【刷题之路Ⅱ】LeetCode 138. 复制带随机指针的链表
- 一、题目描述
- 二、解题
- 难点分析
- 方法——插入拷贝节点
- 2、将拷贝节点插入到原节点的后面
- 3、复制原节点的random到拷贝节点中
- 4、将拷贝节点尾插到新链表中并恢复原链表的结构
一、题目描述
原题连接: 138. 复制带随机指针的链表
题目描述:
给你一个长度为 n 的链表,每个节点包含一个额外增加的随机指针 random ,该指针可以指向链表中的任何节点或空节点。
构造这个链表的 深拷贝。 深拷贝应该正好由 n 个 全新 节点组成,其中每个新节点的值都设为其对应的原节点的值。新节点的 next 指针和 random 指针也都应指向复制链表中的新节点,并使原链表和复制链表中的这些指针能够表示相同的链表状态。复制链表中的指针都不应指向原链表中的节点 。
例如,如果原链表中有 X 和 Y 两个节点,其中 X.random --> Y 。那么在复制链表中对应的两个节点 x 和 y ,同样有 x.random --> y 。
返回复制链表的头节点。
用一个由 n 个节点组成的链表来表示输入/输出中的链表。每个节点用一个 [val, random_index] 表示:
val:一个表示 Node.val 的整数。
random_index:随机指针指向的节点索引(范围从 0 到 n-1);如果不指向任何节点,则为 null 。
你的代码 只 接受原链表的头节点 head 作为传入参数。
示例 1:
输入: head = [[7,null],[13,0],[11,4],[10,2],[1,0]]
输出:[[7,null],[13,0],[11,4],[10,2],[1,0]]

示例 2:
