文章目录
- 一、压力测试
- 1、优化需求
- 2、性能指标
- 3、安装Jmeter
- 4、压力测试
- 5、优化日志
- 二、缓存优化
- 1、给接口加Redis缓存
- 2、缓存穿透
- 3、解决缓存穿透
- 4、缓存雪崩
- 5、缓存击穿
- 三、分布式锁
- 1、本地锁的问题
- 2、IDEA一个项目启动多个实例
- 3、分布式锁
- 4、Redis NX实现分布式锁
- 5、Redisson实现分布式锁
一、压力测试
从项目的门户开始,用户访问域名进入门户,如果一进来就有很多东西要查数据库,则性能必然很差。对于一些不常变动的,可以做页面静态化,对于一些接口,要优化性能。
压力测试是通过测试工具制造大规模的并发请求去访问系统,测试系统是否经受住压力。不仅接口需要压力测试,整个微服务在发布前也是需要经历压力测试。比如:一个在线学习网站,上线要求该网站可以支持1万用户同时在线,此时就需要模拟1万并发请求去访问网站的关键业务流程,比如:测试点播学习流程,测试系统是否可以抗住1万并发请求。
一些功能测试时无法发现的问题在压力测试时就会发现,比如:内存泄露、线程安全、IO异常等问题。
1、优化需求
对于一些接口,在用户未认证状态下也可以访问,如果接口的性能不高,当高并发到来很可能耗尽整个系统的资源,将整个系统压垮,所以特别需要对这些暴露在外边的接口进行优化。 在本项目中,如根据课程id查询课程信息接口:

待优化API:
/open/content/course/whole/{courseId}
2、性能指标
压力测试常用的性能指标有:
吞吐量:
吞吐量是系统每秒可以处理的事务数,也称为TPS(Transaction Per Second)。
比如:一次点播流程,从请求进入系统到视频画图显示出来这整个流程就是一次事务。所以吞吐量并不是一次数据库事务,它是完成一次业务的整体流程。
响应时间:
响应时间是指客户端请求服务端,从请求进入系统到客户端拿到响应结果所经历的时间。响应时间包括:最大响应时间、最小响应时间、平均响应时间。
每秒查询数:
每秒查询数即QPS(Queries-per-second),它是衡量查询接口的性能指标。比如:商品信息查询, 一秒可以请求该接口查询商品信息的次数就是QPS。
拿查询接口举例,一次查询请求内部不会再去请求其它接口,此时 QPS=TPS
如果一次查询请求内容需要远程调用另一个接口查询数据,此时 QPS=2 * TPS
错误率:
错误率 是一批请求发生错误的请求占全部请求的比例。
这些指标应该综合起来看,不同的指标要求也不同,但方向都是:
- 响应时间越来越小
- 吞吐量越来越大
- QPS越来越大
- 错误率保持在一个很小的范围
此外,还要关注系统的负载情况:
- CPU使用率,不高于85%
- 内存利用率,不高于 85%
- 网络利用率,不高于 80%
- 磁盘IO:磁盘IO的性能指标是IOPS (Input/Output Per Second)即每秒的输入输出量(或读写次数)。如果过大说明IO操作密集,IO过大也会影响性能指标
优化前,要根据测试结果分析瓶颈在磁盘IO,在CPU,在数据库,还是本身代码问题。
3、安装Jmeter
Apache JMeter 是 Apache 组织基于 Java 开发的压力测试工具,用于对软件做压力测试。
- 下载https://jmeter.apache.org/download_jmeter.cgi

- 解压,进入bin目录修改jmeter.properties,设置中文和字体(粘贴到该文件末尾即可)
language=zh_CN
jmeter.hidpi.mode=true
jmeter.hidpi.scale.factor=1.8
jsyntaxtextarea.font.family= Hack
