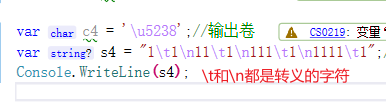
提示一下:我这个中一些用import引用的软件包,你们小白记得要下载哟
不然的话会报错的哟!
下载软件包很简单的!

话不多说,直接开始…
from selenium.webdriver.common.by import By
from selenium import webdriver
import re, requests, csv
from bs4 import BeautifulSoup
from time import sleep
为了打印字典好看
from pprint import pprint
不是很好 有些没有提取到 后面再优化吧
def read(url, headers):
# opens = webdriver.ChromeOptions()
# opens.add_experimental_option(‘detach’, True)
driver = webdriver.Chrome()
driver.get(url=url)
# 自动翻页
for x in range(1, 40, 4): # 1 3 5 7 9 在你不断的下拉过程中, 页面高度也会变的
sleep(1)
j = x / 9 # 1/9 3/9 5/9 9/9
# document.documentElement.scrollTop 指定滚动条的位置
# document.documentElement.scrollHeight 获取浏览器页面的最大高度
js = ‘document.documentElement.scrollTop = document.documentElement.scrollHeight * %f’ % j
driver.execute_script(js)
# 发起get请求
r = requests.get(url=url, headers=headers)
r.encoding = r.apparent_encoding
text = r.text
# 要用记得改路径
fliename = “D:\Python编译器\数据分析\jd.html”
# 建三个空列表把内容放进去
list_moeny = []
list_phone = []
list_soup = []
# 保存成一个html文件 方便使用bs4进行数据分析
with open(fliename, “w”, encoding=‘utf-8’) as fp:
fp.write(text)
fp.close()
# bs4
‘’’
别问为什么不用其他的提取方法
因为我发现只有用bs4提取代码最少
但是bs4提取不完整
无所谓 谁用谁改
‘’’
dome = open(fliename, encoding=“utf-8”)
soup = BeautifulSoup(dome, ‘html.parser’)
# 手机价格
def money():
money_text = soup.find_all(attrs={"class": "p-price"})
re_h = re.findall("<i.*?data-price=.*?>(.*?)</i>", str(money_text), re.S)
for v in re_h:
list_moeny.append(v)
# 手机型号
def phone_texts():
phone_text = soup.find_all(attrs={"class": "p-name p-name-type-2"})
brands = re.findall("<i.*?class=.*?id=.*?>(.*?)</i>", str(phone_text), re.S)
for p in brands:
list_phone.append(p)
# 店铺名称
def soup_text():
souptext = soup.find_all(attrs={"class": "curr-shop hd-shopname"})
re_h = re.findall("<a.*?class=.*?href=.*?onclick=.*?target=.*?title=.*?>(.*?)</a>", str(souptext), re.S)
for s in re_h:
list_soup.append(s)
money()
phone_texts()
soup_text()
driver.quit()
# dicts={}
# 把数据以字典的形式写入csv
def write():
with open("D:\Python编译器\数据分析\\京东商品信息.csv", "w", encoding='utf-8', newline='') as fp:
head = ["手机型号", "店铺信息", "价格"]
writer = csv.DictWriter(fp, fieldnames=head)
writer.writeheader()
for a, b, c in zip(list_phone, list_soup, list_moeny):
dicts = {"手机型号": a, "店铺信息": b, "价格": c}
writer.writerow(dicts)
fp.close()
write()
程序主函数
if name == ‘main’:
url = ‘https://search.jd.com/Search?keyword=%E5%8D%8E%E4%B8%BAp40&enc=utf-8&suggest=1.his.0.0&wq=&pvid=275fb84df1f341d99a8e35ca03088396’
headers = {
‘referer’: ‘https://www.jd.com/’,
‘user-agent’: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36’,
‘upgrade-insecure-requests’: ‘1’,
}
read(url, headers)
谢谢观看,制作不易,不喜勿喷