🍓系列专栏:Spring系列专栏
🍉个人主页:个人主页
目录
一、案例:数据源对象管理
1.环境准备
2.实现Druid管理
3.实现C3P0管理
二、加载properties文件
1.第三方bean属性优化
2.读取单个属性
3.注意事项
三、核心容器
1.环境准备
2.容器
1.容器的创建方式
2.Bean的三种获取方式
3.容器类层次结构
4.BeanFactory的使用
3.核心容器总结
1.容器相关
2.bean相关
3.依赖注入相关
四、图书推荐
一、案例:数据源对象管理
在这一节中,我们将通过一个案例来学习下对于第三方bean该如何进行配置管理。 以后我们会用到很多第三方的bean,本次案例将使用咱们前面提到过的数据源Druid(德鲁伊)和C3P0来配置学习下。
1.环境准备
- 创建一个Maven项目

- pom.xml添加依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.itheima</groupId>
<artifactId>spring_09_datasource</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>5.2.10.RELEASE</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.16</version>
</dependency>
<dependency>
<groupId>c3p0</groupId>
<artifactId>c3p0</artifactId>
<version>0.9.1.2</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency>
</dependencies>
</project>- resources下添加spring的配置文件applicationContext.xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd">
</beans>- 编写一个运行类App
public class App {
public static void main(String[] args) {
ApplicationContext ctx = new
ClassPathXmlApplicationContext("applicationContext.xml");
}
}2.实现Druid管理
思路分析
需求 : 使用 Spring 的 IOC 容器来管理 Druid 连接池对象1. 使用第三方的技术,需要在 pom.xml 添加依赖【前面已导入】2. 在配置文件中将【第三方的类】制作成一个 bean ,让 IOC 容器进行管理3. 数据库连接需要基础的四要素 驱动 、 连接 、 用户名 和 密码 ,【如何注入】到对应的 bean 中4. 从 IOC 容器中获取对应的 bean 对象,将其打印到控制台查看结果
步骤1:配置第三方bean
在applicationContext.xml配置文件中添加DruidDataSource的配置
<!-- 管理DruidDataSource对象-->
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource">
<property name="driverClassName" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/spring_db"/>
<property name="username" value="root"/>
<property name="password" value="root"/>
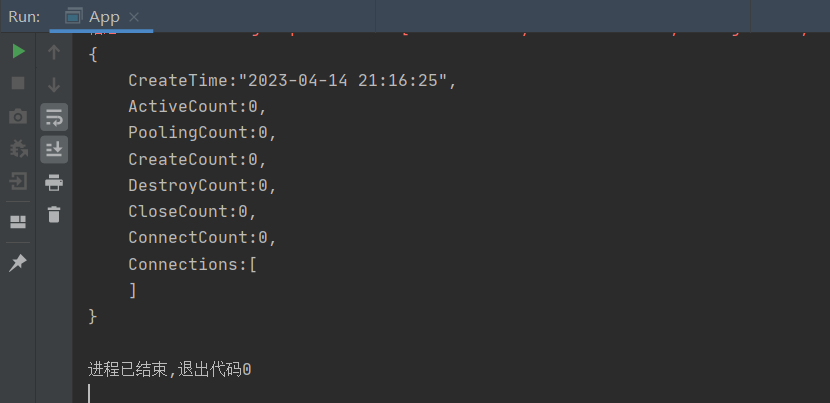
</bean>public class App {
public static void main(String[] args) {
ApplicationContext ctx = new ClassPathXmlApplicationContext("applicationContext.xml");
DataSource dataSource = (DataSource) ctx.getBean("dataSource");
System.out.println(dataSource);
}
}
- 第三方的类指的是什么?