输入: head = [[1,1],[2,1]]
输出:[[1,1],[2,1]]
示例 3:
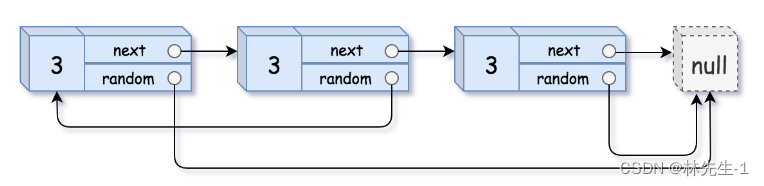
输入: head = [[3,null],[3,0],[3,null]]
输出:[[3,null],[3,0],[3,null]]
提示:
0 <= n <= 1000
-104 <= Node.val <= 104
Node.random 为 null 或指向链表中的节点。
二、解题
难点分析
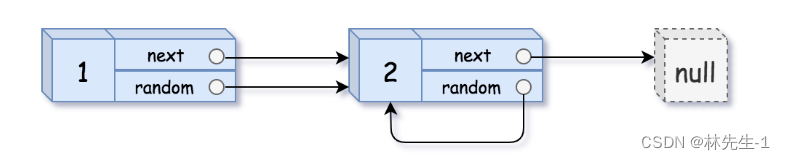
可能有的朋友在读完这一大串的题目后可能就感觉快晕厥过去了,可能还不知道题目的要求是什么。题目的要求其实很简单,就是要你复制一个同样结构链表,即每个节点的next和random的指向都一样,例如:
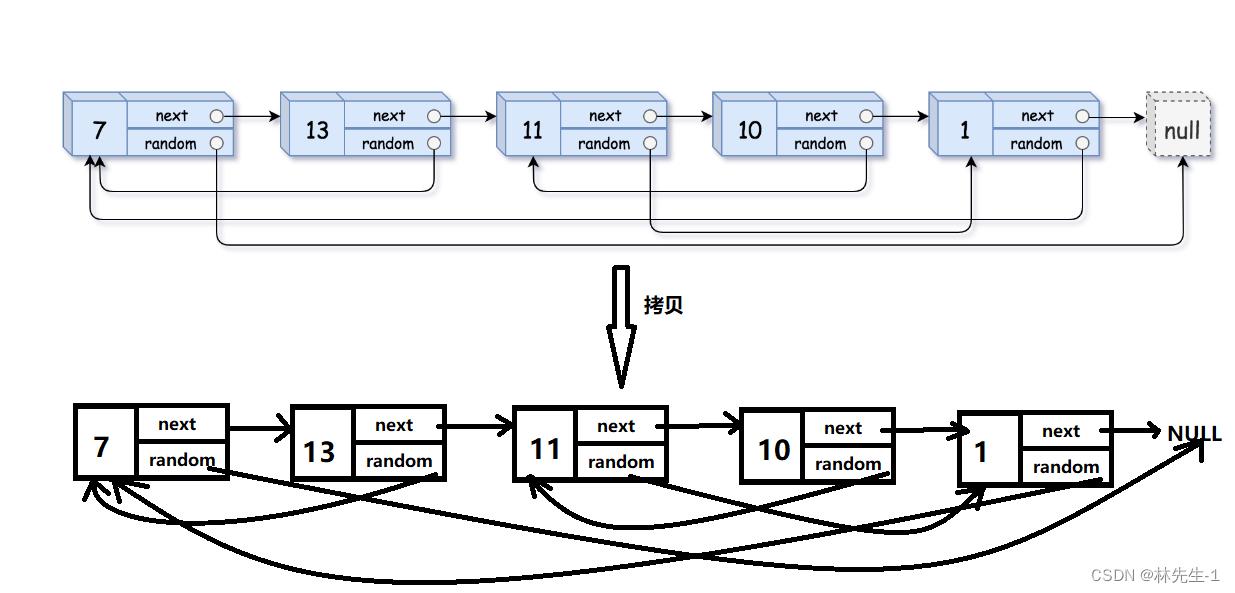
有人可能就会想这还不简单,我遍历所有的原节点,然后每次都开辟一个新节点,再将原节点的next和random赋值到新节点中不就行了吗。
如果你是这样想的,那你就大大的理解错了题目了,如果你真的像上面所说的了,那我们最终完成的效果就如下图所示:
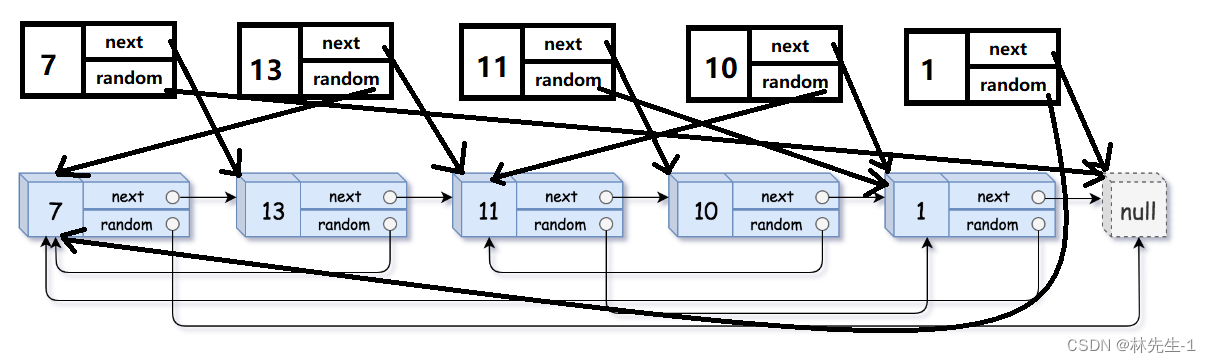
原因当然也很明显,如果我们像上面所说的去做,那我们开辟出来的新节点的next和random所执行的还是原来链表中的节点。而题目要求我们的是开辟出一个新的链表,链表中的节点的next和random连接到的也是新的节点。
而如果该题目的链表没有random这个指针,其实要做起来并没有什么难度,我们只需要遍历原链表的所有节点,对于每一个节点都开辟一个新的节点,将原节点的val复制到新节点,并想办法记录到上一次开辟的节点,将上一次开辟的节点的next指向这次开辟的节点即可,代码并不难,很容易就能写得出:
struct Node *copyList(struct Node *head) {
if (NULL == head) {
return NULL;
}
struct Node *copyhead = NULL;
struct Node *cur = head;
struct Node *pre = NULL; // 记录前一个节点
while (cur) {
struct Node *newNode = (struct Node*)malloc(sizeof(struct Node));
newNode->val = cur->val;
if (NULL == newhead) {
newhead = newNode;
pre = newNode;
} else {
pre->next = newNode;
pre = newNode;
}
}
pre->next = NULL;
return newhead;
}
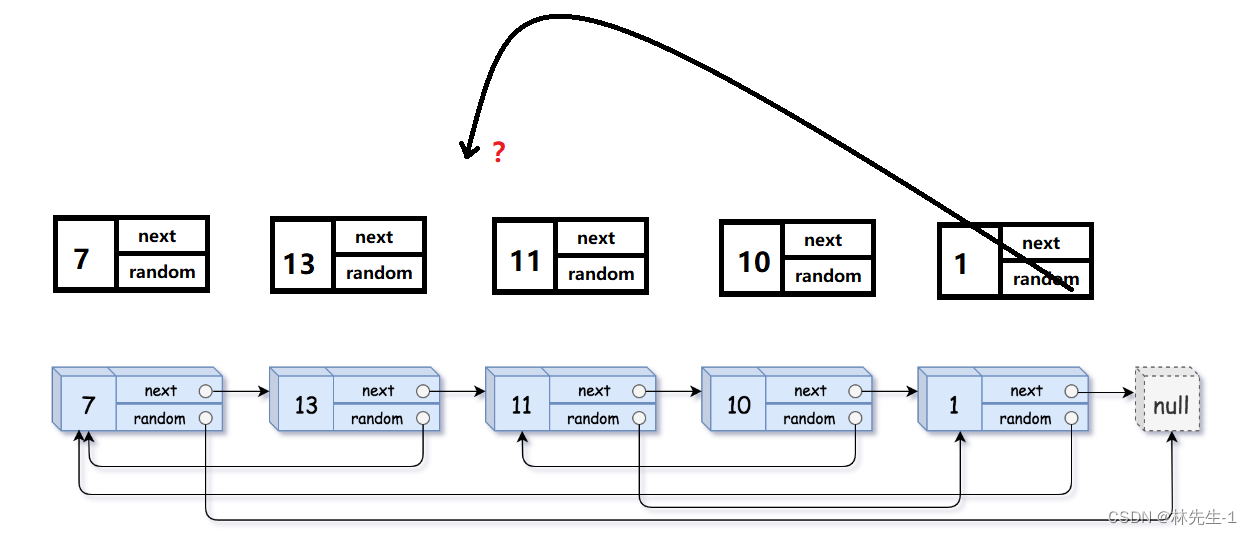
但这题难就难在多了个random节点,因为当我们想要复制random指针时,我们很大可能并没有办法知道random指向的节点的地址。例如我们在复制某个节点的random时,它的random可能指向的是前几个开辟的节点,但我们最多只能记录前一个节点的地址,所以我们就不能直接的知道random指向的节点的地址:
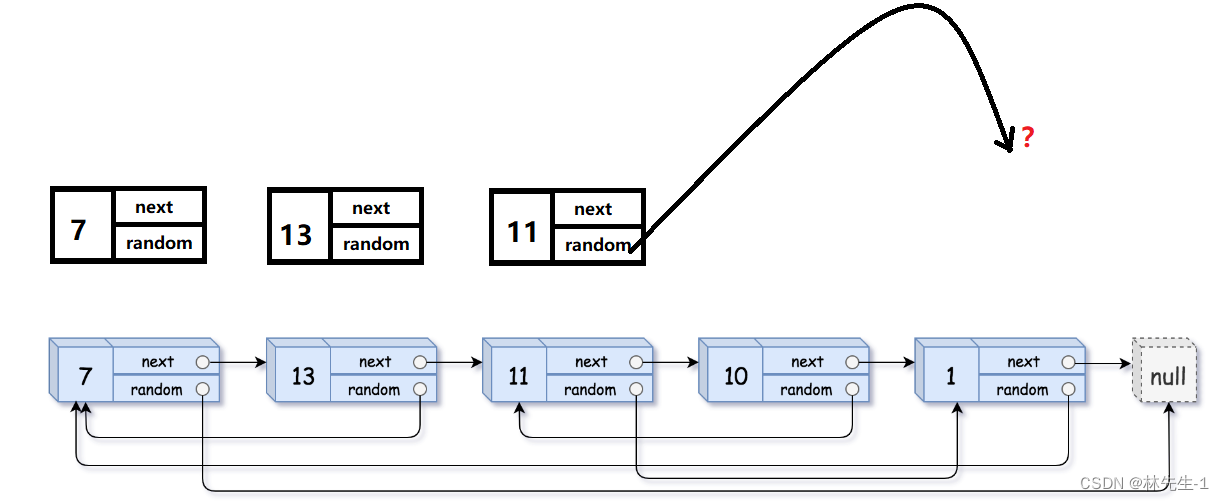
当然也有可能是某个节点的random指向的节点还没开辟出来:
那么这一题到底应该怎么解呢?
