一、Kettle 输入输出算子介绍
上篇文章对 Kettle 进行了简单的介绍及做了个简单的案例,但是对 Kettle 的Step算子工具没有做过多的解释,本篇文章从输入输出算子工具开始进行介绍。
下面是上篇文章的地址:
ETL工具 - Kettle 介绍及基本使用
二、输入算子介绍
输入是转换里面的第一个分类,用来完成 ETL 中的 E 抽取数据或者生成数据。在Kettle 中输入算子主要有如下分类:

2.1 CSV文件输入
准备 CSV文件内容如下:
id,name,sex,grade1,grade2,grade3
1,小明,男,90,80,70
2,小红,女,91,81,71
3,小兰,女,92,82,72
4,小爱,女,93,83,73
5,张三,男,94,84,74
6,李四,男,95,85,75
7,王五,男,96,86,76
8,赵六,男,97,87,77
9,小六,男,98,88,78
10,小七,男,99,89,79
拖入一个CSV文件输入:
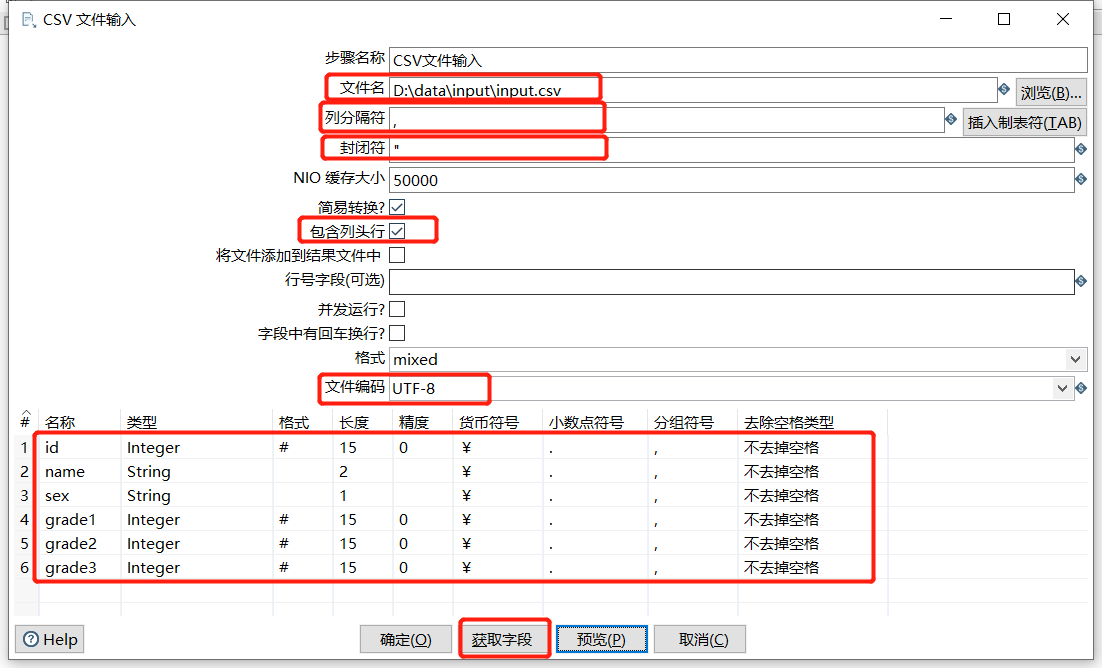
- 步骤名称:在同一个转换里面要保证唯一性
- 文件名:选择对应的
CSV文件 - 列分隔符:默认是逗号
- 封闭符:结束行数据的读写
- NIO缓存大小:文件如果行数过多,需要调整此参数
- 包含列头行:意思是文件中第一行是字段名称行,表头不进行读写
- 行号字段:如果文件第一行不是字段名称或者需要从某行开始读写,可在此输入行号
- 并发运行?:选择并发,可提高读写速度
- 字段中有回车换行?:不选择,会将换行符做数据读出
- 文件编码:如果预览数据出现乱码,可更换文件编码,例如
UTF-8
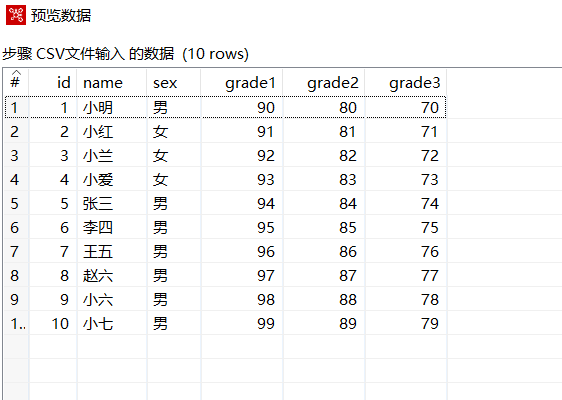
