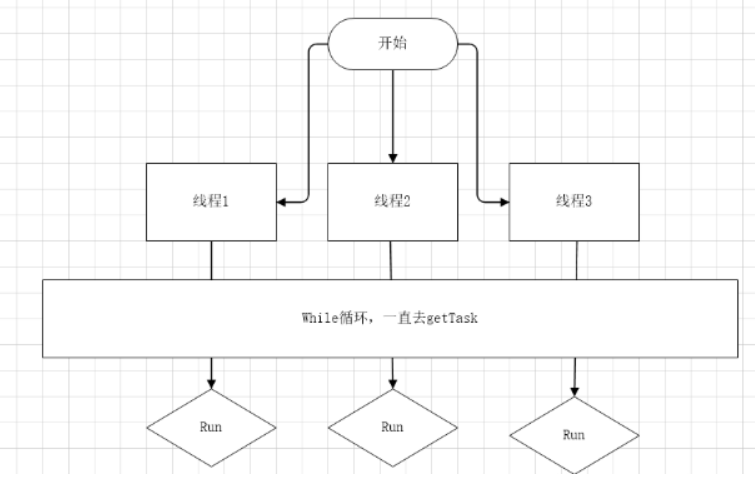
Fork调用创建进程
在实验1中通过gdb调试初步熟悉了Nahcos上下文切换的基本流程,但这个过程还不够清晰,通过源码阅读进一步了解这个过程。
在实验1中通过执行Threadtest,Fork创建子进程,并传入SimpleThread执行currentThread->Yield()进行进程切换:
//----------------------------------------------------------------------
// SimpleThread
// Loop 5 times, yielding the CPU to another ready thread
// each iteration.
//
// "which" is simply a number identifying the thread, for debugging
// purposes.
//----------------------------------------------------------------------
void
SimpleThread(_int which)
{
int num;
for (num = 0; num < 5; num++) {
printf("*** thread %d looped %d times\n", (int) which, num);
currentThread->Yield(); // 模拟时间片用完,Yield进入就绪队列
}
}
//----------------------------------------------------------------------
// ThreadTest
// Set up a ping-pong between two threads, by forking a thread
// to call SimpleThread, and then calling SimpleThread ourselves.
//----------------------------------------------------------------------
void
ThreadTest()
{
DEBUG('t', "Entering SimpleTest");
Thread *t = new Thread("forked thread");
t->Fork(SimpleThread, 1); // fork之后父子进程轮转协作,运行SimpleThread
SimpleThread(0);
}
在实验8中通过系统调用Exec执行Fork进行子进程的创建,传入StartProcess,与实验1不同,这个Fork是为用户程序创建进程,需要进行地址空间的拷贝,调用InitRegisters初始化CPU寄存器,调用RestoreState加载页表(在处理SC_Exec时已经分配好了用户程序的地址空间),并调用machine::run()执行。
case SC_Exec:
{
printf("Execute system call of Exec()\n");
// read argument
char filename[50];
int addr = machine->ReadRegister(4);
int i = 0;
do
{
// read filname from mainMemory
machine->ReadMem(addr + i, 1, (int *)&filename[i]);
} while (filename[i++] != '\0');
printf("Exec(%s)\n", filename);
// 为halt.noff创建相应的进程以及相应的核心线程
// 将该进程映射至新建的核心线程上执行begin
DEBUG('x', "thread:%s\tExec(%s):\n", currentThread->getName(), filename);
// if (filename[0] == 'l' && filename[1] == 's') // ls
// {
// DEBUG('x', "thread:%s\tFile(s) on Nachos DISK:\n", currentThread->getName());
// fileSystem->List();
// machine->WriteRegister(2, 127); //
// AdvancePC();
// return;
// }
// OpenFile *executable = fileSystem->OpenTest(filename);
OpenFile *executable = fileSystem->Open(filename);
AddrSpace *space;
if (executable == NULL)
{
printf("Unable to open file %s\n", filename);
// return;
ASSERT(false);
}
space = new AddrSpace(executable);
// printf("u:Fork\n");
Thread *thread = new Thread(filename);
thread->Fork(StartProcess, space->getSpaceId());
// end
// return spaceID
machine->WriteRegister(2, space->getSpaceId());
AdvancePC();
currentThread->Yield();
delete executable;
break;
}
Yield调度线程执行
但是Fork出的子程序并不是立即执行的!进程的调度由Scheduler负责,Fork前会将该进程加入到就绪队列中。如果我们不用任何进程调度命令,bar程序在执行完系统调用之后,会继续执行该程序剩下的指令,并不会跳转到halt程序执行,因此需要在系统调用返回前调用currentThread->Yield,切换执行halt进程,这样才是完整的Exec系统调用。
nextThread = scheduler->FindNextToRun();
if (nextThread != NULL) {
scheduler->ReadyToRun(this);
scheduler->Run(nextThread);
}
scheduler::run
Yield调用scheduler::run执行:
void
Scheduler::Run (Thread *nextThread)
{ // 运行一个新线程
Thread *oldThread = currentThread;
#ifdef USER_PROGRAM // ignore until running user programs
// 1. 将当前CPU寄存器的内容保存到旧进程的用户寄存器中
// 2. 保存用户页表
if (currentThread->pcb->space != NULL) { // if this thread is a user program,
currentThread->SaveUserState(); // save the user's CPU registers
currentThread->pcb->space->SaveState();
}
#endif
oldThread->CheckOverflow(); // check if the old thread
// had an undetected stack overflow
currentThread = nextThread; // switch to the next thread
currentThread->setStatus(RUNNING); // nextThread is now running
// 将线程指针指向新线程
DEBUG('t', "Switching from thread \"%s\" to thread \"%s\"\n",
oldThread->getName(), nextThread->getName());
// This is a machine-dependent assembly language routine defined
// in switch.s. You may have to think
// a bit to figure out what happens after this, both from the point
// of view of the thread and from the perspective of the "outside world".
