Java8
-
新特性
- 速度更快
- 代码更少(lambda、stream)
- 强大的Stream API
- 便于并行
- 最大化减少空指针异常Optional
-
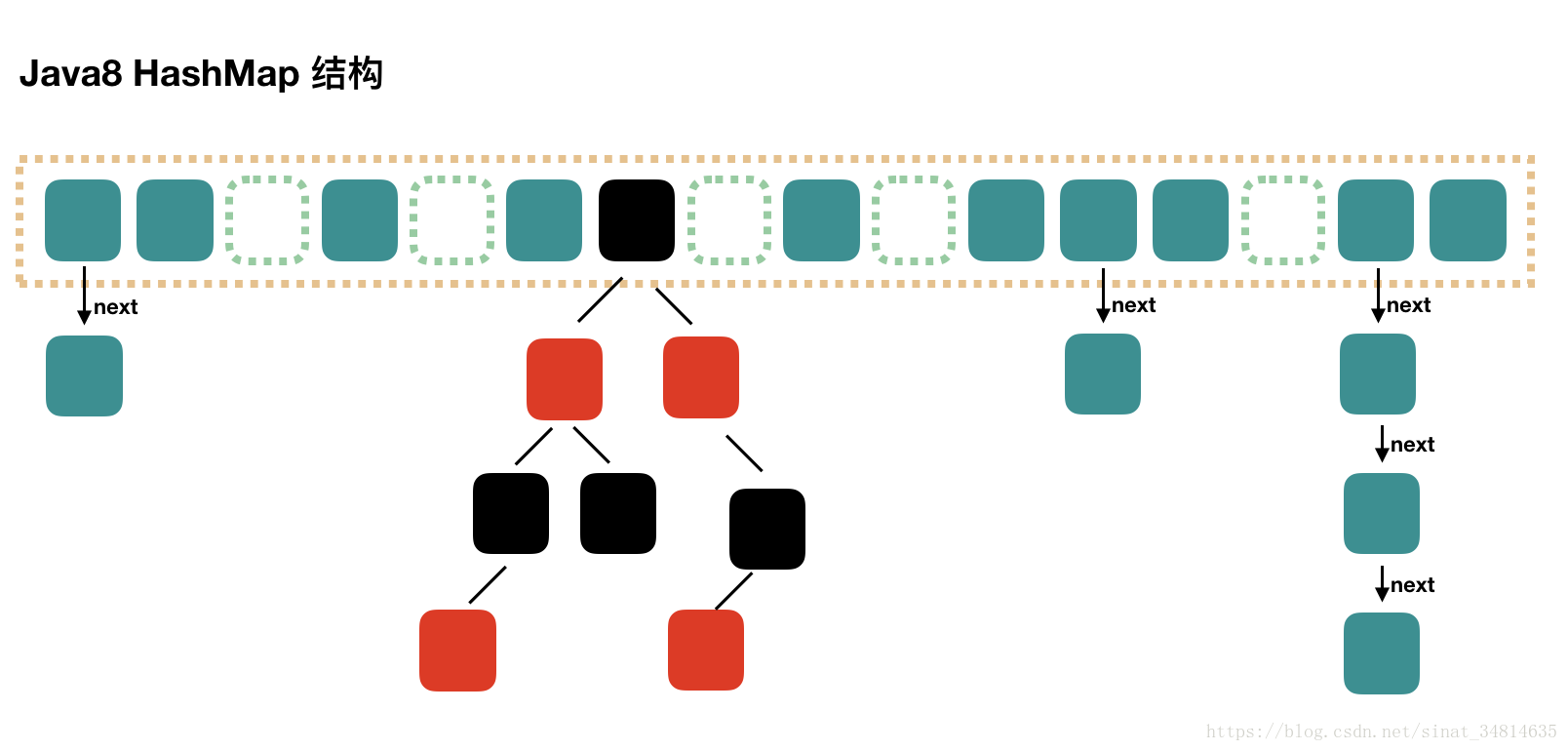
速度更快:对底层数据结构哈希map的优化
- 解释说明hashmap基本原理
- hashmap本质是一个长度16的数组
- 元素的键值对以key:value的形式存储,当key相同时如果value不同则放入同一个key下的链表中,遵循先来的往后放的原则。在jdk1.8则是直接加在链表末尾
- hashcode方法:调用之后产生一个长串的哈希码值,码值再经过运算变成hashmap数组的索引值。
- hashMap在jdk8中底层实现原理与jdk7不同的说明:
- new HashMap(); 底层没有创建一个长度为16的数组。首次调用put()方法时才创建了长度为16的数组
- jdk8底层数组为: Node[] ,而非Entry[]
- jdk7的底层为: 数组+链表 而 jdk8的底层为: 数组+链表+红黑树
- 数组: 用来定位元素的位置
- 链表: 用来存储位置相同的元素
- 红黑树: 可以实现自平衡(旋转)
- 当数组的某一个索引位置上的元素以链表形式存储的数据个数>8,且当前数组元素总数的长度>64时,此时此索引位置上的所有数据改为使用红黑树存储;当在树上进行删除操作,使结点数等于6时,又自动转为链表存储
- 加载因子 :也叫扩容因子,就是当hashmap的实际包含元素达到初始化容量*加载因子时,hashmap会进行扩容,
- 加载因子0.75: 容量与性能的平衡结果,过大会引起更多冲突,过小会浪费太多空间。
- hashset的实现方式也相应改变了。
- ConcurrentHashMap也进行了升级,原本并发级别concurrentLevel = 16,改进后基本不用,使用CAS算法
- CAS无锁算法:一种乐观锁算法,销量更高,底层操作系统支持的算法。
- 解释说明hashmap基本原理
-
速度更快2:底层内存结构也不一样
- 原本:栈、堆、方法区(堆中永久区的一部分,堆永久区主要加载类信息,几乎不会被垃圾回收区回收,只不过回收条件比较苛刻;)
- 堆的永久区:早在1.8之前,除sun版本的jvm其余JVM早已没有永久区,已经将方法区单独剥离出来永久区。
- 堆的永久区:1.8之后,彻底被干掉了,取而代之的是metaSpace元空间,它使用的是物理内存,而不是分配的内存,物理内存有多大,我就可以用多大,而不受限于分配空间。垃圾的清理取决于metaSpaceSize和MaxMetaSpaceSize
