文章目录
Doris基础介绍
一、基本概念
二、建表语法及参数解释
1、column_definition_list
2、index_definition_list
3、engine_type
4、key_type
5、table_comment
6、partition_desc
7、distribution_desc
8、rollup_list
9、properites
三、数据类型
Doris基础介绍
一、基本概念
在 Doris 中,数据都以表(Table)的形式进行逻辑上的描述,一张表包括行(Row)和列(Column),Table中又有分区(partition)和分桶(tablet)概念,下面分别介绍这些概念。
- ROW&Column
Row 代表用户的一行数据,Column用于描述一行数据中不同的字段。Column 可以分为两大类:Key 和 Value。从业务角度看,Key 和 Value 可以分别对应维度列和指标列。从聚合模型的角度来说,Key 列相同的行,会聚合成一行。其中 Value 列的聚合方式由用户在建表时指定。具体可以参考数据模型小节。
- Tablet&Partition
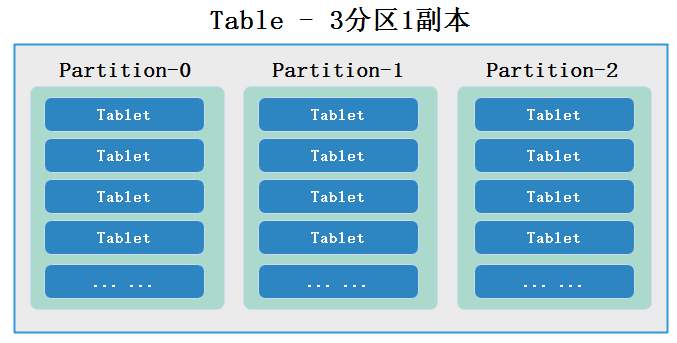
在 Doris 的存储引擎中,用户Table数据被水平划分为若干个数据分片(Tablet,也称作数据分桶)。每个 Tablet 包含若干数据行。各个 Tablet 之间的数据没有交集,并且在物理上是独立存储的。
多个 Tablet 在逻辑上归属于不同的分区(Partition)。一个 Tablet 只属于一个 Partition。而一个 Partition 包含若干个 Tablet。 因为 Tablet 在物理上是独立存储的,所以可以视为 Partition 在物理上也是独立。Tablet 是数据移动、复制等操作的最小物理存储单元。
若干个 Partition 组成一个 Table。 Partition 可以视为是逻辑上最小的管理单元。数据的导入与删除,都可以或仅能针对一个 Partition 进行。
二、建表语法及参数解释
Doris的建表语句如下:
CREATE TABLE [IF NOT EXISTS] [database.]table
(
column_definition_list,
[index_definition_list]
)
[engine_type]
[keys_type]
[table_comment]
[partition_desc]
[distribution_desc]
[rollup_list]
[properties]
注意:
- Doris建表时一个同步命令,SQL执行完成即返回结果,命令返回成功即表示建表成功。
IF NOT EXISTS表示如果没有创建过该表,则创建。注意这里只判断表名是否存在,而不会判断新建表结构是否与已存在的表结构相同。所以如果存在一个同名但不同构的表,该命令也会返回成功,但并不代表已经创建了新的表和新的结构。
1、column_definition_list
column_definition_list 表示定义的列信息,一个表中可以定义多个列,每个列的定义如下:
column_name column_type [KEY] [aggr_type] [NULL] [default_value] [column_comment]
以上定义列参数解释如下:
- column_name:列名;
- column_type:列类型,Doris支持常见的列类型:INT、BIGING、FLOAT、DATE、VARCHAR等,详细参考数据类型小节;
- aggr_type:表示聚合类型,支持以下聚合类型:
SUM:求和。适用数值类型。
MIN:求最小值。适合数值类型。
MAX:求最大值。适合数值类型。
REPLACE:替换。对于维度列相同的行,指标列会按照导入的先后顺序,后倒入的替换先导入的。
REPLACE_IF_NOT_NULL:非空值替换。和 REPLACE 的区别在于对于null值,不做替换。这里要注意的是字段默认值要给NULL,而不能是空字符串,如果是空字符串,会给你替换成空字符串。
HLL_UNION:HLL 类型的列的聚合方式,通过 HyperLogLog 算法聚合。
BITMAP_UNION:BIMTAP 类型的列的聚合方式,进行位图的并集聚合。
- default_value:列默认值,当导入数据未指定该列的值时,系统将赋予该列default_value。语法为
default default_value,当前default_value支持两种形式:
#1.用户指定固定值,如:
k1 INT DEFAULT '1',
k2 CHAR(10) DEFAULT 'aaaa'
#2.系统提供的关键字,目前只用于DATETIME类型,导入数据缺失该值时系统将赋予当前时间
dt DATETIME DEFAULT CURRENT_TIMESTAMP
示例如下:
k1 TINYINT,
k2 DECIMAL(10,2) DEFAULT "10.5",
k4 BIGINT NULL DEFAULT "1000" COMMENT "This is column k4",
