可以通过以下命令在线安装 Logstash 7.17.7
sudo rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
sudo rpm -ivh https://artifacts.elastic.co/downloads/logstash/logstash-7.17.7-x86_64.rpm
安装完成后,需要添加环境变量
export PATH=$PATH:/usr/share/logstash/bin
然后,通过执行以下命令,使更改生效:
source ~/.bashrc
你可以通过运行以下命令来验证 Logstash 版本:
logstash -V
如果一切正常,你应该能看到类似如下输出:
logstash 7.17.7
Mysql创建数据库,表,并制造和添加数据
假设有一个 MySQL 数据库 mydb,其中包含一个表 mytable,表结构如下:
CREATE TABLE mytable (
id INT NOT NULL AUTO_INCREMENT,
name VARCHAR(50) NOT NULL,
age INT NOT NULL,
address VARCHAR(100) NOT NULL,
PRIMARY KEY (id)
);
造46条数据:
INSERT INTO mytable (name, age, address) VALUES
('Alice', 25, '主街123号'), ('Bob', 30, '高街456号'), ('Charlie', 35, '橡树大道789号'), ('David', 40, '松树街321号'), ('Emma', 45, '榆树街654号'),
('Frank', 50, '枫树大道987号'), ('Grace', 55, '樱桃街246号'), ('Henry', 60, '桦树路369号'), ('Isabella', 65, '橡木道802号'), ('John', 70, '公园大道1473号'),
('Kate', 75, '柳树巷567号'), ('Lucas', 80, '森林路901号'), ('Mia', 85, '胡桃街2345号'), ('Nathan', 90, '松林大道678号'), ('Olivia', 95, '雪松街1011号'),
('Paul', 100, '第五大道1213号'), ('Quinn', 105, '主街1415号'), ('Robert', 110, '百老汇1617号'), ('Samantha', 115, '榆树道1819号'), ('Thomas', 120, '松树巷2021号'),
('Ursula', 125, '橡树路2223号'), ('Vincent', 130, '公园大道2425号'), ('Wendy', 135, '日落大道2627号'), ('Xavier', 140, '橡木道2829号'), ('Yvette', 145, '枫木路3031号'),
