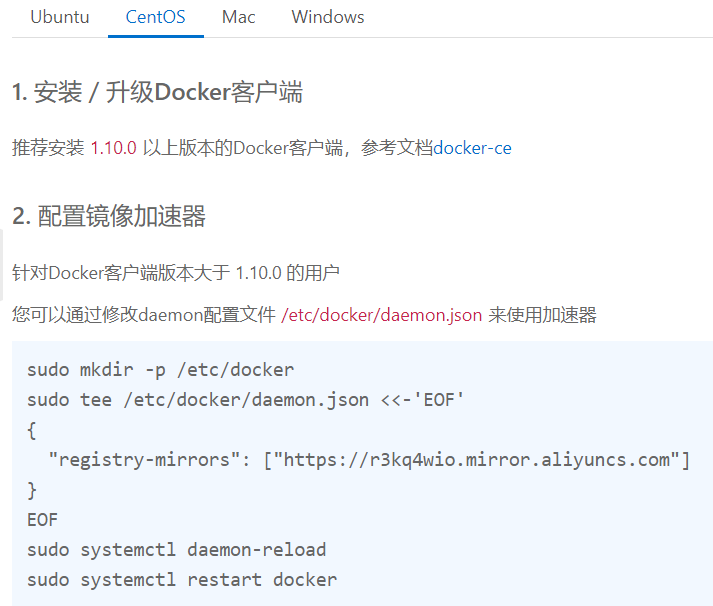
模型构建的目的
首先明确,模型拟合的目的:
不是对训练数据进行准确预测,而是对新数据进行准确预测
欠拟合 与 过拟合

欠拟合:可以通过训练数据及时发现,且可通过优化模型结果解决
过拟合:难以发觉;
过拟合的原因与解决
过拟合原因
本质原因: 对训练数据的拟合过于准确,忽略了训练数据也可能存在的误差
模型上的原因:
1. 模型过于复杂(维度过高)
2. 把过多的属性参考在内,产生了干扰
过拟合解决思路
解决
1. 简化模型结构(使用低阶模型)
2. 数据预处理(降维处理,PCA主成分分析)
3. 模型训练时,增加正则化项
法一:要素降维——PCA主成分分析
详见:【python】sikit-learn包:机器学习
法二:增加正则项
普通拟合时,损失函数如下:

其中 g(Θ,xi) 可以理解为 :

添加正则项后的损失函数如下:

可以通过抬高 λ 的值,控制 Θ 的值在较小范围内,从而降低高阶自变量对因变量的影响
模型评估方法——数据分离 & 混淆矩阵
什么是数据分离?
由模型构建目的 => 我们要想评估模型,我们在具有“训练数据”的同时,还需要“新数据”,并且知道“新数据”的正确结果
=> 所以我们需要将我们已有数据进行分离,
分成:训练集、测试集
训练集用于模型训练,测试集用于预测
训练集和测试集的比例可以不断调整
数据分离的代码实现
from sklearn.model_selection import train_test_split
Xtrain,Xtest,y_train,y_test=train_test_split(X,y,random_state=4,test_size=0.4)
# x与y为一一对应关系,随机状态为4,测试数据的占全部数据的比例为0.4
准确率评估的局限性:
传统模型评估方法:直接计算准确率 accuracy
局限性例子:
对0-1数据进行预测,被预测数据中有900个1和100个0
模型1:猜对850个1和50个0,其余猜错,准确率90%
模型2:全部猜测为1,准确率为90%
显然,模型2不靠谱,但它具备和模型1一样的准确率
准确率具有局限性的原因:
reason1: 没有体现数据预测的实际分布情况(0和1的分布比例等)
reason2: 没有体现模型错误预判的类型(因为什么错了)
混淆矩阵
定义
混淆矩阵又叫误差矩阵,用来衡量分类算法的准确程度


混淆矩阵的评估要素
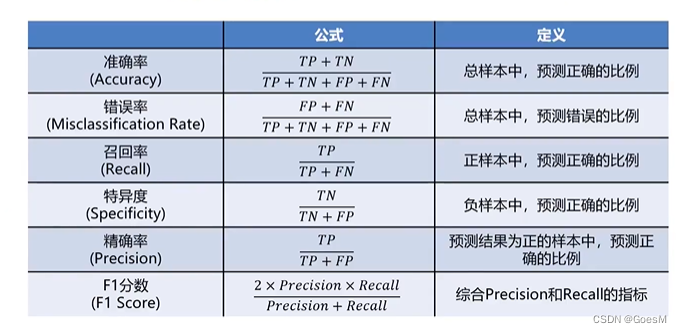
混淆矩阵可以提供更加全面的评估信息
可以将混淆矩阵所包含的各种率都进行观察,即可得知该模型的具体情况;哪个指标更重要,取决于模型使用的环境
F1分数 越高,模拟
混淆矩阵的代码实现
from sklearn.metrics import confusion matrix
cm = confusion_matrix(y,pred_y)
TP = cm[1,1] #正样本猜对
TN = cm[0,0] #正样本猜错
FP = cm[0,1] #负样本猜对
FN = cm[1,0] #负样本猜错
recall = TP/(TP+FN) #召回率,正样本的猜对率
specificity = TN/(TN+FP) #特异度,负样本的猜对率
precision = TP/(TP+FP) # 精确率 预测为正样本的正确率
f1 = 2*precision*recall / (precision +recall) #F1分数,综合精确度和召回率的指标
模型优化方法
数据质量决定模型表现的上限
思路:
- 数据属性的意义,是否为无关数据
- 不同属性数据的数量级差异
- 是否有异常数据
- 采集数据的方法是否合理,采集到的数据是否有代表性
- 数据标签映射编码 的结果具有一致性
方法:
- 删除无关属性的数据
- 数据预处理:整合、规范、标准、归一
- 异常数据 是否保留或过滤
- 尝试多种模型,对比模型表现
模型优化 的 思路框架
Step 1. 观察原始数据(数据内容、数据范围等)
Step 2. 数据格式整理(标签编码、数据类型转换等)
Step 3. 筛出异常数据【异常检测算法】(决定是否保留)
Step 4. 删除低相关属性【PCA主成分分析算法】(提高模型效率)
Step 5. 尝试不同的模型
Step 6. 对不同模型的表现进行评价【混淆矩阵评估法】
Step 6. 模型优化【调整模型参数、正则化处理】
进一步优化方法
- 遍历模型的核心参数的组合,评估模型表现
- 扩大数据样本量
- 增减属性数据
- 模型正则化处理,调整正则项λ的值