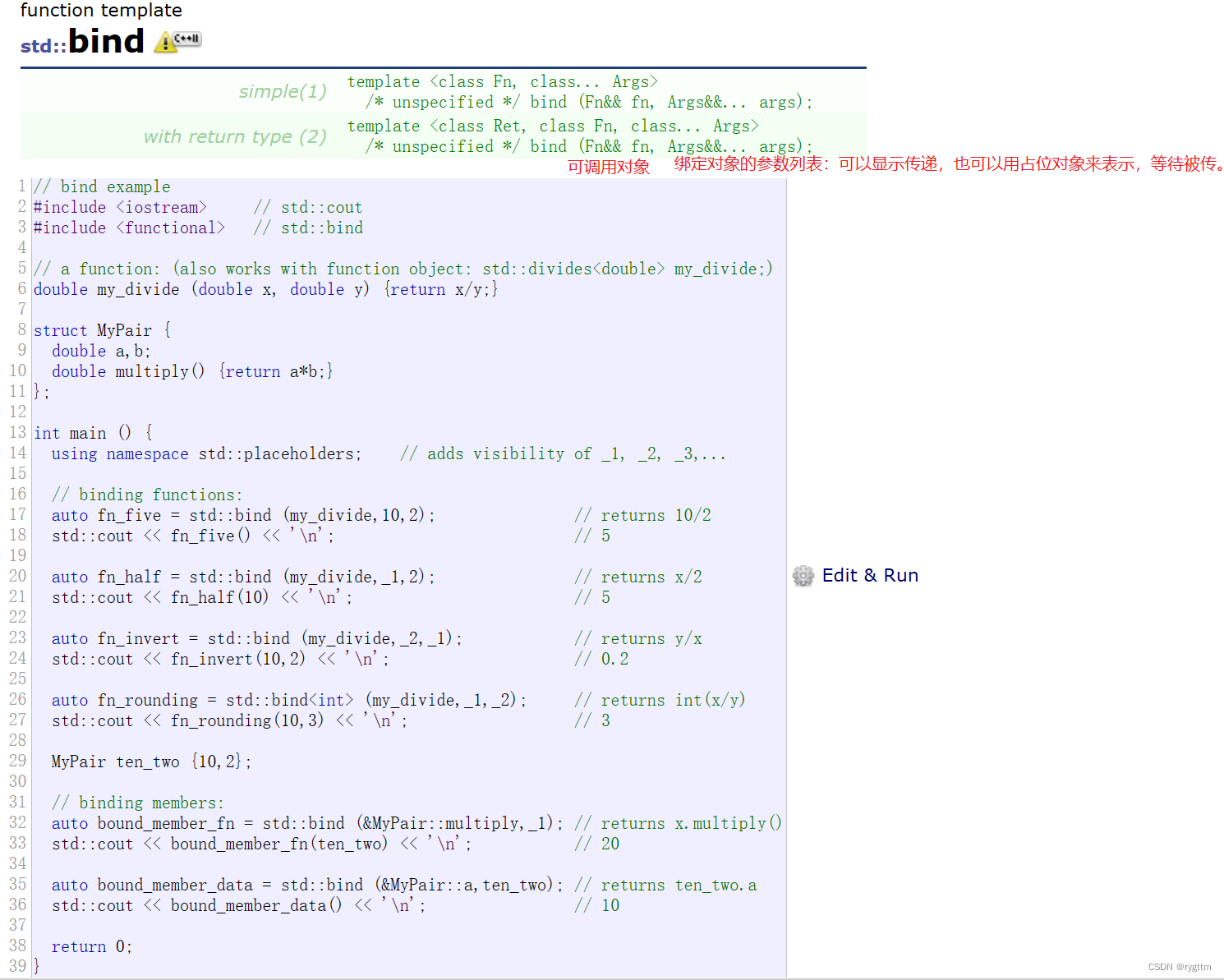
Depression mediated the relationships between precentral-subcortical causal links and motor recovery in spinal cord injury patients
手动防爬虫,原创作者CSDN:总是重复名字我很烦啊,联系邮箱daledeng123@163.com
直达原文
这是一篇收录在神经科学领域一区期刊Cerebral Cortex的文章。文章主要研究的是抑郁是否会阻碍脊椎损伤(SCI)患者的运动恢复。
题目
文章题目很明确,Depression mediated(抑郁导致) precentral-subcortical causal links(大脑里一个叫做precentral-subcortical的区域的因果关系)和motor recovery in spinal cord injury patients(SCI患者的运动功能恢复)。所以说文章研究涉及两个内容,一个是抑郁和precentral-subcortical区域的因果关系;抑郁和SCI患者的运动功能恢复的关系。
Introduction
在引言部分,文章介绍了SCI患者可能出现心理抑郁的情况,并且抑郁会导致运动功能恢复受损。并且有足量的研究表明,大脑里NAcc这个区域作为运动中枢,在SCI患者早期恢复阶段可以促进motor cortex活动,进而使得SCI患者的运动能力得到改善。所以说,抑郁、motor cortex和运动恢复是存在一定联系的。因此接下来文章就想要探究这三者的联系。
在这里,作者的想法是通过格兰杰因果检验的方法判断他们之间的因果关系。在这里简单梳理一下格兰杰因果检验:
Granger causality analysis(GCA,格兰杰因果分析)
自回归
在了解格兰杰因果分析前,需要首先清楚“自回归”的概念。
在这里假设有一个时序数据:
T
=
[
t
1
,
t
2
,
t
3
,
.