接下来就让我们正式开始解题吧。
方法——插入拷贝节点
这一题虽然看起来难,但只要我们把它细分成三个主要步骤,就会发现这三个步骤其实考察的还是一些链表的基本操作,并没有多难的。
2、将拷贝节点插入到原节点的后面
其实我们可以先把复制好的节点插入到原节点的后面:

这样其实就可以做到通过原节点作为一个“桥梁”从而将我们拷贝的链表中的节点的random指针指向相应的节点。
具体该怎么做我们放到下一步在介绍,而我们这一步先完成将拷贝的节点插入到原节点的后面。
这个操作其实并不难完成,这其实是和我们链表的随机插入是一样的,我们可以用一个cur指针遍历原链表的每一个节点,每遍历到一个节点我们就相应的开辟出一个新节点:

开辟好节点后我们就先让新节点的next指向cur的下一个节点,再让cur的next指向新节点即可,完事后再让cur等于newnode的next即可。直到cur等于空,我们就完成了拷贝节点的插入:
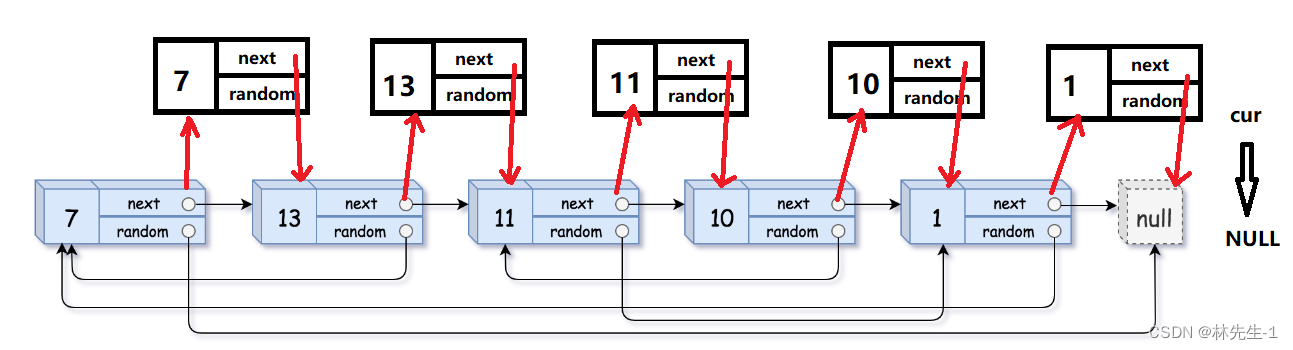
具体的代码如下:
struct Node* copyRandomList(struct Node* head) {
struct Node *cur = head;
// 第一步,先拷贝原节点,并将拷贝的节点连接到源节点后面
while (cur) {
struct Node *CopyNode = (struct Node*)malloc(sizeof(struct Node));
CopyNode->val = cur->val;
// 将拷贝的节点连接到原节点的后面
CopyNode->next = cur->next;
cur->next = CopyNode;
cur = CopyNode->next;
}
}
3、复制原节点的random到拷贝节点中
接下来我们就可以通过我们上一步所搭建的“桥梁”来完成random指针的拷贝了。
通过上一步我们就可以通过原节点找到对应的拷贝节点了(即原节点的next):
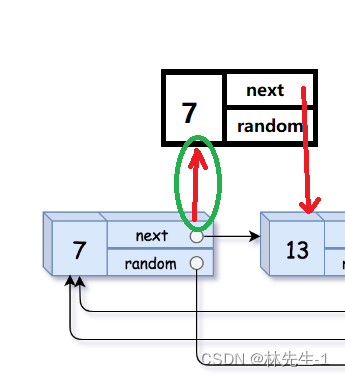
相同的道理,其实我们也可以通过原节点来找到对应的拷贝节点的random所指向的节点,因为我们可以通过原节点来找到原链表中原节点的random指向的节点,那当我们找到了这个节点,这个节点的next不就是对应的拷贝链表中的random指向的节点了吗?例如:
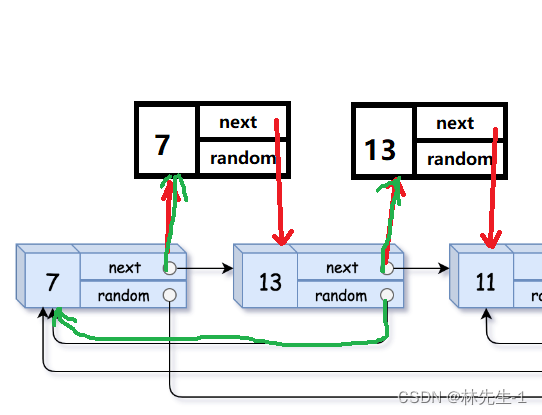
所以,假设我们使用一个cur指针来再次遍历原链表,我们想要拷贝新链表的random的指向就只需要执行cur->next->random = cur->random-next即可:
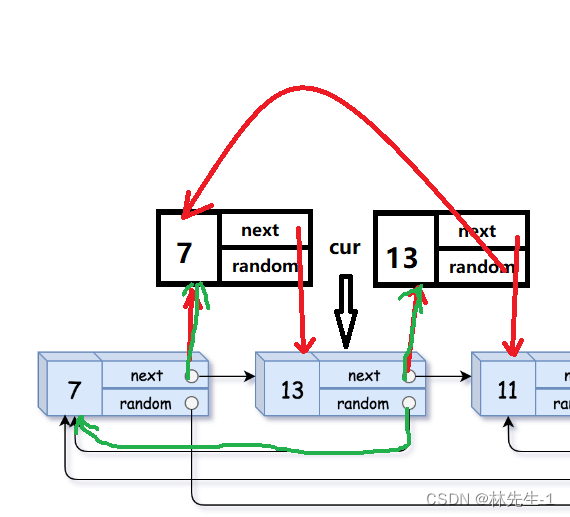
有了这个思路,那我们写起代码来也就没有问题了:
struct Node* copyRandomList(struct Node* head) {
struct Node *cur = head;
// 第一步,先拷贝原节点,并将拷贝的节点连接到源节点后面
while (cur) {
struct Node *CopyNode = (struct Node*)malloc(sizeof(struct Node));
CopyNode->val = cur->val;
// 将拷贝的节点连接到原节点的后面
CopyNode->next = cur->next;
cur->next = CopyNode;
cur = CopyNode->next;
}
// 第二步,拷贝原节点的random到拷贝的节点中
cur = head;
while (cur) {
struct Node *copy = cur->next;
// 拷贝random
if (NULL == cur->random) { // random指向空的情况
copy->random = NULL;
} else {
copy->random = cur->random->next;
}
cur =copy->next;
}
}
4、将拷贝节点尾插到新链表中并恢复原链表的结构
最后一步就是将我们拷贝好的新节点尾插到新的链表当中,然后再恢复原链表的结构。
尾插其实和普通的链表的尾插逻辑是一样的,而恢复原链表的结构其实也和链表的随机删除节点的逻辑是一样的。
完成这个操作我们需要很多个指针,具体如下图:
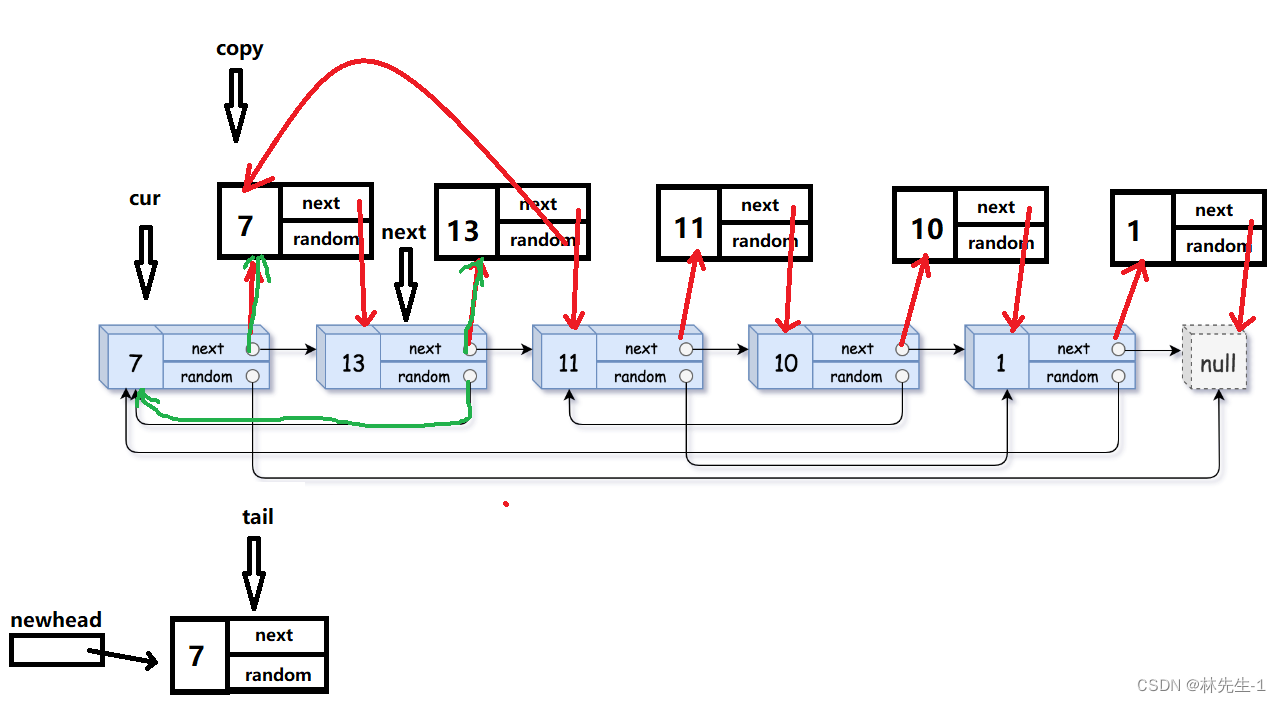
