追风赶月莫停留,平芜尽处是春山。
文章目录
- 追风赶月莫停留,平芜尽处是春山。
- 一、准备工作
- 二、目标分析
- 二、接口分析
- url分析
- 返回数据分析
- 三、编写代码
- 获取数据
- 保存数据
- 完整代码
大四考研狗没时间更新博客了,大家勿怪,等我有学上了,一天一更(可能/狗头
一、准备工作
- 要保证你的PC端的微信版本要在
3.6.0之前的版本 - 电脑安装配置好
Fiddler安装与配置请移步这里
二、目标分析
在PC端微信打开某讯较真辟谣小程序
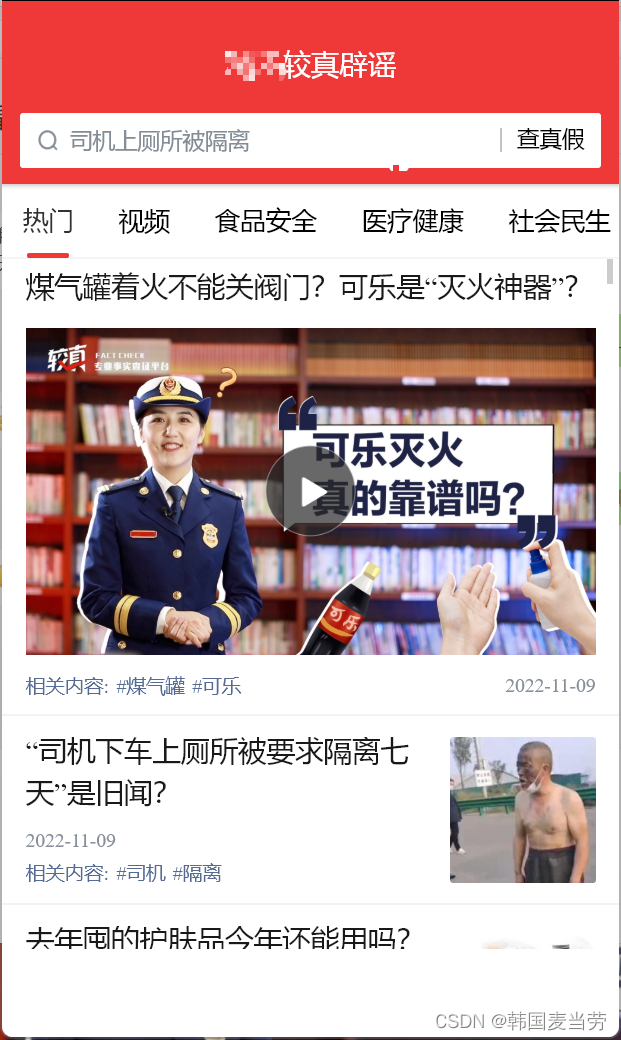
咱们今天要爬取的是热门专栏里的一条条数据
打开Fiddler然后往下刷新新闻
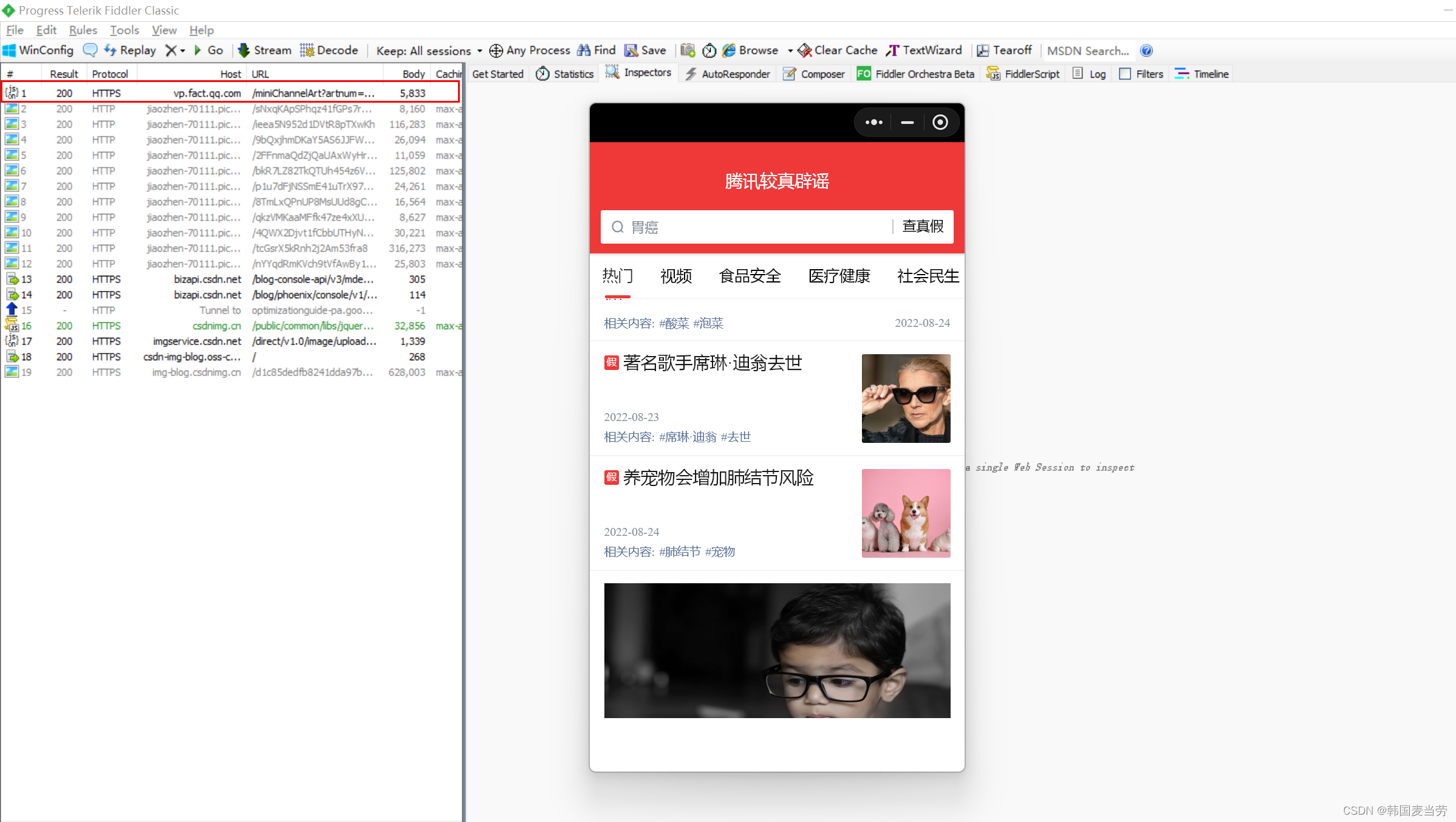
会发现在Fiddler里面找到了这么一个请求
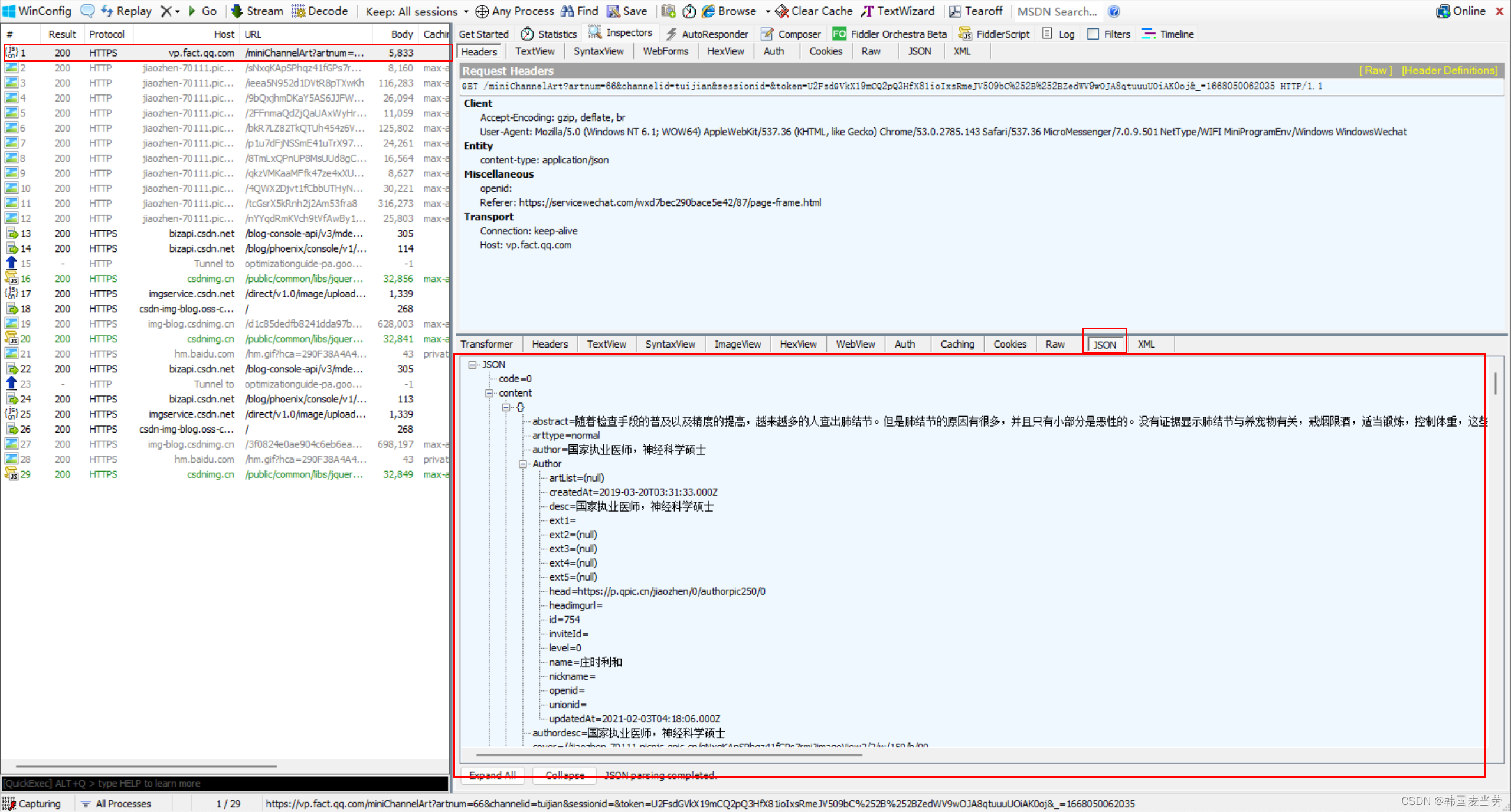
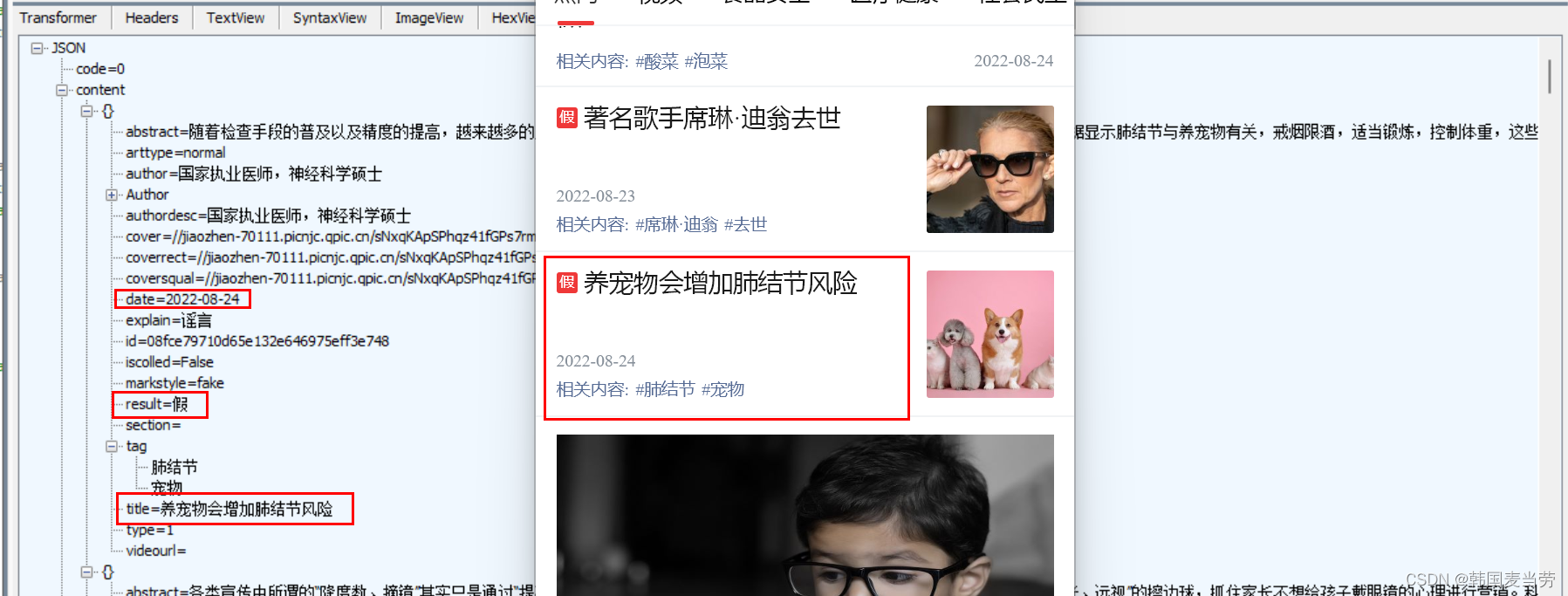
在这里我们可以看到他的一个数据的来源
二、接口分析
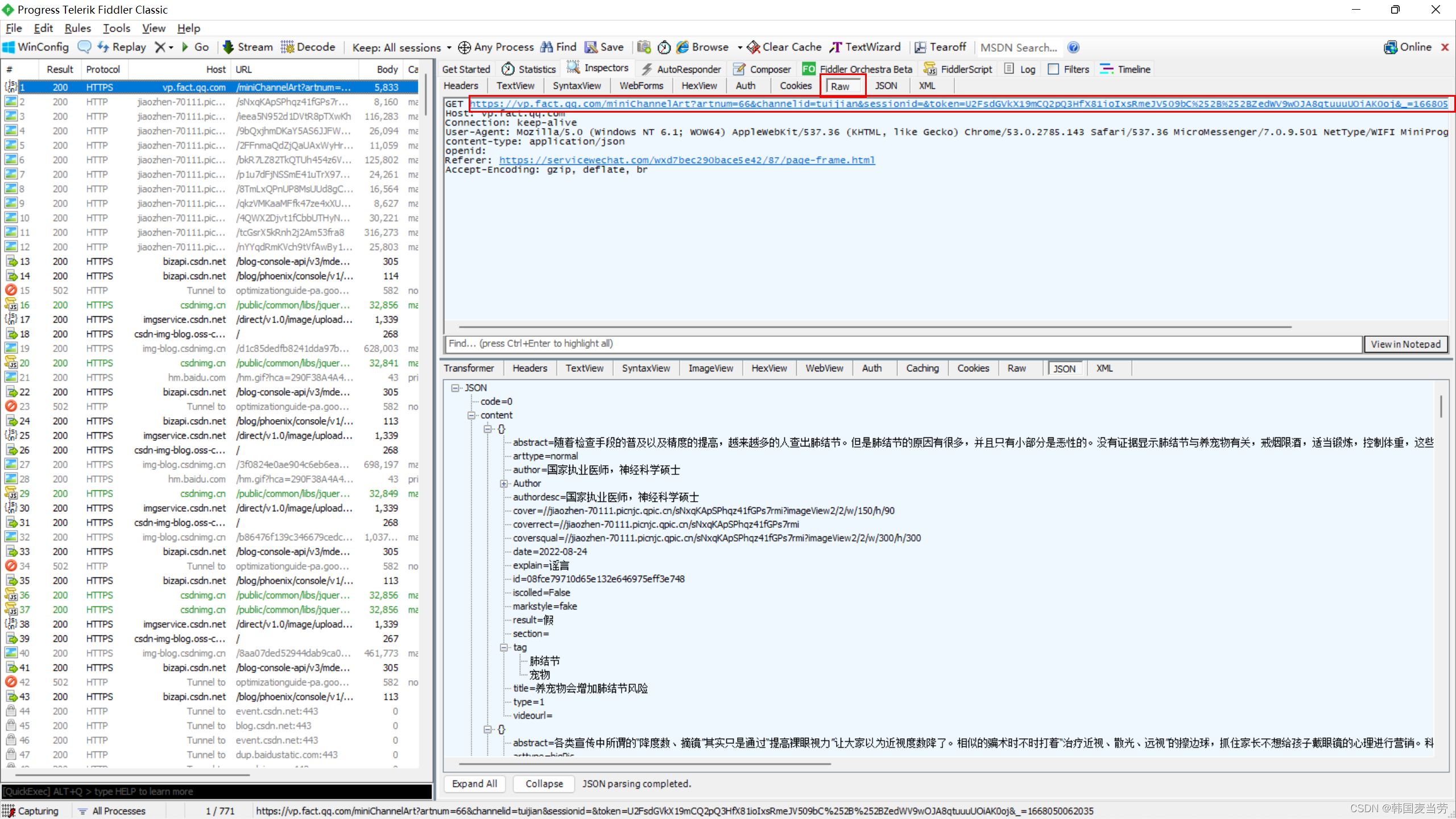
url分析