点击预览可以对 CSV数据进行预览:
2.2 文本文件输入
例如有如下文本:
id;name;age
1;张三;20
2;李四;21
3;王五;22
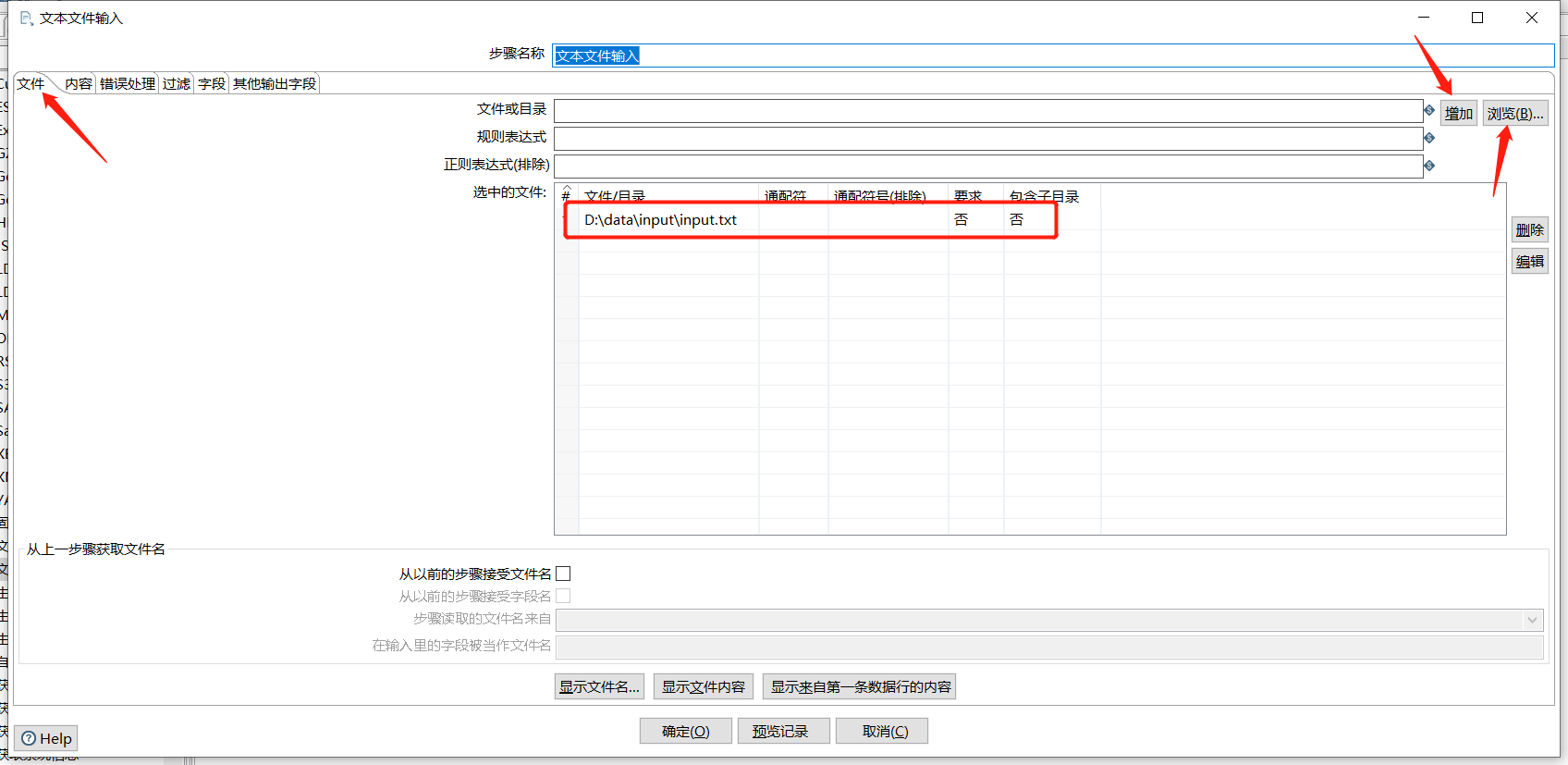
拖入一个文本文件输入:
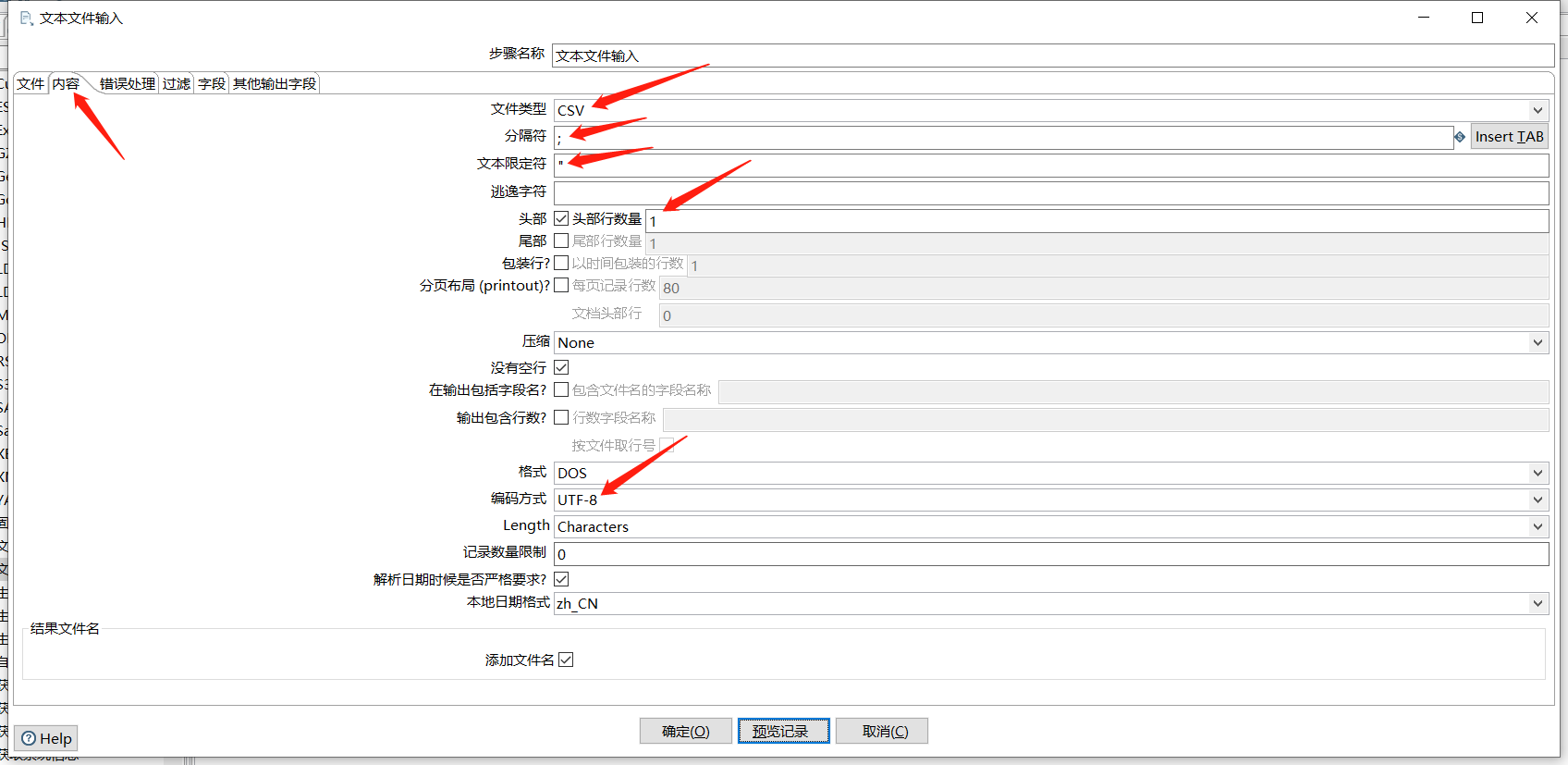
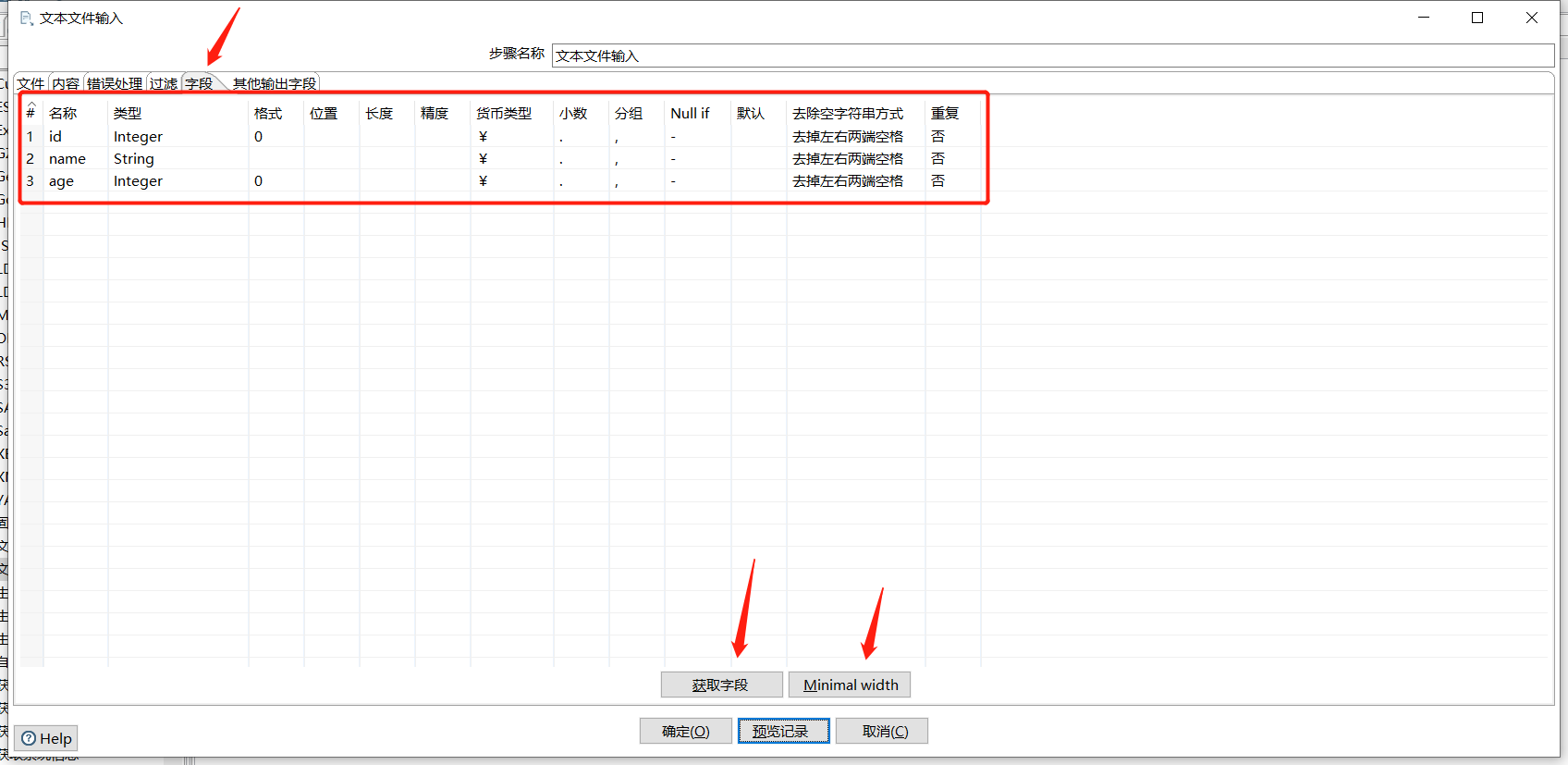
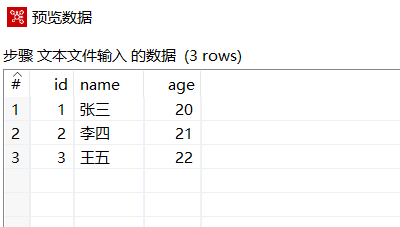
点击预览查看数据:
2.3 Excel输入
例如有如下 Excel :
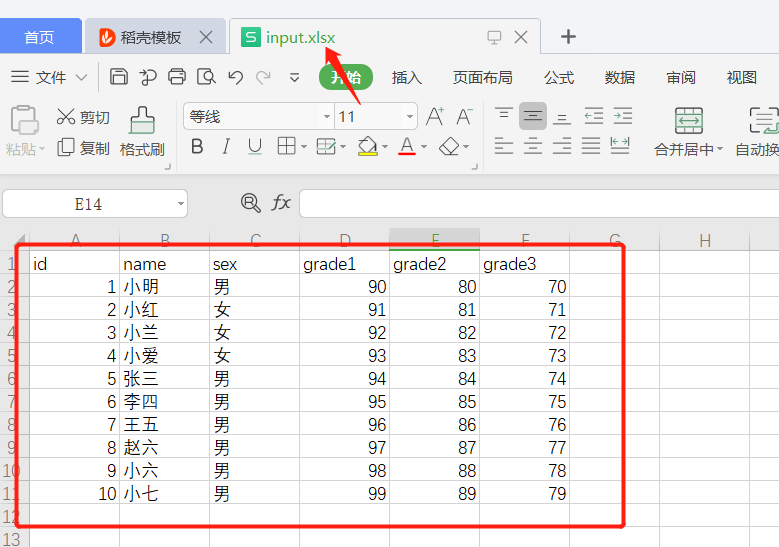
拖入一个 Excel输入:
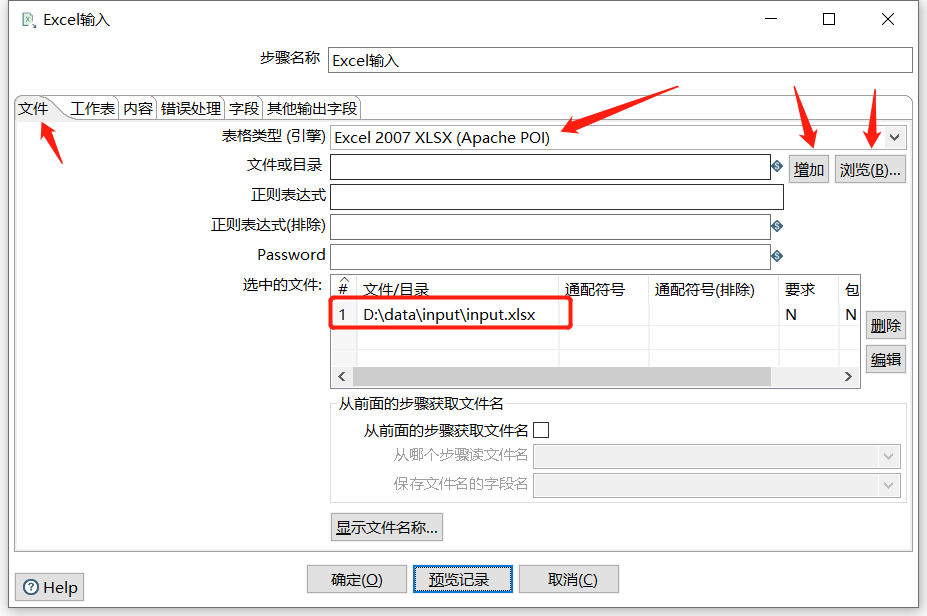
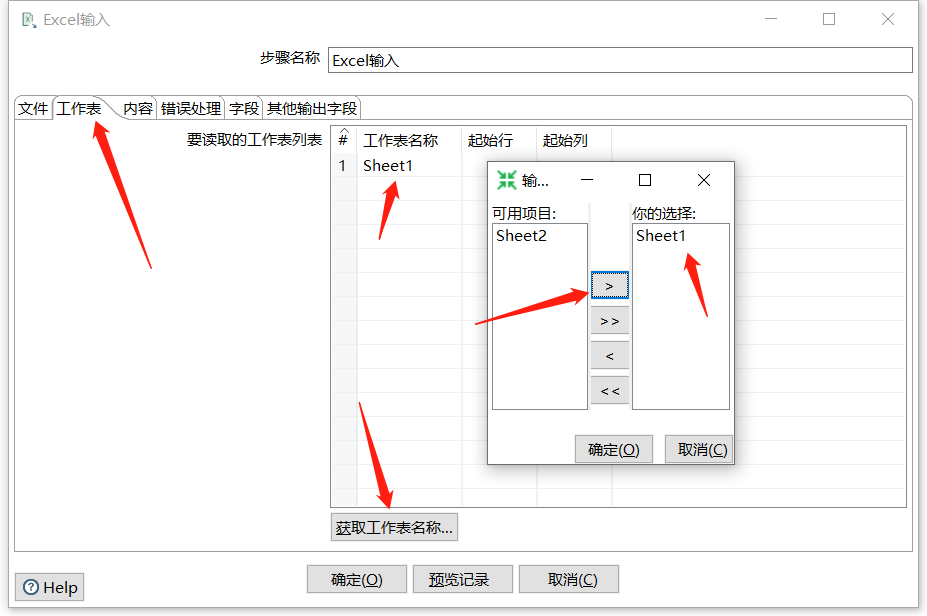
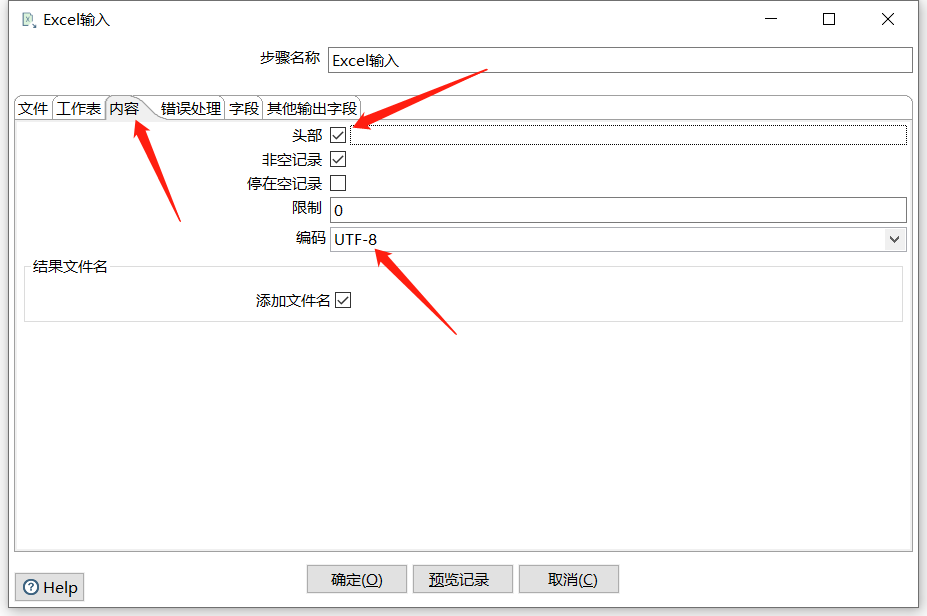
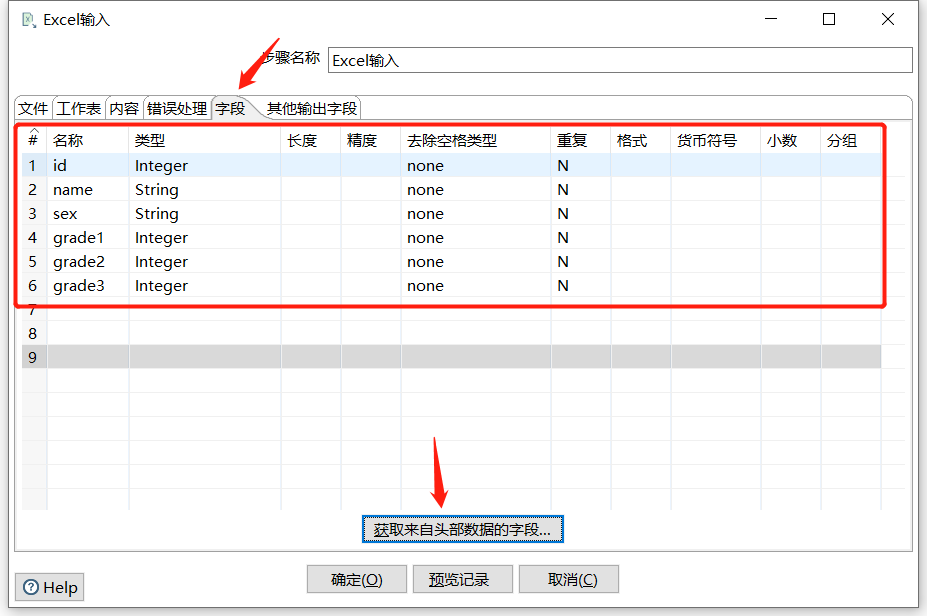
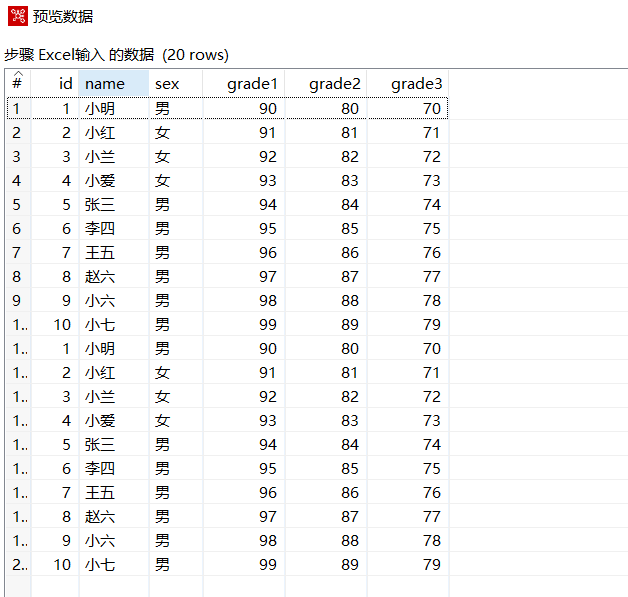
预览数据:
2.4 JSON input
有如下JSON示例数据,解析出 type、name、age、grade 字段
{
"status":200,
"message":"success",
"data":[
{
"type":1,
"data":[
{
"name":"张三",
"age":20,
"grade":90
},
{
"name":"李四",
"age":21,
"grade":88
},
{
"name":"王五",
"age":22,