DruidDataSource- 如何注入数据库连接四要素?
setter注入3.实现C3P0管理
<bean class="com.mchange.v2.c3p0.ComboPooledDataSource">
<property name="driverClass" value="com.mysql.jdbc.Driver"/>
<property name="jdbcUrl" value="jdbc:mysql://localhost:3306/spring_db"/>
<property name="user" value="root"/>
<property name="password" value="root"/>
<property name="maxPoolSize" value="1000"/>
</bean>- ComboPooledDataSource的属性是通过setter方式进行注入
- 想注入属性就需要在ComboPooledDataSource类或其上层类中有提供属性对应的setter方法
- C3P0的四个属性和Druid的四个属性是不一样的
运行程序

二、加载properties文件
- 这两个数据源中都使用到了一些固定的常量如数据库连接四要素,把这些值写在Spring的配置文件中不利于后期维护
- 需要将这些值提取到一个外部的properties配置文件中
- Spring框架如何从配置文件中读取属性值来配置就是接下来要解决的问题。
1.第三方bean属性优化
实现思路
需求 : 将数据库连接四要素提取到 properties 配置文件, spring 来加载配置信息并使用这些信息来完成属性注入。1. 在 resources 下创建一个 jdbc.properties( 文件的名称可以任意 )5 2. 将数据库连接四要素配置到配置文件中3. 在 Spring 的配置文件中加载 properties 文件4. 使用加载到的值实现属性注入其中第 3 , 4 步骤是需要大家重点关注,具体是如何实现。
实现步骤
jdbc.driver=com.mysql.jdbc.Driver
jdbc.url=jdbc:mysql://127.0.0.1:3306/spring_db
jdbc.username=root
jdbc.password=root<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd
</beans><context:property-placeholder location="jdbc.properties"/> <context:property-placeholder location="jdbc.properties"/>
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource">
<property name="driverClassName" value="${jdbc.driver}"/>
<property name="url" value="${jdbc.url}"/>
