文章目录
- 第一章 开始
- 1. c++之与其他语言的优点?
- 2. c++语言的组成
- 3. 标准输入输出cin、cout
- 4. include格式
- 第二章 变量和基本类型
- 1. 无符号数的使用注意
- 2. 初始化注意事项
- 3. 声明与定义
- 4. 标识符的下划线规则
- 5. &引用、取地址&、指针的区别
- 6. 如何理解“因为引用不是对象,没有实际地址,所以不能定义指向引用的指针”
- 7. 复合类型的声明
- 8. 指向指针的引用
- 9. extern+const让常量在文件外部使用
- 10. 使用const可以让引用类型与引用对象的类型不一致
- 11. 指向常量的指针与常量指针
- 12. 常量表达式与constexpr
- 13. 字面值类型和指针constexpr
- 字面值类型
- 指针constexpr
- 14. decltype与引用
- 第三章 字符串、向量和数组
- 1. getline函数回车问题
- 2. 注意c++的字符串字面量的类型
- 3. 使用size()的注意事项
- 4. 类模版
- 5. 来自vector列表初始化的恶意
- 6. c++的vector与go的slice初始化效率择优方式的不同
- 7. c++的!=编程规范
- 8. vector的使用注意事项
- 9. 兼容c的数组特性
- 10. 数组的指针与引用:从内向外阅读
- 11. 范围for语句(for range)中想要改变变量值的注意点
- 第四章 表达式
- 1. 求值顺序中的未定义表达式
- 第五章 语句
- 1. c++与go的switch case区别
- 第六章 函数
- 1. 行参与实参的注意点
- 2. 函数的指针传参与传引用参数
- 3. 函数一次返回多个值
- 4. 数组作为函数参数传递注意事项(p193)
- 5. 禁止返回局部变量的引用(p201)
- 6. const_cast强制转换在重载中的广泛使用
- 第七章 类
- 1. 常量成员函数的来龙去脉
- 2. 类中函数成员与参数同名情况分析
- 3. 使用默认初始化初始化一个对象而非声明一个函数(p263)
参考:
- 《C++ Primer》
第一章 开始
1. c++之与其他语言的优点?
风格的灵活性:
- c++较大的特性在于并非像其他语言提供过分的抽象能力,可以完成c风格的底层编程和效率
- c++同时又具备了其他高级语言的抽象功能,能够实现面向对象的编程
- c++的编程风格包括:
- c风格
- 基于对象
- 面向对象
- 泛型
2. c++语言的组成
- 低级语言:大部分继承自c
- 现代高级语言特性:允许我们自定义类型和大规模程序/系统
- 标准库:用现代高级语言提供的一些高效的数据结构和算法
3. 标准输入输出cin、cout
-
cin和cout的多个对象使用
<<链接时,即使这些对象不是同一个类型,标准库也会进行处理std::cout << "The sum of " << v1 << " and " << v2 << " is " << v1+v2 << std::endl;
-
如果需要持久的读取多个输入,那么可以配合
while循环读取,循环结束的条件是:1.读取到文件结束符EOF2.一个无效的输入(例如与对象类型不同)while (std::cin >> val) { sum += val; }
4. include格式
<>:来自标准库的头文件“”:不属于标准库的头文件,则使用双引号包围
第二章 变量和基本类型
1. 无符号数的使用注意
-
当赋值给一个无符号类型的变量一个超出其范围的值的时候,其值为其数值总数的取模的余数
-
例如:8比特大小的
unsigned char可以表示0~255区间,如果赋值了一个区间以外的值,例如赋值-1,那么所得的结果是255#include <iostream> #include <unistd.h> int main() { // 无符号整型导致错误(死循环),-1会被取模为4294967295 for (unsigned i=10; i>=0; --i) { std::cout << i << std::endl; sleep(1); } return 0; }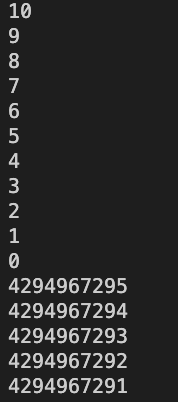
