id>.<job_name>.<operator_name>.<subtask_index>
算子的输出记录数指标为:
hlinkui.taskmanager.1234.wordcount.flatmap.0.numRecordsIn
三、metrics运行机制
在生产环境下,为保证对Flink集群和作业的运行状态进行监控,Flink提供两种集成方式:
(1)主动方式MetricReport
Flink Metric通过在conf/flink-conf.yaml中配置一个或者一些reporters,将指标暴露给一个外部系统。这些reporters将在每个job和task manager启动时被实例化。
(2)被动方式RestAPI
通过提供Rest接口,被动接收外部系统调用,可以返回集群、组件、作业、Task、算子的状态。RestAPI实现类是WebMonitorEndpoint