目录
前言
数据库
数据库的建立
数据库的使用
数据库的查看
数据库的删除
模式
查看所有的模式
模式和数据库之间的关系
编辑建立模式
删除模式
表
数据类型
查看一个数据库下面的所有表(必须进入要查看的数据库)
创建基本表
查看表结构(查看表建立的字段)
修改表结构(修改已经建立好的表)
视图
视图的作用
视图的保存的方式
建立一个视图
查看所有的视图
查询视图
删除视图
索引
建立索引的目的
索引的建立
索引的删除
前言
在上一节我们介绍了MySQL数据库服务的基本操作,初步的离开的理论,安装、操作属于我们自己的数据库。从新的一节开始,我们会从创建属于我们自己的数据库开始,逐步深入,进而掌握数据库的所有基本操作。
这一节我们将会讲述MySQL数据库模式、表、视图、索引四种结构的说明以及操作方法。
注:博客内标蓝色背景的是教材原话,黄色背景的是博主自己理解的加注,绿色背景的为引用。
数据库
我们要存放数据也好,创建模式、表、视图、索引也罢,都是在创建数据库的基础上进行的,也就是说,最初的最初,我们要先建立一个数据库,再在数据库里面建立模式、表、试图、索引等。
我们在【MySQL自学之路】第2天里面就已经进行过数据库的创建、使用,不过我们当时并没有详细说明。
数据库的建立
SQL语句:
create database sqlstudy;注:创建一个名字为sqlstudy的数据库。如果已经创建,则不会再创建,并抛出已存在错误。
数据库的使用
SQL语句:
use sqlstudy;
注:我们一次只能在一个数据库里面操作,我们想要修改哪个数据库的数据,就要先进入(使用)哪个数据库。
数据库的查看
SQL语句:
show databases;注:查看已经创建的所有数据库。
数据库的删除
SQL语句:
drop database sqlstudy;模式
相比肯定会有自学MySQL的小伙伴吧,大家一般在用的时候是不是创建完数据库就直接建立表结构了?其实在建立数据库之后,还有一个层级叫做模式,只不过其可以作为数据库和表之间的一个过渡,所以好多教程或者文章并没有涉及。
注:以下内容为MySQL中使用方法,可以和其他的数据库管理系统有所出入。
查看所有的模式
SQL语句:
SELECT * FROM information_schema.schemata;
模式和数据库之间的关系
一个数据库可以建立多个模式。
在MySQL当中,建立数据库的时候默认会把其作为一个模式,并基于这个模式进行表操作。同样,建立模式的时候默认把其作为一个数据库。
例如:
(1)先建立一个数据库:temp
create database temp;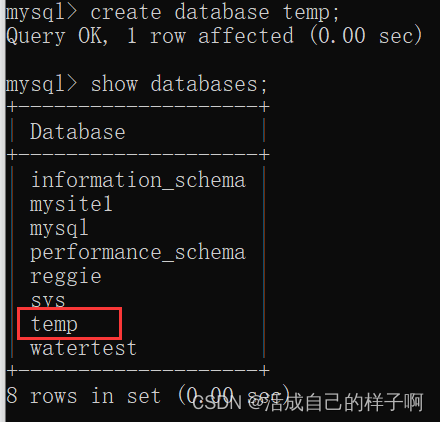
(2)查看所有的模式:
 建立模式
建立模式
SQL语句:
create schema hahaha;其他数据库也可以:
create schema 【模式名】 authorization 【用户名】;
删除模式
SQL语句:
级联删除(删除该模式以及该模式下的所有表、试图等)
drop schema <模式名> cascade;限制删除(如果该模式下有已经创建的表、试图等,则拒绝删除)
drop schema <模式名> restrict;默认:
级联删除
drop schema <模式名>;注:其实在MySQL当中,数据库和模式并没有严格的区分,可以看作是一个东西。但是在其他数据库里面会有显著的区别。
表
假如说我们不关注模式,一个数据库下面可以存放多张表,而表就是存储数据的地方。
数据类型
表里面之间存放数据,我们需要指定字段对应的数据类型。
常用的数据类型(参考材料《数据库系统概论》):
| 数据类型 | 含义 |
| char(n), character(n) | 长度为n的定长字符串 |
| varchar(n), charactervarying(n) | 最大长度为n的变长字符串 |
| clob | 字符串大对象 |
| blob | 二进制大对象 |
| int,integer | 长整数(4字节) |
| smallint | 短整数(2字节) |
| bigint | 大整数(8字节) |
| numeric(p,d), decimal(p,d),dec(p,d) | 定点数。由p位数字组成,小数点后有d位数字 |
| float(n) | 可选精度浮点数,精度至少为n位数字 |
| boolean | 逻辑布尔量 |
| date | 日期,包含年、月、日【yyyy-mm-dd】 |
| time | 时间,包含时、分、秒【hh:mm:ss】 |
| timestamp | 时间戳 |
| real | 取决于机器精度的单精度浮点数 |
| double precision | 取决于机器精度的双精度浮点数 |
查看一个数据库下面的所有表(必须进入要查看的数据库)
SQL语句:
# 使用temp数据库
use temp;
# 查看数据库下面的表
show tables;创建基本表
SQL语句:
create table <table_name>(
<列名> <数据类型> [列级完整性约束],
...