.
.
,
t
n
]
T=[t_1,t_2,t_3,...,t_n]
T=[t1,t2,t3,...,tn]
Y
=
[
y
1
,
y
2
,
y
3
,
.
.
.
,
y
n
]
Y=[y_1,y_2,y_3,...,y_n]
Y=[y1,y2,y3,...,yn]
这里的y与t一一对应。
在自回归的概念里,我们认为,若数据存在强时间关联性,那么当前时刻的数据应该是之前历史数据的共同结果。例如,今天下雨,那么大概率是之前云层中水分积累到了一个临界值。
因此,可以提出这样一种对当前时刻的预测表达:
y
t
=
∑
0
n
−
1
a
t
i
y
t
i
+
ε
y_t = \sum_0^{n-1}a_{t_i}y_{t_i}+\varepsilon
yt=0∑n−1atiyti+ε
A
=
[
a
1
,
a
2
,
a
3
,
.
.
.
,
a
n
−
1
]
A=[a_1,a_2,a_3,...,a_{n-1}]
A=[a1,a2,a3,...,an−1]
这里的
a
i
a_i
ai是
y
i
y_i
yi时刻的权重,
ε
\varepsilon
ε是噪声,A是她的权重系数矩阵。
这个公式表达意思是,今天下雨,那么是因为前天积累了60%水分,但是云层活动又消耗10%,昨天积累了70%,消耗了20%,所以今天下雨了。这个积累的水分就是
a
i
y
i
a_iy_i
aiyi,消耗的就是
ε
\varepsilon
ε。
二元自回归
自回归对时序数据的解释似乎很好,因为历史的各种原因的积累,导致了当前时刻的结果。但实际上当前时刻的结果并不是一个原因导致的,可能是各种原因一起作用导致的。例如今天下雨,云层积累的水量是确定相关的,但有没有可能是昨天萧敬腾来过呢,你并不能百分百确定萧敬腾来和下不下雨是否存在联系。没关系,先把这个回归方程写出来:
y
t
=
∑
0
n
−
1
a
t
i
y
t
i
+
∑
0
n
−
1
b
t
i
x
t
i
+
ε
y_t = \sum_0^{n-1}a_{t_i}y_{t_i}+\sum_0^{n-1}b_{t_i}x_{t_i}+\varepsilon
yt=0∑n−1atiyti+0∑n−1btixti+ε
B
=
[
b
1
,
b
2
,
b
3
,
.
.
.
,
b
n
−
1
]
B=[b_1,b_2,b_3,...,b_{n-1}]
B=[b1,b2,b3,...,bn−1]
接下来判断这个x是否与y构成相关。显然,如果x不影响y,那么B=[0,0,0,…,0]即可。
原假设H0:B=[0,0,0,…,0];H1:B不全为0。
统计量
F
=
(
R
S
S
r
−
R
S
S
u
)
/
m
R
S
S
u
/
(
n
−
(
m
+
s
)
)
,临界值
F
(
m
,
n
−
(
m
+
s
)
)
统计量F=\frac{(RSS_r-RSS_u)/m}{RSS_u/(n-(m+s))},临界值F(m,n-(m+s))
统计量F=RSSu/(n−(m+s))(RSSr−RSSu)/m,临界值F(m,n−(m+s))
若统计量F>临界值F则拒绝原假设,称x为y的格兰杰原因。
这里
R
S
S
r
RSS_r
RSSr表示有约束模型的残差平方和,也就是自回归模型的残差平方和,
R
S
S
u
RSS_u
RSSu表示无约束模型的残差平方和,也就是无约束的残差平方和,m是x的滞后期数,s是协率个数。
代码实现(以python为例)
from statsmodels.tsa.stattools import grangercausalitytests as GCA
import pandas as pd
import numpy as np
# 随机数据验证
# 创建一个两个array,分别有20个范围在0-50随机数据
df = pd.DataFrame(np.random.randint(0, 50, size=(20, 2)), columns=['y', 'x'])
# 这里的maxlag就是滞后期数
GCA(df[['y', 'x']], maxlag=2)

这里我们只需要关注p这一列的结果,必须所有的p都小于0.05才能证明x会影响y。
Output paramters:
number of lags 1/2: 当lags为1/2时的检测结果
ssr based F test: 残差平方和F检验
ssr based chi2 test: 残差平方和卡方检验
likelihood ratio test: 似然比检验
parameter F test: 参数F检验结果
接下来我们换一个具有相关性的人造数据看看结果:
x = np.random.rand(1, 10)
y = np.random.rand(1, 10)
y += x * np.random.rand(1,10)
df = pd.DataFrame({'y':y[0,:], 'x':x[0,:]}, columns=['y', 'x'])
GCA(df[['y', 'x']], maxlag=2)

在这种情况下,就说明x对y的预测确实有帮助,拒绝原假设,x与y有一定的内在联系。
(uploading……)