目录
环境变量过多或者参数值过长时,为什么提交作业失败?
为什么Shell作业状态和相关的YARN Application状态不一致?
创建作业和执行计划的区别是什么?
如何查看作业运行记录?
如何在OSS上查看日志?
读写MaxCompute时,报错java.lang.RuntimeException.Parse response failed: ‘…’
多个ConsumerID消费同一个Topic时为什么TPS不一致?
E-MapReduce中是否可以查看Worker上的作业日志?
为什么Spark Streaming作业已经结束,但是E-MapReduce控制台显示作业还处于“运行中”状态?
报错“Error: Could not find or load main class”
如何在MR作业中使用本地共享库?
如何在MR或Spark作业中指定OSS数据源文件路径?
如何查看E-MapReduce服务的日志?
报错"No space left on device"
访问OSS或LogService时报错ConnectTimeoutException或ConnectionException
如何清理已经完成作业的日志数据?
为什么AppMaster调度启动Task的时间过长?
E-MapReduce是否提供实时计算的功能?
作业参数传递至脚本文件该如何处理?
如何使用阿里云E-MapReduce HDFS的Balancer功能以及参数调优?
如果E-MapReduce控制台上没有自定义配置选项,该如何处理?
使用数据开发提交的作业一直处于Submit状态,该如何处理?
作业长时间处于等待状态,如何处理?
Map端是否读取了小文件?
Reduce Task任务耗时,是否出现了数据倾斜?
如何预估Hive作业并发量的上限值?
为什么Hive创建的外部表没有数据?
在哪里可以查看Spark历史作业?
是否支持Standalone模式提交Spark作业?
如何减少Spark2命令行工具的日志输出?
如何使用Spark3的小文件合并功能?
如何处理SparkSQL数据倾斜?
如何指定PySpark使用Python 3版本?
临时生效方式
永久生效方式
为什么Spark Streaming作业运行一段时间后无故结束?
为什么Spark Streaming作业已经结束,但是E-MapReduce控制台显示作业状态还处于“运行中”?
导入RDS数据至EMR时,时间字段显示延迟8小时如何处理?
环境变量过多或者参数值过长时,为什么提交作业失败?
- 问题现象:提交作业时,报错信息如下。
Message: FailedReason:FailedReason:[[JOB_ENGINE][JOB_ENGINE_START_JOB_FAILED/ERR-200001] Failed to execute job: [FJ-xxxx]]. - 问题分析:数据开发系统存在单项目变量总数和长度限制。如果环境变量过多或者参数值过长(大于1024)都会导致提交作业失败。
- 解决方案:如果确实存在大量需要编辑的变量,请分项目添加变量,确保单项目变量数和长度较小。
为什么Shell作业状态和相关的YARN Application状态不一致?
- 问题现象:在数据开发页面编辑Shell作业类型,任意编写一个会拉起YARN Application的作业,例如hive -f xxx.sql。在YARN Application未结束前,单击作业终止按钮,此时数据开发作业状态为KILLED,但YARN Application仍然会继续运行,直到自然结束。
- 问题分析:终止Shell作业时会给Shell进程发送终止信号,如果YARN Application的驱动程序和Shell进程不存在父子进程关系,则YARN Application不会随Shell进程的终止而终止。例如Hive、sqoop、spark-submit(cluster模式)均存在这种情况。
- 解决方案:建议不要使用Shell类型作业开发Hive、Spark或Sqoop等作业,尽可能使用原生作业类型(例如,Hive、Spark或Sqoop等类型)进行开发,这些作业类型存在一定的关联机制,可以确保作业驱动程序本身和YARN Application状态的一致性。
创建作业和执行计划的区别是什么?
- 创建作业
在E-MapReduce中创建作业,实际只是创建了作业如何运行的配置,该配置中包括该作业要运行的JAR包、数据的输入输出地址以及一些运行参数。该配置创建好后,给它命名即定义了一个作业。
- 执行计划执行计划是将作业与集群关联起来的一个纽带:
- 可以把多个作业组合成一个作业序列。
- 可以为作业准备一个运行集群(或者自动创建出一个临时集群或者关联一个已存在的集群)。
- 可以为这个作业序列设置周期执行计划,并在完成任务后自动释放集群。
- 可以在执行记录列表上查看每一次执行的情况与对应的日志。
如何查看作业运行记录?