[,表级完整性约束]
);例如:(表名:student_table, 属性:学号(主键,非空)、姓名(非空)、年龄(非空))
create table student_table(
sno char(20) not null primary key,
name char(20) not null,
age int not null
);
常见的完整性约束:
- primary key
- foreign key() reference ...
查看表结构(查看表建立的字段)
SQL语句:
desc <表名>;修改表结构(修改已经建立好的表)
注:修改表结构不是修改数据,是修改列定义、约束等。
SQL语句:(包含增加、修改、删除)
# 添加一列(家庭地址)
alter table student_table
add column home char(30);
# 修改列属性(学号由字符串改为可变字符串)
alter table student_table
modify column sno varchar(20);
# 显示当前表的状态
desc student_table;
# 删除一列(家庭地址)
alter table student_table
drop column home;
# 显示当前表的状态
desc student_table;
视图
视图的作用
视图可以连接一个或多个表的不同字段,并设置新的约束和关系,可以有效的保护数据,方便对关键数据的查看。
视图的保存的方式
视图在内存中其实保存的是sql语句,并没有保存数据,也就是视图里面的数据可以随着建立视图使用表的数据变化而变化。
建立一个视图
SQL语句:
# 假如说我们没有删除上面建立的地址列
create view address
as
select name, home
from student_table;查看所有的视图
SQL语句:
show tables;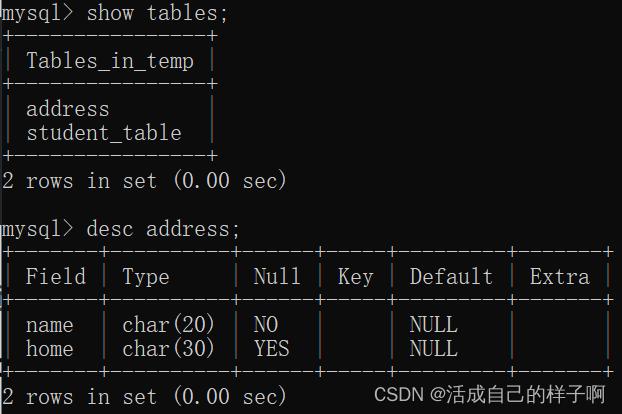
查询视图
从数据字典中取出视图的定义,把定义中的子查询和用户的查询结合起来,转换成等价的对基本表的查询,这一过程称为视图消解。
SQL语句:
select *
from address;删除视图
SQL语句:
drop view address cascade;注:cascade是级联删除,帮助你把该视图和由他导出的所有视图一起删除。
索引
建立索引的目的
当表的数据量比较大的时候,查询操作会比较费时。建立索引是加快查询速度的有效手段。
索引虽然能加快数据库的查询,但需要占据一定的存储空间,当基本表更新的时候,索引要进行维护,这些都会增加数据库的负担,因此要根据实际应用的需要有选择的建立索引。
索引的建立
SQL语句:
create [unique] index <index_name>
on
<表名>(<列名> <次序>, <列名> <次序>);
# unique:索引的每一个索引值只对应唯一的数据记录
# 次序:desc 降序;asc 升序(默认)。索引的删除
SQL语句:
drop index <index_name>;修改索引(只能重命名)
SQL语句:
alter index <old_index_name> rename to <new_index_name>;