这篇文章我们简略的讲一下java的正则表达式
目录
1.正则表达式概述
2.正则表达式的简单匹配规则
3.正则表达式的复杂匹配规则
4.正则表达式的分组匹配规则
5.正则表达式的非贪婪匹配
6.使用正则表达式进行搜索和替换
1.正则表达式概述
首先,我们需要明确一个观点,什么是正则表达式?
正则表达式:可以定义出一个字符串的结构特征,然后我们可以利用这个特征来查找、匹配、替换一个字符串中的某些内容。
解释:其实很好理解。就比如这里有一个字符串,很复杂,但是呢,我知道一些子串或者说具体的部分内容,现在我想匹配一下这个字符串里面是否含有这些子串,或者说这个字符串是否符合我的目标格式,又或者说,我只知道一个大概的字符串特征,但是我想在一大堆字符串中查找一个有这个特征的字符串,等等等等,这些操作都是靠正则表达式来完成的
案例演示:
需求:给出字符串“3ahfget56adwnf8adba4jk5sg6wfa4dw”,现在要求将该字符串中但凡出现“数组+a”的部分全部替换为“---”
代码如下:

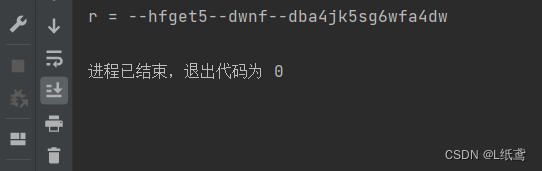
代码:
public class zhengzeTest {
public static void main(String[] args) {
String s = "3ahfget56adwnf8adba4jk5sg6wfa4dw";
String r = s.replaceAll("\\da","--");
System.out.println("r = "+r);
}
}解析:初看很简单,再看很复杂。字符串替换,我们都会,因为有java提供的StringAPI,但是,这些替换都是将具体的内容替换为新的内容,而现在我们要求的是将“数字+a”这个内容替换为新内容,这个内容不是固定的啊,它可以是“1a”可以是“3a”,它不是固定的,这就很麻烦。这个时候就要用到正则表达式了。正则表达式的定义就是,我们定义一个字符创的结构特征,然后我们利用这个特征来对字符串进行相应的操作。所以我们就要定义一个字符串的结构特征,这个特征是“xa”,但凡符合这个特征的部分,都要被替换。这就是正则表达式的作用。
到此,我们算是初步的认识了什么是正则表达式,正则表达式有什么用,用在什么地方了。
2.正则表达式的简单匹配规则
下面来讲一下正则表达式的简单匹配规则
正则表达式的匹配规则:从左到右按规则匹配
下面就结合具体的实例来讲一下。
如果,我们编写了一个正则表达式“abc”,那么在匹配时,就只能匹配“abc”,不能匹配“Abc”或者“ab”或者“ac”
如果,我们编写了一个正则表达式“a\&c”,那么在匹配时,就只能匹配“a&c”,不能匹配“Ac”或者“ac”或者“aC”
如果,我们编写了一个正则表达式“a\u548cc”,那么在匹配时,就只能匹配“a与c”,不能匹配“A与c”或者“ac”或者“AC”。在正则表达式中,如果我们需要表示汉字,则我们需要其对应的Unicode字符
如果,我们编写了一个正则表达式“a.c”,那么在匹配时,就能匹配“a与c”或者“abc”,不能匹配“A与c”或者“ac”或者“AC”。在正则表达式中,我们用“.”来代表一个任意字符
