TimescaleDB食用手册
一 TimescaleDB介绍
TimescaleDB是一种用于处理时间序列数据的开源时序数据库,它是PostgreSQL的扩展。它可以处理大量的时间序列数据,并且支持SQL查询和连续聚合功能。
1.TimescaleDB的优点
- 分布式架构:TimescaleDB利用
分布式架构和根据时间戳进行分片的方式,以提高并行查询性能,从而可以轻松地处理大型数据集 - 高性能:由于其专注于时间序列数据,TimescaleDB包括了许多特性,如离线压缩、顺序扫描等,这些功能使得查询效率更高、数据占用空间更小
- 兼容标准SQL:使用标准SQL来查询数据,并且完全兼容 PostgreSQL,也可以支持 PostGIS 等其它扩展
- 易于部署和维护:TimescaleDB安装非常方便,与现有应用程序基础设施兼容。同时,它的监控工具也可以帮助用户监视和管理整个系统
总之,TimescaleDB是一个
快速,可伸缩的开源时序数据库,适合于需要处理和分析大量时间序列数据的应用场景。
2.TimescaleDB的缺点
- 开源版本的 TimescaleDB 功能相对较为简单,如果需要使用更高级的功能,需要购买专业版或企业版的许可证
- TimescaleDB 可以处理大量的时间序列数据,但是它并不是一个通用的数据库,因此在处理非时间序列的数据时,需要使用其他的数据库
- TimescaleDB 依赖 PostgreSQL 运行,因此需要一定的 PostgreSQL 知识才能使用它
- TimescaleDB 的写入性能相对较慢,尤其是在数据量非常大的情况下。由于它是一个基于时间序列的数据库,因此写入操作需要进行时间序列的排序和分区,这可能会影响到写入的速度
- TimescaleDB 目前还不支持复杂的分布式操作,例如分布式事务和分布式 join 等。这对于需要进行复杂分布式操作的场景可能是一个限制
总的来说,虽然 TimescaleDB 具有很多优点,但是它也有一些限制和缺点。在选择数据库时,需要根据实际情况进行权衡和选择
二 TimescaleDB的安装
注意:安装TimescaleDB的前提是,已经成功安装了PostgreSQL
安装完成之后需要重启PostgreSQL
1.Windows安装
Window安装前提:已将bin目录地址和lib目录地址配置到了环境变量Path中,另外记得暂时关闭各种杀毒软件
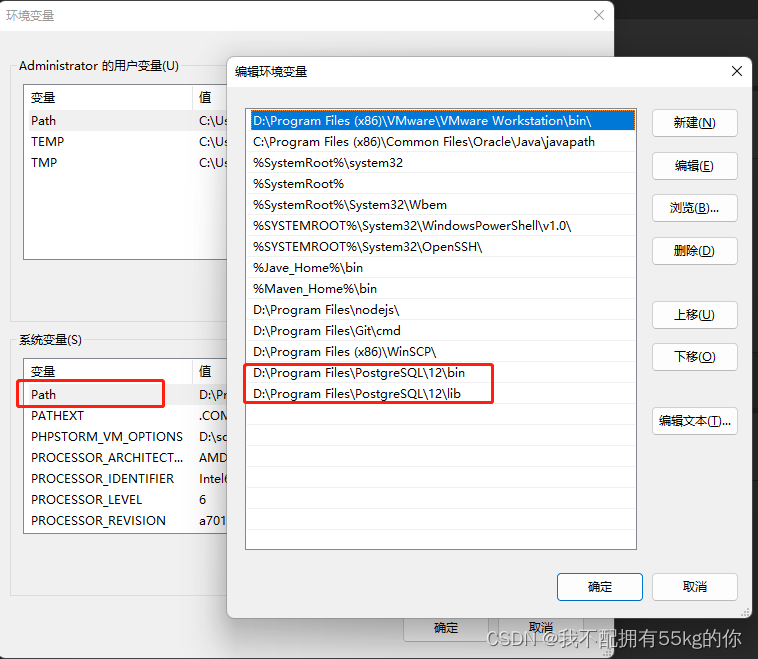
1.下载Timescale安装包
下载地址:Releases · timescale/timescaledb · GitHub
我这里使用的是PostgreSQL12.x,故此下载12版本的timescaledb-postgresql的压缩包
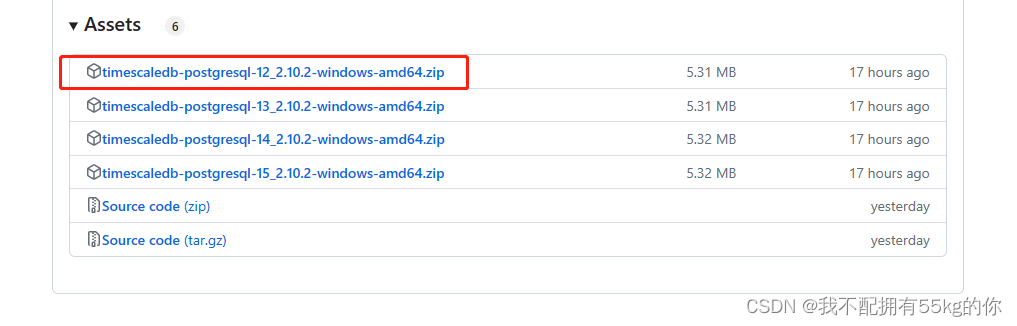
2.解压运行