<property name="username" value="${jdbc.username}"/>
<property name="password" value="${jdbc.password}"/>
</bean>
2.读取单个属性
实现思路
对于上面的案例,效果不是很明显,我们可以换个案例来演示下:
需求 : 从 properties 配置文件中读取 key 为 name 的值,并将其注入到 BookDao 中并在 save 方法中进行打印。1. 在项目中添加 BookDao 和 BookDaoImpl 类2. 为 BookDaoImpl 添加一个 name 属性并提供 setter 方法3. 在 jdbc.properties 中添加数据注入到 bookDao 中打印方便查询结果4. 在 applicationContext.xml 添加配置完成配置文件加载、属性注入 (${key})
实现步骤
public interface BookDao {
public void save();
}
public class BookDaoImpl implements BookDao {
private String name;
public void setName(String name) {
this.name = name;
}
public void save() {
System.out.println("book dao save ..." + name);
}
} <context:property-placeholder location="jdbc.properties"/>
<bean id="bookDao" class="com.itheima.dao.impl.BookDaoImpl">
<property name="name" value="${jdbc.driver}"/>
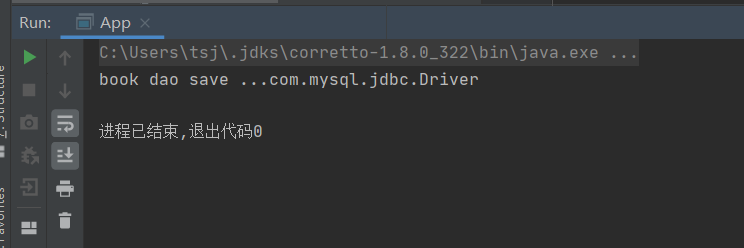
</bean>public class App {
public static void main(String[] args) {
ApplicationContext ctx = new ClassPathXmlApplicationContext("applicationContext.xml");
BookDao bookDao = (BookDao) ctx.getBean("bookDao");
bookDao.save();
}
}
3.注意事项
问题一:键值对的key为username引发的问题
1.在properties中配置键值对的时候,如果key设置为username
username=root666 <context:property-placeholder location="jdbc.properties"/>
<bean id="bookDao" class="com.itheima.dao.impl.BookDaoImpl">
<property name="name" value="${username}"/>