-
所以不要赋值一个超出无符号数范围的值
-
不要混用带符号类型和无符号类型,因为带符号整型可能会出现负数导致异常(带符号整型会自动转换为无符号整型)
-
2. 初始化注意事项
-
最好使用
{}的方式初始化变量,这样的好处在于可以在编译期检查是否发生了精度损失#include <iostream> int main() { long double ld = 3.1415926536; int a{ld}, b = {ld}; // 编译错误,{}会检测是否有精度丢失 int c(ld), d = ld; // 正确的,转换发生了会丢失精度 return 0; }
3. 声明与定义
变量的声明与定义的区别:
- 相同点:都规定了变量的类型与名字
- 不同点:定义除了规定还会为变量申请存储空间,也可能给变量赋上一个初始值
- 如果想只声明而不是定义,那么可以使用
extern关键字,而且不会显式的初始化变量(如果使用extern的同时赋值,那么就也还是定义)
extern int i; // 声明i并非定义i
int j; // 声明并定义j
extern double pi = 3.1415; // 定义, 注意不要在函数体内部这样做
注意点:
-
不能在函数体内部使用
extern变量并初始化赋值,这样会报错:#include <iostream> int main() { extern int idx = 3; // 错误 return 0; }
正确的写法:
#include <iostream> extern int idx = 3; int main() { return 0; }
作用:
- 如果想在多个文件中使用同一个变量,那么就必须将声明和定义分离开来
- 因为一个变量只能定义一次(分配一次内存),可以声明多次
- 在多个文件同时编译的情况下,一个变量有且只能在一个文件中定义,而其他用到的文件可以对其声明,却绝对不能重复定义
4. 标识符的下划线规则
c++不允许:
- 连续出现两个下划线
- 不能以下划线+大写字母开头
- 函数体外的标志符不能用下划线开头
5. &引用、取地址&、指针的区别
https://m.xp.cn/b.php/53505.html
引用:
-
c++中出现在变量声明中位于变量左侧的&,表示声明的是对象的引用,其作用就是给等式右边的变量起一个别名,两者是绑定在一起的
- 引用的右侧必须是一个对象/变量,不能是一个表达式计算结果或字面值
- 并且被引用的对象必须与引用是相同的数据类型(一般情况下,也有两个特例([10. 使用const可以让引用类型与引用对象的类型不一致](##10. 使用const可以让引用类型与引用对象的类型不一致)))
-
引用声明的过程中必须要初始化,程序会将引用和它的初始值绑定在一起而不是拷贝初始值到引用(也就是使用被引用对象的同一块内存)
#include <iostream> int main() { int a = 10; int &b = a; // b引用a,也就是重命名 std::cout << a << ", " << b << std::endl; // 10, 10 b = 20; // b修改值 std::cout << a << ", " << b << std::endl; // 20, 20 return 0; }
取地址:
-
c++中位于赋值语句右侧的变量的前面&,表示取变量的地址
int a=3; int &b=a; //引用 int *p=&a; //取地址
指针:
-
c++中使用
*表示一个指针对象,指针保存了一个对象的地址,是对该对象的一种间接引用(指针和引用都是对一个对象的间接引用),其本身就是一个对象 -
一个引用只能初始化绑定到一个对象上,之后不能修改,而指针保存的是地址,本身也是一个对象,可以修改地址指向不同的对象
-
指针在声明的时候也不需要必须初始化赋值
-
因为引用没有实际的对象,所以不能定义指向引用的指针
6. 如何理解“因为引用不是对象,没有实际地址,所以不能定义指向引用的指针”
https://blog.csdn.net/fatfish_/article/details/86768887
如下是否就是一个指向引用的指针呢?