jsyntaxtextarea.font.size=25
jmeter.toolbar.icons.size=32x32
- 双击运行bin目录下的jmeter.bat文件
点击 jmeter.bat 后闪退
解决:编辑环境变量,找到JMETER_HOME删除,然后运行,CLASSPATH里配置
D:\ceshi\jmeter\apache-jmeter-4.0\lib\ext\ApacheJMeter_core.jar;D:\ceshi\jmeter\apache-jmeter-4.0\lib\jorphan.jar;
如果是%JMETER_HOME%最好换掉
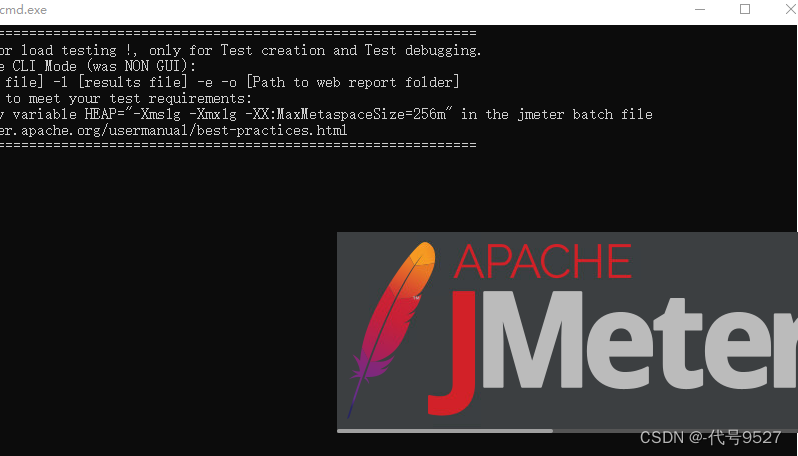
- 启动成功
4、压力测试
-
压力机:通常压力机是单独的干净的客户端
-
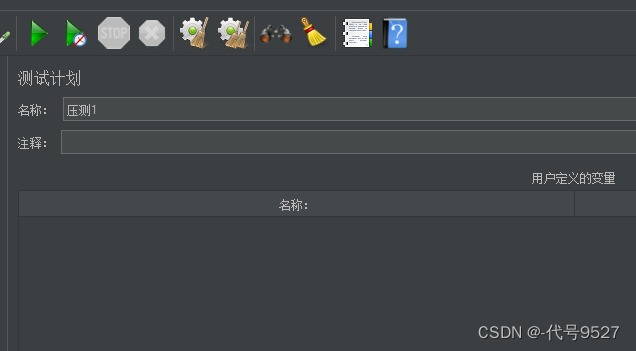
添加测试计划
-
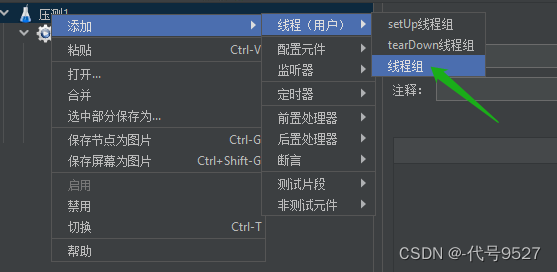
在测试计划下添加线程组
-
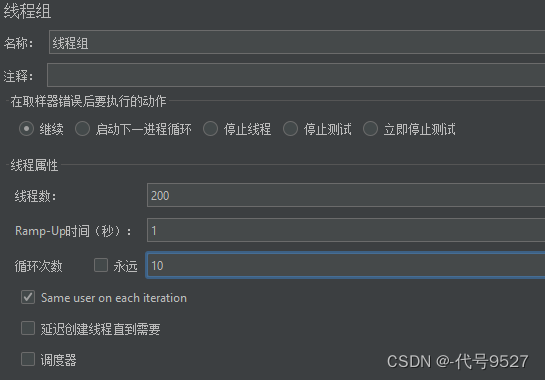
200个线程,每个线程请求10次,一秒内完成。即一秒200X10=2000次请求
-
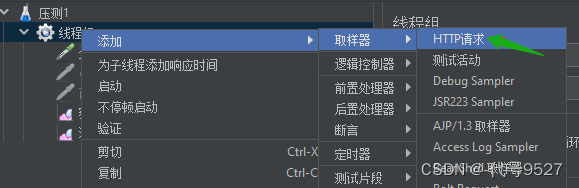
添加取样器,输入host、port、path
-
添加监听器–结果树和汇总报告
-
点击启动
-
测试完成
5、优化日志
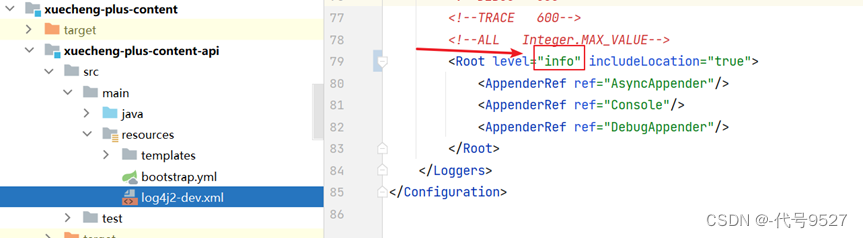
debug级别输出大量日志,影响性能。开发阶段用debug,上线就info。
二、缓存优化
1、给接口加Redis缓存
数据库连接资源珍贵,但优化的这个接口,不存在复杂的SQL,也不存在数据库连接不释放的问题,暂时不考虑数据库方面的优化。而课程发布信息修改很少,这里考虑将课程发布信息进行缓存。
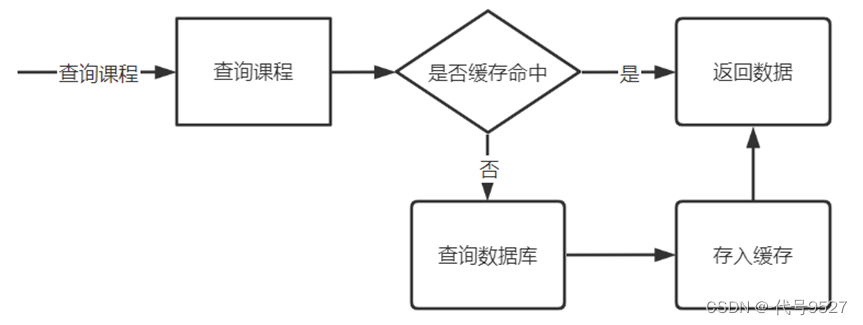
- 首先在nacos中加入redis的配置文件redis-dev.yaml
spring:
redis:
host: 6.6.6.6
port: 6379
password: redis
database: 0
lettuce:
pool:
max-active: 20
max-idle: 10
min-idle: 0
timeout: 10000
- 在接口所在服务中,引入这个配置
shared-configs:
- data-id: redis-${spring.profiles.active}.yaml
group: xuecheng-plus-common
refresh: true
- 添加依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
<version>2.6.2</version>
</dependency>
- 在原Service接口中定义的方法下面,
定义查询缓存的接口
//原方法
public CoursePublish getCoursePublish(Long courseId);
/**
* @description 查询缓存中的课程信息
* @param courseId
* @return
*/
public CoursePublish getCoursePublishCache(Long courseId);
写实现:
public class CoursePublishServiceImpl implements CoursePublishService{
...
@Autowired
RedisTemplate redisTemplate;
...