v1 VARCHAR(10) REPLACE NOT NULL,
v2 BITMAP BITMAP_UNION,
v3 HLL HLL_UNION,
v4 INT SUM NOT NULL DEFAULT "1" COMMENT "This is column v4"
- column_comment:列注释。
2、index_definition_list
index_definition_list表示定义的索引信息。定义索引可以是一个或多个,多个使用逗号隔开。索引定义语法如下:
INDEX index_name (col_name) [USING BITMAP] COMMENT 'xxxxxx'示例:
INDEX idx1 (k1) USING BITMAP COMMENT "This is a bitmap index1",
INDEX idx2 (k2) USING BITMAP COMMENT "This is a bitmap index2",
...
3、engine_type
engine_type表示表引擎类型,在Apache Doris中表分为普通表和外部表,两类表主要通过ENGINE类型来标识是那种类型的表。普通表就是Doris中创建的表ENGINE为OLAP,OLAP是默认的Engine类型;外部表有很多类型,ENGIE也不同,例如:MYSQL、BROKER、HIVE、ICEBERG 、HUDI。
示例:
ENGINE=olap4、key_type
key_type表示数据类型。用法如下:
key_type(col1, col2, ...)key_type 支持以下模型:
- DUPLICATE KEY(默认):其后指定的列为排序列。
- AGGREGATE KEY:其后指定的列为维度列。
- UNIQUE KEY:其后指定的列为主键列。
示例:
DUPLICATE KEY(col1, col2),
AGGREGATE KEY(k1, k2, k3),
UNIQUE KEY(k1, k2)
5、table_comment
table_comment表示表注释,示例:
COMMENT "This is my first DORIS table"
6、partition_desc
partitioin_desc表示分区信息,支持三种写法
LESS THAN:仅定义分区上界。下界由上一个分区的上界决定。
PARTITION BY RANGE(col1[, col2, ...])
(
PARTITION partition_name1 VALUES LESS THAN MAXVALUE|("value1", "value2", ...),
PARTITION partition_name2 VALUES LESS THAN MAXVALUE|("value1", "value2", ...)
)
FIXED RANGE:定义分区的左闭右开区间
PARTITION BY RANGE(col1[, col2, ...])
(
PARTITION partition_name1 VALUES [("k1-lower1", "k2-lower1", "k3-lower1",...), ("k1-upper1", "k2-upper1", "k3-upper1", ...)),
PARTITION partition_name2 VALUES [("k1-lower1-2", "k2-lower1-2", ...), ("k1-upper1-2", MAXVALUE, ))
)
MULTI RANGE :批量创建 RANGE 分区,定义分区的左闭右开区间,设定时间单位和步长,时间单位支持年、月、日、周和小时。
PARTITION BY RANGE(col)
(
FROM ("2000-11-14") TO ("2021-11-14") INTERVAL 1 YEAR,
FROM ("2021-11-14") TO ("2022-11-14") INTERVAL 1 MONTH,
FROM ("2022-11-14") TO ("2023-01-03") INTERVAL 1 WEEK,
FROM ("2023-01-03") TO ("2023-01-14") INTERVAL 1 DAY
)
注意:该特性是Doris1.2.1版本后新增。
7、distribution_desc
distribution_desc定义数据分桶方式。有两种方式分别为HASH分桶语法和RANDOM分桶语法。
Hash 分桶
语法: DISTRIBUTED BY HASH (k1[,k2 ...]) [BUCKETS num]
说明: 使用指定的 key 列进行哈希分桶。
Random 分桶
语法: DISTRIBUTED BY RANDOM [BUCKETS num]
说明: 使用随机数进行分桶。
8、rollup_list
rollup_list指的是建表的同时可以创建多个物化视图(ROLLUP),多个物化视图使用逗号隔开,语法如下:
ROLLUP (rollup_definition[, rollup_definition, ...])
