这篇文章,主要介绍微服务组件之Sleuth + Zipkin实现服务调用链路追踪功能。
目录
一、Sleuth链路追踪
1.1、什么是Sleuth
1.2、Sleuth专业术语
(1)Span
(2)Trace
(3)工作原理
1.3、Sleuth的使用
(1)引入依赖
(2)运行测试
二、Zipkin链路可视化
2.1、什么是Zipkin
2.2、Zipkin服务端
(1)下载Zipkin
(2)启动Zipkin
2.3、Zipkin客户端
(1)引入依赖
(2)添加配置信息
(3)运行测试
2.3、Zipkin持久化数据到MySQL
(1)创建数据库
(2)修改Zipkin服务端启动方式
2.4、Zipkin使用RabbitMQ持久化数据到MySQL
(1)准备RabbitMQ环境
(2)修改Zipkin服务端启动方式
(3)Zipkin客户端添加RabbitMQ配置
(4)运行测试
2.5、Zipkin使用RabbitMQ持久化数据到ES
(1)搭建ES环境
(2)修改Zipkin服务端启动方式
(3)运行测试
一、Sleuth链路追踪
1.1、什么是Sleuth
在微服务环境下,一个服务可能调用多个其他的微服务,调用的微服务有可能会去调用其他的微服务,依次类推,这样就会存在一个微服务的调用链,那么这种情况下,就会存在一个问题,当某个接口调用出现报错的时候,我们应该要怎么去排查问题???
传统的方式就是:从第一个微服务开始,找到接口下一个调用的微服务,一个一个查找,这种方式虽然可以找到调用链路,但是却需要我们开发人员逐个定位,显然有些不合适。
为了能够清晰的知道服务的调用链路情况,于是就出现了各种服务链路追踪组件,这里要介绍的就是Spring Cloud Sleuth,它是一个服务链路追踪组件,Sleuth组件有下面这些功能:
- 链路追踪:可以知道每一个请求的完整调用链路。
- 性能分析:可以清楚的知道每一个微服务调用链路的耗时情况。
- 数据分析、优化链路:通过服务的调用链路以及耗时情况,可以针对耗时多的链路进行优化。
- 可视化错误查看:可以结合Zipkin等可视化组件,查看链路调用日志。
1.2、Sleuth专业术语
(1)Span
Span:这个就是指每一个微服务之间的一次调用过程,假设:A服务调用B服务,这个过程就会新建一个Span,B服务调用C服务,也会新建一个Span,所以说,在一个调用链路中,可以存在多个Span,并且这些Span是采用树形结构组织的。
- Span中记录了服务的一些调用信息,例如:开始调用时间、服务接收时间、服务响应时间、服务结束时间、上级服务ID等等。
- 开始调用时间(cs,Client Send):服务最开始发起请求的时间。
- 服务接收时间(sr,Server Received):服务端接收到请求的时间。
- 服务响应时间(ss,Server Send):服务器处理完请求之后,返回响应数据给客户端的时间。
- 服务结束时间(cr,Client Received):客户端接收到请求响应的时间。
- 上级服务ID(parentId):表示当前这个请求是来自哪个微服务调用结点。
(2)Trace
Trace:这个表示一次完整的HTTP请求链路,因为客户端可能发起很多次HTTP请求,所以为了标记每一次请求,就采用Trace来表示,一个HTTP请求就只会存在一个Trace,但是一个Trace中可以包含多个Span。
- traceId:全局跟踪ID,用于表示是同一次HTTP请求,它主要是通过HTTP中的header参数传递到下一个微服务结点中。

(3)工作原理
Sleuth的工作原理其实很简单,就是在服务调用开始,判断是否存在traceId、spanId,不存在则会生成一个随机的ID,再调用下一个微服务的时候,会将Trace和Span放在请求头Header里面,传递到下一个微服务里面,下一个微服务接收到请求时候,会从请求头Header中获取Trace和Span,当前微服务会根据传递过来的Trace和Span信息,生成一个新的Span,作为当前微服务的调用链路信息,继续传递到下一个微服务,依此类推,直到请求结束。
1.3、Sleuth的使用
这里基于前一篇文章【【微服务笔记23】使用Spring Cloud微服务组件从0到1搭建一个微服务工程】的环境,引入Sleuth组件实现链路追踪功能。
(1)引入依赖
- 引入要实现链路追踪,所以需要在每一个微服务工程中引入【sleuth】的依赖。
<!-- 引入 sleuth 依赖 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>(2)运行测试
在每一个工程中引入sleuth依赖之后,其实就已经完成Sleuth的集成啦,只需要重新启动工程,访问一个接口测试即可。需要注意的是:我们应该使用Logger打印一些日志,这样才能够在控制台看到Sleuth输出的链路追踪日志信息。

