前言
- 代码来自哔哩哔哩博主deep_thoughts,视频地址,该博主对深度学习框架方面讲的非常详细,推荐大家也去看看原视频,不管是否已经非常熟练,我相信都能有很大收获。
- 论文An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale,下载地址。开源项目地址
- 本文不对开源项目中代码进行解析,仅使用
pytorch实现ViT框架,让大家对框架有更清楚的认知。
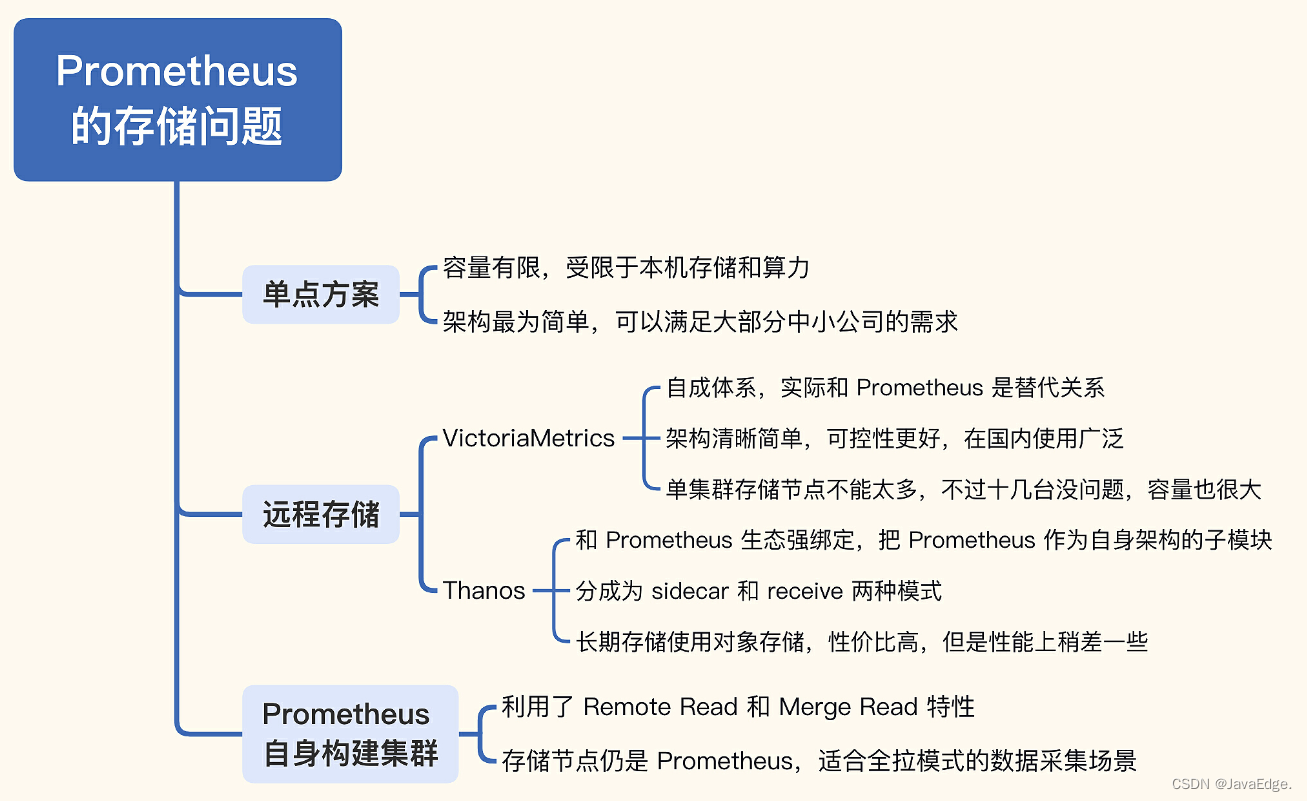
模型框架展示

Encoder部分和Transformer中的实现方法一致,可以直接调用pytorch中的API实现(博主在前面几个视频中使用pytorch逐行写了decoder和encoder,再次推荐大家去看他的视频),下面主要针对左边的部分进行实现。- 架构思维导图,如下图
-
- 导入必要包
import torch
import torch.nn as nn
import torch.nn.functional as F
- 定义初始变量
# batch_size, 输入通道数,图像高,图像宽
bs, ic, image_h, image_w = 1, 3, 8, 8
# 分块边长
patch_size = 4
# 输出通道数
model_dim = 8
# 最大子图片块数
max_num_token = 16
# 分类数
num_classes = 10
# 生成真实标签
label = torch.randint(10,(bs,))
# 卷积核面积 * 输入通道数
patch_depth = patch_size * patch_size * ic
# image张量
image = torch.randn(bs, ic, image_h, image_w)
# model_dim:输出通道数,patcg_depth:卷积核面积 * 输入通道数
weight = torch.randn(patch_depth, model_dim)
perspective
- 这一部分有两种实现方式,第1种是
DNN方式,利用pytorch中的unfold函数滑动提取图像块。第2种是使用2维卷积的方法,最后将特征铺平。
DNN perspective
- 首先使用
unfold函数,滑动提取不重叠的块,所以kernel_size和stride相同。 - 再与
weight进行矩阵相乘,维度变化以及每个维度意义都在注释中。
def image2emb_naive(image, patch_size, weight):
# patch:[batch_size, patch_size * patch_size * ic, (image_h * image_w) / (patch_size * patch_size)]
patch = F.unfold(image, kernel_size=patch_size,stride=patch_size)
# 转置操作[batch_size, (image_h * image_w) / (patch_size * patch_size), patch_size * patch_size * ic]]
patch = patch.transpose(-1, -2)
# 矩阵乘法weight:[patch_size * patch_size * ic, model_dim]
patch_embedding = patch @ weight
return patch_embedding
- 调用函数,得到
patch_embedding,检查维度
# 得到patch_embedding:[batch_size, (image_h * image_w) / (patch_size * patch_size), model_dim]
patch_embedding_naive = image2emb_naive(image, patch_size, weight)
print(patch_embedding_naive.shape)
输出:
torch.Size([1, 4, 8])
CNN perspective
def image2emb_conv(image, kernel, stride):
conv_output = F.conv2d(image, kernel, stride = stride)
bs, oc, oh, ow = conv_output.shape
# patch_embedding:[batch_size, outchannel, o_h * o_w]
patch_embedding = conv_output.reshape((bs, oc, oh*ow))
print(patch_embedding.shape)
# patch_embedding:[batch_size, o_h * o_w, outchannel]
patch_embedding = patch_embedding.transpose(-1,-2)