int a = 10;
int &b = a;
int *c = &b; // 指针c 指向b
上述代码编译运行都不会有问题,但是不是如题所示的指向引用的指针,因为引用b就是a,实际上对b取地址&b就等价于&a, 因为引用b是没有地址的
如下可以实现初始化一个指针指向引用(当然是不合理的):
int a = 10;
int &b = a;
int &*c = &b; // 编译错误
&*c 从右往左读,*表示c是一个指针,&表示c指针指向类型的类型(指向一个引用类型)
7. 复合类型的声明
指针*与引用&都是复合类型,在定义的时候要注意一定要注意其类型修饰符是紧跟变量的,而不要与基本类型放在一起产生误导:
int *p1, p2; // p1是指针,p2是int类型
int* p1, p2; // 与上面相同,但是可能会产生误导,认为p1、p2都是指针
8. 指向指针的引用
开始绕。。。
-
引用本身不是一个对象,所以不能定义指向引用的指针
-
但是指针本身是一个新的对象,所以可以创建指向指针的引用
#include <iostream> using namespace std; int main() { int i = 42; int *p; int *&r = p; // r是一个指向p指针的引用 r = &i; // r就是指针p,这一步操作就是将i的地址给p也就是让p指向i cout << *p << endl; // 42 cout << *r << endl; // 42 *r = 0; cout << *p << endl; // 0 cout << *r << endl; // 0 return 0; }
一个变量的定义中有多个类型描述符的理解思路:
- 从右向左阅读定义,例如上面的
int *&r = p, 首先是&表明r是一个引用,随后*表明r引用的类型是一个指针,最后基本数据类型int表示其是一个指向int类型的指针的引用
9. extern+const让常量在文件外部使用
直接看代码吧:
file_1.cc
extern const int bufSize = func(); // 使用一个函数赋值会更加灵活(相对于一个字面量)
file_1.h
extern const int bufSize; // 将上面的定义导出,其他文件才能够使用
10. 使用const可以让引用类型与引用对象的类型不一致
#include <iostream>
using namespace std;
int main() {
double dval = 3.14;
const int &ri = dval; // 使用int的引用去指向一个double,借助const
cout << ri << endl; // 3
ri = 4; // 编译报错,ri是一个const不可修改
return 0;
}
能完成上面的过程的原因在于,其实是发生了如下的过程(编译器帮我们做了):
double dval = 3.14;
const int temp = dval; // 使用中间变量,或者官方叫法是临时量(书p55)
const int &ri = temp;
引用一个对象就是为了修改,但是const又不能修改,并且能修改也是中间变量,所以这样的做法没有任何的意义
11. 指向常量的指针与常量指针
指向常量的指针,顾名思义就是被指向的对象是一个常量,自己本身也必须是能够指向一个常量类型的指针:
const double pi = 3.14;
double *ptr = π // 错误,不能是一个普通指针
const double *ptr = &p1; // 正确,但是不能通过ptr指针去改pi的值,这与pi是否是常量无关只与自己的定义const有关
常量指针则不同,其关键点在于类似于常量,定义时必须初始化,之后不能再改变(即指针保存的地址是一个常量)
int num = 0;
int *const curErr = # // curErr将一直指向num
从右往左理解:const保证curErr对象本身就是一个常量,*表示其是一个指针
这两个的区别点核心在于:
- 指向常量的指针:强调不变的是指向对象(即指向的对象是const)
- 常量指针:指针自己保存的地址值是一个常量(不会改变)
终极形态:
const double pi = 3.14;
const double *const p = π // 两者都是const,指向常量对象的常量指针
顶层const:指针本身是一个常量
底层const:指针指向的对象是一个常量
=> 指针类型就是一个既可以是顶层const也可以是底层const的类型
当进行拷贝的时候,拷入和拷出的两个对象都应该有相同的底层const资格,否则不被允许
12. 常量表达式与constexpr
什么是常量表达式?