到这里,Sleuth就已经可以实现链路追踪的功能了,但是通过控制台查看不太方便,所以又出现了Sleuth可视化的组件。
二、Zipkin链路可视化
2.1、什么是Zipkin
Zipkin是开源的分布式实时数据追踪系统,它采用可视化的界面显示服务调用情况,Zipkin并且支持持久化的功能,可以将收集到日志信息持久化到MySQL、ES等数据库里面。默认情况下,Zipkin是将收集到的数据存储在内存里面的,服务重启就会丢失。
Zipkin采用的是C/S架构模式,Zipkin服务端用于收集和显示数据,Zipkin客户端就是每一个微服务应用程序,在程序中引入Zipkin的客户端依赖,配置Zipkin服务端地址,这样客户端就会将收集到数据信息发送给Zipkin服务端进行存储和展示。
常见的分布式链路追踪组件除了Zipkin之外,还有下面这些:
- PinPoint。
- HTrace。
- 阿里的鹰眼Tracing。
- 京东的Hydra。
- 新浪的Watchman。
- 美团的CAT。
- SkyWalking(我之前工作的公司就是采用这个)。
2.2、Zipkin服务端
(1)下载Zipkin
Zipkin是采用C/S架构模式,Zipkin服务端官方已经提供了对应的jar,我们只要下载jar部署即可,官方提供的下载地址:【Zipkin服务端】,下载有一些慢。
(2)启动Zipkin
打开CMD命令行窗口,运行【java -jar zipkin-server-exec.jar】命令,启动Zipkin服务端工程。浏览器访问【http://localhost:9411/】,就可以看到Zipkin的运行界面(默认启动端口是9411)。

2.3、Zipkin客户端
Zipkin客户端,其实就是指每一个微服务应用,我们只要在对应的微服务中引入【zpikin】客户端的依赖就可以了。
(1)引入依赖
<!-- 引入 zipkin 客户端依赖 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>(2)添加配置信息
- 在每一个微服务应用的【bootstrap.yml】配置文件中,添加zikpin的配置信息:
spring:
# 链路追踪配置
zipkin:
base-url: http://localhost:9411/ # zipkin 服务端的地址
sender:
type: web # 采用哪种方式上报数据,web表示次啊用HTTP报文方式
sleuth:
sampler:
probability: 1.0 # 收集数据的百分比,默认是 0.1,即:10%(3)运行测试
启动微服务工程,浏览器访问一个接口,然后就可以去Zipkin服务端查看调用链路信息。

点击SHOW可以查看详细的调用详细,可以看到每一个环节的调用耗时,调用链路顺序,经过几个微服务调用。

到此,Zipkin可视化查看调用链路就设置好啦,下面介绍几种持久化数据的方式。
2.3、Zipkin持久化数据到MySQL
Zipkin默认是将收集到的数据存储在内存中,重新启动就会丢失,但是Zipkin也提供了几种持久化的方式,分别是:MySQL、ES等。
(1)创建数据库
首先下载Zipkin持久化到MySQL数据库的表结构脚本,官方下载地址:【Zipkin持久化的MySQL脚本】。下载之后,创建一个【zipkin】数据库,数据库名称最好叫【zipkin】,当然也可以自定义,然后将MySQL脚本导入数据库里面。

(2)修改Zipkin服务端启动方式
数据库创建之后,Zipkin服务端的启动方式就需要修改一下,因为需要告诉Zipkin服务端工程,将数据持久化到哪个数据库,数据库的用户名和密码之类的信息。
java -jar zipkin-server-2.24.0-exec.jar --STORAGE_TYPE=mysql --MYSQL_HOST=localhost --MYSQL_TCP_PORT=3306 --MYSQL_USER=root --MYSQL_PASS=root --MYSQL_DB=zipkin重新启动Zipkin服务端工程,再次访问接口,此时查看数据库中的表数据,就可以发现数据已经保存到MySQL里面了。

到此,Zipkin数据持久化到MySQL数据库就完成啦。
2.4、Zipkin使用RabbitMQ持久化数据到MySQL
直接将Zipkin数据持久化到MySQL是同步的方式,这种方式持久化过程中很慢,那么就会导致性能问题,所以为了提高性能,可以引入RabbitMQ进行异步的方式进行持久化。
Zipkin客户端将数据发送到RabbitMQ队列中,然后Zipkin服务端从RabbitMQ队列中获取数据,并且将数据保存到MySQL数据库里面,这样就可以提高Zipkin客户端的效率。

(1)准备RabbitMQ环境
因为这里需要使用到RabbitMQ消息队列,所以事先要准备好RabbitMQ的运行环境,可以参考【【RabbitMQ笔记01】Windows搭建RabbitMQ消息队列基础运行环境】文章。
(2)修改Zipkin服务端启动方式
启动Zipkin服务端的时候,需要告诉Zipkin采用哪种方式持久化,并且指定RabbitMQ的IP地址等信息。
java -jar zipkin-server-2.24.0-exec.jar --STORAGE_TYPE=mysql --MYSQL_HOST=localhost --MYSQL_TCP_PORT=3306 --MYSQL_USER=root --MYSQL_PASS=root --MYSQL_DB=zipkin --RABBIT_ADDRESSES=localhost --RABBIT_USER=guest --RABBIT_PASSWORD=guest --RABBIT_VIRTUAL_HOST=/ --RABBIT_QUEUE=zipkin启动成功之后,此时RabbitMQ中就会创建一个zipkin队列。