"grade":70
}
]
},
{
"type":2,
"data":[
{
"name":"小红",
"age":20,
"grade":90
},
{
"name":"小明",
"age":21,
"grade":88
},
{
"name":"小兰",
"age":22,
"grade":70
}
]
}
]
}
JSON 需要了解下 JSON Path 语法:
| 符号 | 描述 |
|---|---|
$ | 查询的根节点对象,用于表示一个json数据,可以是数组或对象 |
@ | 过滤器断言(filter predicate)处理的当前节点对象,类似于java中的this字段 |
* | 通配符,可以表示一个名字或数字 |
.. | 可以理解为递归搜索,Deep scan.Available anywhere a name is required. |
.<name> | 表示一个子节点 |
['<name>'(,'<name>)] | 表示一个或多个子节点 |
[<number>(<number>)] | 表示一个或多个数组下标 |
[start:end] | 数组片段,区间为[start,end),不包含end |
[?(<expression>)] | 过滤器表达式,表达式结果必须是boolean |
例如:
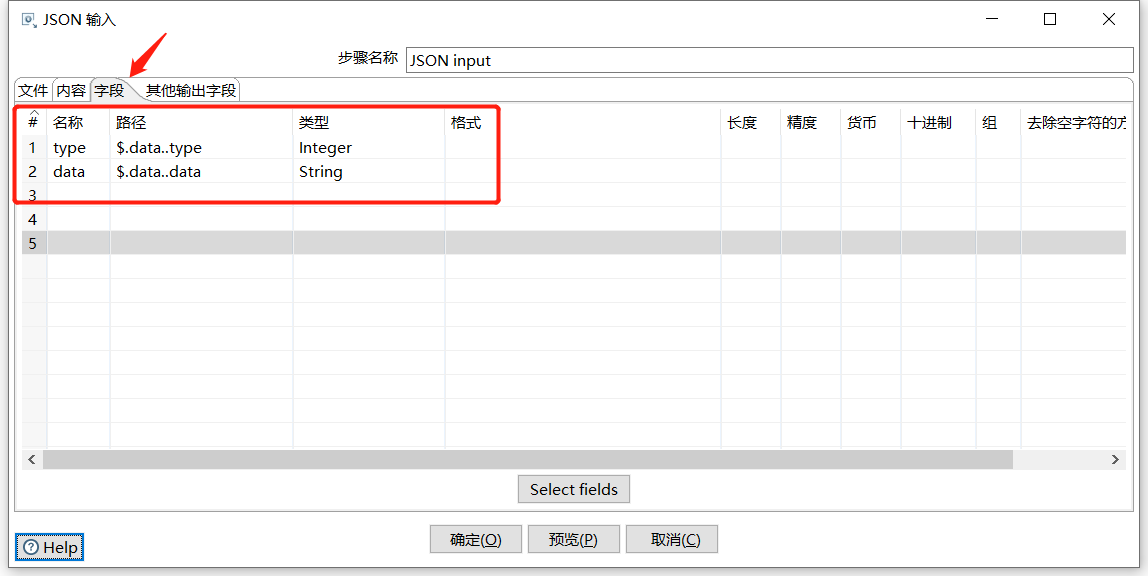
取 type 字段,语法为:$.data..type
取 data.data 信息,语法为:$.data..data
取 name 信息,语法为:$.data..data..name
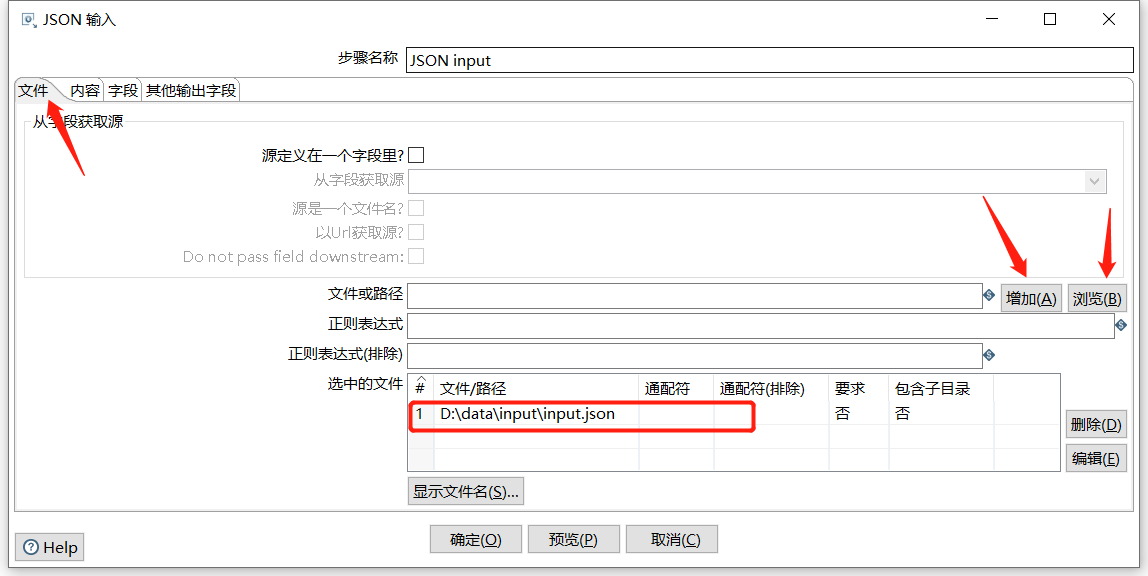
下面先拖入一个 JSON input 解析出 type、data:
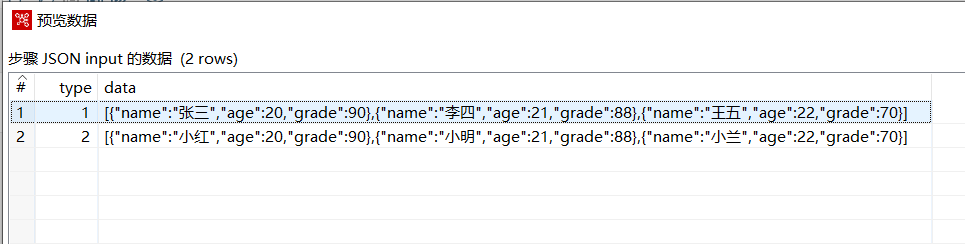
预览下数据:
下面再拖一个 JSON input 解析 data :
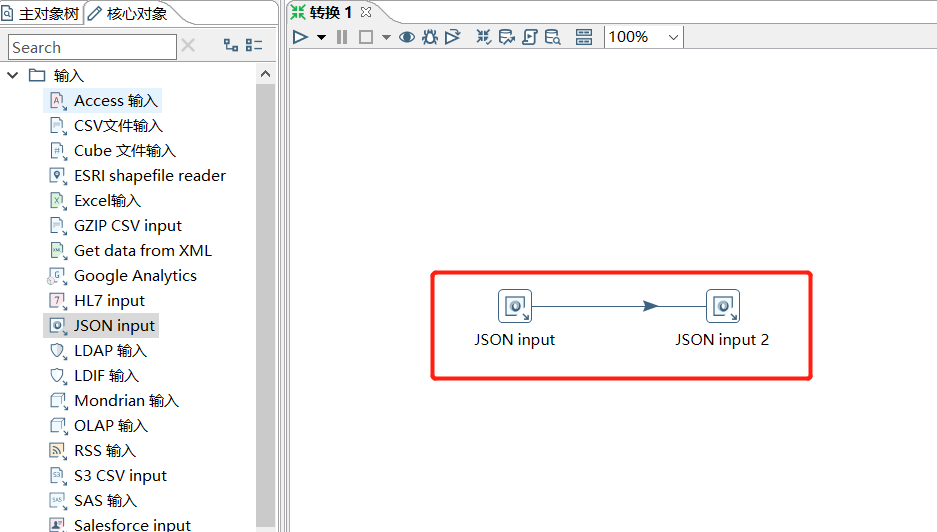
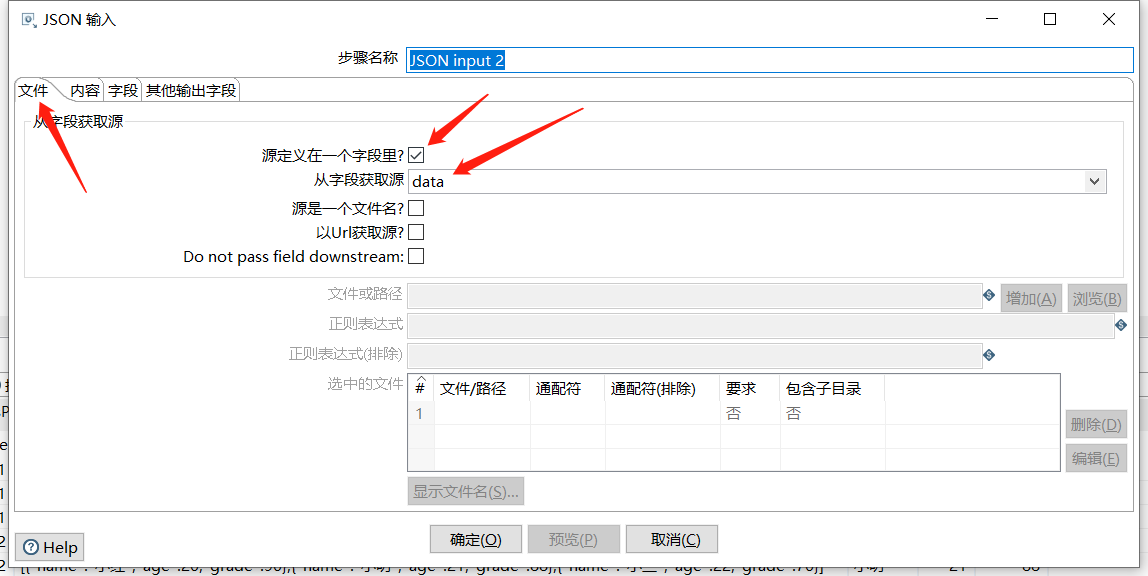
第二个JSON input 内容获取上一个的 data 字段:
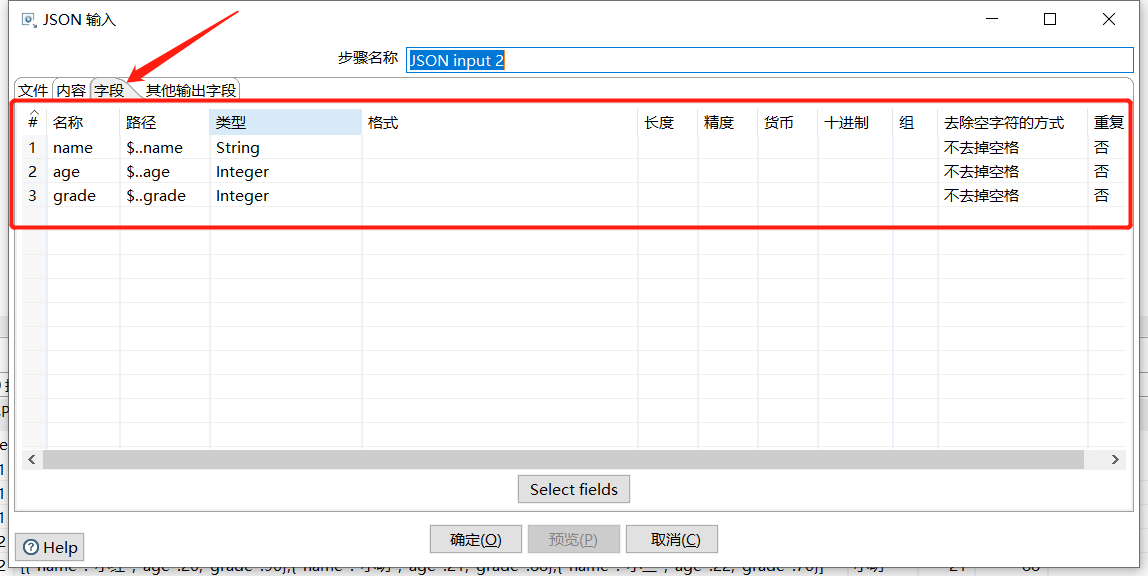
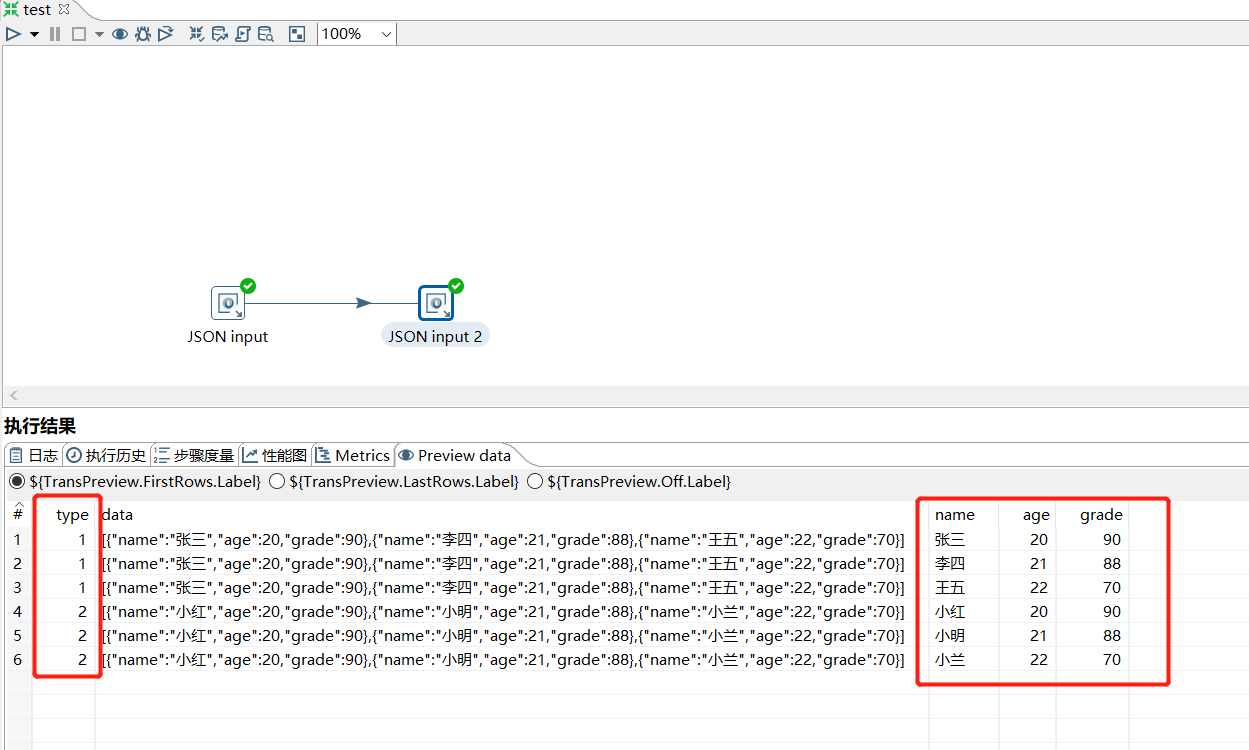
运行转换,查看JSON input2 的结果:
2.5 XML输入
例如有如下 XML信息,解析出 info属性、type属性、name字段、age字段:
<?xml version="1.0" encoding="UTF-8"?>
<data info="datainfo">
<list type="1">
<item>
<name>张三</name>
<age>20</age>
</item>
<item>
<name>李四</name>
<age>21</age>
</item>
</list>
<list type="2">
<item>
<name>王五</name>
<age>22</age>
</item>
<item>
<name>赵六</name>
<age>23</age>
</item>
</list>
</data>
XML 需要了解下 XPath 语法:
| 表达式 | 描述 |
|---|---|
nodename | 选取此节点的所有子节点 |
/ | 从根节点选取 |
// | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置 |