提交作业后,您可以通过数据开发控制台或YARN UI方式查看作业运行记录。
- 数据开发控制台方式
该方式适用于通过控制台方式创建并提交作业的场景。
- 作业运行后,您可以在日志页签中查看作业运行的日志。
- 单击运行记录页签,可以查看作业实例的运行情况。

- 单击目标运行记录右侧的详情,跳转到运维中心,可以查看作业实例信息、提交日志和YARN容器列表。
- YARN UI方式
该方式适用于通过控制台方式和命令行方式创建并提交作业的场景。
- 开启8443端口,详情请参见设置安全组访问。
- 在目标集群的集群管理页签下,单击左侧菜单访问链接与端口。
- 单击YARN UI后面的链接。
在使用Knox账号访问YARN UI页面时,需要Knox账号的用户名和密码,详情请参见管理用户。
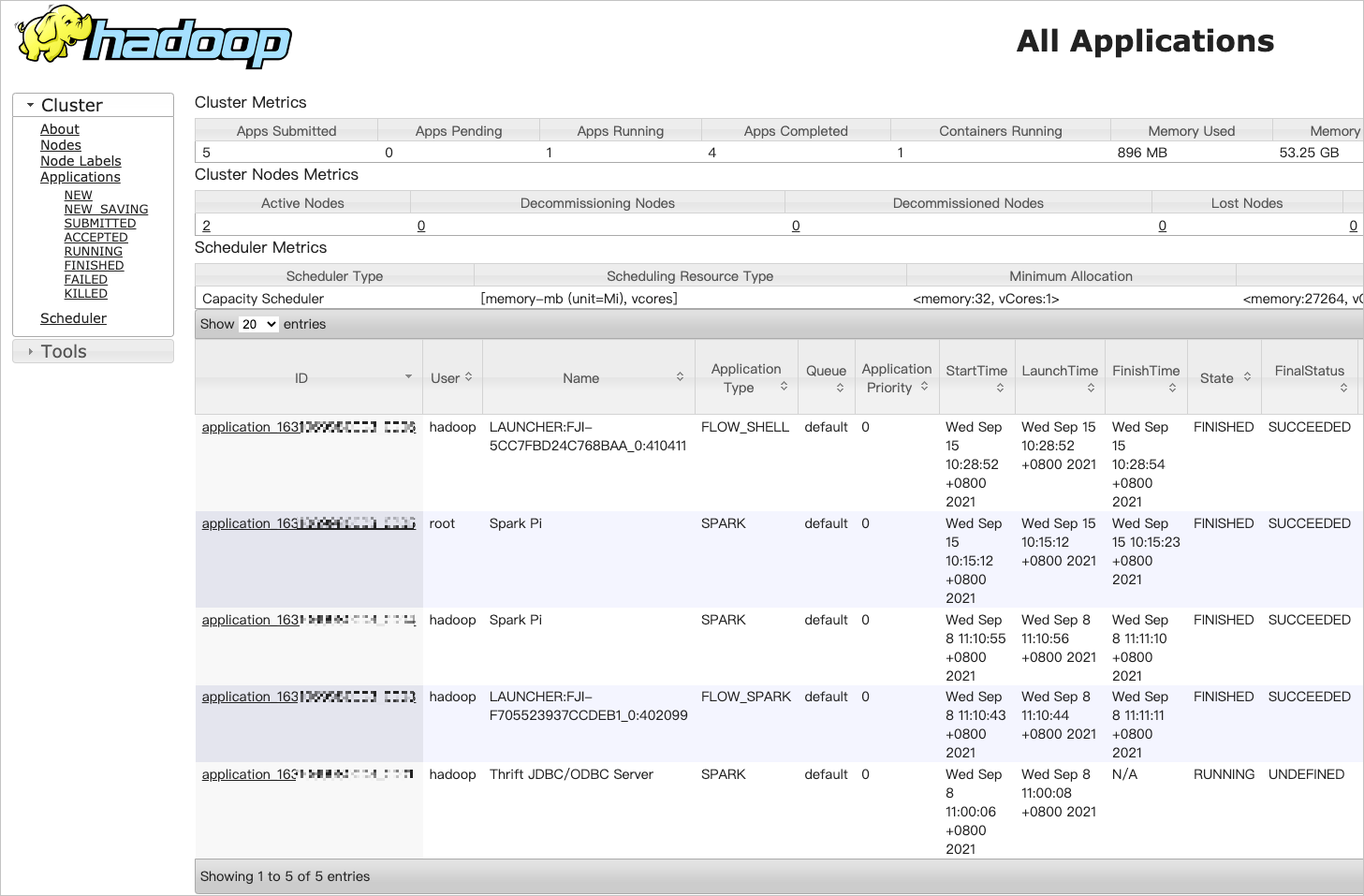
- 在Hadoop控制台,单击目标作业的ID,可以查看作业运行的详情。
如何在OSS上查看日志?
- 在E-MapReduce数据开发的页面,找到对应的工作流实例,单击运行记录。
- 在运行记录区域,单击待查看工作流实例所在行的详情,在作业实例信息页面查看执行集群ID。
- 在日志保存目录OSS://mybucket/emr/spark下,查找执行集群ID目录。
- 在OSS://mybucket/emr/spark/clusterID/jobs目录下会按照作业的执行ID存放多个目录,每个目录下存放了这个作业的运行日志文件。
读写MaxCompute时,报错java.lang.RuntimeException.Parse response failed: ‘<!DOCTYPE html>…’
- 问题分析:可能是MaxCompute Tunnel Endpoint填写错误。
- 解决方法:输入正确的MaxCompute Tunnel Endpoint,详情请参见Endpoint。
多个ConsumerID消费同一个Topic时为什么TPS不一致?
有可能这个Topic在公测或其他环境创建过,导致某些Consumer组消费数据不一致。
E-MapReduce中是否可以查看Worker上的作业日志?
可以。您可以通过YARN UI的方式查看Worker上的日志,详细信息请参见YARN UI方式。
为什么Spark Streaming作业已经结束,但是E-MapReduce控制台显示作业还处于“运行中”状态?
- 问题分析:Spark Streaming作业的运行模式是Yarn-Client。
- 解决方法:因为E-MapReduce对Yarn-Client模式的Spark Streaming作业的状态监控存在问题,所以请修改为Yarn-Cluster模式。
报错“Error: Could not find or load main class”
检查作业配置中作业JAR包的路径协议头是否是ossref,如果不是请改为ossref。
如何在MR作业中使用本地共享库?