// 从线程和外部世界的视角
SWITCH(oldThread, nextThread);
// 此时寄存器(非通用数据寄存器,可能是PC,SP等状态寄存器)的状态还未保存和更新
DEBUG('t', "Now in thread \"%s\"\n", currentThread->getName());
// If the old thread gave up the processor because it was finishing,
// we need to delete its carcass. Note we cannot delete the thread
// before now (for example, in Thread::Finish()), because up to this
// point, we were still running on the old thread's stack!
if (threadToBeDestroyed != NULL) {
delete threadToBeDestroyed; // 回收旧线程的堆栈
threadToBeDestroyed = NULL;
}
#ifdef USER_PROGRAM
// 1. 如果运行用户进程,需要将当前进程的用户寄存器内存加载到CPU寄存器中
// 2. 并且加载用户页表
if (currentThread->pcb->space != NULL) { // if there is an address space
currentThread->RestoreUserState(); // to restore, do it.
currentThread->pcb->space->RestoreState();
}
#endif
}
①首尾两部分是用户寄存器和CPU寄存器之间的操作,将40个CPU寄存器的状态保存至用户寄存器,将新进程的用户寄存器加载至CPU寄存器,并加载用户程序页表。
②检查栈溢出。
③将currentThread指向新进程,将其状态设置为RUNNING。
④调用汇编程序SWITCH,实验1中此处的注释是该程序保存并更新寄存器的状态,可是这不是在①部分code做的事情?
⑤回收进程堆栈。
SWITCH初步探索
结合源码进行分析:
#ifdef HOST_i386
/* void SWITCH( thread *t1, thread *t2 )
**
** on entry, stack looks like this:
** 8(esp) -> thread *t2
** 4(esp) -> thread *t1
** (esp) -> return address
**
** we push the current eax on the stack so that we can use it as
** a pointer to t1, this decrements esp by 4, so when we use it
** to reference stuff on the stack, we add 4 to the offset.
*/
.comm _eax_save,4
.globl _SWITCH
_SWITCH:
movl %eax,_eax_save # save the value of eax
movl 4(%esp),%eax # move pointer to t1 into eax
movl %ebx,_EBX(%eax) # save registers
movl %ecx,_ECX(%eax)
movl %edx,_EDX(%eax)
movl %esi,_ESI(%eax)
movl %edi,_EDI(%eax)
movl %ebp,_EBP(%eax)
movl %esp,_ESP(%eax) # save stack pointer
movl _eax_save,%ebx # get the saved value of eax
movl %ebx,_EAX(%eax) # store it
movl 0(%esp),%ebx # get return address from stack into ebx
movl %ebx,_PC(%eax) # save it into the pc storage
movl 8(%esp),%eax # move pointer to t2 into eax
......
movl _eax_save,%eax
ret
#endif // HOST_i386
的确是寄存器的保存与加载,但这个寄存器和前面的CPU、用户寄存器有什么不同?实际上它们对应0-32(Step=4)之间数字。
#define _ESP 0
#define _EAX 4
#define _EBX 8
#define _ECX 12
#define _EDX 16
#define _EBP 20
#define _ESI 24
#define _EDI 28
#define _PC 32
StackAllocate开辟堆栈存储进程信息
关注Thread::StackAllocate,将无关部分删除。可看到该函数在StartProcess中也被调用,用于为进程创建堆栈,是的,Nachos的堆栈并不是在内存中进行创建,内存中仅仅存放了noff文件加载进来的内容。
调用AllocBoundedArray分配了StackSize 的堆栈空间,之后将stack+StackSize-4的位置设置为栈顶stackTop,之后在stack位置处设置了一个标志STACK_FENCEPOST,用于检查堆栈溢出(②),当该标志被修改,代表堆栈溢出了。也就是stack维护栈底,stackTop维护栈顶。
ASSERT((unsigned int)*stack == STACK_FENCEPOST);
void
Thread::StackAllocate (VoidFunctionPtr func, _int arg)
{ // 栈分配
stack = (int *) AllocBoundedArray(StackSize * sizeof(_int));
// i386 & MIPS & SPARC & ALPHA stack works from high addresses to low addresses
stackTop = stack + StackSize - 4; // -4 to be on the safe side!