解压之后进入根目录,右击setup.exe文件,然后选择“以管理员身份运行”,这一点很重要,如果没有关闭杀毒软件或没有以管理员身份运行,则可能会报错,或者画面一闪而过。
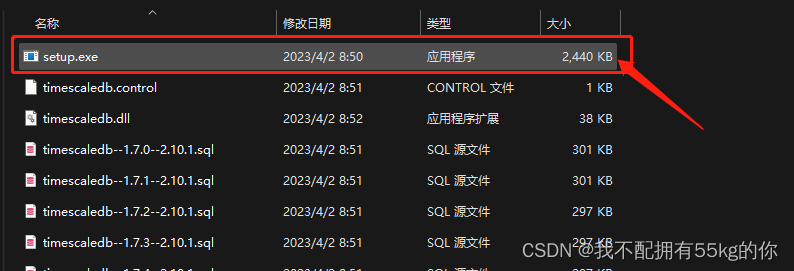
在弹出的cmd对话框中,输入 y,同意继续安装
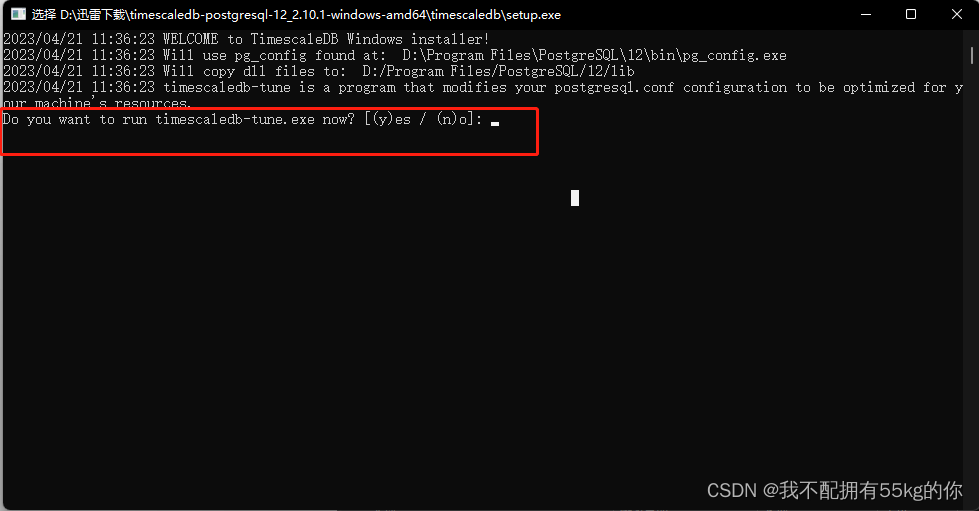
然后根据提示,会让输入PostgreSQL的配置文件路径,找到PostgreSQL的配置文件地址,复制过来即可,一般在/data目录下
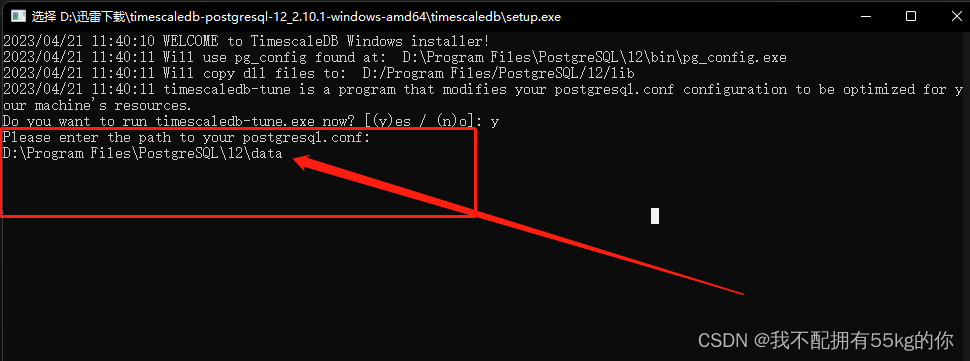
接下来一路 yes,直到提示安装完成。
最后,打开pgsql的控制台,或者使用pgsql的连接工具,打开一个查询界面。
输入以下命令
CREATE EXTENSION IF NOT EXISTS timescaledb CASCADE;
如果出现以下画面,则说明安装成功
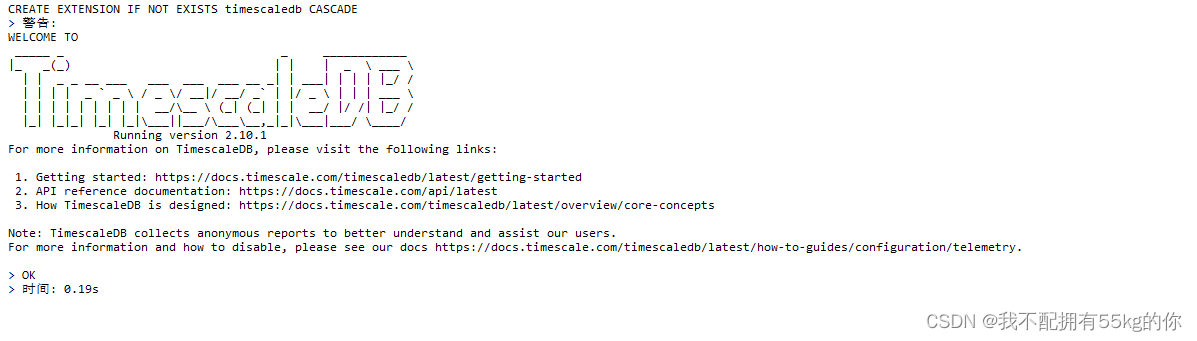
然后重启PostgreSQL服务即可。
如果不再需要TimescaleDB,则可以使用命令移除它
DROP EXTENSION IF EXISTS timescaledb CASCADE;
2.Ubuntu安装
3.Centos安装
4.Docker安装
三 Timescale的使用
1.创建超表
查看timescaledb是否已经安装并且启用
SELECT * FROM pg_extension WHERE extname = 'timescaledb';
PostgreSQL属于关系型数据库,常规表与其他关系型数据库区别不大,可使用PostgreSQL的管理工具pgAdmin连接,也可以使用Navicat。
以下是一个简单的创建表的SQL:
CREATE TABLE sensor_data (
time TIMESTAMPTZ NOT NULL,
location TEXT NOT NULL,
temperature DOUBLE PRECISION NULL,
humidity DOUBLE PRECISION NULL,
pressure DOUBLE PRECISION NULL,
PRIMARY KEY (time, location)
)
需要注意的是,主键是类型为TIMESTAMPTZ的字段
然后为常规表创建超表
在 TimescaleDB 中,超表(hypertable)是指具有不同数据分区的表。 TimescaleDB 的一个主要功能是能够在数据集按时间分割(时间序列数据)的情况下改善查询性能。
-- 实例 1
SELECT create_hypertable('sensor_data', 'time');
-- 实例 2
SELECT create_hypertable('sensor_data', 'time', chunk_time_interval => interval '1 month');
