603 连续空余座位

select distinct c1.seat_id
from Cinema c1
join Cinema c2
on abs(c2.seat_id-c1.seat_id) = 1
where c1.free=1 and c2.free=1
order by c1.seat_id;
总结
- 思路:为什么我们这里需要abs和distinct,如果是如下代码,为什么不可以?
select c1.seat_id
from Cinema c1
join Cinema c2
on c2.seat_id-c1.seat_id = 1
where c1.free=1 and c2.free=1
order by c1.seat_id;
上面代码的结果忽略了最后一个满足条件的记录,因此我们需要使用abs,使得我们可以获得所有满足条件的记录,但这样存在重复的记录,因此需要使用distinct 去重重复元素。
1795 每个产品在不同商店的价格

# Write your MySQL query statement below
select product_id, 'store1' as store, store1 as price from Products where store1 is not null
union all
select product_id, 'store2' as store, store2 as price from Products where store2 is not null
union all
select product_id, 'store3' as store, store3 as price from Products where store3 is not null
总结
- 行转列用groupby+sumif,
列转行用union all - UNION和UNION ALL效率:
UNION和UNION ALL关键字都是将两个结果集合并为一个,但这两者从使用和效率上来说都有所不同。
- 对重复结果的处理:UNION在进行表链接后会筛选掉重复的记录,Union All不会去除重复记录。
- 对排序的处理:Union将会按照字段的顺序进行排序;UNION ALL只是简单的将两个结果合并后就返回。
从效率上说,UNION ALL要比UNION快很多,所以,如果可以确认合并的两个结果集中不包含重复数据且不需要排序时的话,那么就使用UNION ALL。
• 注意:两个要联合的SQL语句字段个数必须一样,而且字段类型要“相容”(一致);
拓展—表格转换问题
- 表格转换总结
613 直线上的最近距离

select min(abs(p1.x-p2.x)) as shortest
from point p1
join point p2
on p1.x != p2.x
- 做过前面那道题,这道题就很简单了~
1965 丢失信息的雇员
select employee_id
from Employees
where employee_id not in (select employee_id from Salaries)
union
select employee_id
from Salaries
where employee_id not in (select employee_id from Employees)
order by employee_id
1264 页面推荐
- 1264题目链接
# Write your MySQL query statement below
select distinct page_id as recommended_page
from Likes
where user_id in (
(
select user2_id
from Friendship
where user1_id = 1
)
union
(
select user1_id
from Friendship
where user2_id = 1
)
) and page_id not in (select page_id from Likes where user_id = 1);
总结
- 该题需要注意not in的用法,如果我们使用!=,当右边出现null时,该语句会为false,因此无查询数据。因此我们应该使用not in。
608 树节点


# Write your MySQL query statement below
select id, (
case when p_id is null then 'Root'
when p_id is not null and id in (select p_id from tree) then 'Inner'
else 'Leaf'
end
) as Type
from tree
总结
- not in中包含有null时,结果集一直为Empty set
- 例如,下列代码就是错误的写法:
select
id,
case when p_id is null then "Root"
when id not in (select p_id from tree) then "Leaf"
else "Inner"
end as Type
from
tree
-
A not in B的原理是拿A表值与B表值做是否不等的比较, 也就是a != b. 在sql中, null是缺失未知值而不是空值(详情请见MySQL reference).