如果,我们编写了一个正则表达式“a\dc”,那么在匹配时,就能匹配“a0c”或者“a1c”或者“a2c”,不能匹配“A与c”或者“ac”或者“AC”。在正则表达式中,我们用“\d”来代表一个任意数字
如果,我们编写了一个正则表达式“a\wc”,那么在匹配时,就能匹配“a_c”或者“abc”或者“a2c”,不能匹配“A与c”或者“ac”或者“AC”。在正则表达式中,我们用“ \w ”来代表一个任意字母,数字,下划线
如果,我们编写了一个正则表达式“a\sc”,那么在匹配时,就能匹配“a c”或者“a c”,不能匹配“A与c”或者“ac”或者“AC”。在正则表达式中,我们用“\s”来代表一个空格或者一个Tab
如果,我们编写了一个正则表达式“a\Dc”,那么在匹配时,就能匹配“aAc”或者“a#c”,不能匹配“A2c”或者“ac”或者“AC”。在正则表达式中,我们用“\D”来代表一个非数字
如果,我们编写了一个正则表达式“a\Wc”,那么在匹配时,就能匹配“a!c”或者“a c”,不能匹配“A2c”或者“ac”或者“AC”。在正则表达式中,我们用“\W”来代表一个非数字,字母,或下划线
如果,我们编写了一个正则表达式“a\d*”,那么在匹配时,就能匹配“a12”或者“a123”,不能匹配“A c”或者“a!”。在正则表达式中,我们用“*”来代表一个任意个字符,它的作用其实就是先匹配a,然后匹配"\d",然后因为有“*”,所以就可以有任意个“\d”了
如果,我们编写了一个正则表达式“a\d+”,那么在匹配时,就能匹配“a1”或者“a12”,不能匹配“A与c”或者“a”或者“AC”。在正则表达式中,我们用“+”来表示,至少有一个+前面的正则表达式字符
如果,我们编写了一个正则表达式“a\d?”,那么在匹配时,就能匹配“a”或者“a1”,不能匹配“A与c”或者“a12”或者“AC”。在正则表达式中,我们用“?”来表示零个或者一个其前面的正则表达式字符
如果,我们编写了一个正则表达式“\d{3}”,那么在匹配时,就能匹配“123”或者“234”,不能匹配“12”或者“1234”或者“1”。在正则表达式中,我们用“{n}”来表示,应该有n个其前面的字符
如果,我们编写了一个正则表达式“\d{3,5}”,那么在匹配时,就能匹配“123”或者“2345”或者“23456”,不能匹配“12”或者“123456”或者“1”。在正则表达式中,我们用“{n,m}”来表示,应该有n-m个其前面的字符
如果,我们编写了一个正则表达式“\d{3,}”,那么在匹配时,就能匹配“123”或者“2344687”,不能匹配“12”或者“1”。在正则表达式中,我们用“{n,}”来表示,应该至少有n个其前面的字符
下面用一张表来概述一下正则表达式的匹配规则:
| 正则表达式 | 规则 | 可以匹配 |
| A | 指定字符 | A |
| \u548c | 指定的Unicode字符 | 和 |
| . | 任意字符 | a,b,&,0 |
| \d | 0~9 | 0,1,2,……,9 |
| \w | a~z,A~Z,0~9,_ | a,A,0,_,…… |
| \s | 空格,Tab键 | 略 |
| \D | 非数字 | a,A,&,_,…… |
| \W | 非\w | &,@,中,…… |
| \S | 非\s | a,A,&,_,…… |