您可以在 阿里云E-MapReduce控制台,YARN服务的 配置页面,修改 mapred-site.xml页签如下参数。
<property>
<name>mapred.child.java.opts</name>
<value>-Xmx1024m -Djava.library.path=/usr/local/share/</value>
</property>
<property>
<name>mapreduce.admin.user.env</name>
<value>LD_LIBRARY_PATH=$HADOOP_COMMON_HOME/lib/native:/usr/local/lib</value>
</property>如何在MR或Spark作业中指定OSS数据源文件路径?
您可以在作业中指定输入输出数据源时使用OSS URL: oss://[accessKeyId:accessKeySecret@]bucket[.endpoint]/object/path形式,类似hdfs://。
您在操作OSS数据时:
- (建议)E-MapReduce提供了MetaService服务,支持免AccessKey访问OSS数据,直接写oss://bucket/object/path。
- (不建议)可以将AccessKey ID,AccessKey Secret以及Endpoint配置到Configuration(Spark作业是SparkConf,MR作业是Configuration)中,也可以在URI中直接指定AccessKey ID、AccessKey Secret以及Endpoint。详情请参见开发准备。
如何查看E-MapReduce服务的日志?
登录Master节点在/mnt/disk1/log中查看对应服务的日志。
报错"No space left on device"
- 问题分析:
- Master或Worker节点空间不足,导致作业失败。
- 磁盘空间满导致本地Hive元数据库(MySQL Server)异常,Hive Metastore连接报错。
- 解决方法:清理Master节点磁盘空间、系统盘的空间以及HDFS空间。
访问OSS或LogService时报错ConnectTimeoutException或ConnectionException
- 问题分析:OSS Endpoint需要配置为公网地址,但EMR Worker节点并无公网IP,所以无法访问。
- 解决方法:
- 修改OSS Endpoint地址修为内网地址。
- 使用EMR metaservice功能,不指定Endpoint。
select * from tbl limit 10可以正常运行,但是执行Hive SQL: select count(1) from tbl时报错。修改OSS Endpoint地址为内网地址。alter table tbl set location "oss://bucket.oss-cn-hangzhou-internal.aliyuncs.com/xxx" alter table tbl partition (pt = 'xxxx-xx-xx') set location "oss://bucket.oss-cn-hangzhou-internal.aliyuncs.com/xxx"
如何清理已经完成作业的日志数据?
- 问题描述:集群的HDFS容量被写满,发现/spark-history下有大量的数据。
- 解决方法:
- 在Spark配置页面的服务配置区域,查看是否有spark_history_fs_cleaner_enabled参数:
- 是:修改参数值为true,可以周期性清理已经完成的作业的日志数据。
- 否:在spark-defaults页签下,单击自定义配置,新增spark_history_fs_cleaner_enabled为true。
- 单击右上角的操作 > 重启 All Components
- 在执行集群操作对话框,输入执行原因,单击确定。
- 在弹出的确认对话框中,单击确定。
- 在Spark配置页面的服务配置区域,查看是否有spark_history_fs_cleaner_enabled参数:
为什么AppMaster调度启动Task的时间过长?
- 问题分析:作业Task数目过多或Spark Executor数目过多,导致AppMaster调度启动Task的时间过长,单个Task运行时间较短,作业调度的Overhead较大。
- 解决方法:
- 减少Task数目,使用CombinedInputFormat。
- 提高前序作业产出数据的Block Size(dfs.blocksize)。
- 提高mapreduce.input.fileinputformat.split.maxsize。
- 对于Spark作业,在阿里云E-MapReduce控制台,Spark服务的配置页面,调节spark.executor.instances减少Executor数目,或者调节spark.default.parallelism降低并发数。
E-MapReduce是否提供实时计算的功能?
E-MapReduce提供Spark Streaming、Storm和Flink三种实时计算服务。
作业参数传递至脚本文件该如何处理?