. | 选取当前节点 |
.. | 选取当前节点的父节点 |
@ | 选取属性 |
下面拖入一个 Get data from XML XML 文件输入:
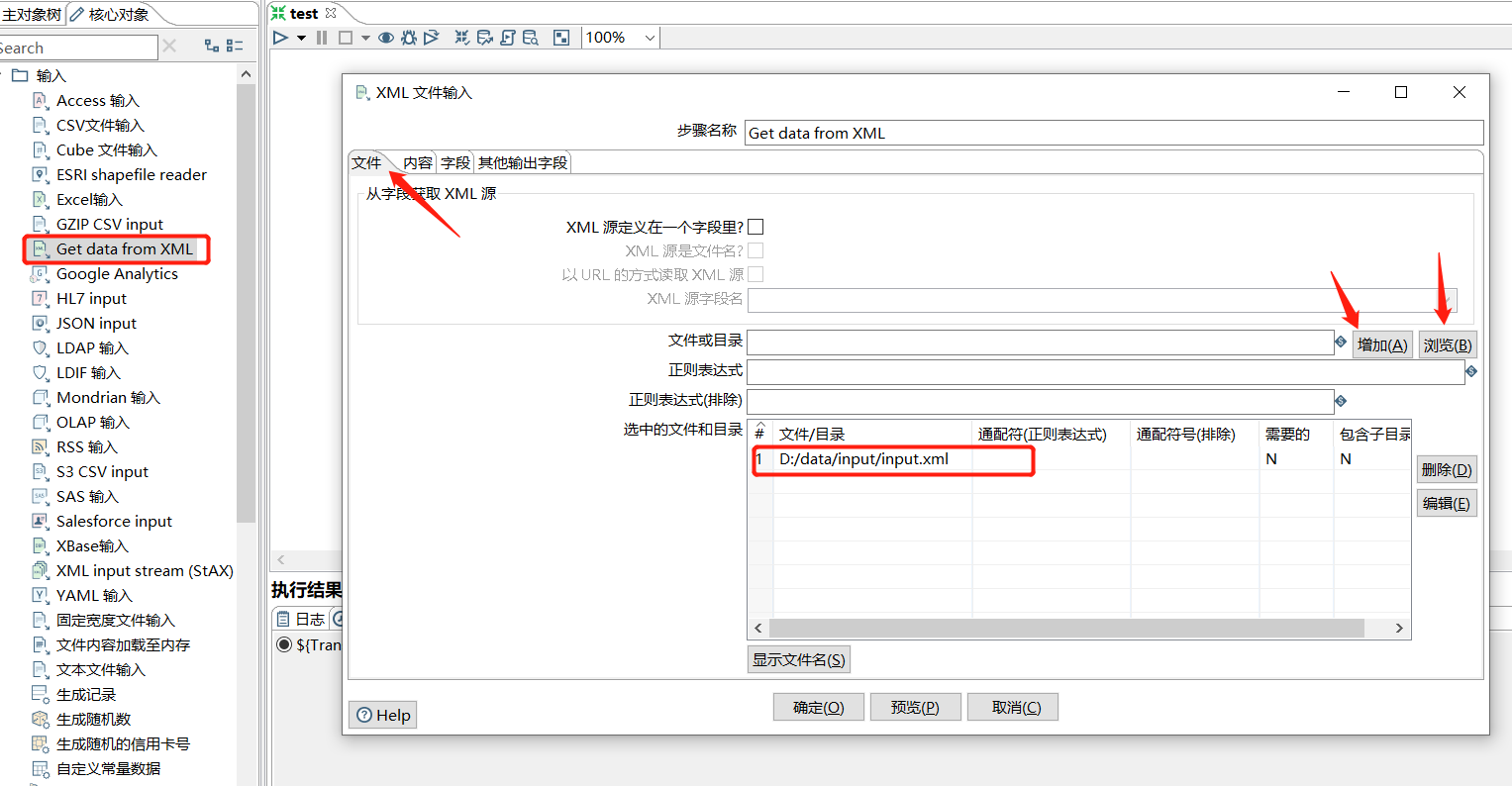
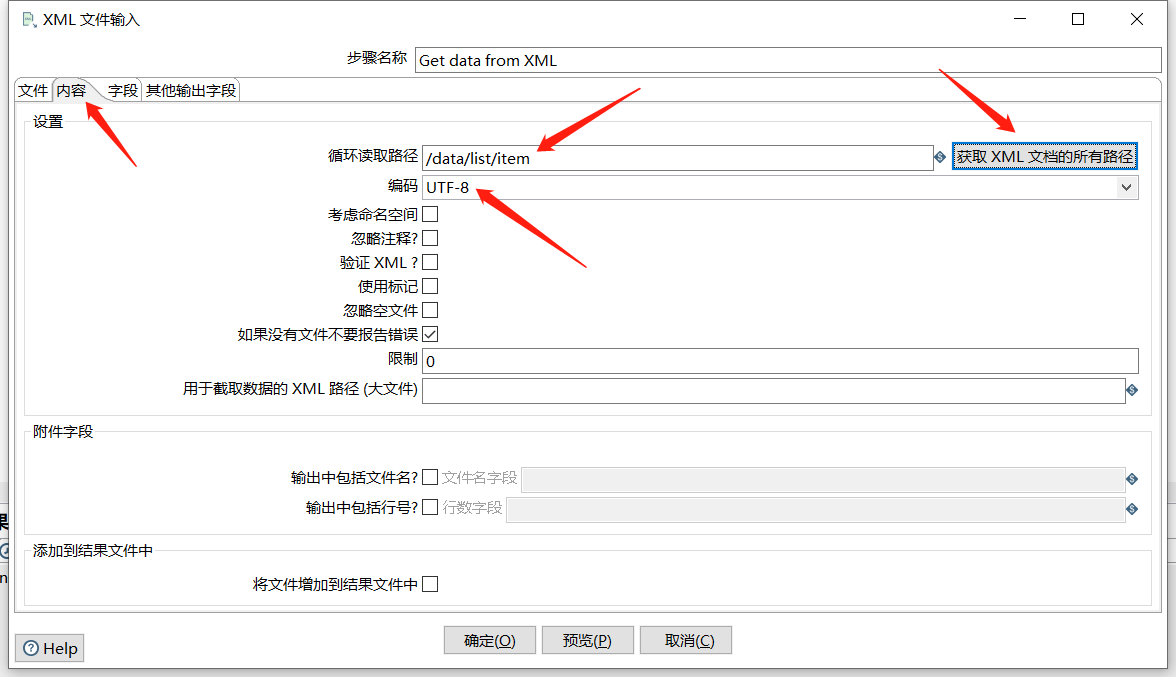
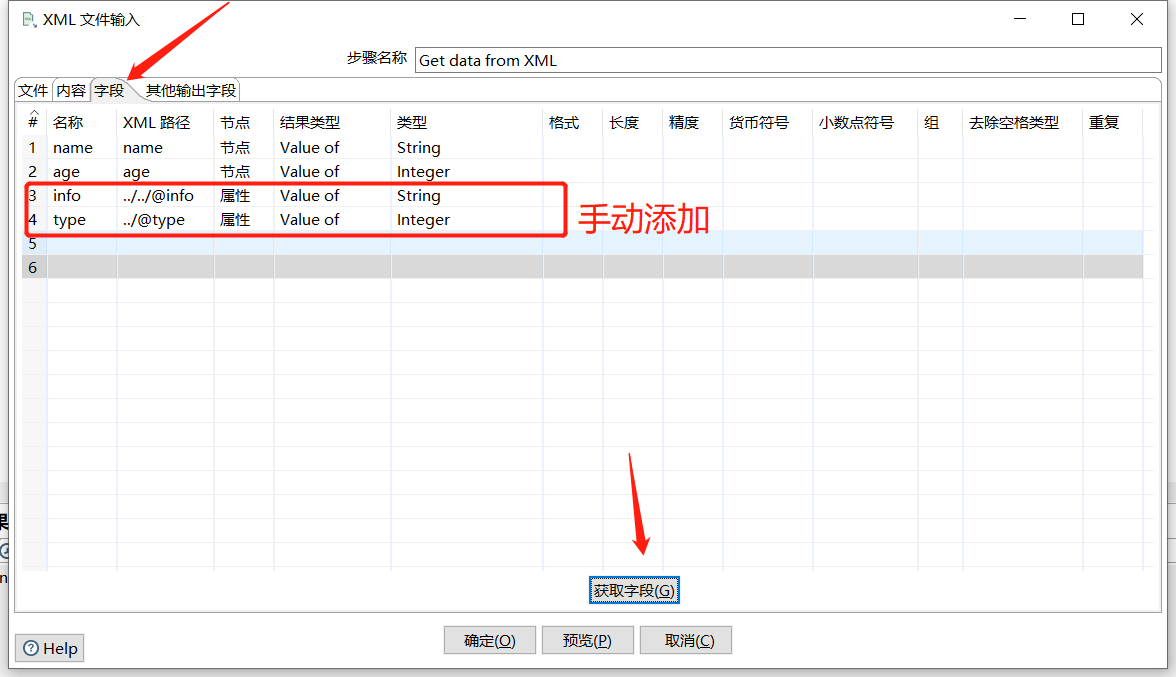
预览下数据:
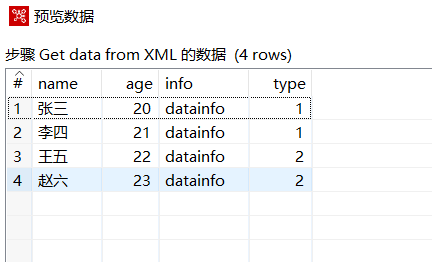
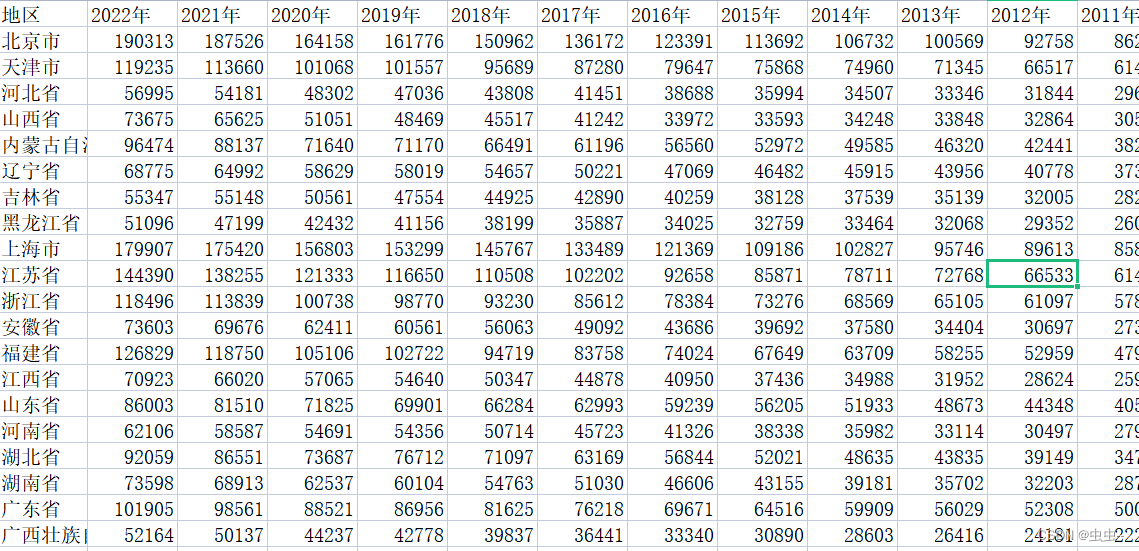
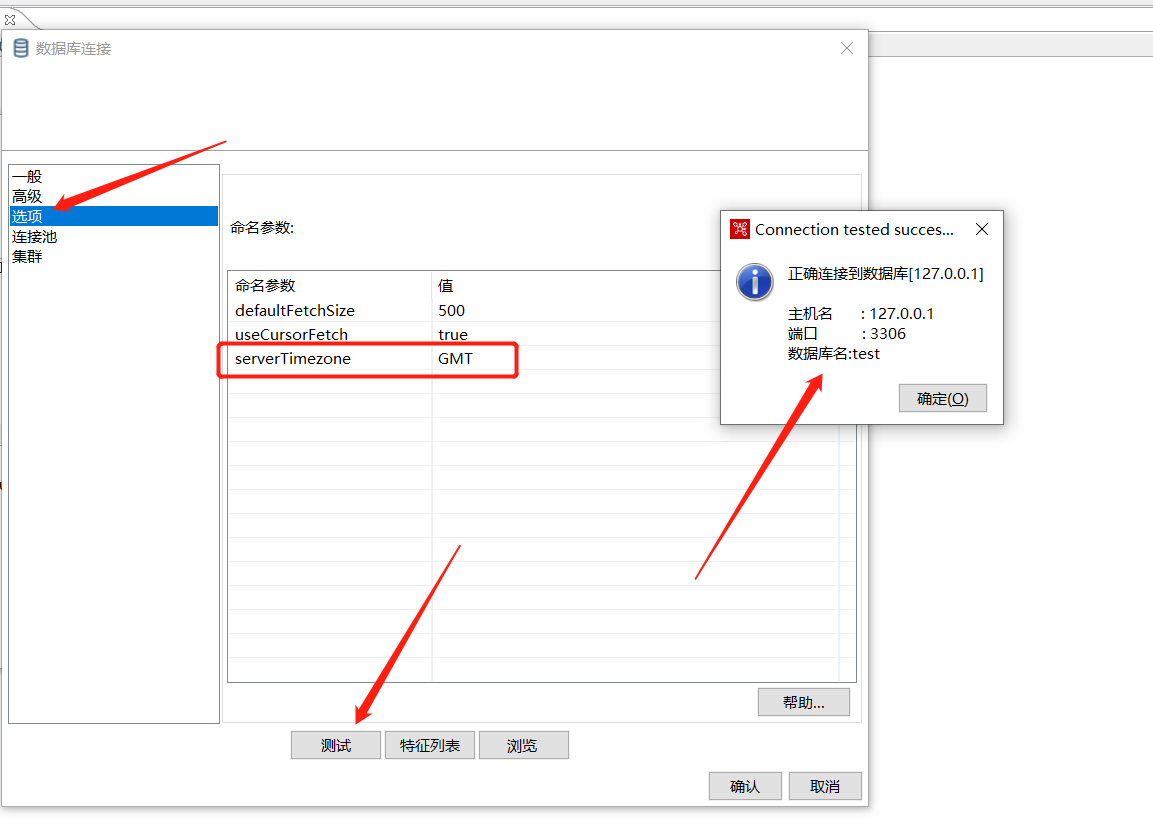
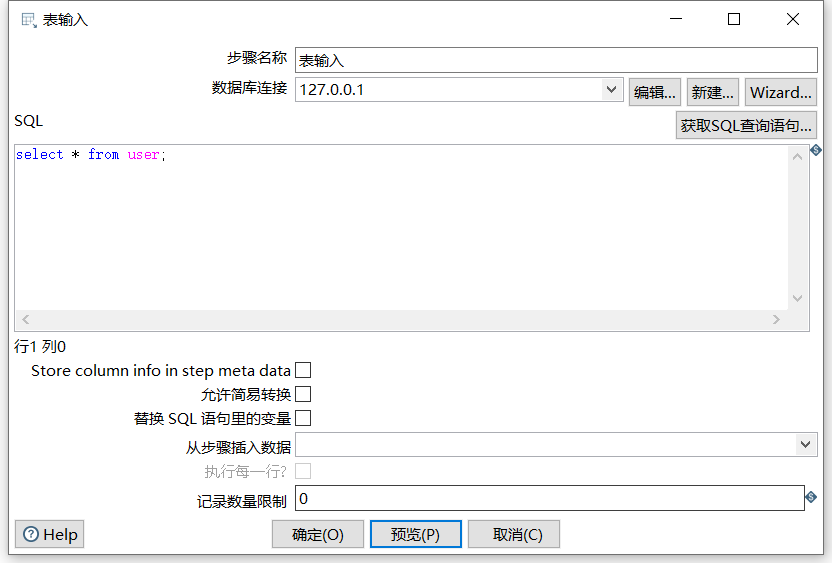
2.6 表输入
表输入用到比较多的一种输入控件,可以连接市面上常见的各种数据库,比如Oracle,Mysql,SqlServer等。但是在连接各个数据库之前,我们需要先配置好对应的数据库驱动,这里以mysql为例:
首先需要将 MySQL 的驱动放到 kettle 安装目录的 lib 下:
例如有如下表和数据:
CREATE TABLE `user` (
`id` int(0) NOT NULL AUTO_INCREMENT,
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL,
`age` int(0) NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;
写入测试数据:
INSERT INTO `user` VALUES (1, '小明', 90);