print(patch_embedding.shape)
return patch_embedding
weight = weight.transpose(0,1)
print(weight.shape)
# kernel:[outchannel, inchannel, patch_size, patch_size]
kernel = weight.reshape((-1,ic, patch_size, patch_size))
print(kernel.shape)
patch_embedding_conv = image2emb_conv(image, kernel, patch_size)
print(patch_embedding_conv.shape)
输出:
torch.Size([8, 48])
torch.Size([8, 3, 4, 4])
torch.Size([1, 8, 4])
torch.Size([1, 4, 8])
torch.Size([1, 4, 8])
class token embedding
- 随机生成
cls_token_emnedding,并将其设为可训练参数。沿着图片块数维度进行拼接,检查cls_token_emnedding,token_embedding维度。
# CLS token embedding
# cls_token_emnedding:[batch_size,1,mode_dim]
cls_token_emnedding = torch.randn(bs, 1, model_dim, requires_grad=True)
# 沿着图片块数维度进行拼接
token_embedding = torch.cat([cls_token_emnedding, patch_embedding_naive], dim=1)
print(cls_token_emnedding.shape)
print(token_embedding.shape)
输出:
torch.Size([1, 1, 8])
torch.Size([1, 5, 8])
position embedding
- 创建
pos embedding:[max_num_token,model_dim],然后使用tile函数进行增自我拼接,重复batch_size次。
# add position embedding
# 创建pos embedding:[max_num_token,model_dim]
position_embedding_table = torch.randn(max_num_token, model_dim, requires_grad = True)
# 取图片块数维度
seq_len = token_embedding.shape[1]
# tile增自我拼接,dims参数指定每个维度中的重复次数,dims = [batch_size,1,1]
position_embedding = torch.tile(position_embedding_table[:seq_len], [token_embedding.shape[0],1,1])
print(position_embedding.shape)
Transformer Encoder部分
- 实例化
TransformerEncoderLayer,再实例化TransformerEncoder,得到Encoder输出。
# pass embedding to Transformer Encoder
encoder_layer = nn.TransformerEncoderLayer(d_model=model_dim,nhead=8)
transformer_encoder = nn.TransformerEncoder(encoder_layer, num_layers=6)
enconder_output = transformer_encoder(token_embedding)
print(enconder_output.shape)
classification head
- 取出
pos embedding维,经过线性层,对输出计算交叉熵损失
# 取出第1个图片块数维度,就是pos embedding维
cls_token_output = enconder_output[:,0,:]
# 实例化线性层model_dim --> num_classes
linear_layer = nn.Linear(model_dim, num_classes)
# 得到线性层输出
logits = linear_layer(cls_token_output)
# 交叉熵损失
loss_fn = nn.CrossEntropyLoss()
# 计算交叉熵损失
loss = loss_fn(logits,label)
print(loss)