在Hive作业中,您可以通过 -hivevar选项,传递作业中配置的参数至脚本中。
- 准备脚本文件。脚本文件中引用变量的方式为
${varname}(例如${rating})。本示例中脚本的相关信息如下:- 脚本名称:hivesql.hive
- 脚本的OSS路径:oss://bucket_name/path/to/hivesql.hive
- 脚本内容
use default; drop table demo; create table demo (userid int, username string, rating int); insert into demo values(100,"john",3),(200,"tom",4); select * from demo where rating=${rating};
- 进入数据开发页面。
- 通过阿里云账号登录阿里云E-MapReduce控制台。
- 在顶部菜单栏处,根据实际情况选择地域和资源组。
- 单击上方的数据开发页签。
- 单击待编辑项目所在行的作业编辑。
- 新建Hive类型作业。
- 在页面左侧,在需要操作的文件夹上单击右键,选择新建作业。
- 在新建作业对话框中,输入作业名称和作业描述,从作业类型下拉列表中选择Hive作业类型。
- 单击确定。
- 编辑作业内容。
- 在基础设置页面,设置参数的Key和Value,其中Key为脚本文件中的变量名,必须与脚本一致,例如rating。
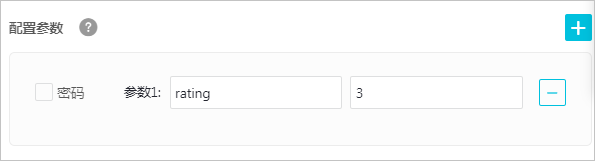
- 作业内容中必须添加
-hivevar选项,以便传递作业中配置的参数值至脚本变量。-hivevar rating=${rating} -f ossref://bucket_name/path/to/hivesql.hive
- 在基础设置页面,设置参数的Key和Value,其中Key为脚本文件中的变量名,必须与脚本一致,例如rating。
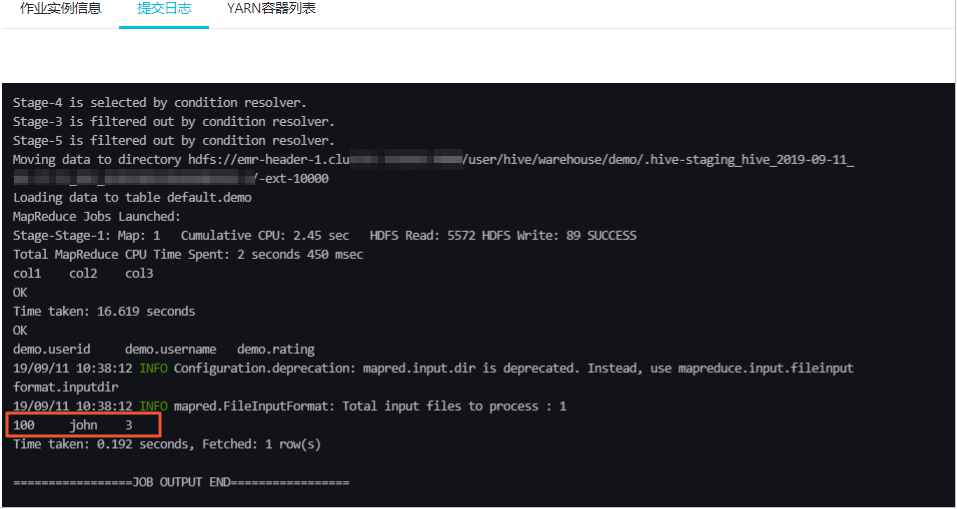
- 执行作业。
本示例执行结果如下。
如何使用阿里云E-MapReduce HDFS的Balancer功能以及参数调优?
- 登录待配置集群任意节点。
- 执行以下命令,切换到hdfs用户并执行Balancer参数。
su hdfs /usr/lib/hadoop-current/sbin/start-balancer.sh -threshold 10 - 执行以下命令,查看Balancer运行情况:
- 方式一
less /var/log/hadoop-hdfs/hadoop-hdfs-balancer-emr-header-xx.cluster-xxx.log - 方式二
tailf /var/log/hadoop-hdfs/hadoop-hdfs-balancer-emr-header-xx.cluster-xxx.log
说明 当提示信息包含
Balancer的主要参数。Successfully字样时,表示执行成功。
DataNode的主要参数。参数 描述 Threshold 默认值为10%,表示上下浮动10%。
当集群总使用率较高时,需要调小Threshold,避免阈值过高。
当集群新增节点较多时,您可以适当增加Threshold,使数据从高使用率节点移向低使用率节点。
dfs.datanode.balance.max.concurrent.moves 默认值为5。
指定DataNode节点并发移动的最大个数。通常考虑和磁盘数匹配,推荐在DataNode端设置为
例如:一个DataNode有28块盘,在Balancer端设置为28,DataNode端设置为4 * 磁盘数作为上限,可以使用Balancer的值进行调节。28*4。具体使用时根据集群负载适当调整。在负载较低时,增加concurrent数;在负载较高时,减少concurrent数。说明 DataNode端需要重启来刷新配置。
dfs.balancer.dispatcherThreads Balancer在移动Block之前,每次迭代时查询出一个Block列表,分发给Mover线程使用。 说明 dispatcherThreads是该分发线程的个数,默认为200。
dfs.balancer.rpc.per.sec 默认值为20,即每秒发送的rpc数量为20。 因为分发线程调用大量getBlocks的rpc查询,所以为了避免NameNode由于分发线程压力过大,需要控制分发线程rpc的发送速度。
例如,您可以在负载高的集群调整参数值,减小10或者5,对整体移动进度不会产生特别大的影响。
dfs.balancer.getBlocks.size Balancer会在移动Block前,每次迭代时查询出一个Block列表,给Mover线程使用,默认Block列表中Block的大小为2GB。因为getBlocks过程会对RPC进行加锁,所以您可以根据NameNode压力进行调整。 dfs.balancer.moverThreads 默认值为1000。 Balancer处理移动Block的线程数,每个Block移动时会使用一个线程。
dfs.namenode.balancer.request.standby 默认值为false。 Balancer是否在Standby NameNode上查询要移动的Block。因为此类查询会对NameNode加锁,导致写文件时间较长,所以HA集群开启后只会在Standby NameNode上进行查询。
dfs.balancer.getBlocks.min-block-size Balancer查询需要移动的参数时,对于较小Block(默认10 MB)移动效率较低,可以通过此参数过滤较小的Block,增加查询效率。 dfs.balancer.max-iteration-time 默认值为1200000,单位毫秒。 Balancer一次迭代的最长时间,超过后将进入下一次迭代。
dfs.balancer.block-move.timeout 默认值为0,单位毫秒。 Balancer在移动Block时,会出现由于个别数据块没有完成而导致迭代较长的情况,您可以通过此参数对移动长尾进行控制。
参数 描述 dfs.datanode.balance.bandwidthPerSec 指定DataNode用于Balancer的带宽,通常推荐设置为100 MB/s,您也可以通过dfsadmin -setBalancerBandwidth 参数进行适当调整,无需重启DataNode。
例如,在负载低时,增加Balancer的带宽。在负载高时,减少Balancer的带宽。
dfs.datanode.balance.max.concurrent.moves 指定DataNode上同时用于Balancer待移动Block的最大线程个数。 - 方式一
如果E-MapReduce控制台上没有自定义配置选项,该如何处理?