</bean>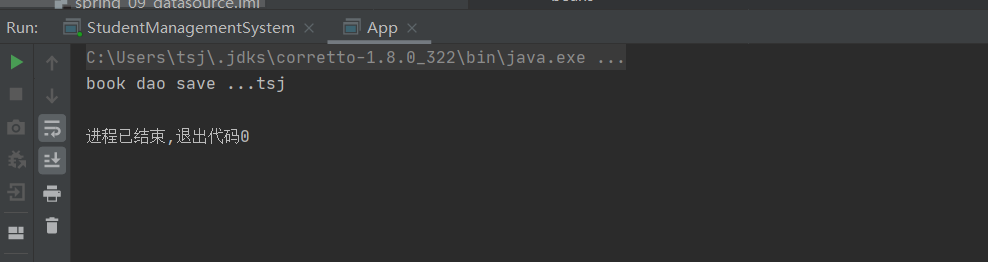
public class AppSystemProperties {
public static void main(String[] args) {
Map<String, String> env = System.getenv();
System.out.println(env);
}
}
<context:property-placeholder location="jdbc.properties" system-properties-mode="NEVER"/>jdbc.driver=com.mysql.jdbc.Driver
jdbc.url=jdbc:mysql://127.0.0.1:3306/spring_db
jdbc.username=root
jdbc.password=rootusername=root666 <!--方式一 -->
<context:property-placeholder
location="jdbc.properties,jdbc2.properties" system-properties-mode="NEVER"/>
<!--方式二-->
<context:property-placeholder location="*.properties" system-properties-mode="NEVER"/>
<!--方式三 -->
<context:property-placeholder location="classpath:*.properties"
system-properties-mode="NEVER"/>
<!--方式四-->
<context:property-placeholder location="classpath*:*.properties"
system-properties-mode="NEVER"/>- 方式一:可以实现,如果配置文件多的话,每个都需要配置
- 方式二: *.properties代表所有以properties结尾的文件都会被加载,可以解决方式一的问题,但是不标准
- 方式三:标准的写法,classpath:代表的是从根路径下开始查找,但是只能查询当前项目的根路径
- 方式四:不仅可以加载当前项目还可以加载当前项目所依赖的所有项目的根路径下的properties配置文件
三、核心容器
前面已经完成bean与依赖注入的相关知识学习,接下来我们主要学习的是IOC容器中的核心容器。
这里所说的核心容器,大家可以把它简单的理解为ApplicationContext,前面虽然已经用到过,但
是并没有系统的学习,接下来咱们从以下几个问题入手来学习下容器的相关知识:
- 如何创建容器?
- 创建好容器后,如何从容器中获取bean对象?
- 容器类的层次结构是什么?
- BeanFactory是什么?
1.环境准备
在学习和解决上述问题之前,先来准备下案例环境:
- 创建一个Maven项目
- pom.xml添加Spring的依赖