https://vp.fact.qq.com/miniChannelArt?artnum=22&channelid=tuijian&sessionid=&token=U2FsdGVkX19mCQ2pQ3HfX81ioIxsRmeJV509bC%252B%252BZedWV9wOJA8qtuuuUOiAK0oj&_=1668050062035
很明显,他有三个参数:
- artnum
这个参数掌管页数 - token
这个参数是一个令牌,暂时还没有破解生成的方法 - _
这个参数代表时间戳
如果你能掌管好这三个参数,那数据不就是手到擒来嘛!
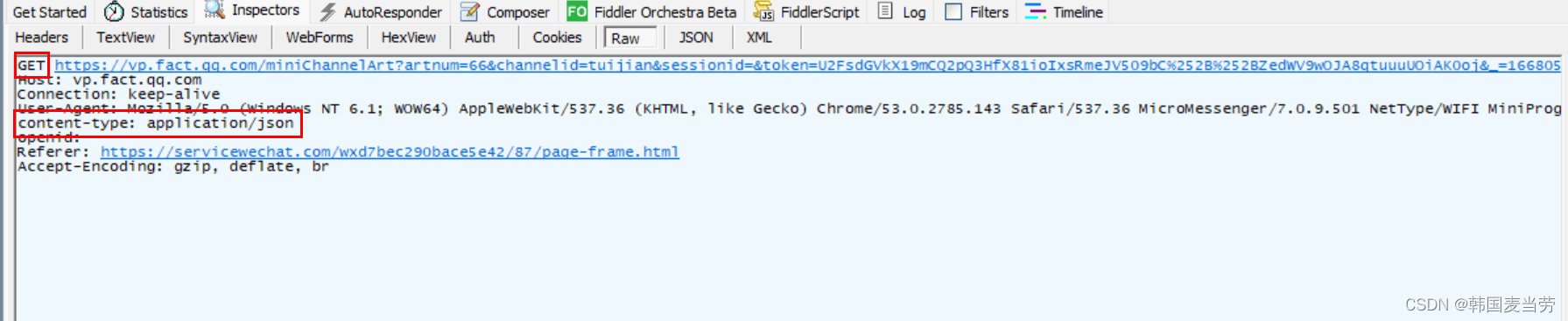
返回数据分析
是get请求,返回数据格式是json格式
三、编写代码
知道了url规则,以及返回数据的格式,那现在咱们的任务就是构造url然后请求数据
url = "https://vp.fact.qq.com/miniChannelArt?artnum={}{}&channelid=tuijian&sessionid=&token=U2FsdGVkX19GKwNTxgwgTzYy78%252BCfE983Iy9p6QNratluvku5th95VzqQAbI6FB9&_={}".format(page, page, int(time.time()*1000))
那就直接上呗,直接请求他
所以我们为了方便就把请求网页的代码写成了函数get_html(url),传入的参数是url返回的是请求到的内容。