| AB* | 任意个数字符 | A,AB,ABB,ABBB |
| AB+ | 至少1个字符 | AB,ABB,ABBB |
| AB? | 0个或者1个字符 | A,AB |
| AB{3} | 指定个数字符 | ABBB |
| AB{1,3} | 指定范围个数字符 | AB,ABB,ABBB |
| AB{2,} | 至少n个字符 | ABB,ABBBB,…… |
| AB{0,3} | 至多n个字符 | A,AB,ABB,ABBB |
3.正则表达式的复杂匹配规则
下面来讲一下正则表达式的复杂匹配规则
如果,我们编写了一个正则表达式“^A\d{3}$”,那么在匹配时,就能匹配“A001”或者“A999”,不能匹配“B001”或者“A0001”。在正则表达式中,我们用^和$来匹配开头和结尾
如果,我们编写了一个正则表达式“[abc]1”,那么在匹配时,就能匹配“a1”或者“b1”或者“c1”,不能匹配“B1”或者“d1”。在正则表达式中,我们用[ ] 来匹配范围内的字符
拓展:[a-f]:a,b……f;[a-f0-9]{3}:aaa,a2d,123……
如果,我们编写了一个正则表达“[^0-5]{3}”,那么在匹配时,就能匹配“789”或者“689”或者“ac8”,不能匹配“a21”或者“132”。在正则表达式中,我们用[^……]来匹配非范围内的字符
如果,我们编写了一个正则表达“AB|CD”,那么在匹配时,就能匹配“AB”或者“CD”,不能匹配“ABCD”或者“AC”。在正则表达式中,我们用“ | ”来表示选择
| 正则表达式 | 规则 | 可以匹配 |
| ^ | 开头 | 字符串开头 |
| $ | 结尾 | 字符串结尾 |
| [ABC] | [……]内任意字符 | A,B,C |
| [A-F0-9xy] | 指定范围的字符 | A……F,0-9,x,y |
| [^A-F] | 指定范围外的字符 | 非A……F |
| AB|CD | AB或者CD | AB,CD |
4.正则表达式的分组匹配规则
正则表达式的分组匹配其实就是利用()来完成的,我们只需要在正则表达式的相应位置加上()就行,就是相当于改变了一下顺序而已
5.正则表达式的非贪婪匹配
下面用一个例子来讲解一下正则表达式的贪婪匹配和非贪婪匹配
例:我们需要判断一串数字末尾0的个数
如下所示:“123000”:3个0;“12300”:2个0;“123”:0个0
我们可以的初始反应一个是需要这样写:“^(\d+)(0*)”
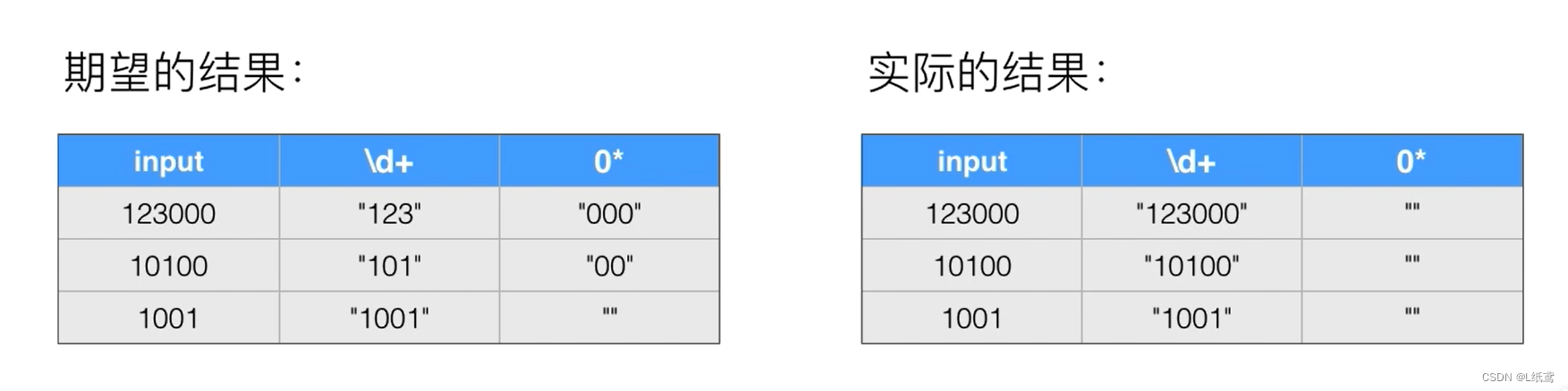
为什么会出现这样的结果呢?因为正则表达式默认的是贪婪匹配,就是说在匹配“^(\d+)”时,它会尽可能多的匹配,所以就会出现上面的结果
那应该怎么解决呢?使用非贪婪匹配
非贪婪匹配就是尽可能少的匹配,它是用“?”来实现的,所以为了实现上面的案例,我们的正则表达式应该为“^(\d+?)(0*)”
这就是非贪婪匹配
6.使用正则表达式进行搜索和替换
使用正则表达式对字符串进行搜索和替换,其实本质上就是对StringAPI的调用。我们需要熟悉StringAPI,然后熟悉正则表达式,编写正确的正则表达式就可以啦。
在java中正则表达式并不是一个重点内容,但是大家还是要有所了解。