- 登录集群的Master节点,详情请参见登录集群。
- 进入配置模板的目录。
cd /var/lib/ecm-agent/cache/ecm/service/HUE/4.4.0.3.1/package/templates/
本示例以
HUE为例:HUE表示服务的目录。4.4.0.3.1为Hue的版本。hue.ini为配置文件。
- 执行以下命令,添加您需要的配置。
vim hue.ini当配置项已存在时,您可以根据时间情况修改参数值。
- 在E-MapReduce控制台,重启服务以生效配置。
使用数据开发提交的作业一直处于Submit状态,该如何处理?
出现此问题,通常是因为EMRFLOW中部分组件状态错误,您需要在控制台重启状态错误的组件。
- 进入EMRFLOW页面。
- 进入任意服务页面,修改访问链接后的服务名为EMRFLOW。

说明 本示例是先进入HDFS服务页面。
- 单击部署拓扑页签。
- 进入任意服务页面,修改访问链接后的服务名为EMRFLOW。
- 启动组件。
- 在部署拓扑页签,单击组件处于STOPPED状态操作列的启动。
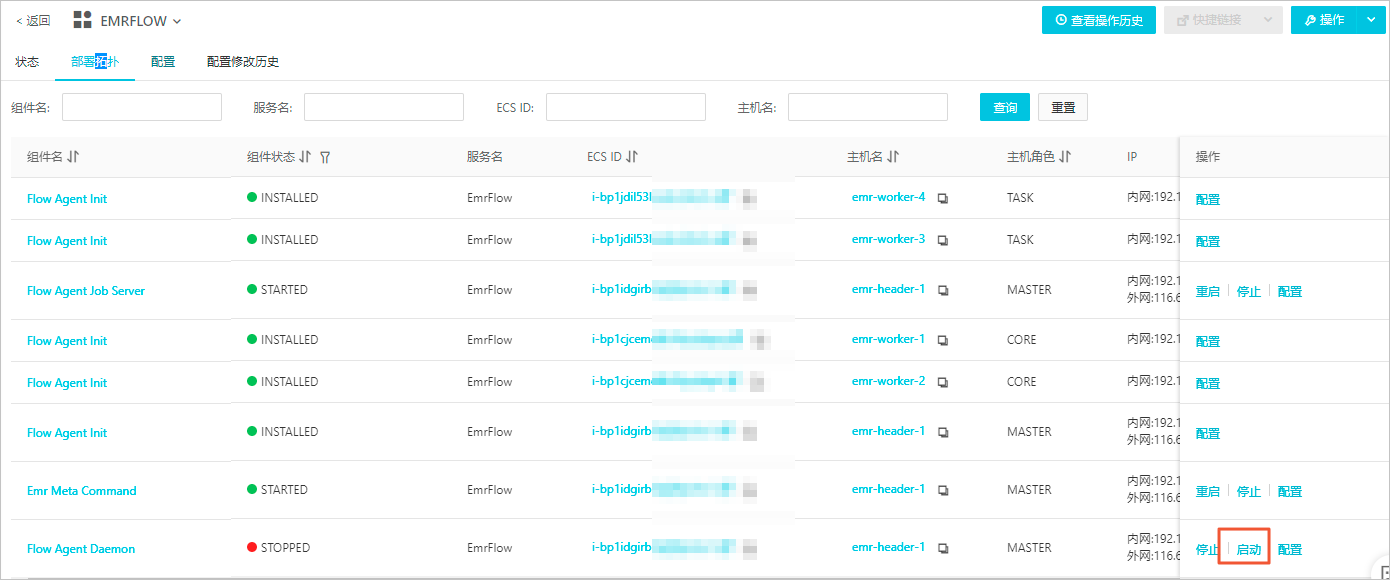
- 在执行集群操作对话中,输入执行原因,单击确定。
- 在确认对话中,单击确定。
- 在部署拓扑页签,单击组件处于STOPPED状态操作列的启动。
- 查看日志信息,检查组件是否启动。
- 单击上方的查看操作历史。
- 在操作历史对话框中,单击操作类型列的Start EMRFLOW FlowAgentDaemon。

- 单击主机名列的emr-header-1。

- 单击任务名列的START_FlowAgentDaemon_ON_emr-header-1。

- 当任务日志区域,提示如下图所示时表示组件启动成功。
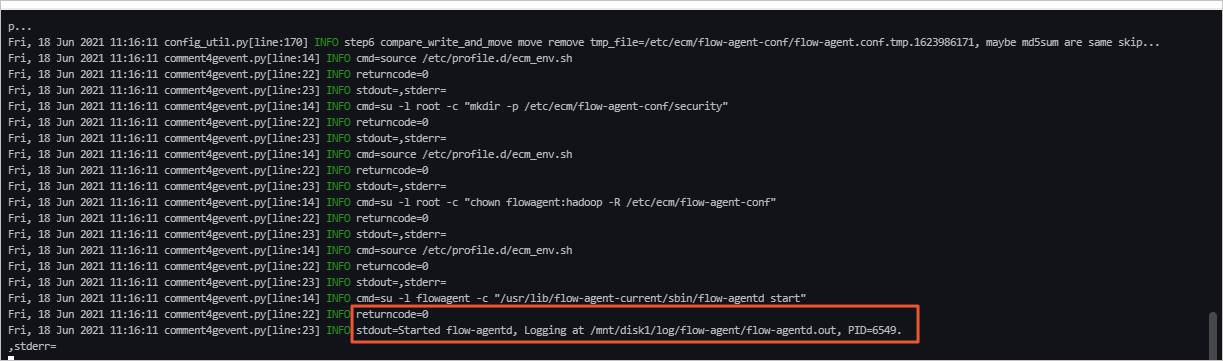
说明 组件启动后,如果还有报错,请根据日志信息排查并处理。如果报错信息提示权限问题,您可以先通过SSH方式登录集群,执行命令
sudo chown flowagent:hadoop /mnt/disk1/log/flow-agent/*处理,然后按照上述步骤重新操作以重启状态错误的组件。
作业长时间处于等待状态,如何处理?