def get_html(url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36 MicroMessenger/7.0.9.501 NetType/WIFI MiniProgramEnv/Windows WindowsWechat",
"Host": "vp.fact.qq.com",
"Referer": "https://servicewechat.com/wxd7bec290bace5e42/87/page-frame.html",
}
response = requests.get(url, headers=headers)
return response.text
获取数据
将获得的数据格式化为json格式的数据。
def get_html(url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36 MicroMessenger/7.0.9.501 NetType/WIFI MiniProgramEnv/Windows WindowsWechat",
"Host": "vp.fact.qq.com",
"Referer": "https://servicewechat.com/wxd7bec290bace5e42/87/page-frame.html",
}
response = requests.get(url, headers=headers)
return response
def get_data():
for page in range(1, 11-----
):
url = "https://vp.fact.qq.com/miniChannelArt?artnum={}{}&channelid=tuijian&sessionid=&token=U2FsdGVkX19GKwNTxgwgTzYy78%252BCfE983Iy9p6QNratluvku5th95VzqQAbI6FB9&_={}".format(page, page, int(time.time()*1000))
data = get_html(url).json()
data = data['content']
for i in data:
title = i['title']
abstract = i['abstract']
result = i['result']
date = i['date']
保存数据
我们写一个save函数用来存放数据
def save_data(title, abstract, result, date):
with open('data.csv', 'a', encoding='utf-8-sig', newline="") as f:
writer = csv.writer(f)