@Override
public CoursePublish getCoursePublishCache(Long courseId){
//查询缓存,这里加入之前第一次查时往Redis里存时key的命名是course+id
Object jsonObj = redisTemplate.opsForValue().get("course:" + courseId);
if(jsonObj!=null){
//查到了
String jsonString = jsonObj.toString();
CoursePublish coursePublish = JSON.parseObject(jsonString, CoursePublish.class);
return coursePublish;
} else {
//从数据库查询
CoursePublish coursePublish = getCoursePublish(courseId);
//查到的结果若不为空则存到redis
if(coursePublish!=null){
redisTemplate.opsForValue().set("course:" + courseId, JSON.toJSONString(coursePublish));
}
return coursePublish;
}
}
}
- 最后修改controller
@ApiOperation("获取课程发布信息")
@ResponseBody
@GetMapping("/course/whole/{courseId}")
public CoursePreviewDto getCoursePublish(@PathVariable("courseId") Long courseId) {
//调用新方法,查询课程发布信息
CoursePublish coursePublish = coursePublishService.getCoursePublishCache(courseId);
//CoursePublish coursePublish = coursePublishService.getCoursePublish(courseId);
if(coursePublish==null){
return new CoursePreviewDto();
}
//课程基本信息
CourseBaseInfoDto courseBase = new CourseBaseInfoDto();
BeanUtils.copyProperties(coursePublish, courseBase);
//课程计划
List<TeachplanDto> teachplans = JSON.parseArray(coursePublish.getTeachplan(), TeachplanDto.class);
CoursePreviewDto coursePreviewInfo = new CoursePreviewDto();
coursePreviewInfo.setCourseBase(courseBase);
coursePreviewInfo.setTeachplans(teachplans);
return coursePreviewInfo;
}
此时再测性能,吞吐量翻倍了。
2、缓存穿透
高并发下(jmeter中模拟一秒内请求查询2000次课程A),第一次查询课程,按代码逻辑,只需查一次数据库,后续走Redis。但看日志可知有大量请求都在查数据库。这是因为并发数高,很多线程会同时到达查询数据库代码处去执行。
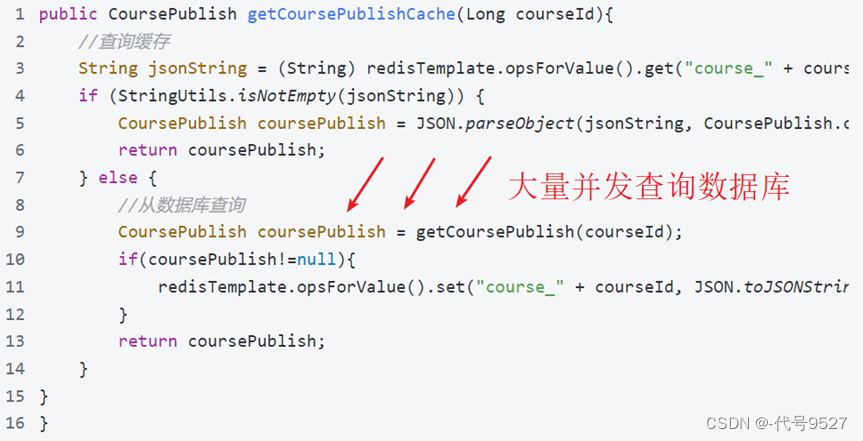
假如存在恶意攻击,查一个不存在的课程信息,则全部并发都会去请求数据库,造成数据库瞬间压力过大,连接数等资源用完,最终数据库拒绝连接不可用。
大量并发去访问一个数据库不存在的数据,由于缓存中没有该数据导致大量并发查询数据库,这个现象叫
缓存穿透。
3、解决缓存穿透
思路一:对请求增加校验机制
对传入的参数进行格式校验,如课程号一般是9527开头的长整型,如果不是长整型或者不是9527打头,则判定为非法请求直接返回。
思路二:布隆过滤器

- 布隆过滤器可以用于检索一个元素是否在一个集合中
- 布隆过滤器的特点是,高效地插入和查询,占用空间少
- 查询结果有不确定性,查到存在(返回1),不一定就存在,但返回0 ,一定不存在
- 只能添加元素不能删除元素,因为删除元素会增加误判率
- 为了避免缓存穿透,需要提前将商品信息id存入布隆过滤器,即缓存预热
- 落地实现有Google工具包Guava
思路三:
缓存空值或特殊值
被全部穿透是因为,在数据库查到null,没写进Reids。那现在即使是空我也存进Redis,缓存一个空值或一个特殊值的数据即可解决。如果缓存了空值或特殊值要设置一个短暂的过期时间。
public CoursePublish getCoursePublishCache(Long courseId) {