<dependencies>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>5.2.10.RELEASE</version>
</dependency>
</dependencies>- resources下添加applicationContext.xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="bookDao" class="com.itheima.dao.impl.BookDaoImpl"/>
</beans>-
添加BookDao和BookDaoImpl类
public interface BookDao {
public void save();
}
public class BookDaoImpl implements BookDao {
public void save() {
System.out.println("book dao save ..." );
}
}-
创建运行类App
public class App {
public static void main(String[] args) {
ApplicationContext ctx = new
ClassPathXmlApplicationContext("applicationContext.xml");
BookDao bookDao = (BookDao) ctx.getBean("bookDao");
bookDao.save();
}
}最终创建好的项目结构如下:

2.容器
1.容器的创建方式
案例中创建ApplicationContext的方式为:
ApplicationContext ctx = new
ClassPathXmlApplicationContext("applicationContext.xml");这种方式翻译为:类路径下的XML配置文件
除了上面这种方式,Spring还提供了另外一种创建方式为:
ApplicationContext ctx = new
FileSystemXmlApplicationContext("applicationContext.xml");这种方式翻译为:文件系统下的XML配置文件
使用这种方式,运行,会出现如下错误:
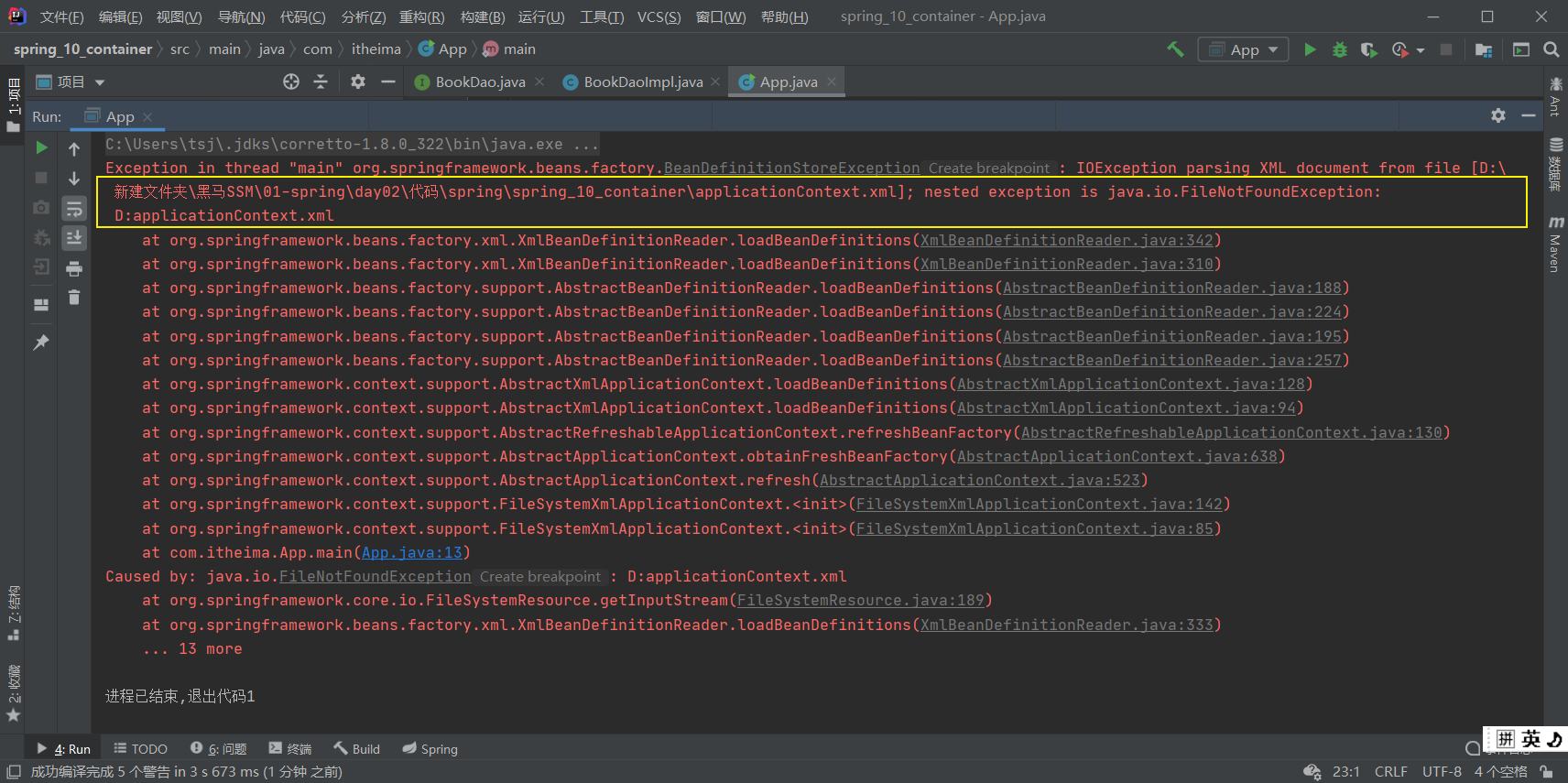
从错误信息中能发现,这种方式是从项目路径下开始查找applicationContext.xml配置文件的,所 以需要将其修改为:对应的绝对路径
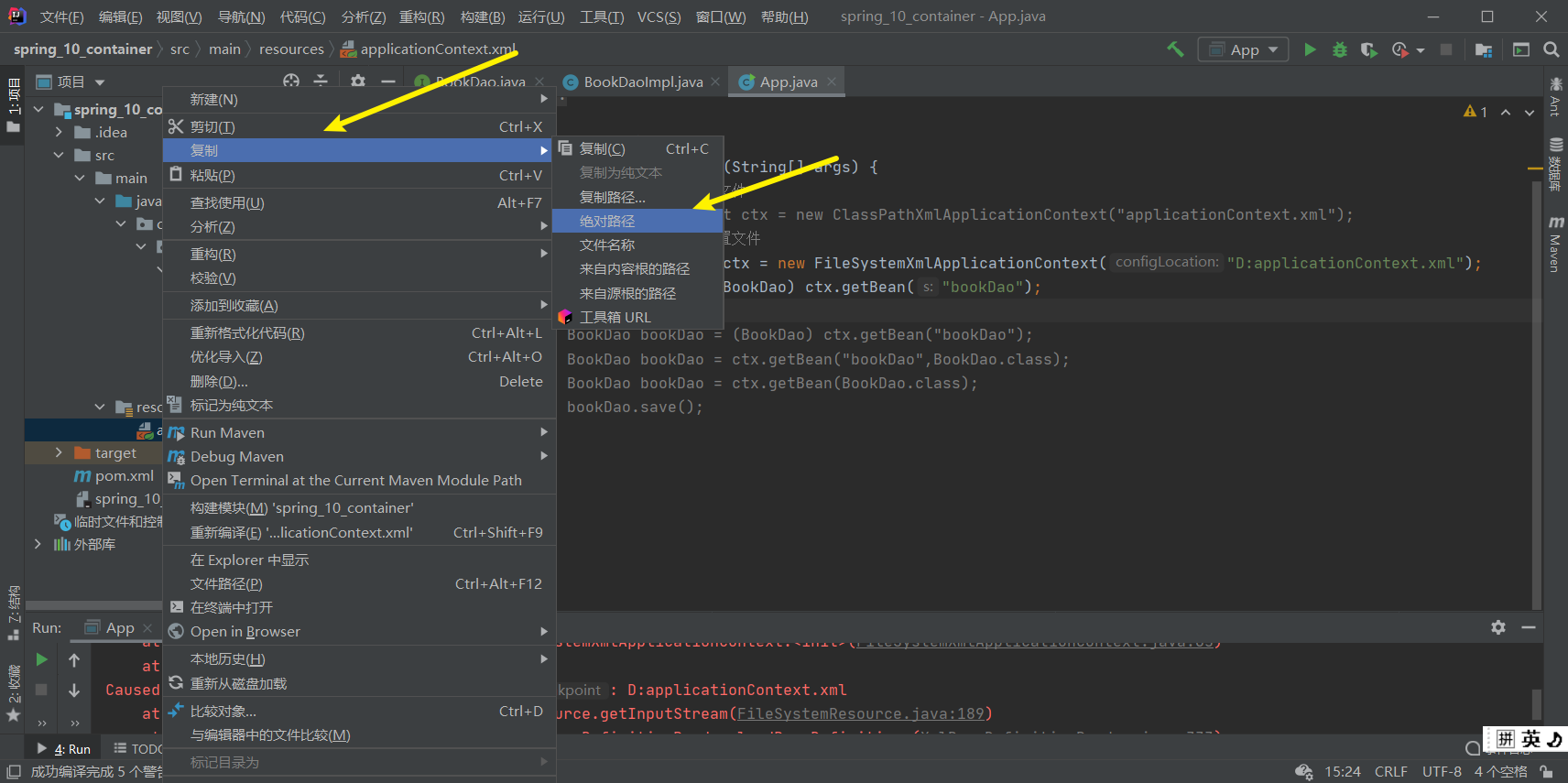
说明:大家练习的时候,写自己的具体路径。 这种方式虽能实现,但是当项目的位置发生变化后,代码也需要跟着改,耦合度较高,不推荐使用。
2.Bean的三种获取方式
方式一,就是目前案例中获取的方式:
BookDao bookDao = (BookDao) ctx.getBean("bookDao");这种方式存在的问题是每次获取的时候都需要进行类型转换,有没有更简单的方式呢?