writer.writerow([title, abstract, result, date])
完整代码
# -*- coding:utf-8 -*-
# @time: 2022/11/10 17:30
# @Author: 韩国麦当劳
# @Environment: Python 3.7
import requests
import time
import csv
def get_html(url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36 MicroMessenger/7.0.9.501 NetType/WIFI MiniProgramEnv/Windows WindowsWechat",
"Host": "vp.fact.qq.com",
"Referer": "https://servicewechat.com/wxd7bec290bace5e42/87/page-frame.html",
}
response = requests.get(url, headers=headers)
return response
def save_data(title, abstract, result, date):
with open('data.csv', 'a', encoding='utf-8-sig', newline="") as f:
writer = csv.writer(f)
writer.writerow([title, abstract, result, date])
def get_data():
for page in range(1, 11):
url = "https://vp.fact.qq.com/miniChannelArt?artnum={}{}&channelid=tuijian&sessionid=&token=U2FsdGVkX19GKwNTxgwgTzYy78%252BCfE983Iy9p6QNratluvku5th95VzqQAbI6FB9&_={}".format(page, page, int(time.time()*1000))
data = get_html(url).json()
data = data['content']
for i in data:
title = i['title']
abstract = i['abstract']
result = i['result']
date = i['date']
save_data(title, abstract, result, date)
if __name__ == '__main__':
get_data()
欢迎一键三连哦!
还想看哪个网站的爬虫?欢迎留言,说不定下次要分析的就是你想要看的!