('Zachary', 150, '橡树街3233号'), ('Alice', 25, '主街123号'), ('Bob', 30, '高街456号'), ('Charlie', 35, '橡树大道789号'), ('David', 40, '松树街321号'),
('Emma', 45, '榆树街654号'), ('Frank', 50, '枫树大道987号'), ('Grace', 55, '樱桃街246号'), ('Henry', 60, '桦树路369号'), ('Isabella', 65, '橡木道802号'),
('John', 70, '公园大道1473号'), ('Kate', 75, '柳树巷567号'), ('Lucas', 80, '森林路901号'), ('Mia', 85, '胡桃街2345号'), ('Nathan', 90, '松林大道678号'),
('Olivia', 95, '雪松街1011号'), ('Paul', 100, '第五大道1213号'), ('Quinn', 105, '主街1415号'), ('Robert', 110, '百老汇1617号'), ('Samantha', 115, '榆树道1819号'),
('Thomas', 120, '松树巷2021号');
需要将 mytable 中的数据导入到 Elasticsearch 中。
实际上不需要分词器!!
以下是操作步骤:
在 Elasticsearch 中创建索引,并指定字段类型和分词器,导入之前还需要注意下时间的问题,确定一下系统时间
PUT /myindex
{
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
},
"age": {
"type": "integer"
},
"address": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
}
}
}
}
安装 Logstash 和 JDBC 驱动
安装 Logstash(Logstash已安装的可以忽略)
sudo rpm -ivh https://artifacts.elastic.co/downloads/logstash/logstash-7.17.7-x86_64.rpm
下载 JDBC 驱动,此处使用 MySQL 官方的 JDBC 驱动
sudo curl -L -O https://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-java-8.0.28.tar.gz
解压 JDBC 驱动
sudo tar xvf mysql-connector-java-8.0.28.tar.gz
将 JDBC 驱动复制到 Logstash 的 plugins 目录下
sudo cp mysql-connector-java-8.0.28/mysql-connector-java-8.0.28.jar /usr/share/logstash/logstash-core/lib/jars/