=> 在编译阶段就可以知道其具体结果的表达式
const int a = 20; // 是
const int b = a+10; // 是
int c = 30; // 不是常量
const int d = get_d(); // 不是,运行期才知道
如果不是常量表达式,那么在运行期和编译期变量的定义与使用完全是不同的,所以我们需要确切的限制,让常量的赋值是一个常量表达式
在大型项目中,难以一眼看出,所以c++的编译器可以帮我们做这一步的判断,也就是使用constexpr
#include <iostream>
using namespace std;
int main() {
constexpr int mf = 20;
constexpr int limit = mf+10;
constexpr int sz = size(); // size函数必须是一个constexpr函数
}
13. 字面值类型和指针constexpr
字面值类型
因为constexpr要在编译期间就能计算到,所以就要限制其用到的类型,这些类型比较简单显而易见,所以叫“字面值类型”
算术类型、引用、指针都是字面值类型
但是指针的字面值类型需要特别注意的是:必须初始化为nullptr或者0或者一个固定地址中的对象(地址在堆中而不是在栈中,即应该是全局变量的地址而不是一个局部变量的地址)
指针constexpr
constexpr限定指针是一个常量指针:
#include <iostream>
using namespace std;
int main() {
const int *p = nullptr; // 指向常量的指针
constexpr int *p2 = nullptr; // 常量指针
constexpr const int *p3 = nullptr; // 指向常量的常量指针
}
constexpr可以将其对象设置为顶层const
14. decltype与引用
decltype用于推断对象的类型而不需要执行、初始化该变量
有几个特殊的点:
-
获取引用的类型的时候,得到的结果不是引用对象的类型,而是引用:
const int ci = 0, &cj = ci; decltype(cj) x; // 错误,decltype(cj)返回的是const int&,而不是const int,所以必须要初始化这里也是唯一一个引用作为原对象的同义词的一个例外
-
decltype对指针的解引用的结果不是指针指向的对象的类型而是其引用类型
int i = 42, *p = &i; decltype(*p) c; // 错误,decltype(*p)返回的类型结果是int&即是对int的引用,所以必须要初始化 -
如果给变量加上括号,也会变成引用
decltype((i)) d; // 错误,d的类型是int&,要初始化 decltype(i) e; // 正确,e是一个未初始化的int
总结来说,decltype处理复合类型(引用、指针)的间接引用的时候,不会解析到最终的引用对象而是引用类型本身
第三章 字符串、向量和数组
1. getline函数回车问题
getline(cin, s)函数会读取一行字符串直到回车,本身会读取掉回车,但是赋值给s的时候不会赋值回车(回车被丢弃了)
2. 注意c++的字符串字面量的类型
c++中字符串字面量的类型不是string(为了兼容c),不是不能直接使用两个字符串字面量+运算(必须有一个是string类型才可)
3. 使用size()的注意事项
字符串函数size()返回字符串的大小,但是返回的类型是string::size_type是一个无符号整型,如果和一个有符号数一起使用,那么就可能会出现问题:
string s;
int n = -1;
while (s.size()<n) { // 会一直循环,因为n会转换为无符号数,但是因为本身是一个负数所以转换后会变为一个很大的正数
...
}
所以最好的方式是使用三段式for或者for range
#include <iostream>
#include <string>
using namespace std;
int main() {
string s;
cin >> s;
for (int i=0; i<s.size(); i++) {
cout << s[i] << endl;
}
return 0;
}
4. 类模版
c++有类模版和函数模版,模版是编译器创建类或者函数的一份说明书,编译器根据模版创建类或者函数的过程就叫做实例化
对于类模版来说,需要提供额外的信息指定实例化成为什么类,一般的方式就是通过尖括号
vector<int> ivec;
5. 来自vector列表初始化的恶意
有两种初始化的方式:
- 列表初始化,使用
{},列表中填入每个元素,如vector<int> v1{1, 2, 3, 4...} - 值初始化,使用
(),例如vector<int> v1(n)、vector<int> (n, 10)
但是今天看书看到了一个奇葩的编译器推断尝试(p89):
#include <iostream>
#include <vector>
#include <string>
using namespace std;
int main() {
vector<string> v1{10, "hi"}; // 等价于 v1(10, "hi")
for (auto item : v1) {
cout << item << ","; // hi,hi,hi,hi,hi,hi,hi,hi,hi,hi,
}
cout << endl;
return 0;
}
当编译器发现列表初始化的值不是对应的类型的时候(这里就是10与string对不上),那么就会尝试使用默认值初始化,上例刚好第二个元素是string符合,所以就等价于vector<string> v1(10, "hi")
同理,如果是vector<string> v1{10}就等价于vector<string> v1(10)
而vector<int> v1{10, 11}就是表示有10、11这两个数字,因为类型一样所以不会推断
但是这样真的不会很绕吗????个人感觉如果列表初始化的类型不对那么就最好还是直接编译报错吧….