INSERT INTO `user` VALUES (2, '小红', 91);
INSERT INTO `user` VALUES (3, '小兰', 92);
INSERT INTO `user` VALUES (4, '小爱', 93);
INSERT INTO `user` VALUES (5, '张三', 94);
INSERT INTO `user` VALUES (6, '李四', 95);
INSERT INTO `user` VALUES (7, '王五', 96);
INSERT INTO `user` VALUES (8, '赵六', 97);
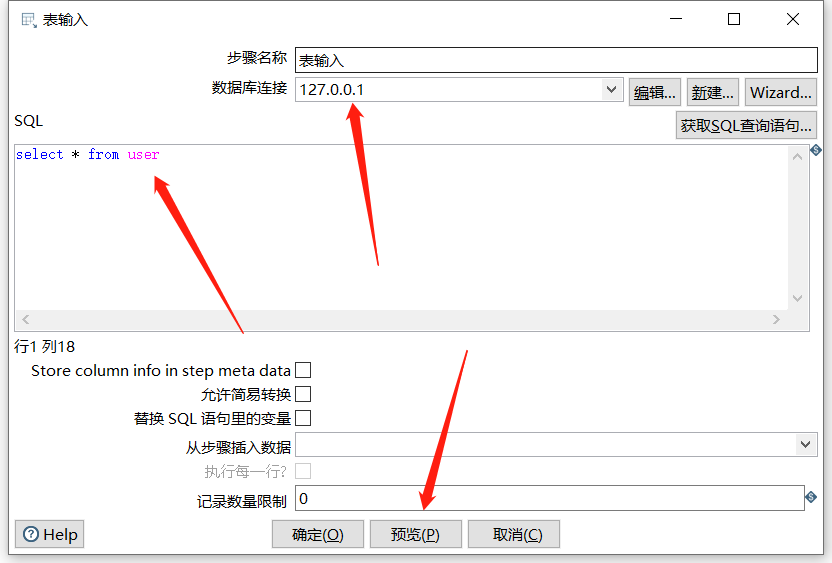
下面拖入一个 表输入 :
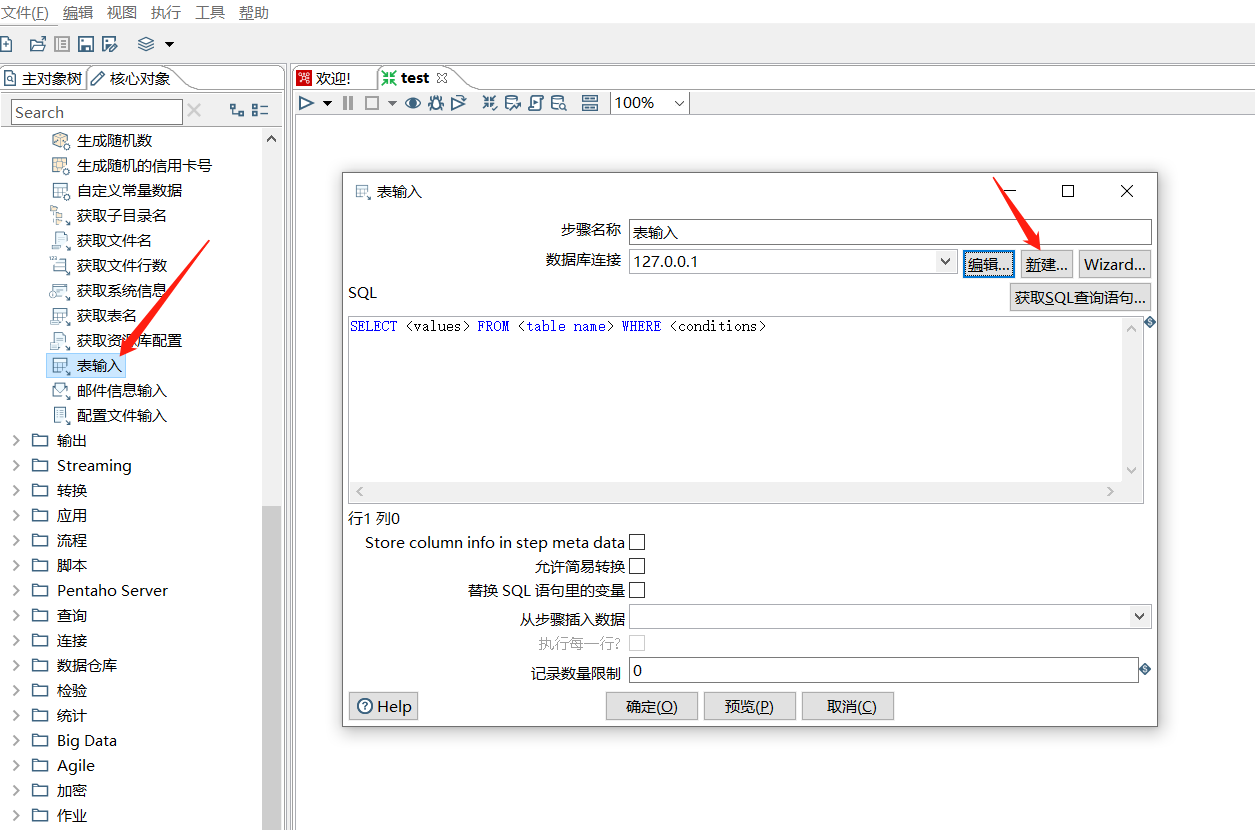
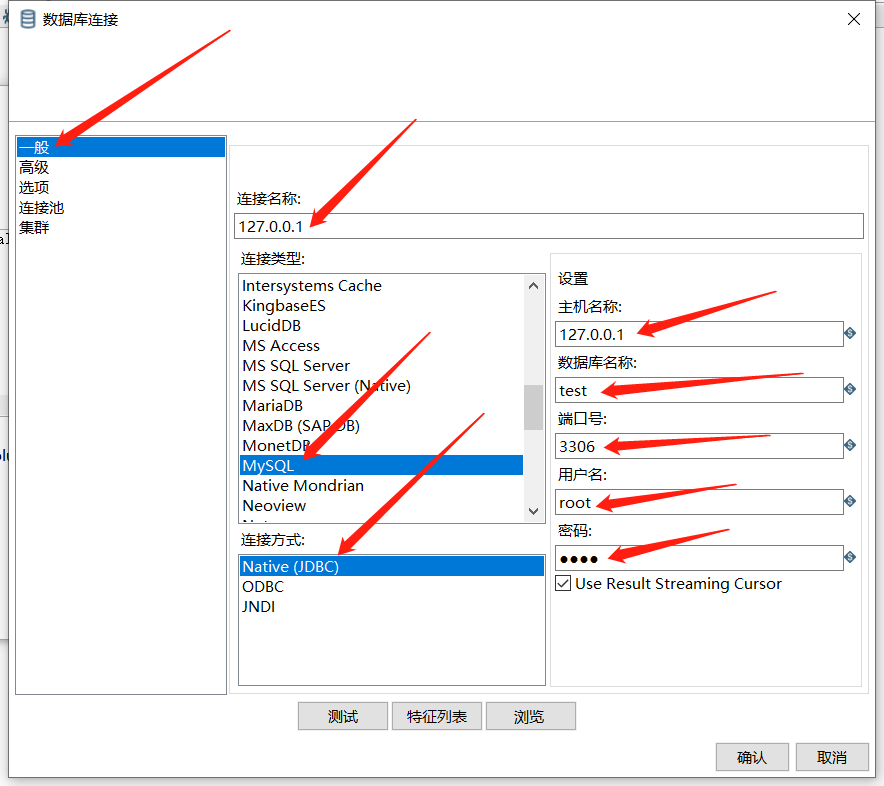
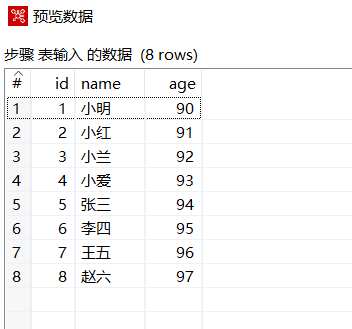
预览数据:
三、输出算子
输出算子是ETL里面的L(Load),主要做数据加载的工作:
下面测试中的输入就使用上面演示的表输入的结构:
3.1 Microsoft Excel 输出
拖入一个 Microsoft Excel 输出 ,这个和 Excel 输出相比支持更多格式:
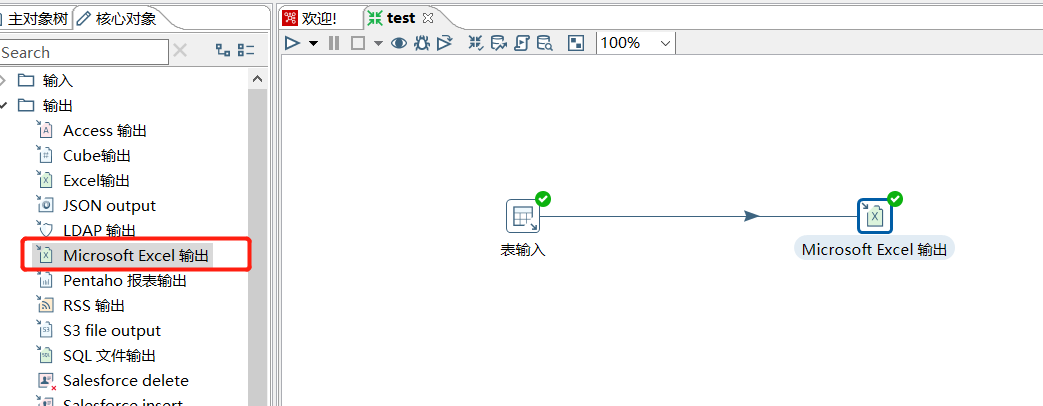
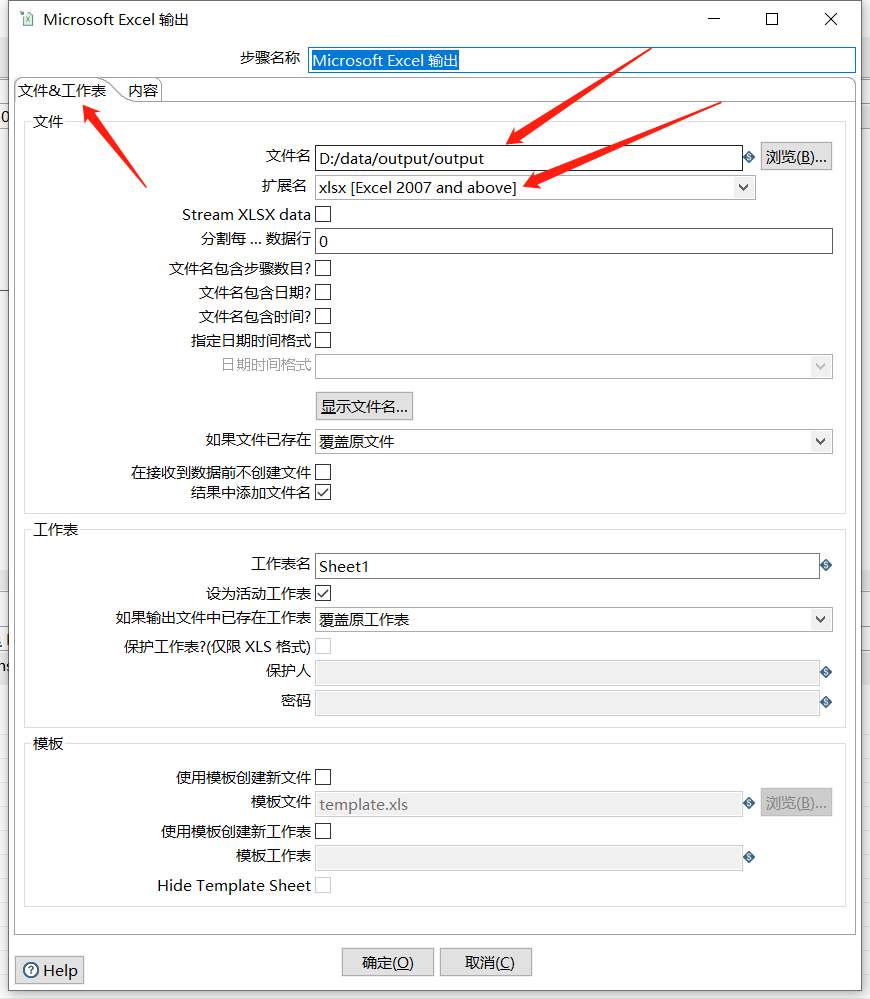
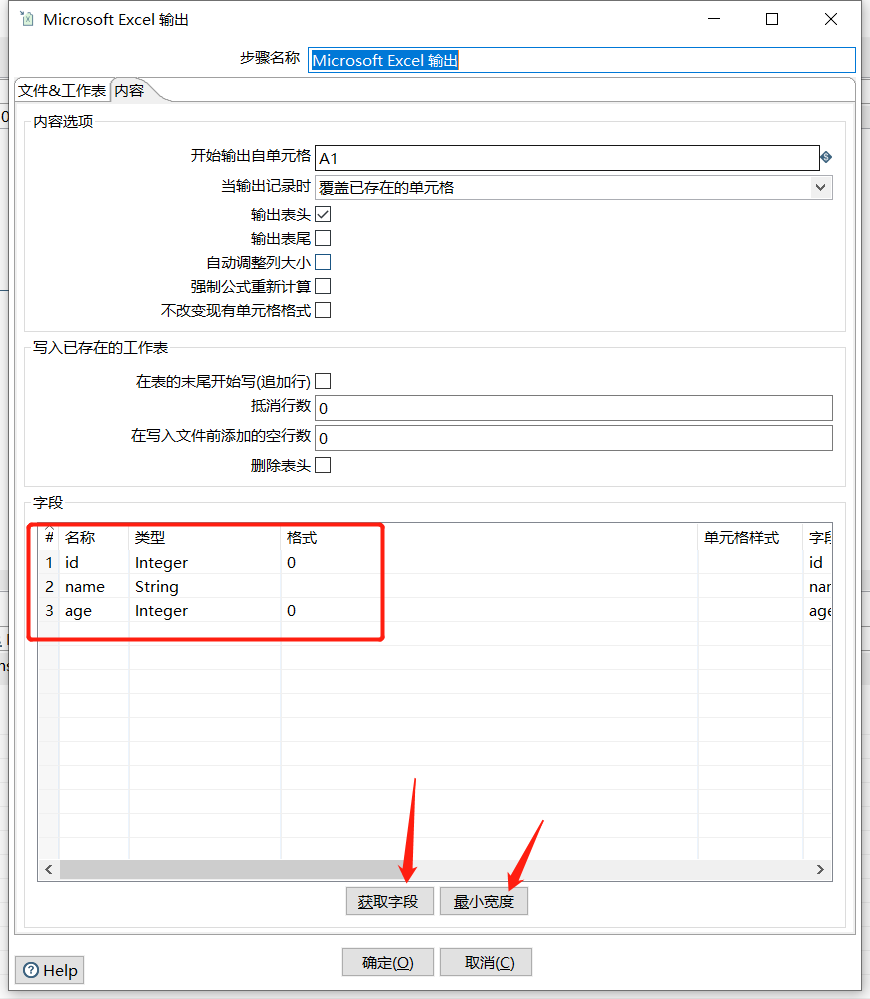
运行之后查看结果:
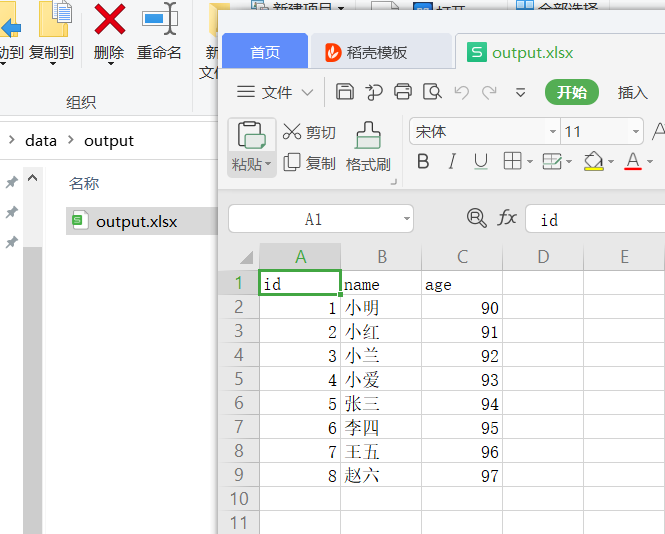