//查询缓存
Object jsonObj = redisTemplate.opsForValue().get("course:" + courseId);
if(jsonObj!=null){
String jsonString = jsonObj.toString();
if("null".equals(jsonString)){
//如果为空,则不用解析成对象了
return null;
}
CoursePublish coursePublish = JSON.parseObject(jsonString, CoursePublish.class);
return coursePublish;
} else {
//从数据库查询
CoursePublish coursePublish = getCoursePublish(courseId);
//设置过期时间30秒,别占坑,防止一会儿有数据了,你还存个null
redisTemplate.opsForValue().set("course:" + courseId, JSON.toJSONString(coursePublish),30, TimeUnit.SECONDS);
return coursePublish;
}
}
4、缓存雪崩
高并发下,存入Redis的大量的key拥有相同的过期时间,从而大量的key同时失效,导致大量请求又同时到了数据库,这就是缓存雪崩。
解决思路一:使用同步锁控制查询数据库的线程
使用同步锁控制查询数据库的线程,只允许有一个线程去查询数据库,查询得到数据后存入缓存,如此就不会有大量的key拥有相同的过期时间。
//但这时性能肯定也受影响了
synchronized(obj){
//查询数据库
//存入缓存
}
解决思路二:过期时间+随机数
通常对一类信息的key(如course开头的key)设置的过期时间是相同的,那就可以在原有过期固定时间的基础上加上一个随机时间使它们的过期时间都不相同。
//设置过期时间300秒
redisTemplate.opsForValue()
.set("course:" + courseId, JSON.toJSONString(coursePublish),300+new Random().nextInt(100), TimeUnit.SECONDS);
解决思路三:缓存预热
后台写定时任务,不用等到请求到来再去查询数据库存入缓存,去将数据分批次提前存入缓存。
5、缓存击穿
缓存击穿是指大量并发访问同一个热点数据,当热点数据失效后同时去请求数据库,瞬间耗尽数据库资源,导致数据库无法使用。比如某手机新品发布,当缓存失效时有大量并发到来导致同时去访问数据库。
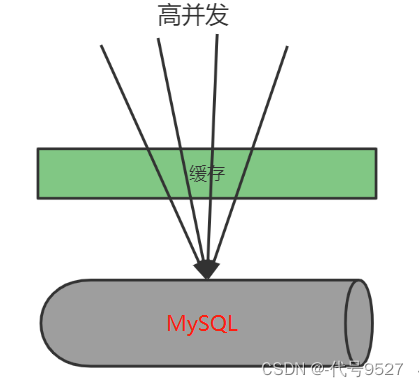
解决思路一:同步锁控制查询数据库的线程
使用同步锁控制查询数据库的代码,只允许有一个线程去查询数据库,查询得到数据库存入缓存。
synchronized(obj){
//查询数据库
//存入缓存
}
public CoursePublish getCoursePublishCache(Long courseId){
//写this,Bean是单例,即可达到效果
synchronized(this){
//查询缓存
String jsonString = (String) redisTemplate.opsForValue().get("course:" + courseId);
if(StringUtils.isNotEmpty(jsonString)){
if(jsonString.equals("null"))
return null;
CoursePublish coursePublish = JSON.parseObject(jsonString, CoursePublish.class);
return coursePublish;
}else{
//从数据库查询
CoursePublish coursePublish = getCoursePublish(courseId);
//设置过期时间300秒
redisTemplate.opsForValue().set("course:" + courseId, JSON.toJSONString(coursePublish),300, TimeUnit.SECONDS);
return coursePublish;
}
}
}
此时,过期时间到了以后,进来一个线程,只查一次数据库,下一个线程进来拿到锁,此时Redis已有数据,但这时吞吐量很低。继续优化上面的代码,查Redis是可以多线程访问的,只需要限制查数据库即可。
public CoursePublish getCoursePublishCache(Long courseId){
//查询缓存
Object jsonObj = redisTemplate.opsForValue().get("course:" + courseId);
