1题目
给你一个含重复值的二叉搜索树(BST)的根节点 root ,找出并返回 BST 中的所有 众数(即,出现频率最高的元素)。
如果树中有不止一个众数,可以按 任意顺序 返回。
假定 BST 满足如下定义:
- 结点左子树中所含节点的值 小于等于 当前节点的值
- 结点右子树中所含节点的值 大于等于 当前节点的值
- 左子树和右子树都是二叉搜索树
示例 1:
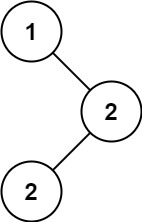
输入:root = [1,null,2,2] 输出:[2]
示例 2:
输入:root = [0] 输出:[0]
2链接
题目链接:501. 二叉搜索树中的众数 - 力扣(LeetCode)
视频链接:不仅双指针,还有代码技巧可以惊艳到你! | LeetCode:501.二叉搜索树中的众数_哔哩哔哩_bilibili
3解题思路
如果不是二叉搜索树
如果不是二叉搜索树,最直观的方法一定是把这个树都遍历了,用map统计频率,把频率排个序,最后取前面高频的元素的集合。
具体步骤如下:
1、这个树都遍历了,用map统计频率
至于用前中后序哪种遍历也不重要,因为就是要全遍历一遍,怎么个遍历法都行,层序遍历都没毛病!
2、把统计的出来的出现频率(即map中的value)排个序
有的同学可能可以想直接对map中的value排序,还真做不到,C++中如果使用std::map或者std::multimap可以对key排序,但不能对value排序。
所以要把map转化数组即vector,再进行排序,当然vector里面放的也是pair<int, int>类型的数据,第一个int为元素,第二个int为出现频率。
3、取前面高频的元素
此时数组vector中已经是存放着按照频率排好序的pair,那么把前面高频的元素取出来就可以了。
是二叉搜索树
既然是搜索树,它中序遍历就是有序的。、
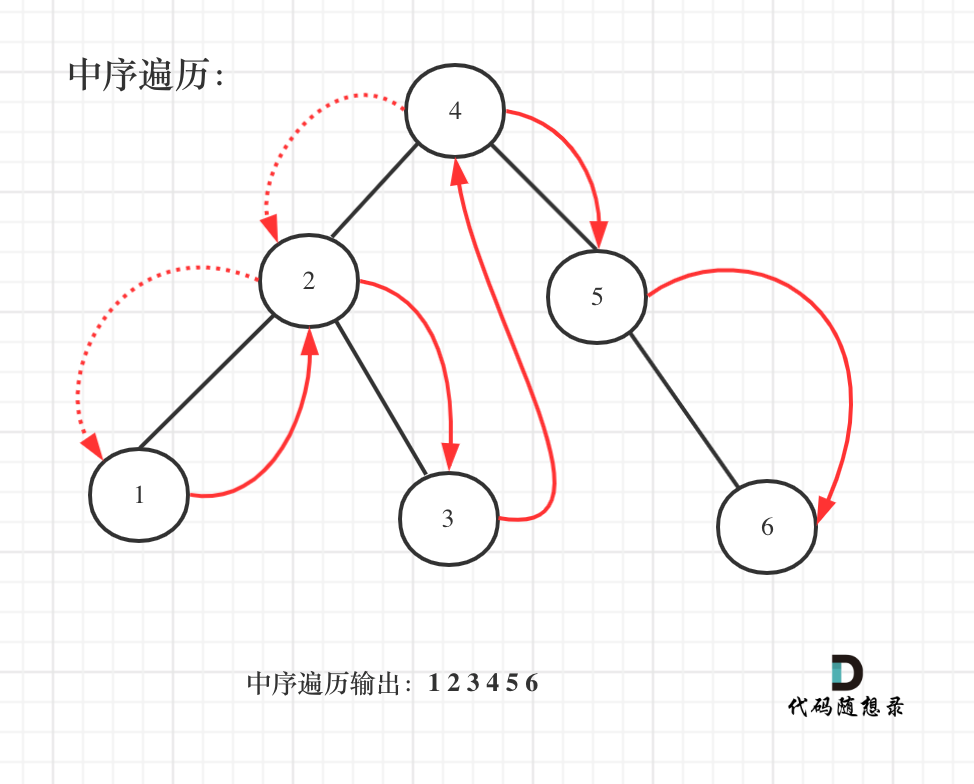
在二叉树:搜索树的最小绝对差 (opens new window)中我们就使用了pre指针和cur指针的技巧,这次又用上了。
弄一个指针指向前一个节点,这样每次cur(当前节点)才能和pre(前一个节点)作比较。
而且初始化的时候pre = NULL,这样当pre为NULL时候,我们就知道这是比较的第一个元素。
此时又有问题了,因为要求最大频率的元素集合(注意是集合,不是一个元素,可以有多个众数),如果是数组上大家一般怎么办?
应该是先遍历一遍数组,找出最大频率(maxCount),然后再重新遍历一遍数组把出现频率为maxCount的元素放进集合。(因为众数有多个)
这种方式遍历了两遍数组。
那么我们遍历两遍二叉搜索树,把众数集合算出来也是可以的。
但这里其实只需要遍历一次就可以找到所有的众数。
那么如何只遍历一遍呢?
如果 频率count 等于 maxCount(最大频率),当然要把这个元素加入到结果集中(以下代码为result数组)
result怎么能轻易就把元素放进去了呢,万一,这个maxCount此时还不是真正最大频率呢。
所以下面要做如下操作:
频率count 大于 maxCount的时候,不仅要更新maxCount,而且要清空结果集(以下代码为result数组),因为结果集之前的元素都失效了。
4代码
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
//对任何二叉树都适用的传统方法
class Solution {
public:
void searchBST(TreeNode* cur, unordered_map<int,int>& map) {
if (cur == nullptr) return ;
map[cur->val]++; //统计元素频率
searchBST(cur->left, map);
searchBST(cur->right, map);
return ;
}
bool static cmp (const pair<int, int>& a, const pair<int, int>& b) {
return a.second > b.second;
}
vector<int> findMode(TreeNode* root) {
unordered_map<int, int> map; //key:元素,value:出现的频率
vector<int> result;
if (root == nullptr) return result;
searchBST(root, map);
vector<pair<int, int>> vec(map.begin(), map.end());
sort(vec.begin(), vec.end(), cmp); //给频率排序
result.push_back(vec[0].first);
for (int i = 1; i < vec.size(); i++) {
//取最高的放到result数组中
if (vec[i].second == vec[0].second) result.push_back(vec[i].first);
else break;
}
return result;
}
};
//双指针(pre & cur)法
class Solution {
public:
int count = 0;
int maxCount = 0;
TreeNode* pre = nullptr;
vector<int> result;
void traversal (TreeNode* cur) {
if (cur == nullptr) return ;
//左
traversal(cur->left);
//中
if (pre == nullptr) count = 1;
else if (cur->val == pre->val) count++; //cur节点与pre节点数值相同,计数+1
else count = 1; //cur节点与pre节点数值不相同,重置cur->val的计数
pre = cur; //双指针依次后移
if (count == maxCount) result.push_back(cur->val);// 如果和最大值相同,放进result中
if (count > maxCount) {
maxCount = count; //更新最大频率
result.clear(); //清空result数组中储存的所有最大元素,因为找到了更大的
result.push_back(cur->val); //把这个更大的元素放入result数组
}
//右
traversal(cur->right);
return ;
}
vector<int> findMode(TreeNode* root) {
traversal(root);
return result;
}
};