-
当你判断任意值a != null时, 官方说,
"You cannot use arithmetic comparison operators such as =, <, or <> to test for NULL", 任何与null值的对比都将返回null. 因此返回结果为否,这点可以用代码select if(1 = null, 'true', 'false')证实. -
从上述原理可见, 当询问
id not in (select p_id from tree)时, 因为p_id有null值, 返回结果全为false, 于是跳到else的结果, 返回值为inner. 所以在答案中,leaf结果从未彰显,全被inner取代。
534
# 写法1
# Write your MySQL query statement below
select a2.player_id, a2.event_date, sum(a1.games_played) as games_played_so_far
from Activity a1, Activity a2
where a1.player_id = a2.player_id and a2.event_date >= a1.event_date
group by a2.player_id, a2.event_date
order by a2.player_id, a2.event_date
# 写法2
# Write your MySQL query statement below
select player_id, event_date,
sum(games_played) over(partition by player_id order by event_date)
as games_played_so_far
from Activity
窗口函数的使用
- 窗口函数详解
1783 大满贯数量
- 1783题
# 写法1
# Write your MySQL query statement below
select player_id, player_name,
sum(player_id = Wimbledon) + sum(player_id = Fr_open) +
sum(player_id = US_open) + sum(player_id = Au_open)
as grand_slams_count
from Players, Championships
group by player_id, player_name
having grand_slams_count > 0
# 写法2
select player_id, player_name, count(*) as grand_slams_count
from Players join (
select Wimbledon from Championships
union all
select Fr_open from Championships
union all
select US_open from Championships
union all
select Au_open from Championships
) t
on Players.player_id = t.Wimbledon
group by player_id, player_name;
总结
- union all和union的区别 : union all 和union和union形象讲解
- sum函数中使用if判断条件格式为:
sum(if(条件,列值,0))
#order_type:订单类型
#open_id:用户唯一标识
SELECT