if(jsonObj!=null){
String jsonString = jsonObj.toString();
CoursePublish coursePublish = JSON.parseObject(jsonString, CoursePublish.class);
return coursePublish;
}else{
synchronized(this){
//为什么要在这儿再写一次查缓存?
//因为同步代码块缩小范围后,可能出现:
//一个线程已经把结果放进Redis,但同时到达来抢锁而没抢到的另一个线程,在查询结果存进Redis前,已经走过了上面的查Redis,到了同步代码块前。
Object jsonObj = redisTemplate.opsForValue().get("course:" + courseId);
if(jsonObj!=null){
String jsonString = jsonObj.toString();
CoursePublish coursePublish = JSON.parseObject(jsonString, CoursePublish.class);
return coursePublish;
}
//从数据库查询
CoursePublish coursePublish = getCoursePublish(courseId);
//设置过期时间300秒
redisTemplate.opsForValue().set("course:" + courseId, JSON.toJSONString(coursePublish),300, TimeUnit.SECONDS);
return coursePublish;
}
}
}
此时,只锁查数据库,查Redis是可以并发的,性能又提高了很多。(尽量缩小同步块的范围)注意这里同步块里查数据库前又查一次缓存的细节!
解决思路二:热点数据不过期
设置热点key的过期时间为永不过期。
最后,总结:
无中生有是穿透,布隆过滤null隔离。
大量过期成雪崩,过期时间要随机。
缓存击穿key过期, 锁与非期解难题。
面试必考三兄弟,可用限流来保底。
限流技术方案:
alibaba/Sentinel
nginx+Lua
三、分布式锁
1、本地锁的问题
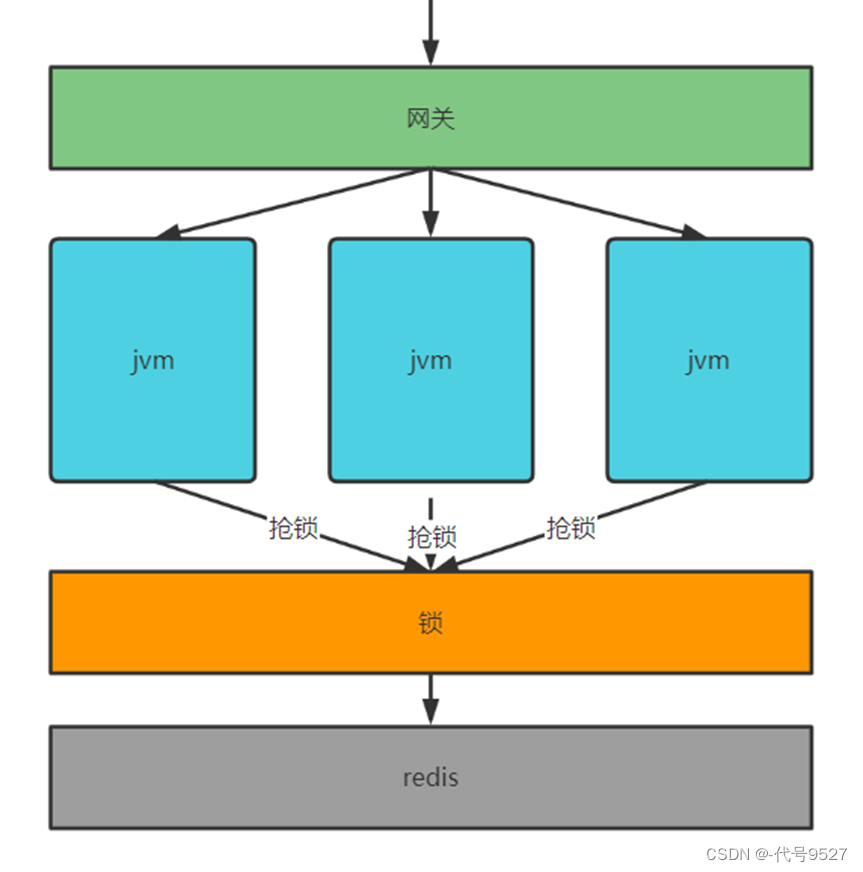
上面使用同步锁解决了缓存击穿和缓存雪崩。但如果将同步锁的程序分布式部署在多个虚拟机上则无法保证同一个key只会查询一次数据库,如下图:
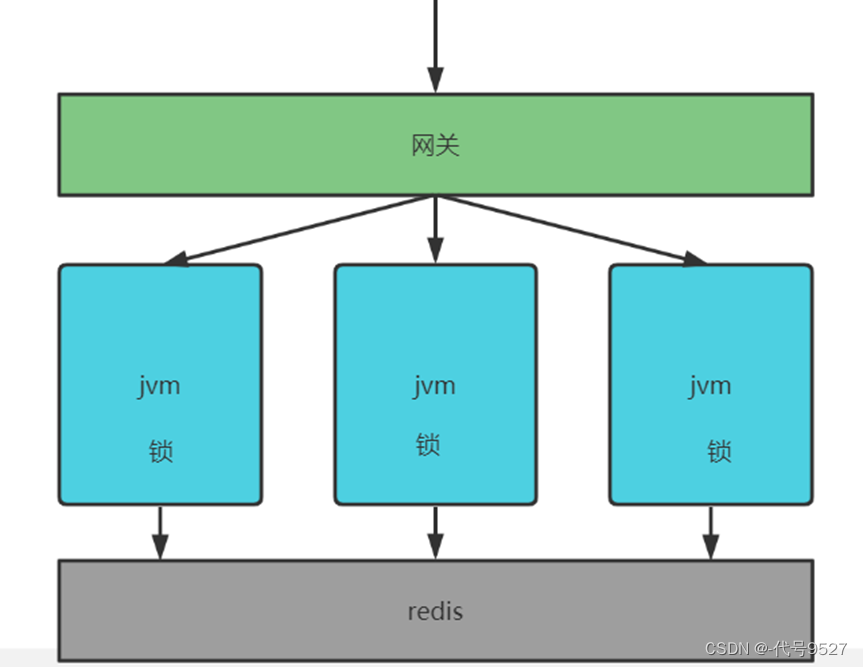
一个同步锁程序只能保证同一个虚拟机中多个线程只有一个线程去数据库,如果高并发通过网关负载均衡转发给各个虚拟机,此时就会存在多个线程去查询数据库情况,因为虚拟机中的锁只能保证该虚拟机自己的线程去同步执行,无法跨虚拟机保证同步执行。 这种虚拟机内部的锁,叫本地锁,本地锁只能保证所在虚拟机的所有线程去同步执行。
2、IDEA一个项目启动多个实例
IDEA的启动默认是单实例的,想模拟分布式集群,即通过一份代码启动多个实例。
-
配置文件指定端口,启动项目后出现第一个实例
-
点击编辑配置
-
复制相关的服务
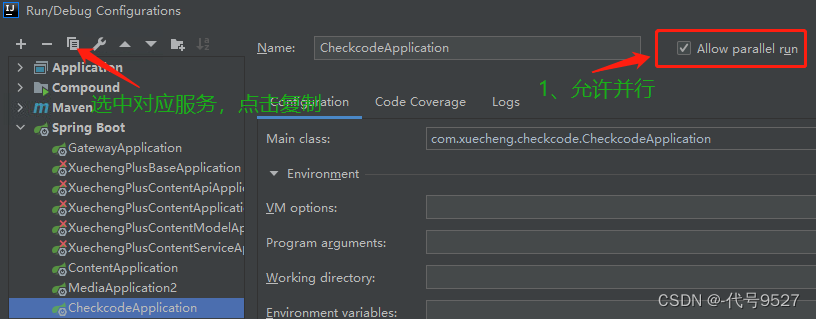
-
-Dserver.port=63076指定一个新的端口,点击OK
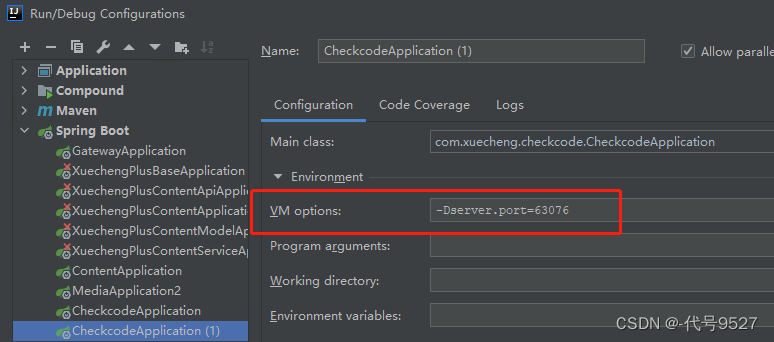
-
设置本地配置优先,让上面指定的端口别被其他优先级高的配置覆盖
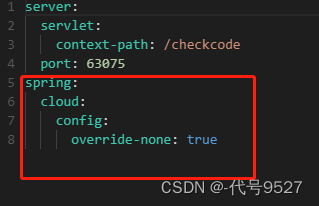
-
点击启动
-
还可以配置一个批量启动
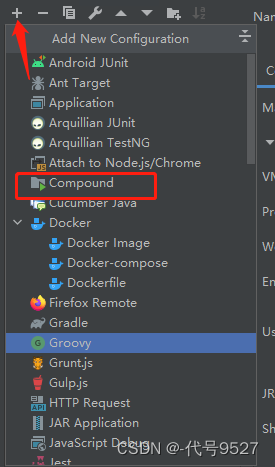
-
加入刚配置好的几个服务实例
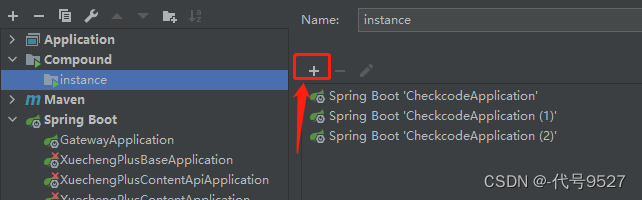
-
点击启动即可同时启动多个实例
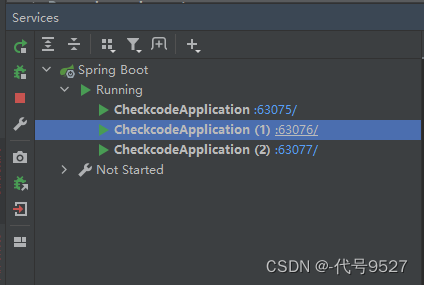
此时通过网关访问这个服务,网关通过负载均衡将请求转发给三个服务。此时压测,可以看到每个服务分别查了一次数据库后才走Redis,即本地锁无法跨虚拟机保证同步执行。
3、分布式锁
本地锁只能控制所在虚拟机中的线程同步执行,现在要实现分布式环境下所有虚拟机中的线程去同步执行就需要让多个虚拟机去共用一个锁。虚拟机都去抢占同一个锁,锁是一个单独的程序提供加锁、解锁服务,谁抢到锁谁去查询数据库。
该锁已不属于某个虚拟机,而是分布式部署,由多个虚拟机所共享,这种锁叫分布式锁。
分布式锁的实现方案有:
- 基于数据库实现分布式锁:利用数据库主键唯一性的特点,或利用数据库唯一索引的特点,多个线程同时去插入相同的记录,谁插入成功谁就抢到锁。
- 基于redis实现锁:比如:SETNX、set nx、redisson