*stack = STACK_FENCEPOST;
machineState[PCState] = (_int) ThreadRoot;
machineState[StartupPCState] = (_int) InterruptEnable;
machineState[InitialPCState] = (_int) func;
machineState[InitialArgState] = arg;
machineState[WhenDonePCState] = (_int) ThreadFinish;
}
注意到Thread类将stackTop和machineState的定义提前了,而SWITCH的参数为Thread*,其操作的也是0偏移量为32以内的内存单元,因此SWITCH操作的“寄存器”就是stackTop和machineState,以及Linux系统的寄存器%ebx,%eax,%esp等等。
class Thread {
private: // 特意提前,保证SWITCH例程正常
// NOTE: DO NOT CHANGE the order of these first two members.
// THEY MUST be in this position for SWITCH to work.
int* stackTop; // the current stack pointer
_int machineState[MachineStateSize]; // all registers except for stackTop
public:
结合下面宏定义,了解machineState中各个寄存器存储内容的含义。
#define PCState (_PC/4-1)
#define FPState (_EBP/4-1)
#define InitialPCState (_ESI/4-1)
#define InitialArgState (_EDX/4-1)
#define WhenDonePCState (_EDI/4-1)
#define StartupPCState (_ECX/4-1)
ThreadRoot维护进程的生命周期
那么machineState的“寄存器”存储了哪些信息?有什么作用?SWITCH之后Linux系统PC保存的应该是ThreadRoot的起始地址,因为4(%esp)是SWITCH的返回地址,它被设置为ThreadRoot的起始地址。这个函数模拟了一个进程的“一生”,初始化,执行,到终结。下面这几个调用函数的地址在StackAllocate最末尾被存储在machineState中,并在SWITCH中装载到Linux系统的寄存器中。
#define InitialPC %esi
#define InitialArg %edx
#define WhenDonePC %edi
#define StartupPC %ecx
.text
.align 2
.globl _ThreadRoot
/* void ThreadRoot( void )
**
** expects the following registers to be initialized:
** eax points to startup function (interrupt enable)
** edx contains inital argument to thread function
** esi points to thread function
** edi point to Thread::Finish()
*/
_ThreadRoot:
pushl %ebp
movl %esp,%ebp
pushl InitialArg
call StartupPC
call InitialPC
call WhenDonePC
# NOT REACHED
movl %ebp,%esp
popl %ebp
ret
SWITCH更新Linux寄存器状态
现在可以回答最开始的问题了,SWITCH程序保存和更新的是Linux系统寄存器的内容,将其保存到machinState寄存器中。不同于Nachos的用户寄存器和CPU寄存器,这两者是在执行用户程序时才会使用到,用于保存用户指令和机器指令的结果和状态,前者是Nachos得以在Linux机器上运行的基础,这也是为什么它必须要通过汇编代码实现的原因,要操纵Linux系统的寄存器。
回收进程堆栈
scheduler::run最后的语句,回收线程堆栈,这时当前线程仍然在执行,它回收的肯定不是当前线程的堆栈!实际上是已经结束的线程,执行Thread::Finish,会将threadToBeDestroyed指向自己。而Finish是在进程终结之时执行,ThreadRoot中call WhenDonePC就是执行Finish。It all makes sense!
总结
之前在阅读scheduler::run的时候,有一段SWITCH注释让我很迷惑,“You may have to think a bit to figure out what happens after this, both from the point of view of the thread and from the perspective of the “outside world”.”,这个从外部世界去看是什么意思?现在,我也许有了答案。Nachos终归是运行在Linux上的操作系统,用了很多设计Timer,Scheduler,Interrupt模拟了machine,也就是硬件,但是归根结底,它只是运行在Linux系统上的一个进程,Linux系统的PC寄存器保存着Nachos“程序”正在执行的指令地址,为了实现Nachos系统的进程切换,在Linux的一个进程中的一个部分(Nachos进程)跳转到另一个部分,必须修改Linux系统的PC寄存器以及其他寄存器。为了操作Linux系统的寄存器,也就是实际物理硬件的寄存器,必须通过汇编程序进行,因此有了两个SWITCH和ThreadRoot两个汇编方法调用。在Nachos上下文切换中,前者更新Linux寄存器的内容,后者管理进程(除了在Initialize方法中创建的第一个线程main)的生命周期,通过Linux寄存器调用进程初始化StartupPC,运行InitialPC,终结WhenDonePC的3个过程。






![[论文笔记]C^3F,MCNN:图片人群计数模型](https://img-blog.csdnimg.cn/e9025f1d6d7f4b349e9bae36b1cfe15f.png)
![[oeasy]python0141_自制模块_module_reusability_复用性](https://img-blog.csdnimg.cn/img_convert/a227eff5be6dce210c71892f74258df2.png)