(3)Zipkin客户端添加RabbitMQ配置
客户端应用中需要引入RabbitMQ的依赖。
<!-- 引入 rabbitmq 依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>在每一个Zipkin客户端应用程序中,需要添加RabbitMQ的配置信息:
spring:
# 链路追踪配置
zipkin:
base-url: http://localhost:9411/ # zipkin 服务端的地址
sender:
type: rabbit # 采用哪种方式上报数据,rabbitmq 方式上报数据
rabbitmq:
queue: zipkin # 指定队列
sleuth:
sampler:
probability: 1.0 # 收集数据的百分比,默认是 0.1,即:10%
# 配置 rabbitmq
rabbitmq:
host: 127.0.0.1
port: 5672
username: guest
password: guest
virtual-host: /
listener:
direct:
retry:
enabled: true # 开启重试策略
max-attempts: 5 # 最多重试5次
initial-interval: 5000 # 每次重试间隔5秒
simple:
retry:
enabled: true # 开启重试策略
max-attempts: 5 # 最多重试5次
initial-interval: 5000 # 每次重试间隔5秒(4)运行测试
先不要启动Zipkin服务端工程,先启动客户端工程,然后访问接口,查看RabbitMQ中队列是否存在数据。

然后启动Zipkin服务端工程,此时服务端工程就会从RabbitMQ里面将数据保存到MySQL数据库中。
2.5、Zipkin使用RabbitMQ持久化数据到ES
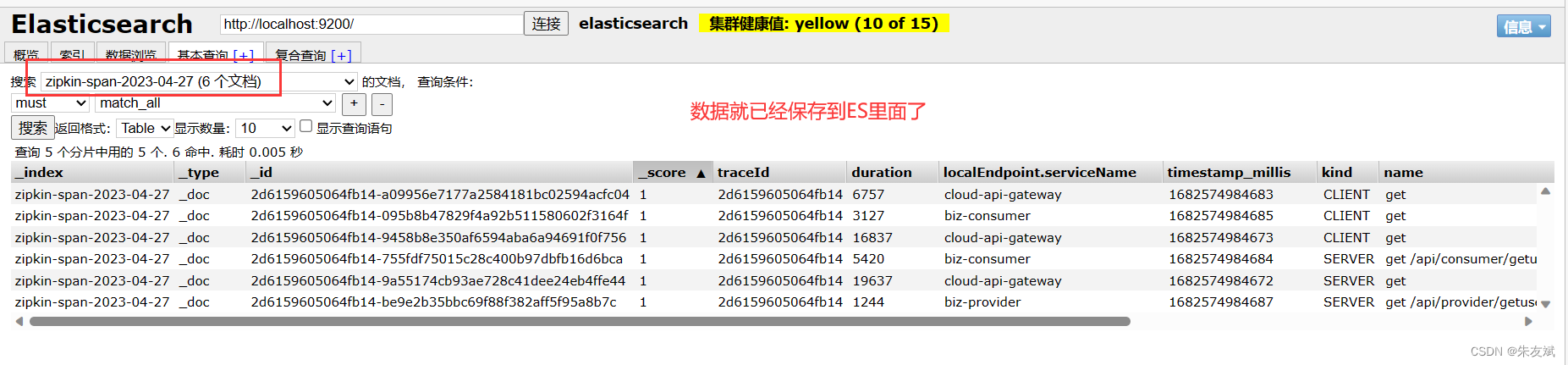
Zipkin调用链路数据虽然可以保存到MySQL里面,但是当数据量非常多的时候,MySQL查询效率就会有一定的影响,所以可以将数据保存到ES数据库里面,ES支持海量数据的高效查询。这里是采用了RabbitMQ将数据保存到ES中,所以也需要RabbitMQ的环境。
(1)搭建ES环境
ES环境可以是单机的,也可以是集群的,看自己情况吧,我这里采用单机的ES作为测试案例,官方下载地址:【ES下载地址】。
(2)修改Zipkin服务端启动方式
修改Zipkin服务端的持久化方式为elasticsearch,指定ES的主机地址人,如果是集群,则多个主机地址使用逗号分隔。
java -jar zipkin-server-2.24.0-exec.jar --STORAGE_TYPE=elasticsearch --ES_HOSTS=localhost --RABBIT_ADDRESSES=localhost --RABBIT_USER=guest --RABBIT_PASSWORD=guest --RABBIT_VIRTUAL_HOST=/ --RABBIT_QUEUE=zipkin(3)运行测试
启动工程,访问接口,查看ES是否已经存在数据信息。
到此,Sleuth和Zipkin链路追踪就介绍完啦。
综上,这篇文章结束了,主要介绍微服务组件之Sleuth + Zipkin实现服务调用链路追踪功能。







![[openwrt] valgrind定位内存泄漏](https://img-blog.csdnimg.cn/44c61c075b4f475591c597dfa6981118.png)