3.最近很多工作好像都绕不开lora,无论是sd还是llm....
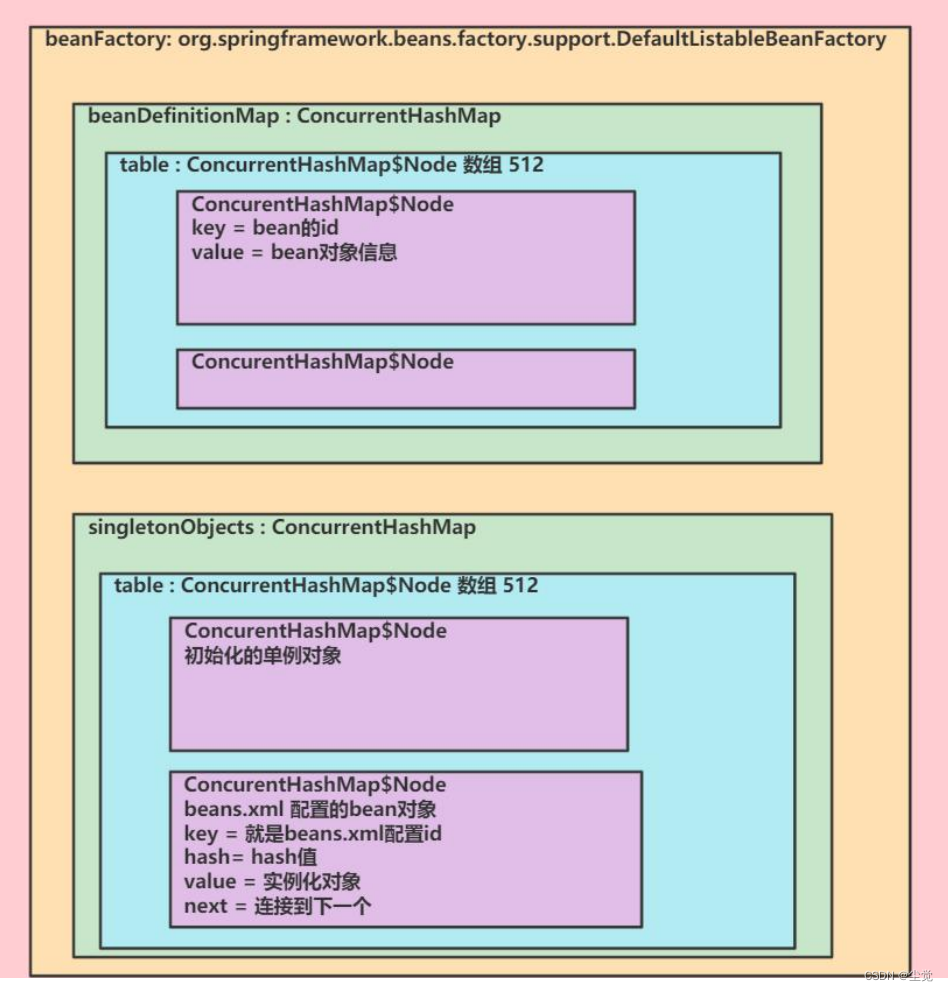
1. 背景
- 问题:大模型重新训练所有模型参数的完全微调变得不太可行。
- lora在做什么
我们提出了低秩自适应,即LoRA,它冻结预先训练的模型权重,并将可训练的秩分解矩阵注入Transformer架构的每一层
- 为什么work?
学习过的参数化模型实际上存在于较低的内在维度上,因此假设模型自适应过程中权重的变化也具有较低的“内在秩”。LoRA允许我们通过优化适应过程中密集层变化的秩分解矩阵来间接训练神经网络中的一些密集层,同时保持预先训练的权重冻结
该结论基于Measuring the Intrinsic Dimension of Objective Landscapes和Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning
2.目前的解决办法
在大规模和延迟敏感的生产场景中有比较大的局限性
3.LORA
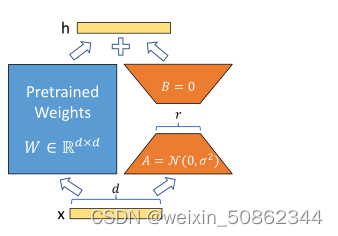
对于预训练的权重矩阵W0∈Rd×k,我们通过用低秩分解W0+∆W=W0+BA表示后者来约束其更新,其中B∈Rd×r,a∈Rr×k,秩r是d,k的较小值
3.1 低秩分解
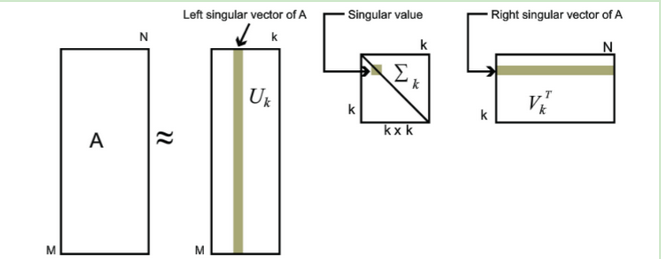
低秩分解是一种将一个矩阵分解为两个或多个较低秩矩阵的方法。具体来说,给定一个矩阵A,低秩分解将其分解为两个矩阵U和V的乘积,其中U和V的秩均比A的秩小,且乘积矩阵与原矩阵相等。
一个比较直观的例子就是SVD
3.2 应用到 transform
在Transformer架构中,自注意模块中有四个权重矩阵(Wq、Wk、Wv、Wo),MLP模块中有两个。我们将Wq(或Wk,Wv)视为维度×
的单个矩阵,即使输出维度通常被划分为注意力头部。
仅调整下游任务的注意力权重,并冻结MLP模块(因此它们不在下游任务中训练)