创建 Logstash 配置文件 mysql.conf,
配置文件可以放任何地方,需要指定 JDBC 连接信息、SQL 语句和 Elasticsearch 输出配置
input {
jdbc {
jdbc_driver_library => "/usr/share/logstash/logstash-core/lib/jars/mysql-connector-java-8.0.28.jar"
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://192.168.80.1:3306/mydb"
jdbc_user => "root"
jdbc_password => "QWER1234@"
statement => "SELECT * FROM mytable"
}
}
output {
elasticsearch {
hosts => ["http://localhost:9200"]
index => "mytable"
document_id => "%{id}"
user => "elastic"
password => "111111"
}
}
其中 jdbc_connection_string 指定了 MySQL 数据库的连接信息,jdbc_user 和 jdbc_password 分别指定了 MySQL 数据库的用户名和密码,statement 指定了 SQL 语句,此处是将 mytable 表中的所有数据导入到 Elasticsearch 中。别忘了配置es的账号密码。
document_id 指定了 Elasticsearch 中文档的 ID,此处将使用 MySQL 中的 id 字段作为 Elasticsearch 中文档的 ID!!!(文档的id需要具有唯一性)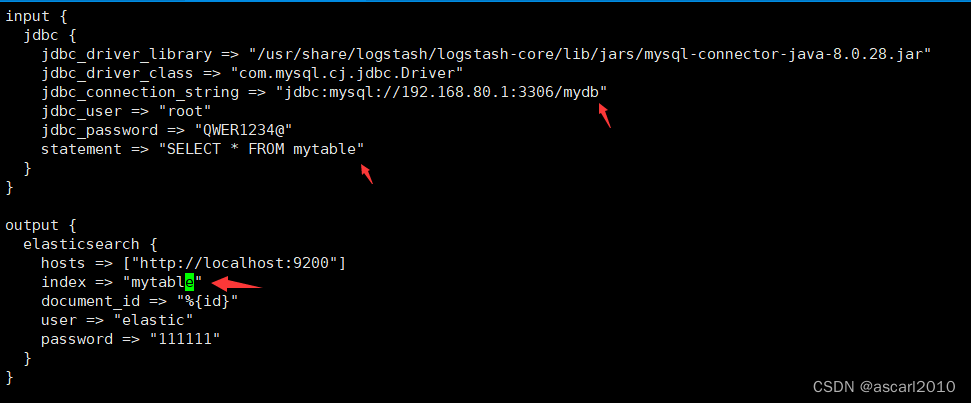
运行 Logstash
sudo /usr/share/logstash/bin/logstash -f mysql.conf
等待 Logstash 导入数据完成

完成以上操作后,我们可以通过以下步骤验证数据是否成功导入 Elasticsearch 中:
在 Kibana 中打开 Dev Tools。
执行以下命令,查询导入的文档数量是否正确:
GET /mytable/_count
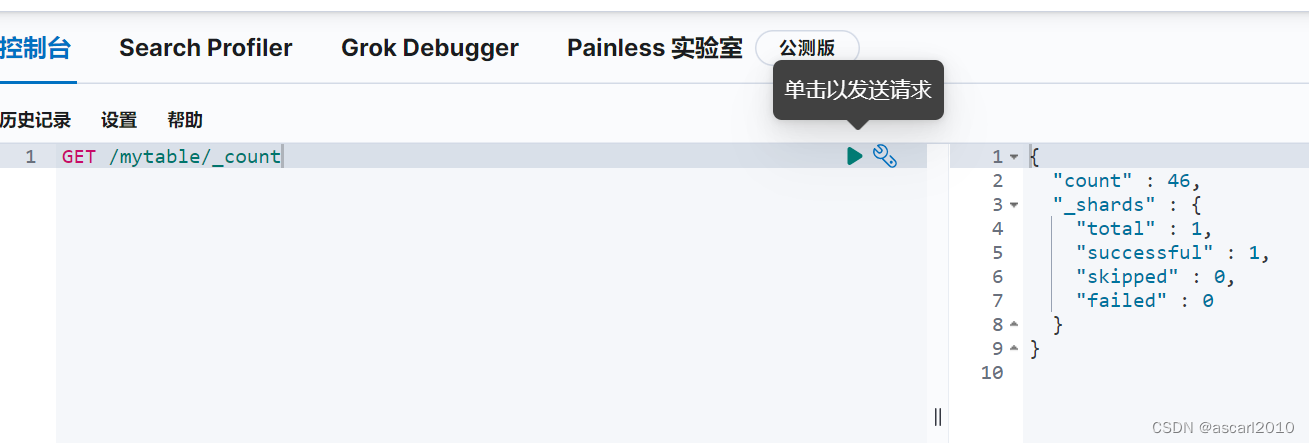
执行以下命令,查询文档内容是否正确:
GET /mytable/_search
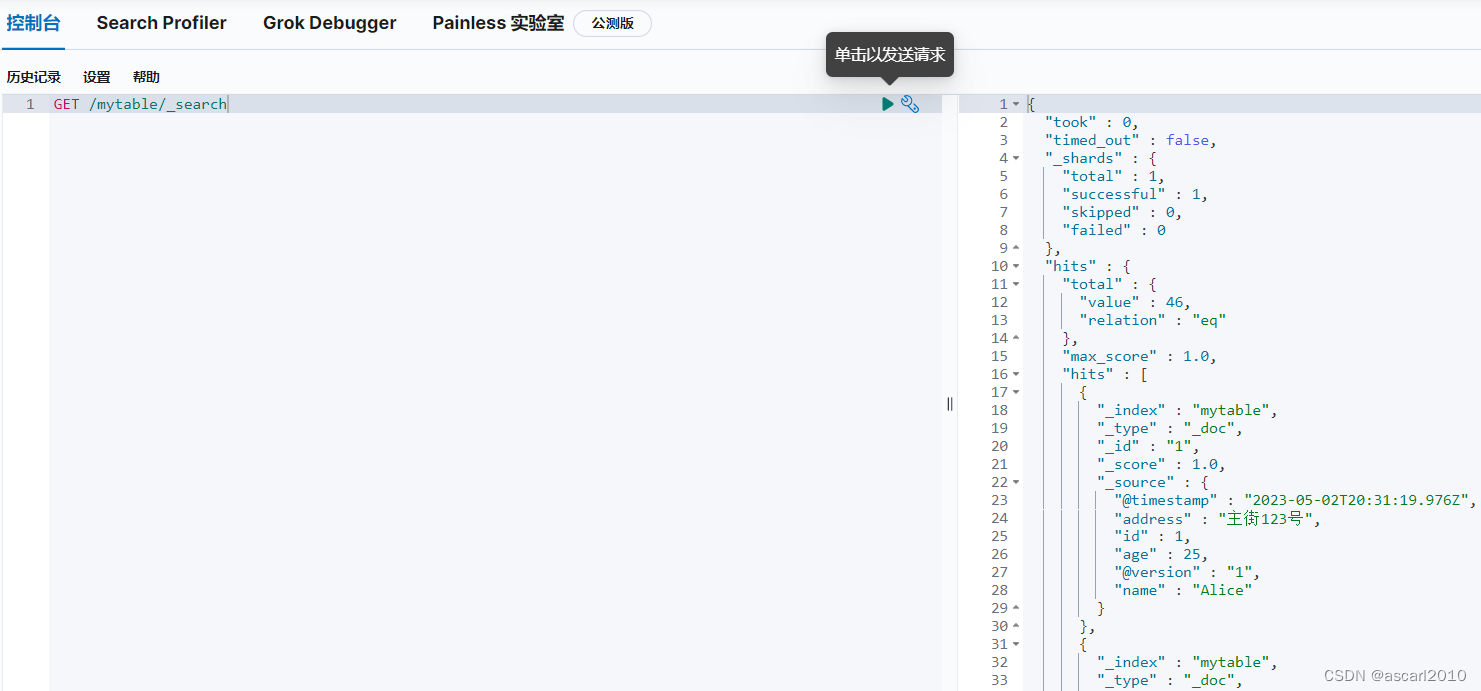
以上步骤中的 SQL 语句可以根据实际需求进行修改,例如可以添加 WHERE 子句来筛选符合条件的数据,或者使用 JOIN 等高级功能来获取更丰富的数据。同时,我们也可以根据需要修改 Logstash 的配置文件和 Elasticsearch 的映射规则等,以满足不同的数据导入需求。
在Elasticsearch中查询地址含有“森林路”的名字,您可以使用以下查询语句:会分词!!!!!