6. c++的vector与go的slice初始化效率择优方式的不同
c++推崇先定一个空vector在不断的添加元素,这样效率更好(即使预先知道了固定大小)
而go是推崇如果预先知道了大小,要先定义大小再填值会比较高效
这俩者的区别还是很大的,看的出来c++动态数组的扩容算法应该是非常高效的
7. c++的!=编程规范
在for循环中,其他语言的判断语句经常会使用<某个上届来判断是否结束,但是c++经常会使用!=来判定,并且我们应该要习惯于这个方式:
#include <iostream>
#include <string>
using namespace std;
int main() {
string s("some thing");
for (auto iter = s.begin(); iter != s.end(); ++iter) {
*iter = toupper(*iter);
}
cout << s << endl;
return 0;
}
具体的原因在于:c++的标准库容器中很多都定义了==和!=运算符,但是没有定义<运算符,所以建议都统一使用!=会更好
8. vector的使用注意事项
当使用迭代器迭代遍历vector的时候,任何可能改变vector对象容量的操作(典型的就是push_back)都会使其迭代器失效
9. 兼容c的数组特性
类似于c语言,在用到数组名字的地方,编译器会自动将其替换为指向其首元素的地址
string *p2 = nums; // 等价于 string *p2 = &nums[0];
所以使用auto来推断一个数组名(数组变量)时,推断出来的其实是指针类型
但是用decltype还是会推断出一个数组类型,而不是一个指针(也就是上述的替换过程不会发生)
10. 数组的指针与引用:从内向外阅读
直接看例子以及注释中的含义:
int main() {
int arr[5] = {1, 2, 3, 4, 5};
int *ptrs[5]; // ptrs是含有10个整型指针的数组
int (*parrary)[5] = &arr; // parrary指向数组arr(是一个指向arr的指针) 对于数组要由内向外阅读理解
int (&arrRef)[5] = arr; // arrRef是arr数组的引用
}
对于数组来说,需要先从内向外再从右向左的阅读理解,对于int (*parrary)[5] = &arr;
首先内部(*parray)表明parray是一个指针,然后再看右边可知parray指向的是一个大小为5的数组,最后左边表明了基本类型是一个int数组(每个元素都是int类型)
例子:int *(&arry)[10] = ptrs;
arry是一个对ptrs的引用/同义词,引用的是一个大小为10的数组,数组的每个元素都是一个指向int类型的指针类型
11. 范围for语句(for range)中想要改变变量值的注意点
范围for语句(for range)中想要改变变量值要使用引用类型,否则修改的只是变量的副本:
#include <iostream>
using namespace std;
int main() {
int ia[5][5];
int cnt = 0;
for (auto &row: ia) { // 注意要用引用
for (auto &col: row) {
col = cnt;
++cnt;
}
}
for (auto &row: ia) {
for (auto &col: row) {
cout << col << ",";
}
cout << endl;
}
}
详细见书本P83,当然如果使用for遍历下标,那么可以直接使用下标的方式修改
同时在上例中因为是二维数组,不使用引用则第一层遍历的变量会自动转换为一维数组的地址,例如:
for (auto row: ia) { // 不用引用
for (auto col: row) { // 无法通过编译,因为row被替换为指向一维数组地址的指针,row是int*类型
col = cnt;
++cnt;
}
}
第四章 表达式
1. 求值顺序中的未定义表达式
如果没有强烈指明运算顺序,但是都修改了同一变量,那么此表达式就是一个未定义的表达式,编译器先计算谁后计算谁都有可能发生,这样的表达式是不准确的并且没有实际意义的,例如:
int i = f1() * f2(); // f1、f2的执行顺序是未知的,所以也是未定义的
#include <iostream>
using namespace std;
int main() {
int i = 0;
cout << i << " " << ++i << endl; // i的运算顺序未知,所以这样编写的代码也是无意义的
return 0;
}
所以编写代码的表达式的时候,如果涉及公共变量的修改或者IO操作,那么就需要定义好先后顺序,这样才不会出现意外的情况
除此之外,c++中的有四种运算符默认规定了运算顺序:
&&、||: 短路原则,如果左边能够决定结果,右边就不会继续计算,先左后右?:: 条件运算符,: 逗号运算符
还有很重要的一点:运算对象的求值顺序与运算符的结合律和优先级完全无关:
f()+g()*h()+j() // 哪个函数先计算与运算符优先级结合律无关
所以,在同一个表达式中,一个表达式改变了某个运算对象的值,其他地方就尽量不要再使用这个运算对象
第五章 语句
1. c++与go的switch case区别
- go语言中switch匹配到了某个case,执行完之后不会继续向下执行其他case(即使没写break),会自动结束
- c/c++语言则需要手动写break,否则会继续向下执行
第六章 函数
1. 行参与实参的注意点
- 函数的实参是用来初始化行参的,但是需要注意的是多个实参的计算顺序是由编译器决定的(任意的)
- 函数的返回类型不能是数组类型或者函数类型,但是可以是指向数组或函数的指针
2. 函数的指针传参与传引用参数
c++中更加推崇行参使用引用而非指针:
#include <iostream>
using namespace std;
// 传递指针
void reset1(int *ip) {
*ip = 0;
ip = 0; // 只是改变了行参的指针地址,不会改变实参指针
}
// 引用行参(更推荐)
void reset2(int &ip) {
ip = 0;
}
int main() {
int i = 42;
reset1(&i);
cout << i << endl; // 0
i = 42;
reset2(i);
cout << i << endl; // 0
return 0;
}
原因在于:
- 引用传参写实参的时候不需要取地址,因为引用就是绑定在同一个变量,在函数中直接当实参使用即可
- 在一些较大的类类型(并且有一些类类型根本不支持拷贝操作)或者容器类型拷贝传递的方式非常低效,所以要尽量使用引用行参的方式
3. 函数一次返回多个值
可以使用引用行参一次返回多个值
例如:find_char函数用于找到某个字符第一次出现的位置并返回该字符出现的总次数
#include <iostream>
using namespace std;
string::size_type find_char(const string s, char c, string::size_type &occurs) { // occurs使用引用行参作为返回值(隐式返回)
auto ret = s.size();
for (decltype(ret) i=0; i!=s.size(); ++i) {
if (s[i] == c) {
// 更新第一次出现的位置
if (ret == s.size()) {
ret = i;
}
// 累加出现的次数
++occurs;
}
}
return ret;
}
int main() {
string t = "afrwersdgnmiressss";
string::size_type occurs = 0;
cout << find_char(t, 's', occurs) << endl;
cout << occurs << endl;
return 0;
}
4. 数组作为函数参数传递注意事项(p193)
因为数组本身的两个性质,所以也决定了作为参数传递的不同之处:
因为不允许直接拷贝数组,并且数组会在编译期间替换为其首元素地址,所以其实传递数组传递的是数组的指针
以下三个函数的声明等价,行参都是const int*类型的:
void print(const int*);
void print(const int[]); // 表示是一个int数组
void print(const int[10]); // 额外声明了数组大小,但是实际传递的不一定
行参数组的大小对于函数调用的实参没有影响
因为对于行参的数组来说不知道传递过来的数组的大小(只有一个数组的首地址),所以最好的处理方式是同时再传递一个指向尾后元素的指针:
void print(const int* beg, const int* end);
调用的时候就可以借助于begin和end函数来获取这两个值
当然也可以将第二个参数改为传递数组的大小size
5. 禁止返回局部变量的引用(p201)
c++的编译器没有像go一样的逃逸分析功能,所以局部变量的引用不能return返回,因为在函数调用结束后会被销毁
#include <iostream>
using namespace std;
const string &manip() {
string ret;
if (!ret.empty()) {
return ret; // 报错: 因为局部变量的引用在函数调用结束后会被销毁
}
return "Empty"; // 报错:也是一个局部临时量
}
int main(int argc, char **argv) {