在上述实例2语句中,create_hypertable 函数用于创建名为 sensor_data 的 hypertable,其中使用 time 列来进行数据分区,并将其按月分割成单独的数据块(chunk)。该函数接受的最后一个参数为 chunk_time_interval,用于定义超级表中每个数据块的范围。
如果不指定chunk_time_interval,则默认为7天,即每间隔7天,将会生成一个新的数据块(chunk)。
也可以在创建超表之后对chunk_time_interval进行修改:
--实例: 将sensor_data超表的数据块范围修改为3天
SELECT set_chunk_time_interval('sensor_data', INTERVAL '3 days');
2.删除超表
-- 删除 sensor_data 表所对应的超表
DROP HYPERTABLE IF EXISTS sensor_data;
-- 删除 sensor_data 表所对应的超表以及数据
DROP HYPERTABLE IF EXISTS sensor_data CASCADE;
3.查看超表
使用以下命令,可以查看当前数据库的超表信息
-- 查看超表的状态
SELECT * FROM timescaledb_information.hypertables;

以上内容,主要展示了超表所在的模式,超表名称,超表拥有者,数据围堵,数据分区数量,是否启用压缩,是否分布式等主要内容,可以清晰的看到各个超表的具体情况。
4.超表压缩
启用压缩后,超表中新插入的数据将被自动压缩,并且查询时只需要解压缩必要的部分,这可以显著降低磁盘空间和 IO 开销,并大幅提高读写性能。
需要注意的是,启用压缩后会增加一定的查询处理时间,因此建议进行基准测试以确定哪些查询将受到影响并了解何时使用压缩或放弃压缩。
同时,也应该考虑其它压缩类型的设置,如timescaledb.compress_orderby,用于指定优化压缩的列或表达式。选择不同的压缩类型也会影响压缩效果和可操作性,必须考虑实际业务情况进行设置。
以下是一个压缩示例:
压缩 sensor_data 超表,并以time列项进行排序
ALTER TABLE sensor_data SET (
timescaledb.compress,
timescaledb.compress_orderby => 'time'
);





![[SWPU CTF]之Misc篇(NSSCTF)刷题记录⑥](https://img-blog.csdnimg.cn/49148a811d6a4e03844d527b92289d14.png)



![[python] 协程学习从0到1,配合案例,彻底理解协程,耗费资源不增加,效果接近多线程](https://img-blog.csdnimg.cn/245095afe56143b19011c1ac53b0ea52.png)