3.2 文本文件输出
拖入一个 文本文件输出:
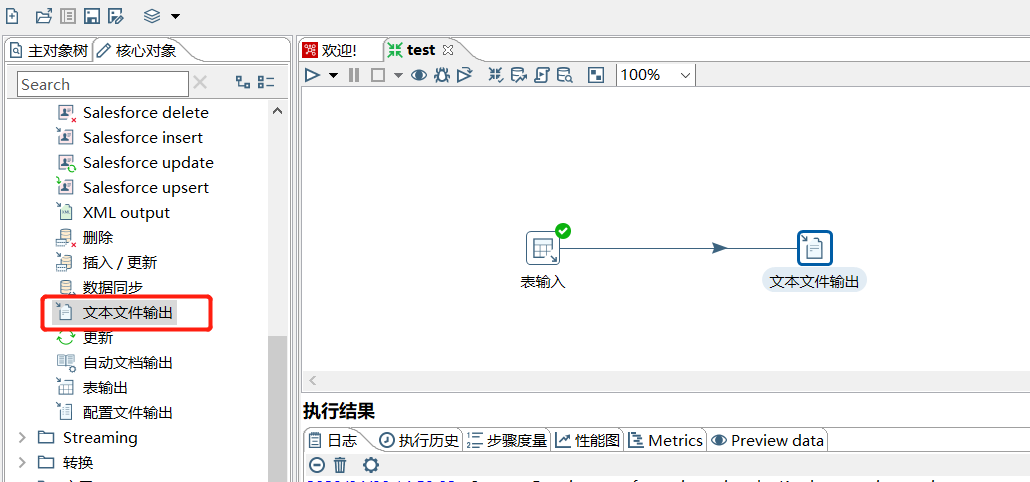
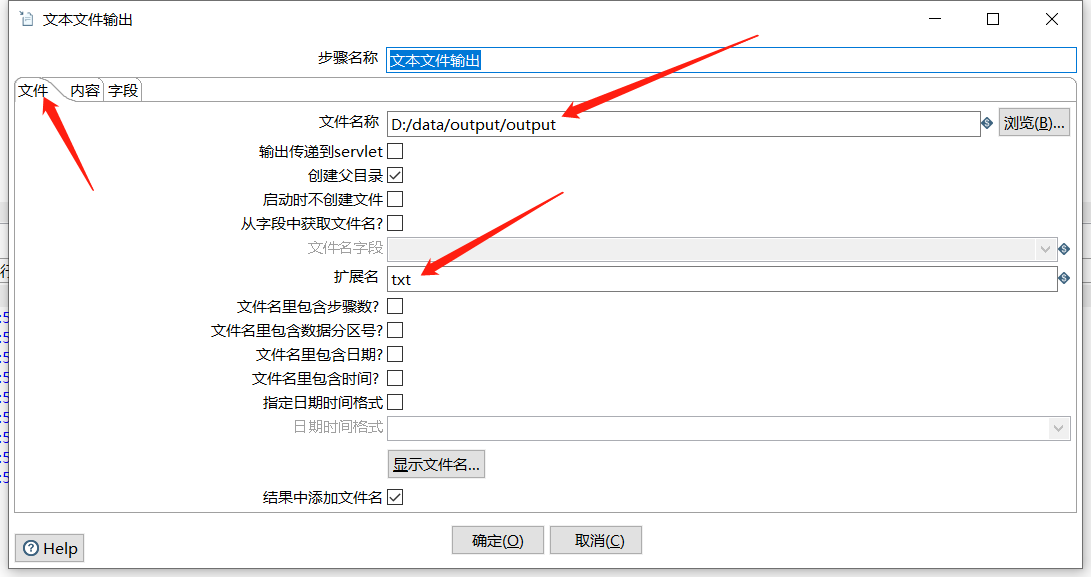
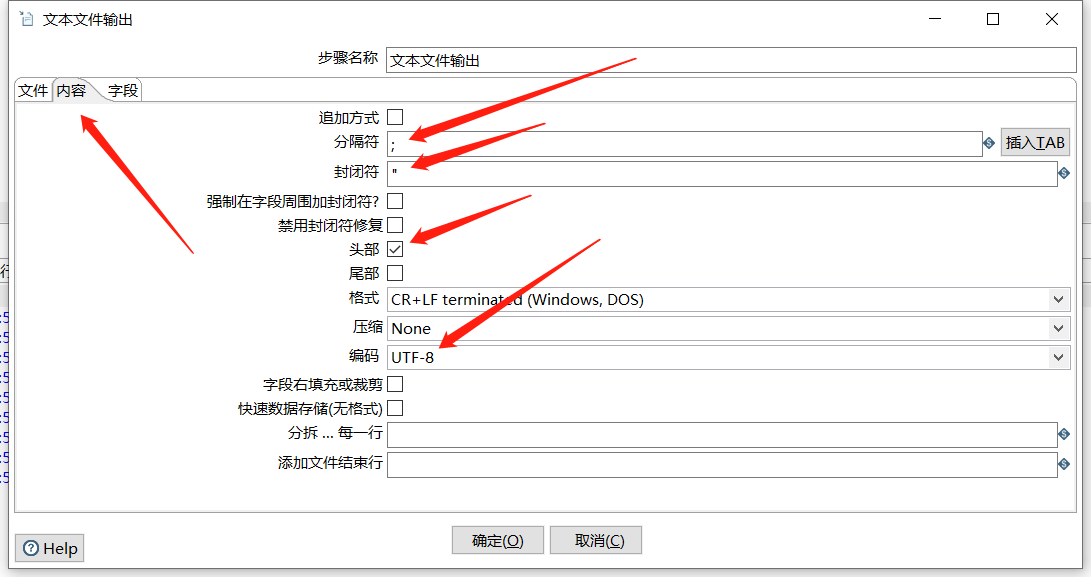
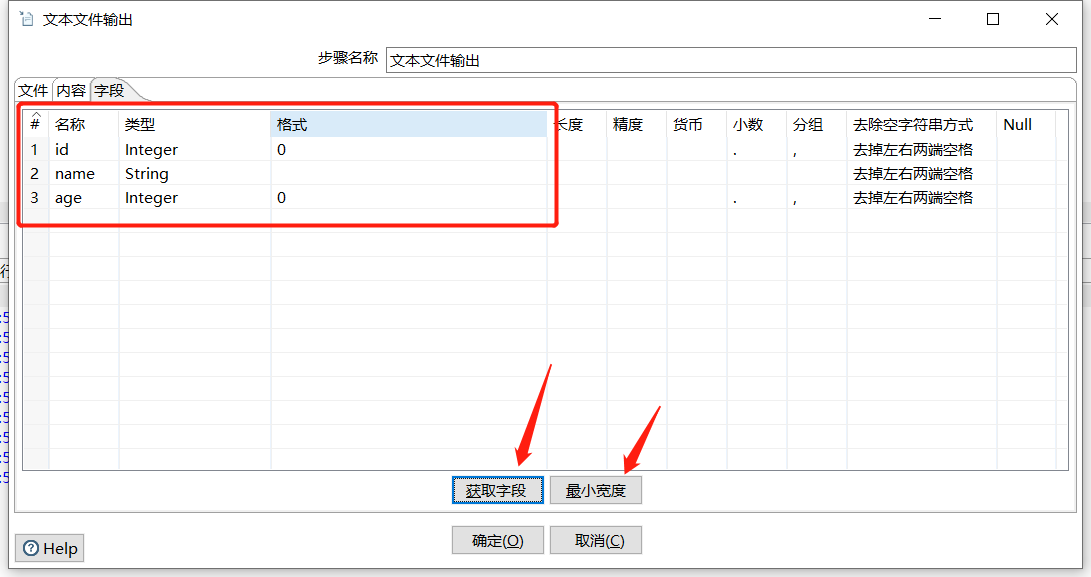
运行查看结果:
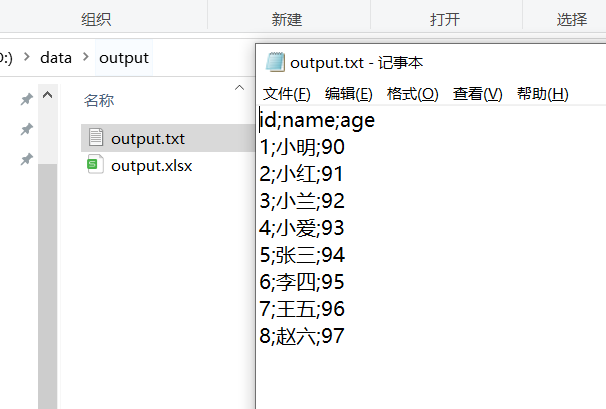
3.3 SQL文件输出
拖入一个 SQL文件输出:
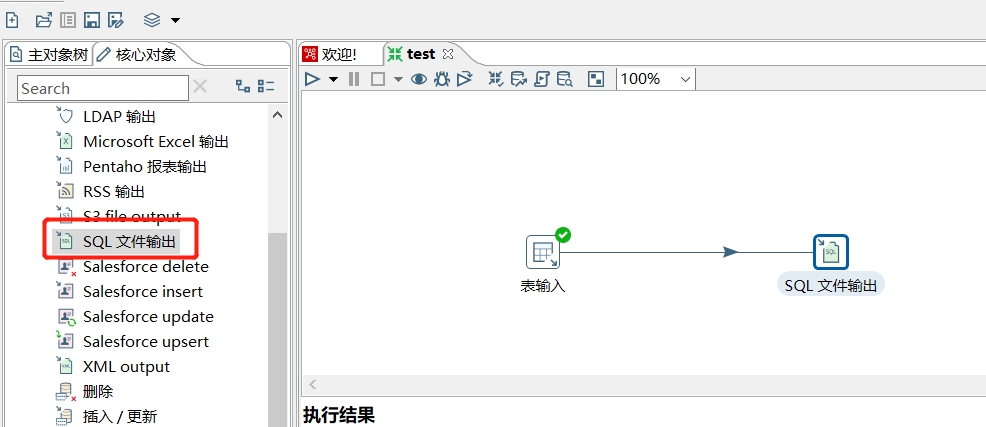
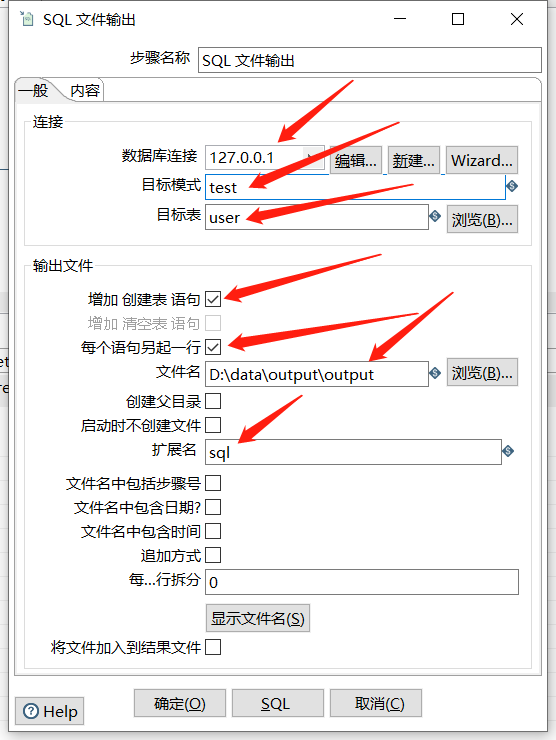
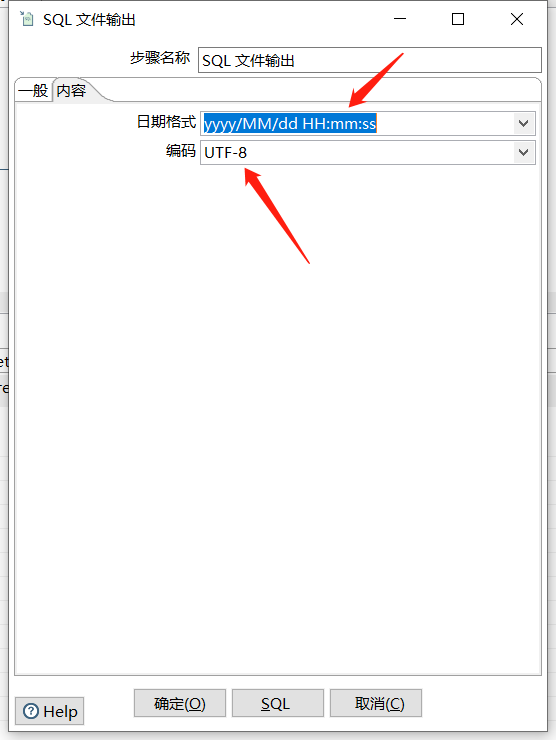
运行查看结果:
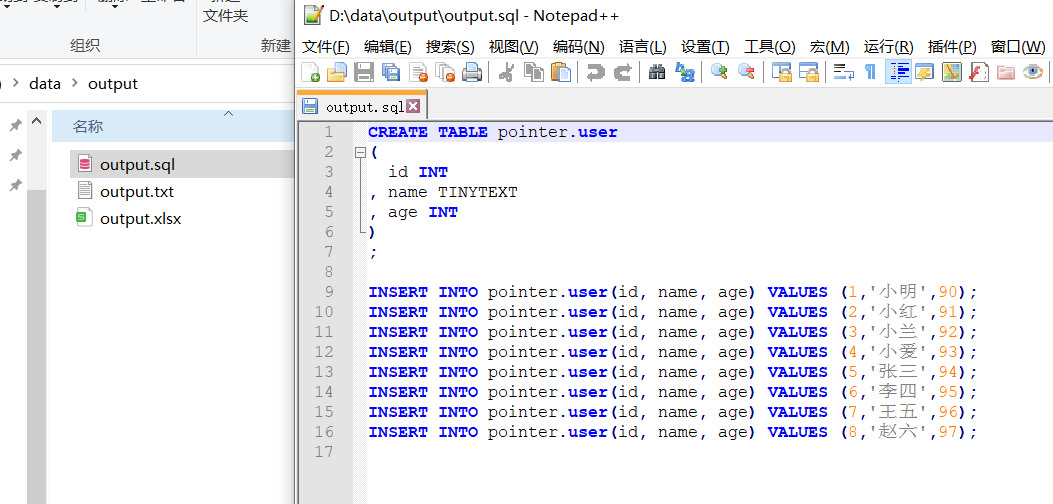
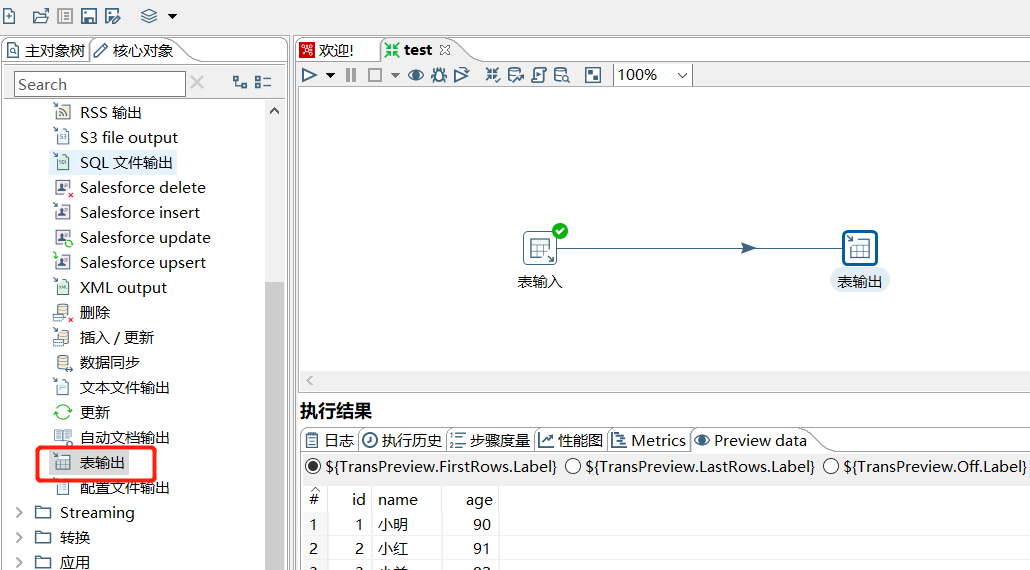
3.4 表输出
可以将数据直接写入到数据库中的表中:
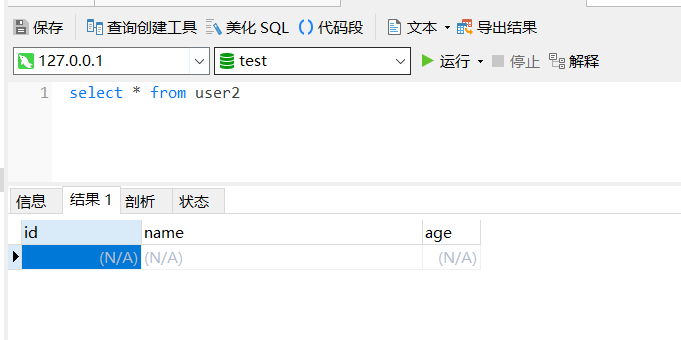
在 test 库下新建一个表 user2:
CREATE TABLE `user2` (
`id` int NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`age` int DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=9 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