方式二:
BookDao bookDao = ctx.getBean("bookDao",BookDao.class);这种方式可以解决类型强转问题,但是参数又多加了一个,相对来说没有简化多少。
方式三:
BookDao bookDao = ctx.getBean(BookDao.class);这种方式就类似我们之前所学习依赖注入中的按类型注入。必须要确保IOC容器中该类型对应的bean对象只能有一个。
3.容器类层次结构
(1)在IDEA中双击shift ,输入BeanFactory
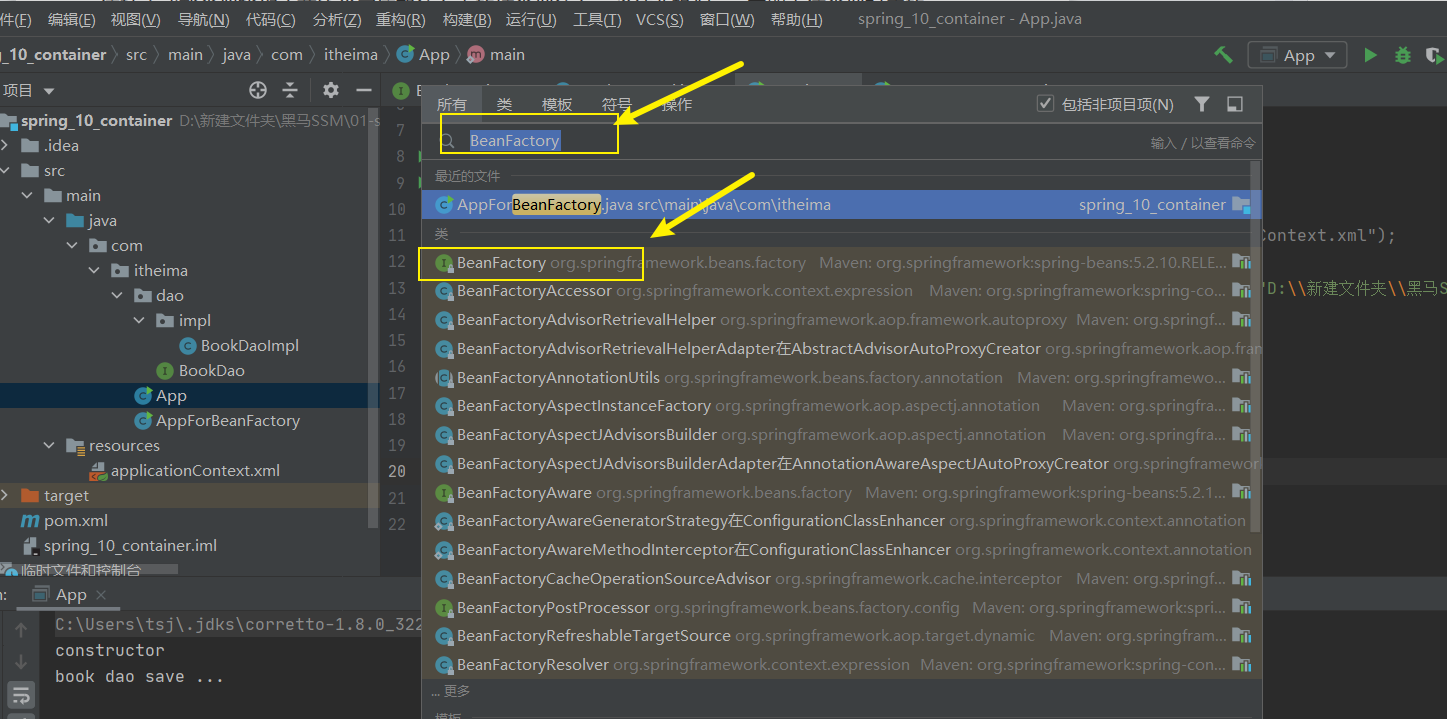
(2)点击进入BeanFactory类,ctrl+h,就能查看到如下结构的层次关系

从图中可以看出,容器类也是从无到有根据需要一层层叠加上来的,大家重点理解下这种设计思想。
4.BeanFactory的使用
使用BeanFactory来创建IOC容器的具体实现方式为:
public class AppForBeanFactory {
public static void main(String[] args) {
Resource resources = new ClassPathResource("applicationContext.xml");
BeanFactory bf = new XmlBeanFactory(resources);
BookDao bookDao = bf.getBean(BookDao.class);
bookDao.save();
}
}public class BookDaoImpl implements BookDao {
public BookDaoImpl() {
System.out.println("constructor");
}
public void save() {
System.out.println("book dao save ..." );
}
}- BeanFactory是延迟加载,只有在获取bean对象的时候才会去创建
- ApplicationContext是立即加载,容器加载的时候就会创建bean对象
- ApplicationContext要想成为延迟加载,只需要按照如下方式进行配置
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="bookDao" class="com.itheima.dao.impl.BookDaoImpl" lazyinit="true"/>
</beans>3.核心容器总结
1.容器相关
- ClassPathXmlApplicationContext[掌握]