- 使用zookeeper实现
4、Redis NX实现分布式锁
官方文档:http://www.redis.cn/commands/set.html
实现指令:
SET [resource-name] [anystring] NX EX [max-lock-time]
# 参数
resource-name: 随便起,锁名
anystring: value值
NX: 表示key不存在才设置成功
EX: 设置过期时间
SET lock001 001 NX EX 30
都去执行这个指令,谁SET成功了,就表示抢到锁了。抢到锁的人,在过期时间内执行自己的操作。不设置过期时间,则后续服务一直不能SET成功,也就一直不能抢到锁。
具体实现:
使用spring-boot-starter-data-redis 提供的api即可实现set nx:
- 添加依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
<version>2.6.2</version>
</dependency>
- 在bean中注入restTemple
@Autowired
RedisTemplate redisTemplate;
- 伪代码:
if(缓存中有){
返回缓存中的数据
}else{
获取分布式锁
if(获取锁成功){
try{
查询数据库
}finally{
释放锁
}
}
}
- 获取分布式锁
// 调用这个方法即执行Set xx NX指令
boolean result = redisTemplate.opsForValue().setIfAbsent("coursequerylock"+ courseId,"01")
//调用setIfAbsent的重载方法设置过期时间
//否则万一在执行finally前出现异常,导致finally语句未执行,则会导致其他线程无法获取锁
boolean result = redisTemplate.opsForValue().setIfAbsent(K var1, V var2, long var3, TimeUnit var5)
释放锁
key到期,自动释放锁,此时有个问题:查询数据库等操作还没有执行完时key到期了,此时其它线程就抢到锁了,最终重复查询数据库。设置一个较长的过期时间又会造成不必要的等待,影响效率。考虑手动删除锁:
redisTemplate.call("del","lock");
但此时存在问题:线程A查询操作还没结束时,key过期,另一个线程B抢锁成功,线程A操作结束后,执行finally,把锁删除了,但此时删除的却是别人的锁。可在finally中加判断解决。
if(缓存中有){
返回缓存中的数据
}else{
//获取分布式锁: set lock 01 NX
if(获取锁成功){
try{
查询数据库
}finally{
//判断这个锁是不是自己设置的,是则删除
if(redis.call("get","lock")=="01"){
//释放锁:
redis.call("del","lock")
}
}
}
}
此时还有个问题:根据CPU切换线程执行,和CPU时间片的概念:
- 当线程A执行完if(redis.call(“get”,“lock”)==“01”),并为true,准备删除lock时,时间片用完
- 切换到线程B。而此刻线程A设置的key刚好过期,则线程B抢锁成功,set了lock,值为02
- 接下来CPU切回线程A继续执行,定位到redis.call(“del”,“lock”),执行则会删除线程B刚设置的锁
问题的根本在于这三行代码的执行要保证原子性:
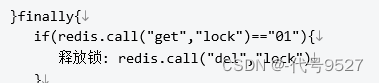
原子性即同成功,同失败,整个执行过程,CPU一气呵成的执行完,中间不要暂停,切换到其他线程。想实现原子性,Redis自己实现不了,得依靠Lua脚本:
Lua 是一个小巧的脚本语言,redis在2.6版本就支持通过执行Lua脚本保证多个命令的原子性。
解锁脚本对应于:
if redis.call("get",KEYS[1]) == ARGV[1]
then
return redis.call("del",KEYS[1])
else
return 0
end
最后,Redis NX始终不能解决的问题就是:过期时间不好把握,设置短了,会被其他线程抢锁(主要问题)。设置长了,万一发生错误(如:断电),导致finally中的解锁语句没被执行,则后续线程只能等key自动过期(次要)。
5、Redisson实现分布式锁
继续查看Redis文档:http://www.redis.cn/commands/set.html

进入找到Java的实现方案:

Redisson的文档地址:
https://github.com/redisson/redisson/wiki/Table-of-Content
Tip:
Ctrl+Alt+L调整代码格式.