cout << manip() << endl;
return 0;
}
6. const_cast强制转换在重载中的广泛使用
#include <iostream>
#include <string>
using namespace std;
// 重载函数1,对应于都是常量参数
const string &shortString(const string &s1, const string &s2) {
cout << "call const shortString" << endl;
return s1.size() <= s2.size() ? s1 : s2;
}
// 重载函数2,对应非常量参数
string &shortString(string &s1, string &s2) {
cout << "call shortString" << endl;
// 直接调用常量函数,但是参数和结果都需要使用const_cast强行转换
auto &r = shortString(const_cast<const string &>(s1), const_cast<const string &>(s2));
return const_cast<string &>(r);
}
int main(int argc, char **argv) {
string s1 = "abc", s2 = "ab";
const string s3 = "efg", s4 = "ef";
cout << shortString(s1, s2) << endl; // call shortString ab
cout << shortString(s3, s4) << endl; // call const shortString ef
return 0;
}
第七章 类
1. 常量成员函数的来龙去脉
在书中定义Sale_data类的成员方法的时候,可以看到如下的定义:
struct Sales_data {
// 成员函数
string isbn() const { return bookNo; } // 函数体直接定义在类内
...
};
其中较为疑惑的一点在于isbn()函数参数列表之后居然又写了一个const常量标记
这里的作用在于:
- 会用this隐性的代指当前类的对象,其默认的类别为
Sales_data* const,也就是指向Sales_data类的一个常量指针 - 但是某些情况下,我们初始化创建的
Sales_data对象是一个常量对象即它的类型是const Sales_data,这样的话上述的this就无法涵盖这样的情况,导致无法调用此isbn()函数 - 所以,为了更好的适配性、灵活性以及this是一个隐性参数的原因,c++提供了这样的写法,可以将this的类别最终变成
const Sale_data* const,这样的函数也就称之为常量成员函数
2. 类中函数成员与参数同名情况分析
见以下一段代码:
typedef int pos;
pos height; // 最外层的height
class dummy
{
private:
/* data */
public:
pos cursor, width, height; // 成员height
void dummy_fcn(pos height) { // 参数height
cursor = height * width; // 这个height是那个height?
}
};
注意:其中成员函数体内的height是参数height而不是类的成员height
如果想使用成员height,则需要改为如下的写法:
void dummy_fcn(pos height) {
cursor = this->height * width;
// 或者
// cursor = dummy::height * width;
}
但其实最好的方法还就是不用将函数参数与成员同名,这样就避免了最初的麻烦
如果想使用最外层的height,则需要改为如下写法:
void dummy_fcn(pos height) { // 参数height
cursor = ::height * width; // ::使用作用域运算符显示指定使用最外层的height
}
3. 使用默认初始化初始化一个对象而非声明一个函数(p263)
Sale_data是一个自定义的类,实现了默认初始化的构造函数
如下代码:
Sale_data obj(); // 创建了一个返回类似是Sale_data的空参数函数声明
obj.isbn(); // 将会报错,因为obj是一个函数而不是一个对象
// 正确的写法(使用默认初始化):
Sale_data obj;



![[附源码]计算机毕业设计springboot环境保护宣传网站](https://img-blog.csdnimg.cn/d555f404e4ca4036975da00314b28766.png)