您可以通过以下步骤定位问题:
- 在EMR控制台的访问链接与端口页面,单击YARN UI所在行的链接。
- 单击Application ID。
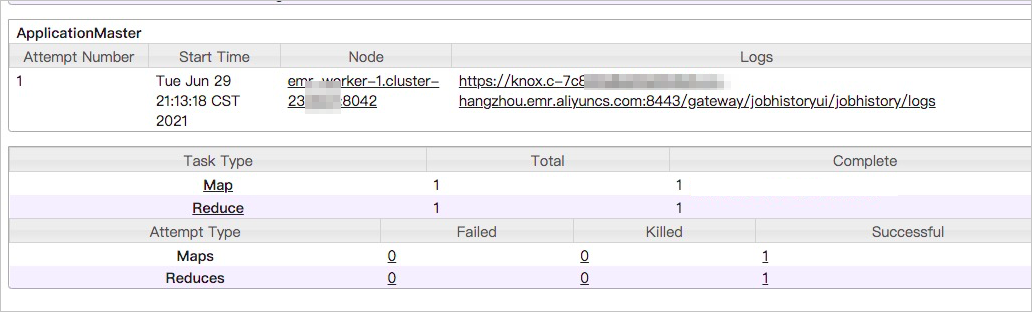
- 单击Tracking URL的链接。
可以看到有多个作业处于等待状态。
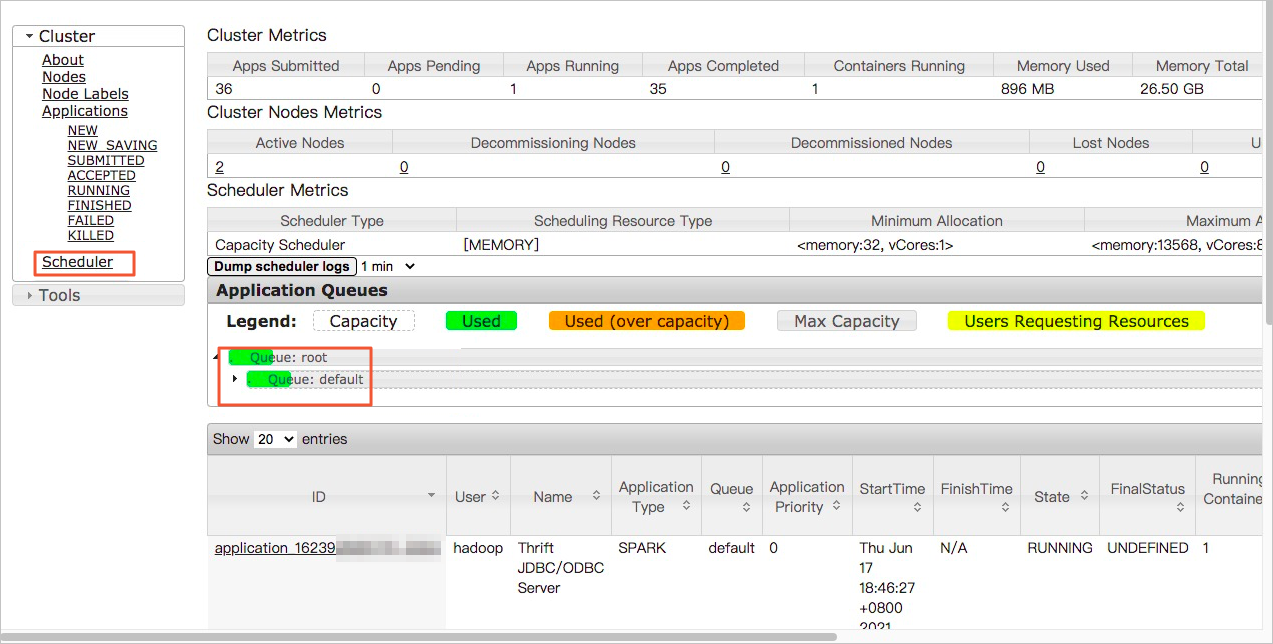
- 在左侧导航中,单击Scheduler。
即可进入队列,您可以看一下当前队列的繁忙程度,来分析是因为队列中没有空闲资源,还是当前任务确实比较耗时。如果是队列资源紧张,您可以考虑切换到空闲队列,否则需要优化代码。
Map端是否读取了小文件?