GET mytable/_search
{
"query": {
"match": {
"address": "森林路"
}
}
}
因为在 Elasticsearch 中使用 Match 查询时,默认情况下会对文本进行分词。这意味着如果你搜索 “森林路”,它将在文本中寻找包含 “森林” 和 “路” 的文档。因此,包含 “松林大道” 或 “枫木路” 的文档也会出现在查询结果中。
这将在名为“mytable”的索引中搜索具有地址“森林路”的所有记录,并返回匹配的文档。如果您只想返回特定字段(例如,只想返回匹配的记录的姓名),可以使用“_source”参数来指定要返回的字段。例如:
GET mytable/_search
{
"_source": ["name"],
"query": {
"match": {
"address": "森林路"
}
}
}
这将仅返回匹配的文档中的“name”字段。
要精确匹配整个短语,可以使用 Match Phrase 查询或使用双引号将搜索词语括起来。例如:
GET mytable/_search
{
"query": {
"match_phrase": {
"address": "森林路"
}
}
}
这将只返回地址中包含 “森林路” 短语的文档。

**
修改数据库中数据然后再同步
**
在数据库中修改数据,然后执行logstash同步,数据居然可以把修改后同步过去,数量依旧是46,保持不变


**
在数据库中新增数据再同步
**
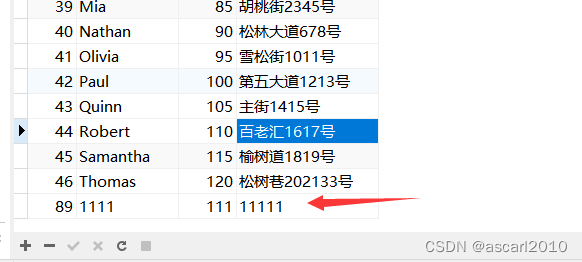
sudo /usr/share/logstash/bin/logstash -f mysql.conf
数量变成了47,同时也查出了数据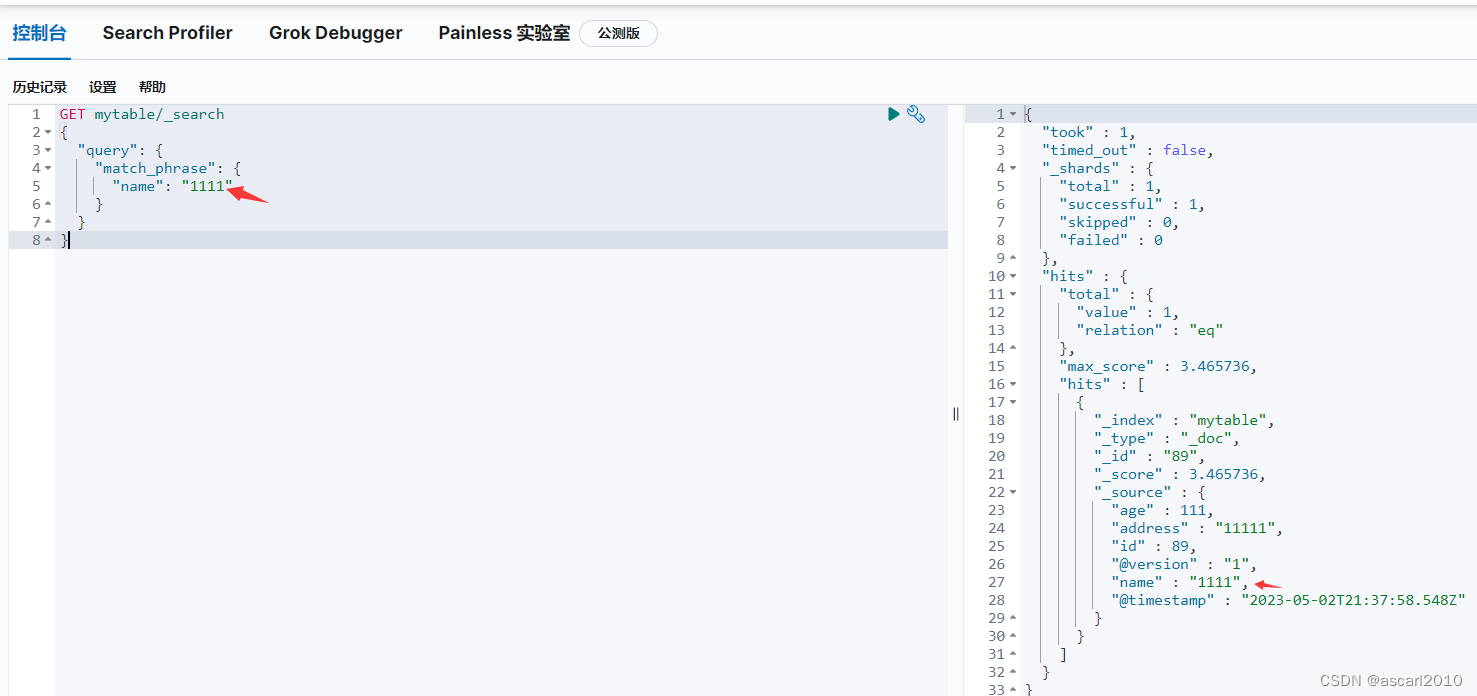


![[架构之路-179]-《软考-系统分析师》-19- 系统可靠性分析与设计 -1- 故障模型、可靠性模型、可靠性分析](https://img-blog.csdnimg.cn/f38135dbfcce4e41b4ed8df5eb33851f.png)



![[架构之路-178]-《软考-系统分析师》-17-嵌入式系统分析与设计- 3- 分区操作系统(Partition Operating System)概述](https://img-blog.csdnimg.cn/img_convert/f6127803753a2c50d6fbf3c886530e08.png)
![[计算机图形学]光场,颜色与感知(前瞻预习/复习回顾)](https://img-blog.csdnimg.cn/fe9d60e5fd0b4bf18f86d88e272243d1.png)