- FileSystemXmlApplicationContext[知道即可]
- getBean("名称"):需要类型转换
- getBean("名称",类型.class):多了一个参数
- getBean(类型.class):容器中不能有多个该类的bean对象
- 只需要知晓容器的最上级的父接口为 BeanFactory即可
- 使用BeanFactory创建的容器是延迟加载
- 使用ApplicationContext创建的容器是立即加载
- 具体BeanFactory如何创建只需要了解即可。
2.bean相关

其实整个配置中最常用的就两个属性id和class。
3.依赖注入相关
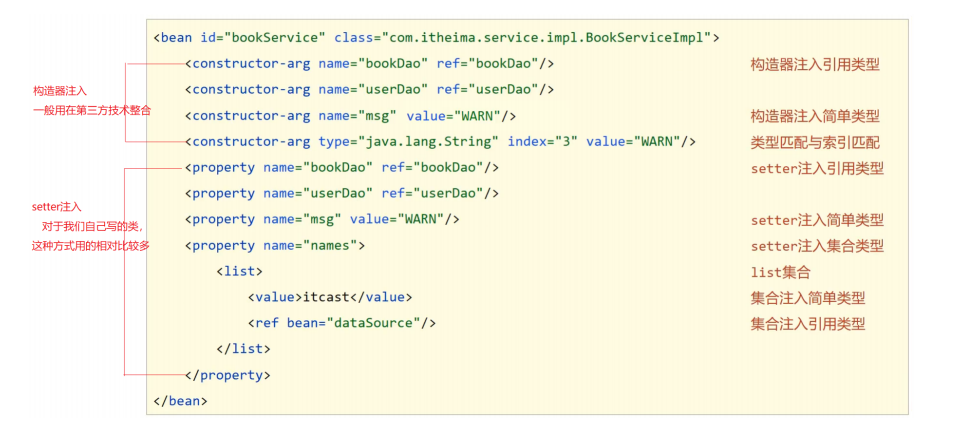
笔记来自:黑马程序员SSM框架教程
四、图书推荐
《Windows PowerShell自动化运维大全》由微软最有价值专家、微软TechEd优秀讲师徐鹏著作,多年经验毫无保留分享,一本书完全讲透Windows PowerShell自动化运维所有核心知识点,赠送同步视频学习教程,助你从运维初级工程师转向高级运维工程师!一本书精通Windows PowerShell自动化运维!
本书从基础的 PowerShell 命令开始,先后讲述了基础命令、模块、脚本的编写等相关知识。同时为了让大家更快地理解和掌握 PowerShell 的环境配置和编写,我们使用系统内置的 PowerShell ISE 开发环境进行 PowerShell 代码的开发和运行。为了照顾很多基础薄弱的读者,在进行代码案例演示时都使用了 15 行以内的代码。
本书可作为学校培训与企业培训的基本学习教程和工具书,相信通过本书的学习,读者可以更快地理解 PowerShell在日常生活及企业内的应用,为读者在自动化运维的道路上助力。
徐鹏,微软最有价值专家、微软TechEd优秀讲师、《PowerQuery从入门到精通》作者。先后就职于宏基企业服务部、微软中国有限公司,为多家全球500强企业提供微软全系列产品培训、顾问咨询及架构优化服务。

🍓本次送 4 本书 ,评论区抽3位小伙伴送书🍓
活动时间:截止到 2023-05-02 14:00:00
抽奖方式:利用程序进行抽奖。
参与方式:关注博主、点赞、收藏,评论区评论 "五一假期,码不停息!"
迫不及待的小伙伴也可以访问下面的链接了解详情:
京东自营链接:Windows PowerShell自动化运维大全
🍓 获奖名单🍓
名单公布时间: 2023-05-02 14:00:00






![[Pandas] 设置DataFrame的index索引起始值为1](https://img-blog.csdnimg.cn/13b38f0022924625865792731c8872d8.png)