您可以通过以下步骤定位问题:
- 在EMR控制台的访问链接与端口页面,单击YARN UI所在行的链接。
- 单击Application ID。
进入Map Task的详情页面,可以看到每个Map Task读取的数据量,如下图所示,读取的数据量是2个字节记录。如果大部分的Map Task读取的文件量都比较小,就需要考虑小文件合并。
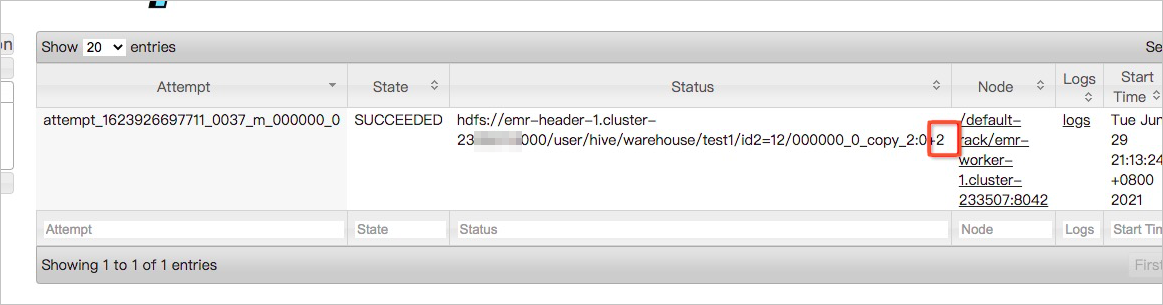
您也可以通过查看Map Task的Log,获取更多的信息。
Reduce Task任务耗时,是否出现了数据倾斜?
您可以通过以下步骤定位问题:
- 在EMR控制台的访问链接与端口页面,单击YARN UI所在行的链接。
- 单击Application ID。
- 在Reduce Task列表页面,按照完成时间逆序排序,找出Top耗时的Reduce Task任务。

- 单击Task的Name链接。
- 在Task详情页面,单击左侧的Counters。

查看当前Reduce Task中Reduce Input bytes和Reduce shuffle bytes的信息,如果比其他的Task处理的数据量大很多,则说明出现了倾斜问题。
如何预估Hive作业并发量的上限值?
Hive作业并发量与HiveServer2的内存以及master实例个数有关系。您可以参考以下公式预估Hive作业并发量的上限值。
max_num = master_num * max(5, hive_server2_heapsize/512)上述公式中涉及到的参数信息如下:
- master_num:集群master实例的个数。
- hive_server2_heapsize:hive-env.sh中的配置项,默认值是512 MB。
例如:集群有3个master实例,hive_server2_heapsize配置为4 GB,那么根据上述公式可以预估出Hive作业的并发量上限值为24,即可以同时运行24个脚本。
为什么Hive创建的外部表没有数据?
- 问题描述:创建完外部表后查询没有数据返回。外部表创建语句示例如下。
查询没有数据返回。CREATE EXTERNAL TABLE storage_log(content STRING) PARTITIONED BY (ds STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE LOCATION 'oss://log-12453****/your-logs/airtake/pro/storage';select * from storage_log; - 问题分析:Hive不会自动关联指定Partitions目录。
- 解决方法:
- 需要您手动指定Partitions目录。
alter table storage_log add partition(ds=123); - 查询返回数据。
返回如下数据。select * from storage_log;OK abcd 123 efgh 123
- 需要您手动指定Partitions目录。
在哪里可以查看Spark历史作业?
您可以在EMR控制台目标集群的访问链接与端口页签,单击Spark UI链接,即查看到Spark历史作业运行信息。访问UI详情,请参见访问链接与端口。
是否支持Standalone模式提交Spark作业?
不支持。E-MapReduce支持使用Spark on YARN以及Spark on Kubernetes模式提交作业,不支持Standalone和Mesos模式。
如何减少Spark2命令行工具的日志输出?
EMR DataLake集群选择Spark2服务后,使用spark-sql和spark-shell等命令行工具时默认输出INFO级别日志,如果想减少日志输出,可以修改log4j日志级别。具体操作如下:
- 在运行命令行工具的节点(例如,master节点)新建一个log4j.properties配置文件,也可以从默认配置文件复制,复制命令如下所示。
cp /etc/emr/spark-conf/log4j.properties /new/path/to/log4j.properties - 修改新配置文件的日志级别。
log4j.rootCategory=WARN, console - 修改Spark服务spark-defaults.conf配置文件中的配置项spark.driver.extraJavaOptions,将参数值中的-Dlog4j.configuration=/etc/taihao-apps/spark-conf/log4j.properties替换为-Dlog4j.configuration=file:/new/path/to/log4j.properties。
重要 路径需要添加file:前缀。
如何使用Spark3的小文件合并功能?
您可以通过设置参数spark.sql.adaptive.merge.output.small.files.enabled为true,来自动合并小文件。由于合并后的文件会压缩,如果您觉得合并后的文件太小,可以适当调大参数spark.sql.adaptive.advisoryOutputFileSizeInBytes的值,默认值为256 MB。
如何处理SparkSQL数据倾斜?
