当下主流语音前端算法在特征工程方面,从vad,降噪、降混响到盲源分离,无论是传统做法还是NN做法,大多基于频域。但近年在语音分离领域也看到了利用时域的做法,也取得了不错的效果。
本文从特征工程的角度,对语音时域进行分析,试图解释时域信息的特点。本文从以下几个方面进行介绍。
-
特征工程应该具备什么?
-
时域分析
-
总结
1,特征工程应该具备什么?
好的特征工程应该具有以下特性:
区分度:语音部分和噪音部分区分度应该尽量大,理论上,好的特征能使噪声分布和语音分布没有交集;
噪声鲁棒性:背景噪声会使语音失真,好的特征应该具有对噪声的鲁棒性;
以常用的特征fbank来举例,


由上可见,noisy speech和clean speech的fbank的分布在e+4量级,相差不大;而pure noise的fbank分布在e+5量级,明显和noisy speech、clean speech相差较大。所以fbank具有好的区分度和噪声鲁棒能力。
2, 时域分析
so时域做特征的话,应该也要具有区分度和噪声鲁棒性。
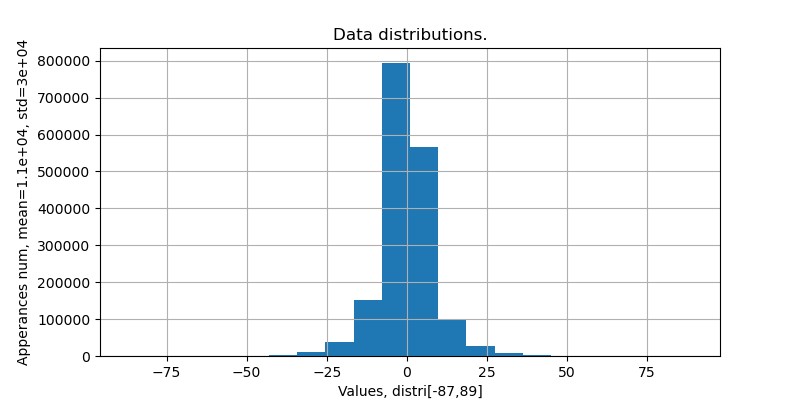
还是看图说话:


由上可见,noisy speech和clean speech的时域信息的分布在e+4量级,相差不大;而pure noise的时域信息分布在e+5量级,明显和noisy speech、clean speech相差较大。所以时域信息也具有好的区分度和噪声鲁棒能力。
3, 总结
综上,可以解释为什么部分基于时域的语音算法可以取得sota的效果,大家赶紧尝试起来吧,本文也可作为大家利用时域信息的理论依据。近期我打算结合nn,基于时域信息,训练个vad看看效果。
如果存在问题,欢迎大家指正。
最后,喜欢的话,点个赞吧。