参考:
ModelMesh installation - KServe Documentation Website
ModelMesh Overview - KServe Documentation Website
前言
Kserve提供了“Serverless”和“ModelMesh”两种安装模式。其中Serverless是通过Knative组件实现动态扩缩容等功能。而ModelMesh则是另一种资源开销较小的模式。
意义
按照通常的 AI 部署方案,不同的模型需要运行在不同的模型运行时(runtime)下,多模型部署需要维护大量不同模型运行时 起的服务。
而使用ModelMesh模式,让可以在一个模型运行时运行的模型,部署在一个Pod上,不用造成Pod、IP资源的浪费。
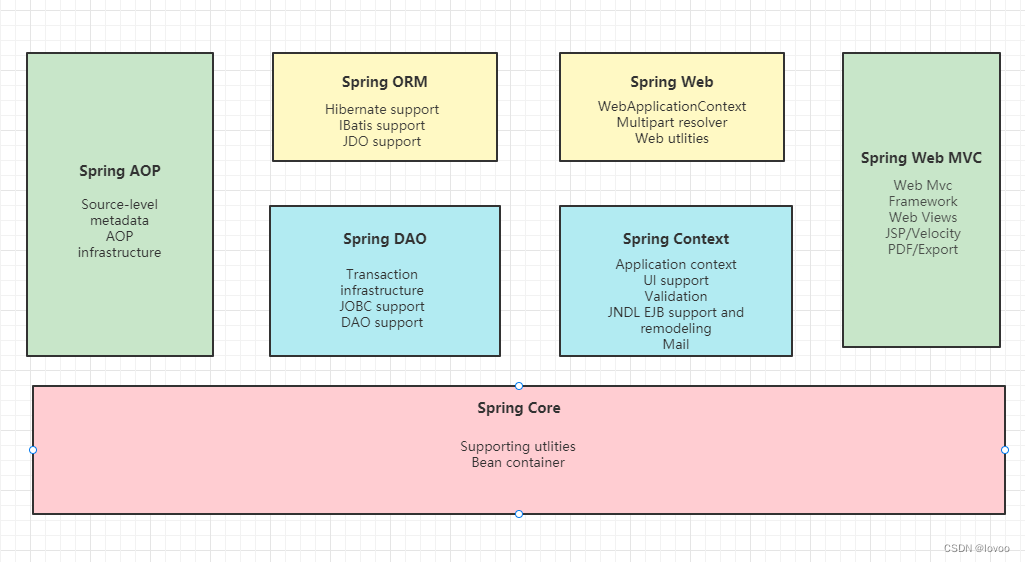
ModelMesh架构

从上图可以看到ModelMesh 主要由三个模块构成:
- ModelMesh serve。ModelMesh CR的调谐模块
- ModelMesh。运行在Runtime Deployment Pod里面,用于调谐模型加载的位置,以及路由推理API请求。
- ModelMesh runtime adapter。运行在Runtime Deployment Pod里面,在上图的Puller位置,用于适配不同的model runtime。
入门使用
首先,用户的namespace需要打上标签:
[root@node-1 working]# k get ns --show-labels chenxy
NAME STATUS AGE LABELS
chenxy Active 66d kubernetes.io/metadata.name=chenxy,modelmesh-enabled=true创建ServingRuntime:
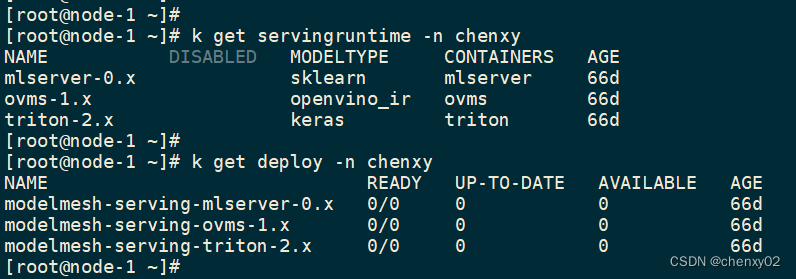
[root@node-1 working]# k get servingruntime -n chenxy
NAME DISABLED MODELTYPE CONTAINERS AGE
mlserver-0.x sklearn mlserver 66d
ovms-1.x openvino_ir ovms 66d
triton-2.x keras triton 66d在ServingRuntime里,有设置runtime的镜像:
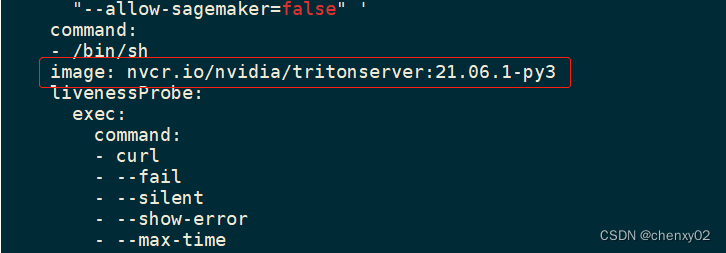
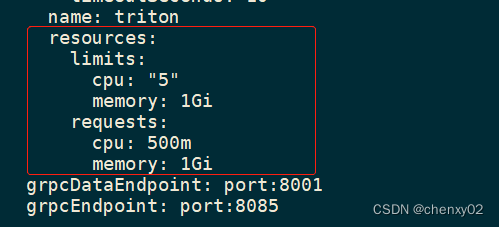
以及runtime占用的资源:
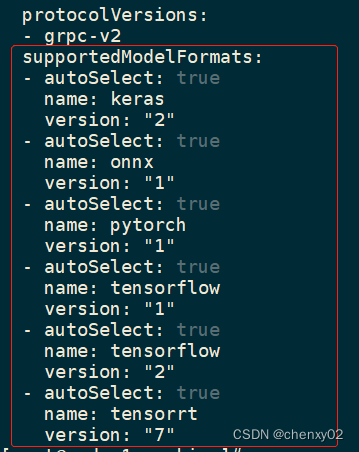
还有runtime支持的model type:
创建完后,可以看到有一个对应的deployment生成:
在没有model部署在相应的 runtime 的时候,这个deployment 是不启动pod的,当相应的runtime上创建一个InferenceService:

等待资源创建成功

再看runtime deployment,就会发现已经有 pod 起来了。