Ctrl+Alt+v自动补全变量名和变量类型.
Redisson是一个在Redis的基础上实现的Java驻内存数据网格(In-Memory Data Grid)。它不仅提供了一系列的分布式的Java常用对象,还提供了许多分布式服务。

Redisson相比set nx实现分布式锁要简单的多,工作原理如下:
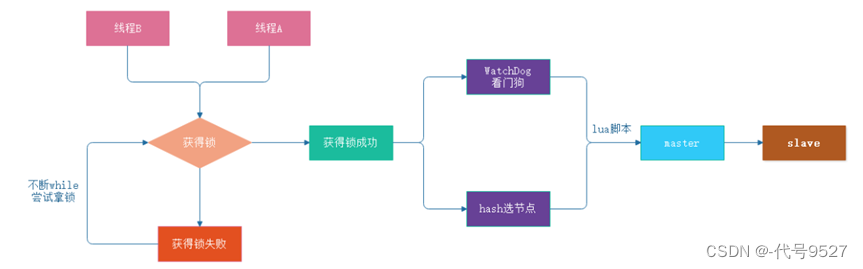
加锁机制
- 线程去获取锁,获取成功: 执行lua脚本,保存数据到redis数据库
- 线程去获取锁,获取失败: 一直通过while循环尝试获取锁(自旋锁),获取成功后,执行lua脚本,保存数据到redis
- Redisson 的分布式锁实现支持自旋锁和阻塞锁,其中自旋锁不会阻塞线程,适合锁竞争不激烈的场景,而阻塞锁则可以避免线程的空转,适合锁竞争激烈的场景 。默认情况下 Redisson 使用阻塞锁,如果需要使用自旋锁,可:
RLock lock = redissonClient.getSpinLock("myLock");
WatchDog自动延期看门狗机制
- case1:在一个分布式环境下,假如一个线程获得锁后,突然服务器宕机了,一定时间后这个锁会自动释放,不设置过期时间默认30秒,防止死锁的发生
- case2:线程A业务还没有执行完,时间就过了,线程A 还想持有锁的话,就会启动一个watch dog后台线程,不断的延长锁key的生存时间 (假如设置60s,Redis中,可看到TTL从60降到二十几,又自动添加到三十几,反反复复,等你执行完)
使用Redission实现分布式锁
- 添加Redisson依赖
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
<version>3.11.2</version>
</dependency>
- 在redis的nacos配置文件中加配置:
spring:
redis:
redisson:
#配置文件目录
config: classpath:singleServerConfig.yaml
#redis集群模式下配置下面这个
#config: classpath:clusterServersConfig.yaml
- 配置singleServerConfig.yaml
---
singleServerConfig:
#如果当前连接池里的连接数量超过了最小空闲连接数,而同时有连接空闲时间超过了该数值,
#那么这些连接将会自动被关闭,并从连接池里去掉。时间单位是毫秒。
#默认值:10000
idleConnectionTimeout: 10000
pingTimeout: 1000
#同任何节点建立连接时的等待超时。时间单位是毫秒。
#默认值:10000
connectTimeout: 10000
#等待节点回复命令的时间。该时间从命令发送成功时开始计时。
#默认值:3000
timeout: 3000
#如果尝试达到 retryAttempts(命令失败重试次数)
#仍然不能将命令发送至某个指定的节点时,将抛出错误。如果尝试在此限制之内发送成功,
#则开始启用 timeout(命令等待超时) 计时。
#默认值:3
retryAttempts: 3
#在某个节点执行相同或不同命令时,连续失败failedAttempts(执行失败最大次数)时,
#该节点将被从可用节点列表里清除,直到 reconnectionTimeout(重新连接时间间隔) 超时以后再次尝试。
#默认值:1500
retryInterval: 1500
#重新连接时间间隔
reconnectionTimeout: 3000
#执行失败最大次数
failedAttempts: 3
#密码
password: redis
#数据库选择 select 4
database: 0
#每个连接的最大订阅数量。
#默认值:5
subscriptionsPerConnection: 5
#在Redis节点里显示的客户端名称。
clientName: null
#在Redis节点
address: "redis://192.168.101.65:6379"
#从节点发布和订阅连接的最小空闲连接数
#默认值:1
subscriptionConnectionMinimumIdleSize: 1
#用于发布和订阅连接的连接池最大容量。连接池的连接数量自动弹性伸缩。
#默认值:50
subscriptionConnectionPoolSize: 50
#节点最小空闲连接数
#默认值:32
connectionMinimumIdleSize: 32
#节点连接池大小
#默认值:64
connectionPoolSize: 64
#这个线程池数量被所有RTopic对象监听器,RRemoteService调用者和RExecutorService任务共同共享。
#默认值: 当前处理核数量 * 2
threads: 8
#这个线程池数量是在一个Redisson实例内,被其创建的所有分布式数据类型和服务,
#以及底层客户端所一同共享的线程池里保存的线程数量。
#默认值: 当前处理核数量 * 2
nettyThreads: 8
#Redisson的对象编码类是用于将对象进行序列化和反序列化,以实现对该对象在Redis里的读取和存储。
#默认值: org.redisson.codec.JsonJacksonCodec
codec: !<org.redisson.codec.JsonJacksonCodec> {}
#传输模式
#默认值:TransportMode.NIO
transportMode: "NIO"
(集群模式下的配置文件:)
---
clusterServersConfig:
#如果当前连接池里的连接数量超过了最小空闲连接数,而同时有连接空闲时间超过了该数值,
#那么这些连接将会自动被关闭,并从连接池里去掉。时间单位是毫秒。
#默认值:10000
idleConnectionTimeout: 10000
#同任何节点建立连接时的等待超时。时间单位是毫秒。
#默认值:10000
connectTimeout: 10000
#等待节点回复命令的时间。该时间从命令发送成功时开始计时。
#默认值:3000
timeout: 3000
#如果尝试达到 retryAttempts(命令失败重试次数)
#仍然不能将命令发送至某个指定的节点时,将抛出错误。如果尝试在此限制之内发送成功,
#则开始启用 timeout(命令等待超时) 计时。
#默认值:3
retryAttempts: 3
#在某个节点执行相同或不同命令时,连续失败failedAttempts(执行失败最大次数)时,
#该节点将被从可用节点列表里清除,直到 reconnectionTimeout(重新连接时间间隔) 超时以后再次尝试。
#默认值:1500
retryInterval: 1500
#密码
password: null
#每个连接的最大订阅数量。