- 针对Spark2,处理方式如下:
- 读取表时过滤无关数据,例如null。
- 广播小表(Broadcast)。
select /*+ BROADCAST (table1) */ * from table1 join table2 on table1.id = table2.id - 根据倾斜key,分离倾斜数据。
select * from table1_1 join table2 on table11.id = table2.id union all select /*+ BROADCAST (table1_2) */ * from table1_2 join table2 on table1_2.id = table2.id - 倾斜key已知时,打散数据。
select id, value, concat(id, (rand() * 10000) % 3) as new_id from A select id, value, concat(id, suffix) as new_id from ( select id, value, suffix from B Lateral View explode(array(0, 1, 2)) tmp as suffix) - 倾斜key未知时,打散数据。
select t1.id, t1.id_rand, t2.name from ( select id , case when id = null then concat(‘SkewData_’, cast(rand() as string)) else id end as id_rand from test1 where statis_date = ‘20221130’) t1 left join test2 t2 on t1.id_rand = t2.id
- 针对Spark3,可以在EMR控制台Spark3服务的配置页签,修改spark.sql.adaptive.enabled和spark.sql.adaptive.skewJoin.enabled的参数值为true。
如何指定PySpark使用Python 3版本?
下面内容以可选服务为Spark2,EMR-5.7.0版本的DataLake集群为例,介绍如何指定PySpark使用Python 3版本。
您可以通过以下两种方式修改Python的版本:
临时生效方式
- 通过SSH方式登录集群,详情请参见登录集群。
- 执行以下命令,修改Python的版本。
export PYSPARK_PYTHON=/usr/bin/python3 - 执行以下命令,查看Python的版本。
当返回信息中包含如下信息时,表示已修改Python版本为Python 3。pysparkUsing Python version 3.6.8
永久生效方式
- 通过SSH方式登录集群,详情请参见登录集群。
- 修改配置文件。
- 执行以下命令,打开文件profile。
vi /etc/profile - 按下
i键进入编辑模式。 - 在profile文件末尾添加以下信息,以修改Python的版本。
export PYSPARK_PYTHON=/usr/bin/python3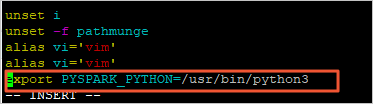
- 按下
Esc键退出编辑模式,输入:wq保存并关闭文件。
- 执行以下命令,打开文件profile。
- 执行以下命令,重新执行刚修改的配置文件,使之立即生效。
source /etc/profile - 执行以下命令,查看Python的版本。
当返回信息中包含如下信息时,表示已修改Python版本为Python 3。pysparkUsing Python version 3.6.8
为什么Spark Streaming作业运行一段时间后无故结束?
- 首先检查Spark版本是否是1.6之前版本,如果是的话更新Spark版本。
Spark 1.6之前版本存在内存泄漏的问题,会导致Container被中止掉。
- 检查自己的代码在内存使用上有没有做好优化。
为什么Spark Streaming作业已经结束,但是E-MapReduce控制台显示作业状态还处于“运行中”?
检查作业提交方式是否为Yarn-Client模式,因为E-MapReduce对Yarn-Client模式的Spark Streaming作业的状态监控存在问题,所以请修改为Yarn-Cluster模式。
导入RDS数据至EMR时,时间字段显示延迟8小时如何处理?
- 问题描述:
- 例如,在云数据库RDS数据源中,数据表Test_Table中包含时间戳(TIMESTAMP)字段。
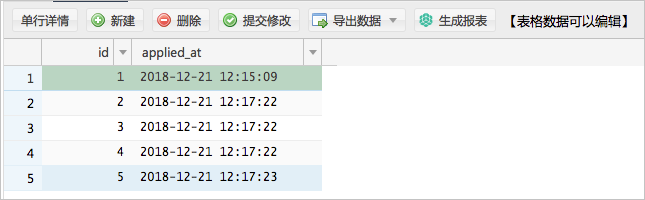
- 您可以执行以下命令,导入Test_Table中的数据至HDFS。
sqoop import \ --connect jdbc:mysql://rm-2ze****341.mysql.rds.aliyuncs.com:3306/s***o_sqoopp_db \ --username s***o \ --password ****** \ --table play_evolutions \ --target-dir /user/hadoop/output \ --delete-target-dir \ --direct \ --split-by id \ --fields-terminated-by '|' \ -m 1 - 查询导入结果。
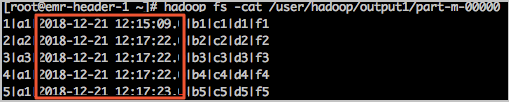
查询结果显示,源数据的时间字段显示延迟8小时。
- 例如,在云数据库RDS数据源中,数据表Test_Table中包含时间戳(TIMESTAMP)字段。
- 解决方法:在使用TIMESTAMP字段导入数据至HDFS时,请删除--direct参数。
sqoop import \ --connect jdbc:mysql://rm-2ze****341.mysql.rds.aliyuncs.com:3306/s***o_sqoopp_db \ --username s***o \ --password ****** \ --table play_evolutions \ --target-dir /user/hadoop/output \ --delete-target-dir \ --split-by id \ --fields-terminated-by '|' \ -m 1查询结果显示正常。