- 原本:栈、堆、方法区(堆中永久区的一部分,堆永久区主要加载类信息,几乎不会被垃圾回收区回收,只不过回收条件比较苛刻;)
-
代码更少:Lambda表达式和Stream API
-
便于并行:对于pop、join进行了提升,从串行切换到并行
-
最大化减少空指针异常
- 提供了一个容器类Option,用于封装有可能为空的对象封装到容器类中提供解决方法
-
总之:最大的两个改动:lambda表达式和stream API
Lambda表达式
-
为什么使用lambda
-
lambda是一个匿名函数,是一段可以传递的代码,也可以理解为函数参数。基本形式() -> {}
-
简化了很多无用的代码,例如:相比匿名内部类定义比较器
/** * 匿名内部类 */ @Test public void test1(){ // 匿名内部类实现接口,匿名内部类的实例作为参数 Comparator<Integer> com = new Comparator<Integer>() { @Override public int compare(Integer o1, Integer o2) { return Integer.compare(o1,o2); } }; TreeSet<Integer> ts = new TreeSet<>(com); } /** * lambda表达式 */ @Test public void test2(){ Comparator<Integer> com = (x,y) -> Integer.compare(x,y); // 更简洁可以这样写 TreeSet<Integer> ts = new TreeSet<>(Integer::compare); } -
对于一些重复代码可以使用相应的设计模式进行优化,例如定义比较器接口然后进行分别实现,不过代码量也不小。
-
总之就是一个词,简洁。
-
-
Lambda基本语法
- lambda操作符:"->"也叫箭头操作符。左右侧分别为不同内容:
- 左侧:参数列表
- 右侧:所需执行功能,lambda体
- lambda操作符:"->"也叫箭头操作符。左右侧分别为不同内容:








![[附源码]计算机毕业设计springboot交通事故档案管理系统](https://img-blog.csdnimg.cn/2e4f01715e42480383b0dc4b99d4ef47.png)