date(create_time) AS '当天日期',
sum(real_price) AS '当天总收入',
sum函数中使用if判断条件:{
sum(
IF (order_type = 0, real_price, 0)
) AS '当天支付收入',
sum(
IF (order_type = 1, real_price, 0)
) AS '当天打赏收入',
}
count(DISTINCT open_id) AS '付费总人数',
count函数中使用if判断条件:{
count(
DISTINCT open_id,
IF (order_type = 0, TRUE, NULL)
) AS '支付人数',
count(
DISTINCT open_id,
IF (order_type = 1, TRUE, NULL)
) AS '打赏人数',
}
count(id) AS '付费订单总数',
count函数中使用if判断条件:{
count(
DISTINCT id,
IF (order_type = 0, TRUE, NULL)
) AS '支付订单数',
count(
DISTINCT id,
IF (order_type = 1, TRUE, NULL)
) AS '打赏订单数'
}
FROM
orders
WHERE
'real_price' != 1
AND 'status' != 0
GROUP BY DATE(create_time)
注解:sum是求和函数,条件为真时,执行列值(字段名)求和也就是累加,条件为假时为0求和(当然还是0)
(1)单条件判断格式,sum(if(条件字段名=值,需要计算sum的字段名,0))
(2)多条件判断格式,sum(if(条件字段名>值 AND 条件字段名>值 AND 条件字段名=值,1,0))
注解:多条件判断格式整体含义为,计算满足条件的数据总数,如果满足条件,那么数据总数加1,所以1的含义为累加1
(3)常见case when格式,sum(case when 条件字段名 in (范围较小值,范围较大值) then [需要计算sum的字段名] else 0 end)
- count函数中使用if判断条件格式为:
(1)统计总数,count(if(条件字段名=值,true,null))
(2)统计总数去重复值,count(DISTINCT 需要计算count的字段名,if(条件字段名=值,true,null))
1747 应该被禁止的 Leetflex 账户
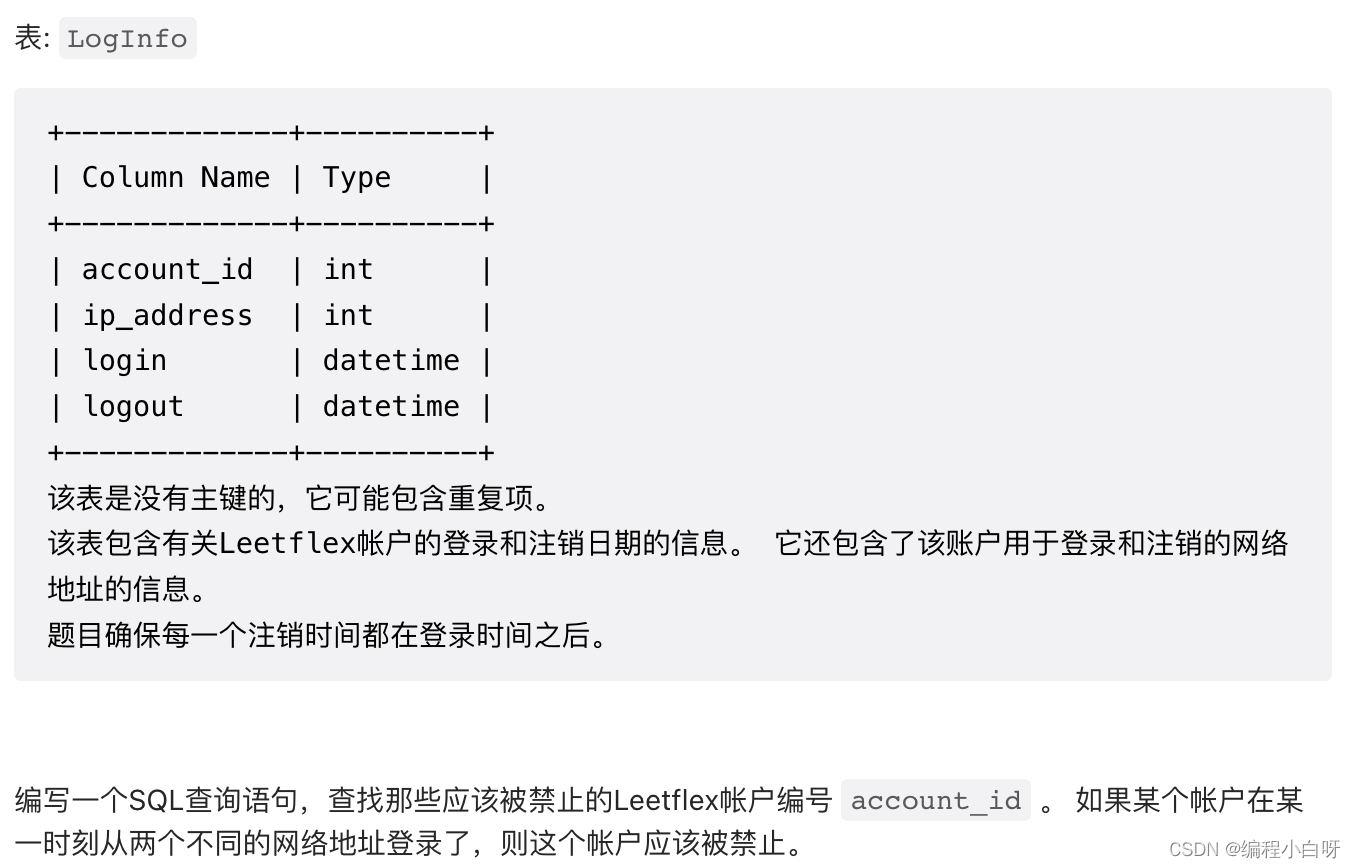
# Write your MySQL query statement below
select distinct l1.account_id
from LogInfo l1
join LogInfo l2
on l1.account_id = l2.account_id and l1.ip_address != l2.ip_address
and l2.login between l1.login and l1.logout;
总结
between and的用法 between and用法
![[架构之路-178]-《软考-系统分析师》-17-嵌入式系统分析与设计- 3- 分区操作系统(Partition Operating System)概述](https://img-blog.csdnimg.cn/img_convert/f6127803753a2c50d6fbf3c886530e08.png)
![[计算机图形学]光场,颜色与感知(前瞻预习/复习回顾)](https://img-blog.csdnimg.cn/fe9d60e5fd0b4bf18f86d88e272243d1.png)