以上语法中rollup_definition是定义多个物化视图,语法如下:
rollup_name (col1[, col2, ...]) [DUPLICATE KEY(col1[, col2, ...])] [PROPERTIES("key" = "value")]
示例:
ROLLUP (
r1 (k1, k3, v1, v2),
r2 (k1, v1)
)
9、properites
在创建表时,可以指定properties设置表属性,详细使用会在后面的文章进行详细介绍。
三、数据类型
Apache Doris支持常见的列数据类型如下:
| 列类型 | 占用字节 | 描述 |
|---|---|---|
| TINYINT | 1字节 | 范围:-2^7 + 1 ~ 2^7 - 1 |
| SMALLINT | 2字节 | 范围:-2^15 + 1 ~ 2^15 - 1 |
| INT | 4字节 | 范围:-2^31 + 1 ~ 2^31 - 1 |
| BIGINT | 8字节 | 范围:-2^63 + 1 ~ 2^63 - 1 |
| LARGEINT | 16字节 | 范围:-2^127 + 1 ~ 2^127 - 1 |
| BOOLEAN | 1字节 | 与TINYINT一样,0代表false,1代表true |
| FLOAT | 4字节 | 支持科学计数法 |
| DOUBLE | 12字节 | 支持科学计数法 |
| DECIMAL[(precision, scale)] | 16字节 | 保证精度的小数类型。默认是 DECIMAL(10, 0)precision: 1 ~ 27scale: 0 ~ 9其中整数部分为 1 ~ 18不支持科学计数法 |
| DECIMALV3[(precision, scale)] | 16字节 | 更高精度的小数类型。默认是 DECIMAL(10, 0)precision: 1 ~ 38scale: 0 ~ precision |
| DATE | 3字节 | 范围:0000-01-01 ~ 9999-12-31 |
| DATEV2 | 3字节 | DATEV2类型相比DATE类型更加高效,在计算时,DATEV2相比DATE可以节省一半的内存使用量。 |
| DATETIME | 8字节 | 范围:0000-01-01 00:00:00 ~ 9999-12-31 23:59:59 |
| DATETIMEV2 | 8字节 | 范围是0000-01-01 00:00:00[.000000] ~ 9999-12-31 23:59:59[.999999],相比DATETIME类型,DATETIMEV2更加高效,并且支持了最多到微秒的时间精度。 |
| CHAR[(length)] | 1字节 | 定长字符串。长度范围:1 ~ 255。 |
| VARCHAR[(length)] | - | 变长字符串。长度范围:1 ~ 65533。 |
| STRING | - | 变长字符串。最大(默认)支持1048576 字节(1MB)String类型的长度还受 be 配置 string_type_length_soft_limit_bytes, 实际能存储的最大长度 取两者最小值,String类型只能用在value 列,不能用在 key 列和分区、分桶列 |
| HLL | 1~16385个字节 | HyperLogLog 列类型,不需要指定长度和默认值。长度根据数据的聚合程度系统内控制。必须配合 HLL_UNION 聚合类型使用。 |
| BITMAP | - | bitmap 列类型,不需要指定长度和默认值。表示整型的集合,元素最大支持到2^64 - 1。必须配合 BITMAP_UNION 聚合类型使用。 |
Apache Doris还支持ARRAY、JSONB类型,具体可以参考官网:
https://doris.apache.org/zh-CN/docs/dev/sql-manual/sql-reference/Data-Types/
- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