首先我们还是需要一个cur指针来遍历原链表中的节点,然后我们需要一个copy指针保存我们待尾插的节点(即cur的next),而为了在尾插完后我们还能找到原链表的下一个节点,我们需要一个next指针来保存我们原链表的下一个节点(即copy的next)。而为了方便尾插,我们还需要一个tail指针来记录新节点的尾节点,每次插入一个新节点,我们就得让tail往后走一步。
完成这些后,我们直接返回newhead即可。
代码其实并不难,如下:
struct Node* copyRandomList(struct Node* head) {
struct Node *cur = head;
// 第一步,先拷贝原节点,并将拷贝的节点连接到源节点后面
while (cur) {
struct Node *CopyNode = (struct Node*)malloc(sizeof(struct Node));
CopyNode->val = cur->val;
// 将拷贝的节点连接到原节点的后面
CopyNode->next = cur->next;
cur->next = CopyNode;
cur = CopyNode->next;
}
// 第二步,拷贝原节点的random到拷贝的节点中
cur = head;
while (cur) {
struct Node *copy = cur->next;
// 拷贝random
if (NULL == cur->random) {
copy->random = NULL;
} else {
copy->random = cur->random->next;
}
cur =copy->next;
}
// 第三步,将拷贝的节点尾插到新链表,并恢复原链表的结构
cur = head;
struct Node *newhead = NULL;
struct Node *tail = NULL; // 记录新链表的为尾节点
while (cur) {
struct Node *copy = cur->next;
struct Node *next = copy->next;
// 将从copy节点头插到新链表
if (NULL == newhead) {
newhead = copy;
tail = copy;
} else {
tail->next = copy;
tail = tail->next;
}
// 恢复原链表的结构
cur->next = next;
cur = next;
}
return newhead;
}```