#默认值:5
subscriptionsPerConnection: 5
clientName: null
#负载均衡算法类的选择
#默认值: org.redisson.connection.balancer.RoundRobinLoadBalancer
#在使用多个Elasticache Redis服务节点的环境里,可以选用以下几种负载均衡方式选择一个节点:
#org.redisson.connection.balancer.WeightedRoundRobinBalancer - 权重轮询调度算法
#org.redisson.connection.balancer.RoundRobinLoadBalancer - 轮询调度算法
#org.redisson.connection.balancer.RandomLoadBalancer - 随机调度算法
loadBalancer: !<org.redisson.connection.balancer.RoundRobinLoadBalancer> {}
slaveSubscriptionConnectionMinimumIdleSize: 1
slaveSubscriptionConnectionPoolSize: 50
slaveConnectionMinimumIdleSize: 32
slaveConnectionPoolSize: 64
masterConnectionMinimumIdleSize: 32
masterConnectionPoolSize: 64
readMode: "SLAVE"
nodeAddresses:
- "redis://192.168.200:129:7001"
- "redis://192.168.200.129:7002"
- "redis://192.168.200.129:7003"
scanInterval: 1000
threads: 0
nettyThreads: 0
codec: !<org.redisson.codec.JsonJacksonCodec> {}
"transportMode":"NIO"
- 代码完善
@Resource
RedissonClient redissonClient;
//Redisson分布式锁
public CoursePublish getCoursePublishCache(Long courseId){
//查询缓存
String jsonString = (String) redisTemplate.opsForValue().get("course:" + courseId);
if(StringUtils.isNotEmpty(jsonString)){
if(jsonString.equals("null")){
return null;
}
CoursePublish coursePublish = JSON.parseObject(jsonString, CoursePublish.class);
return coursePublish;
}else{
//每门课程设置一个锁
RLock lock = redissonClient.getLock("coursequerylock:"+courseId);
//获取锁
lock.lock();
try {
jsonString = (String) redisTemplate.opsForValue().get("course:" + courseId);
if(StringUtils.isNotEmpty(jsonString)){
CoursePublish coursePublish = JSON.parseObject(jsonString, CoursePublish.class);
return coursePublish;
}
System.out.println("=========从数据库查询==========");
//从数据库查询
CoursePublish coursePublish = getCoursePublish(courseId);
redisTemplate.opsForValue().set("course:" + courseId, JSON.toJSONString(coursePublish),1,TimeUnit.DAYS);
return coursePublish;
}finally {
//释放锁
lock.unlock();
}
}
}
此时,仍旧启动三个实例,模拟并发请求,可以看到三个实例中仅有一个请求了一次数据库。
最后,看一下RLock接口,它继承了JDK的Lock,因此有Lock接口的所有特性,比如lock、unlock、trylock,同时它还有很多新特性:强制锁释放,带有效期的锁。
public interface RLock {
//----------------------Lock接口方法-----------------------
/**
* 加锁 锁的有效期默认30秒
*/
void lock();
/**
* 加锁 可以手动设置锁的有效时间
*
* @param leaseTime 锁有效时间
* @param unit 时间单位 小时、分、秒、毫秒等
*/
void lock(long leaseTime, TimeUnit unit);
/**
* tryLock()方法是有返回值的,用来尝试获取锁,
* 如果获取成功,则返回true,如果获取失败(即锁已被其他线程获取),则返回false .
*/
boolean tryLock();
/**
* tryLock(long time, TimeUnit unit)方法和tryLock()方法是类似的,
* 只不过区别在于这个方法在拿不到锁时会等待一定的时间,
* 在时间期限之内如果还拿不到锁,就返回false。如果如果一开始拿到锁或者在等待期间内拿到了锁,则返回true。
*
* @param time 等待时间
* @param unit 时间单位 小时、分、秒、毫秒等
*/
boolean tryLock(long time, TimeUnit unit) throws InterruptedException;
/**
* 比上面多一个参数,多添加一个锁的有效时间
*
* @param waitTime 等待时间
* @param leaseTime 锁有效时间
* @param unit 时间单位 小时、分、秒、毫秒等
* waitTime 大于 leaseTime
*/
boolean tryLock(long waitTime, long leaseTime, TimeUnit unit) throws InterruptedException;
/**
* 解锁
*/
void unlock();
}
!!!刷完了。加油!2023/04/28 15:25:00