下面拖入一个表输出:
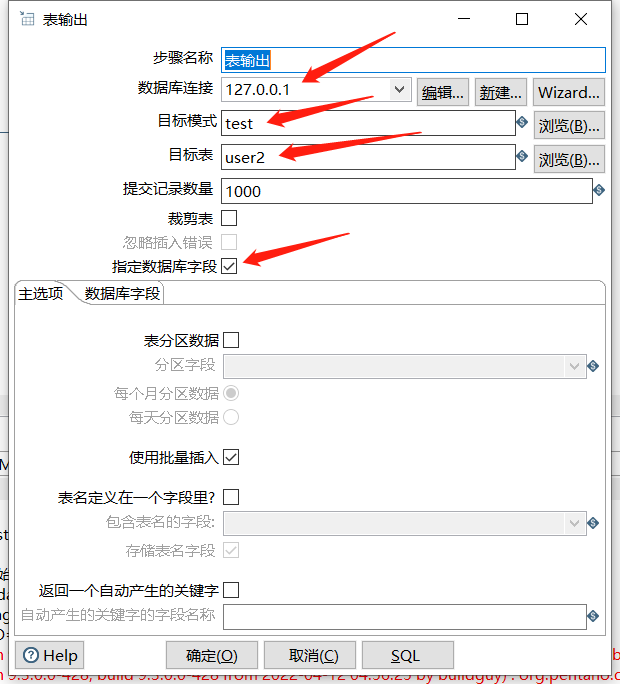
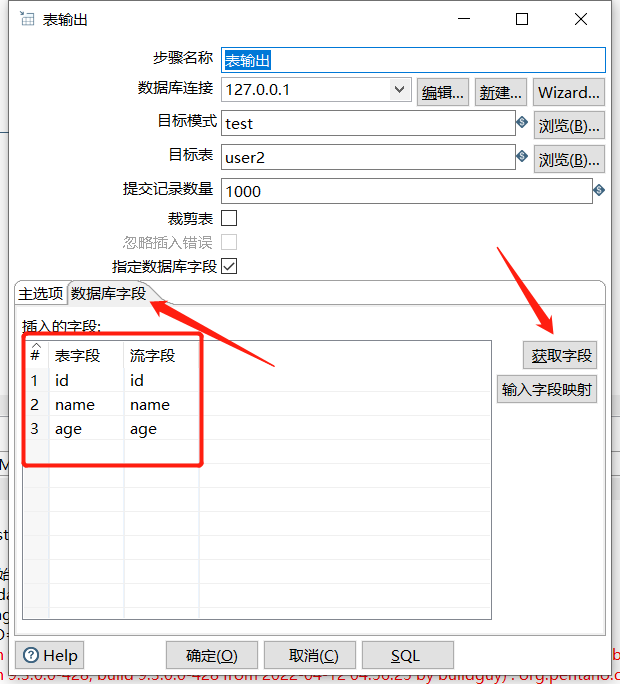
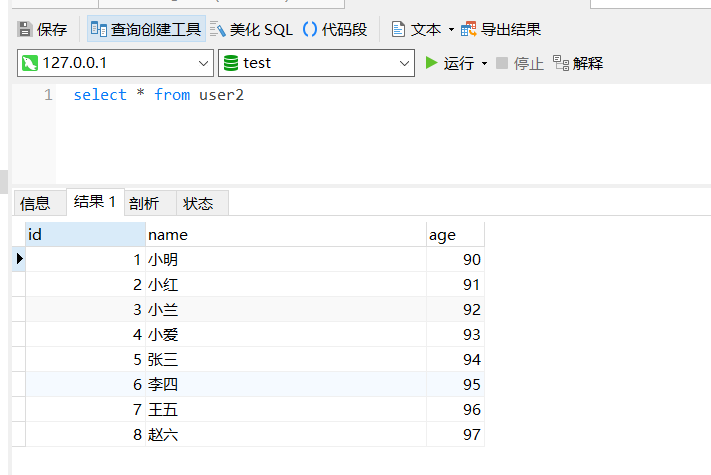
执行后查看结果:
3.5 更新
将数据库已经存在的记录与数据流里面的记录进行对比,如果发现区别就更新,但不存在的数据不会新增:
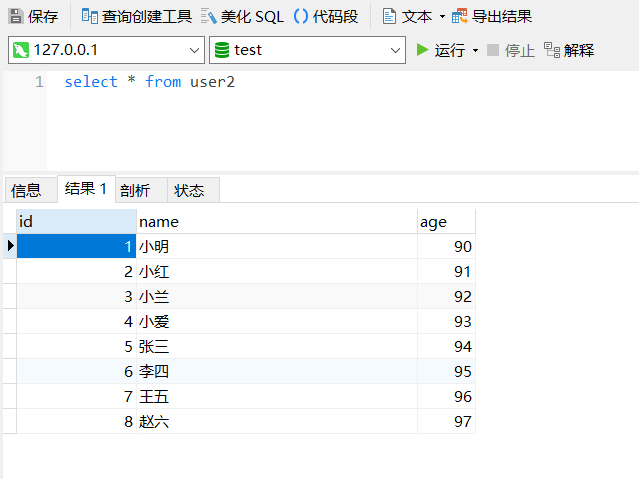
修改下 user2 表数据:
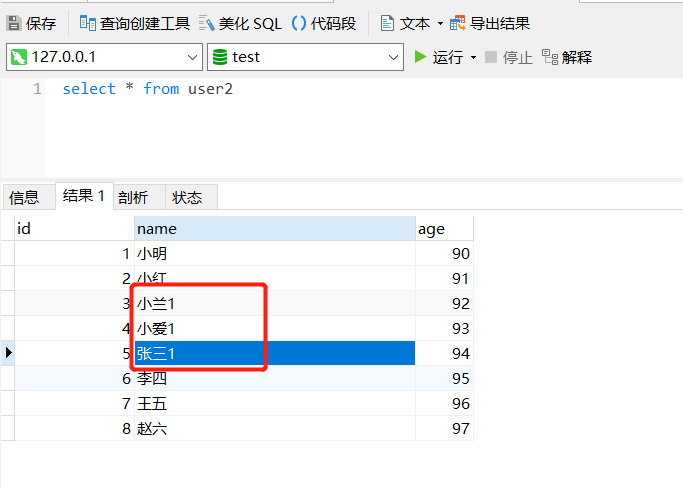
下面拖入一个 更新:
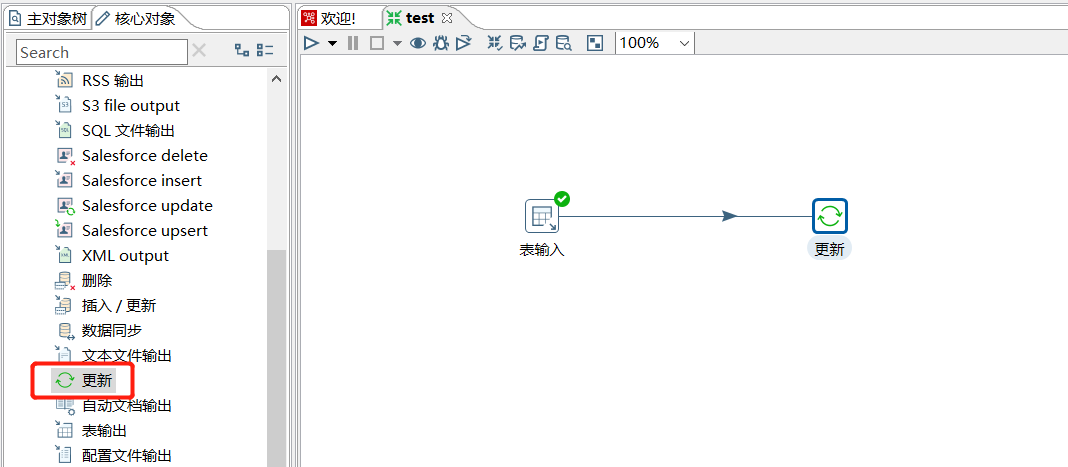
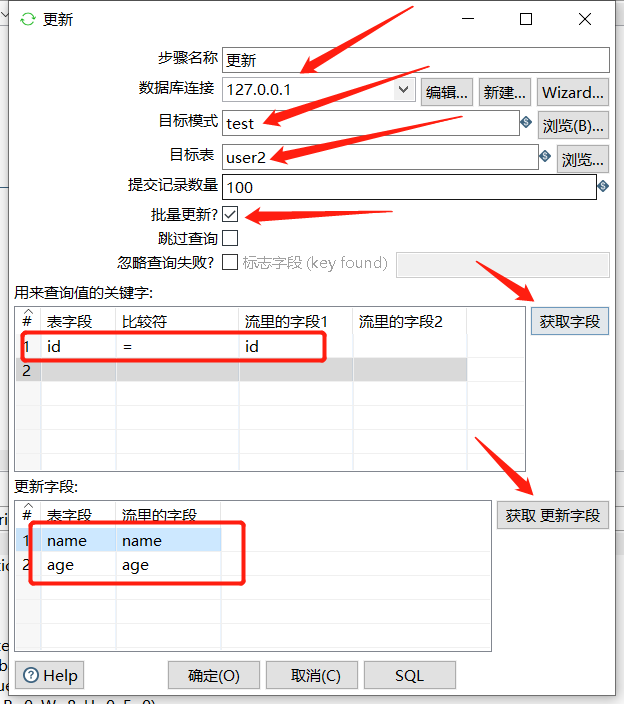
运行之后查看结果:
3.6 插入/更新
和上一个节点的区别是如果不存在则新增:
修改 user2 表删除 name 为 小明、小红 的行,并随机修改几个字段值:
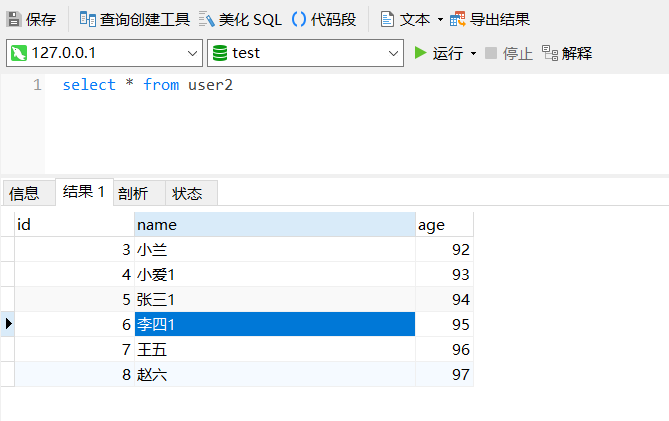
拖入一个插入/更新
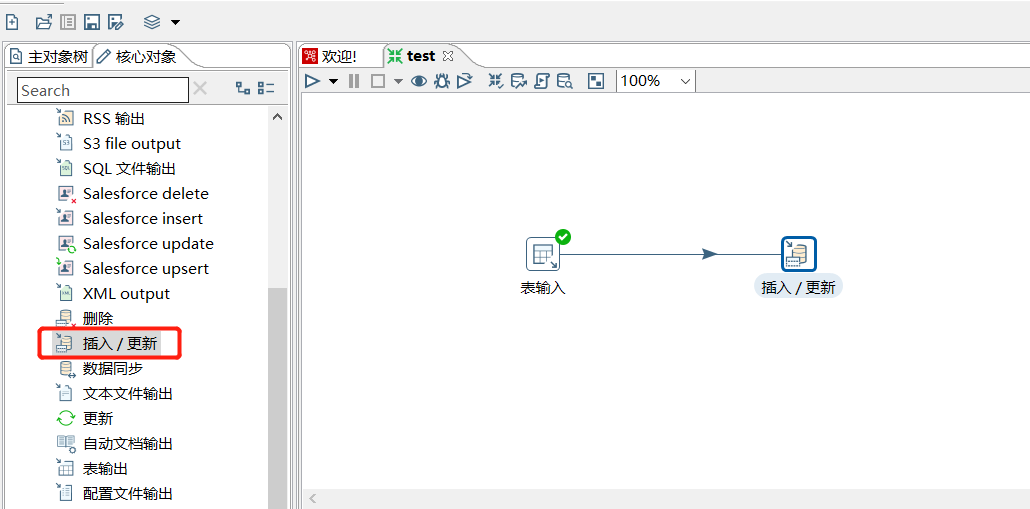
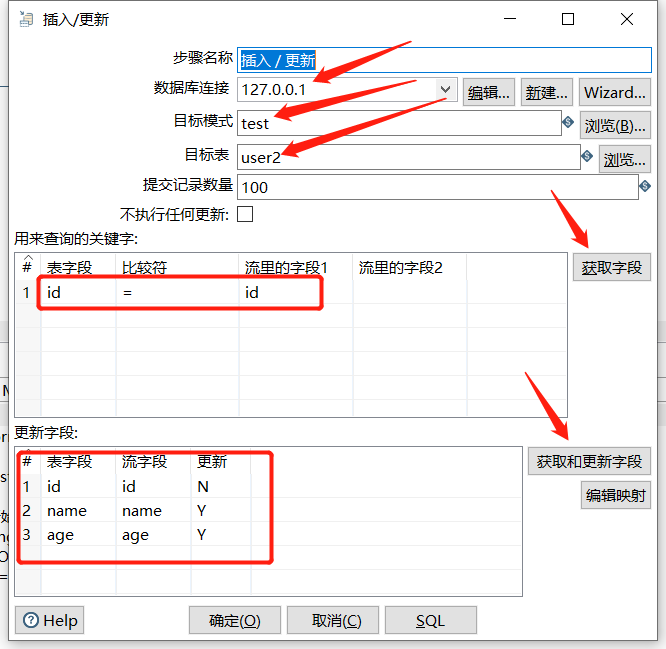
运行后查看结果:
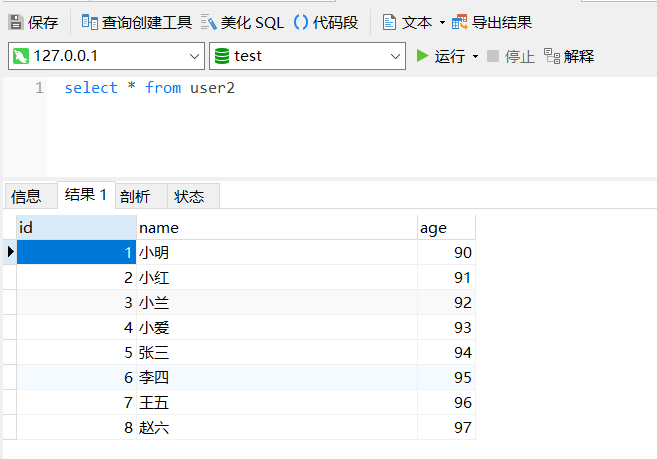
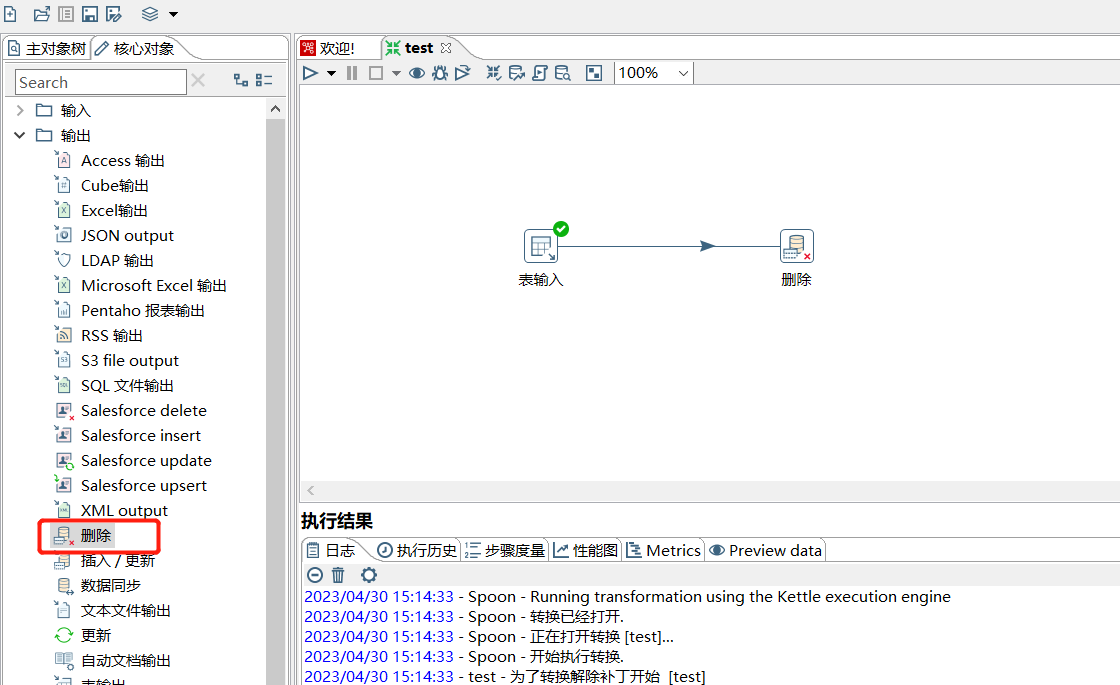
3.7 删除
可以删除数据库表中指定条件的数据:
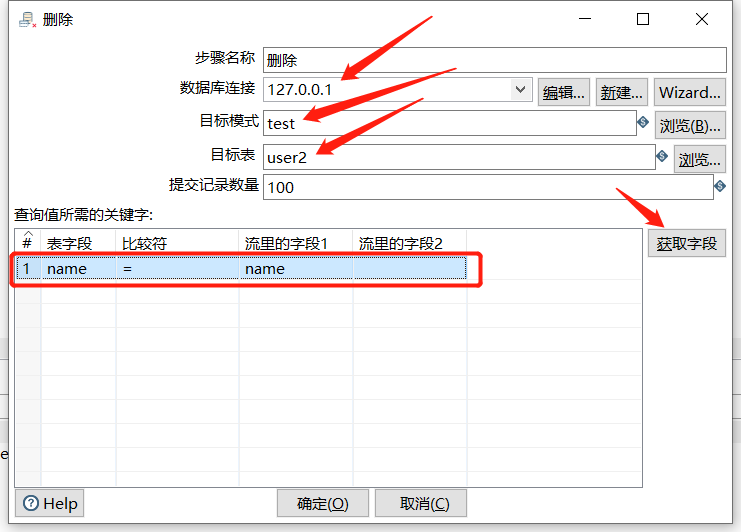
运行之后查看结果: