文章目录
- 简介
- Stream 的特性
- 创建Stream
- 通过集合创建流
- 通过数组创建流
- 通过Stream.of方法创建流
- 创建规律的无限流
- 创建无限流
- 创建空流
- Stream操作分类
- 中间操作
- 无状态
- filter
- map
- flapMap
- 有状态
- distinct
- sorted
- reversed
- thenComparing
- limit
- skip
- concat
- 终结操作
- 非短路操作
- forEach
- reduce
- collect
- groupingBy
- partitioningBy
- max、min
- count
- summaryStatistics
- 短路操作
- anyMatch
- findFirst
- findAny
- Optional类型
- 原始类型流
- 并行流
- 并行流的执行顺序
- sorted()、distinct()等对并行流的影响
- 总结
- Stream 详解
- Collect 详解
简介
Stream作为Java8的一大亮点,它与 java.io 包里的 InputStream 和 OutputStream 是完全不同的概念,Stream是对集合的包装,通常和Lambda一起使用,使用stream可以支持许多操作,如 map, filter, limit, sorted, count, min, max, sum, collect 等等。
流(Stream)到底是什么呢?
- 是数据渠道,用于操作数据源(集合,数组等)所生成的元素序列。
- 集合讲的是数据,流讲的是计算。
Stream 的特性
Stream 主要具有如下三点特性
- stream不存储数据
- stream不会改变源数据,相反,它们会返回一个持有结果的新Stream。
- stream的延迟执行特性,这意味着它们会等到需要结果的时候才执行。
通常我们在数组或集合的基础上创建stream,stream不会专门存储数据,对stream的操作也不会影响到创建它的数组和集合,对于stream的聚合、消费或收集操作只能进行一次,再次操作会报错
@Test
public void test1(){
int[] arr = new int[]{1, 2, 3};
IntStream intStream = Arrays.stream(arr);
intStream.forEach(System.out::println);
intStream.forEach(System.out::println);
}
输出结果
1
2
3
java.lang.IllegalStateException: stream has already been operated upon or closed
stream的操作是延迟执行的,在列出字符串长度大于3的例子中,在collect方法执行之前,filter、sorted、map方法还未执行,只有当collect方法执行时才会触发之前转换操作
public boolean filter(String s) {
System.out.println("begin compare");
return s.length() > 3;
}
@Test
public void test2() {
List<String> strs = new ArrayList<String>() {
{
add("abc");
add("abcd");
}
};
Stream<String> stream = strs.stream().filter(this::filter);
System.out.println("split-------------------------------------");
List<String> list = stream.collect(Collectors.toList());
System.out.println(list);
}
打印结果如下:
split-------------------------------------
begin compare
begin compare
[abcd]
由此可以看出,在执行完filter时,没有实际执行filter中的方法,而是等到执行collect时才会执行,即是延迟执行的。
注意:
- 由于Stream的延迟执行特性,在聚合操作执行前修改数据源是允许的。
- 当我们操作一个流时,并不会修改流底层的集合(即使集合是线程安全的),如果想要修改原有的集合,就无法定义流操作的输出。
/**
* 延迟执行特性,在聚合操作之前都可以添加相应元素
*/
@Test
public void test3() {
List<String> wordList = new ArrayList<String>() {
{
add("a");
add("b");
}
};
Stream<String> words = wordList.stream();
wordList.add("END");
long n = words.distinct().count();
System.out.println(n);
}
输出结果
3
延迟执行特性,会产生干扰
@Test
public void test4(){
List<String> wordList = new ArrayList<String>() {
{
add("a");
add("b");
}
};
Stream<String> words1 = wordList.stream();
words1.forEach(s -> {
System.out.println("s->"+s);
if (s.length() < 4) {
System.out.println("select->"+s);
wordList.remove(s);
System.out.println(wordList);
}
});
}
输出结果
s->a
select->a
[b]
s->null
java.lang.NullPointerException
创建Stream
要进行流操作首先要获取流,有6中方法可以获取流。
通过集合创建流
@Test
public void testCollectionStream() {
List<String> strs = Arrays.asList("a", "b", "c", "d");
//创建普通流
Stream<String> stream = strs.stream();
//创建并行流(即多个线程处理)
// Stream<String> stream1 = strs.parallelStream();
stream.forEach(System.out::println);
}
输出结果
a
b
c
d
通过数组创建流
@Test
public void testArrayStream() {
int[] arr = new int[]{1, 2, 3, 4};
IntStream intStream = Arrays.stream(arr);
intStream.forEach(System.out::println);
System.out.println("========");
Integer[] arr2 = new Integer[]{1, 2, 3, 4};
Stream<Integer> stream = Arrays.stream(arr2);
stream.forEach(System.out::println);
}
输出结果
1
2
3
4
========
1
2
3
4
通过Stream.of方法创建流
@Test
public void testStreamOf() {
Stream<Integer> stream = Stream.of(1, 2, 3);
stream.forEach(System.out::println);
}
输出结果
1
2
3
创建规律的无限流
@Test
public void testUnlimitStream() {
Stream<Integer> stream = Stream.iterate(0, x -> x + 2).limit(3);
stream.forEach(System.out::println);
}
输出结果
0
2
4
创建无限流
@Test
public void testUnlimitStream2() {
Stream<String> stream = Stream.generate(() -> "number" + new Random().nextInt()).limit(3);
stream.forEach(System.out::println);
}
输出结果
number1042047526
number-155761434
number-1605164634
创建空流
@Test
public void testEmptyStream() {
Stream<Integer> stream = Stream.empty();
stream.forEach(System.out::println);
}
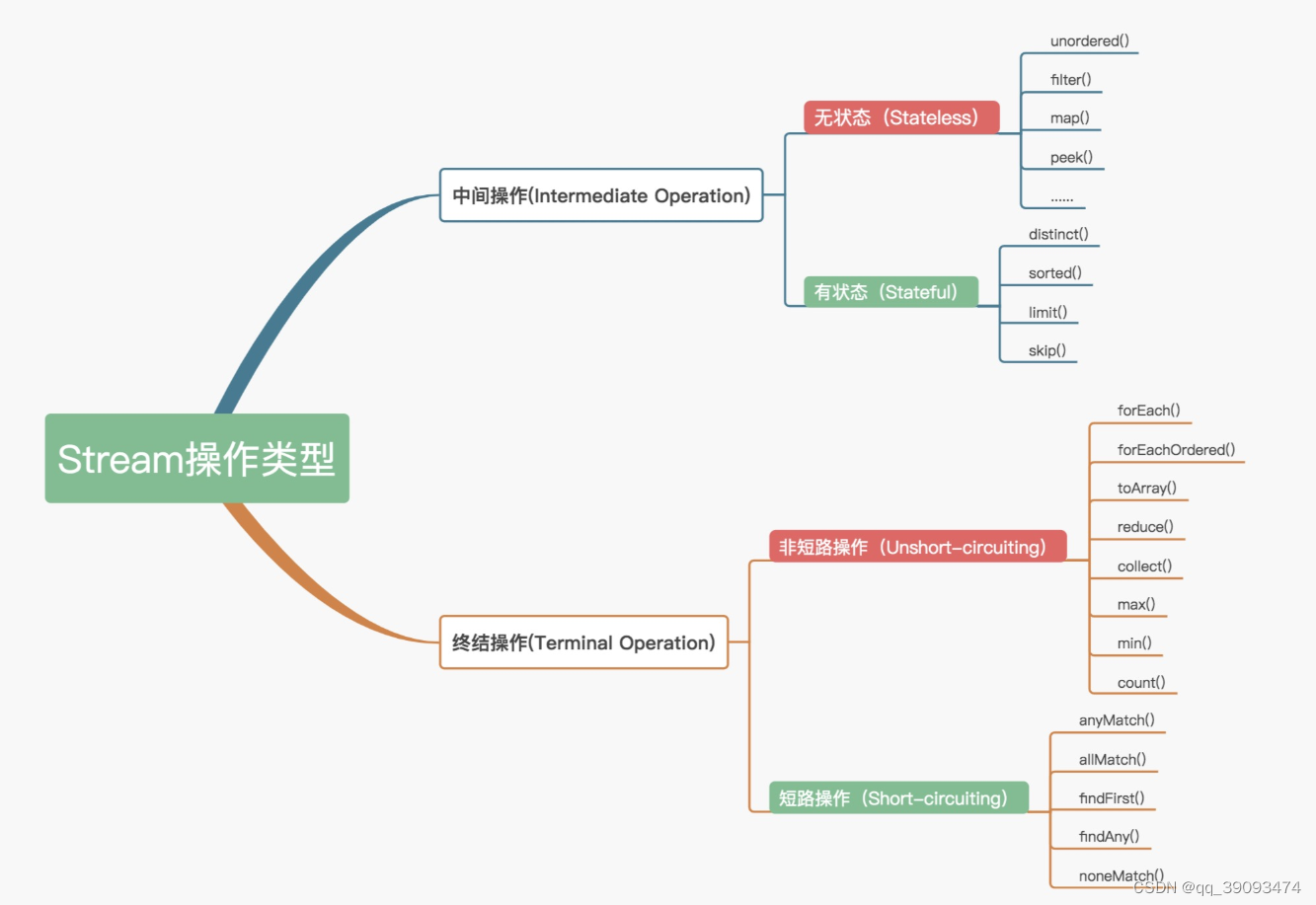
Stream操作分类
中间操作又可以分为无状态(Stateless)与有状态(Stateful)操作
- 无状态是指元素的处理不受之前元素的影响。
- 有状态是指该操作只有拿到所有元素之后才能继续下去。
终结操作又可以分为短路(Short-circuiting)与非短路(Unshort-circuiting)操作
- 短路是指遇到某些
符合条件的元素就可以得到最终结果。 - 非短路是指必须
处理完所有元素就可以得到最终结果。
我们通常还会将中间操作称为懒操作,也正是由这种懒操作结合终结操作、数据源构成的处理管道(Pipeline),实现了 Stream 的高效。
中间操作
无状态
- filter:过滤流,过滤流中的元素
- map:转换流,将一种类型的流转换为另外一种类型的流
- flapMap:拆解流,将流中每一个元素拆解成一个流
filter
filter接收一个Predicate函数接口参数,boolean test(T t);即接收一个参数,返回boolean类型。
@Test
public void testFilter() {
Integer[] arr = new Integer[]{1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
Arrays.stream(arr).filter(x -> x > 3 && x < 8).forEach(System.out::println);
}
输出结果
4
5
6
7
map
map接收一个Function<T, R>函数接口,R apply(T t);即接收一个参数,并且有返回值。
@Test
public void testMap() {
String[] arr = new String[]{"yes", "YES", "no", "NO"};
Arrays.stream(arr).map(x -> x.toLowerCase()).forEach(System.out::println);
}
输出结果
yes
yes
no
no
flapMap
flatMap接收一个Function<T, R>函数接口: Stream flatMap(Function<? super T, ? extends Stream<? extends R>> mapper);即入参为集合类型,返回Stream类型。
@Test
public void testFlatMap() {
String[] arr1 = {"a", "b"};
String[] arr2 = {"e", "f"};
String[] arr3 = {"h", "j"};
// Stream.of(arr1, arr2, arr3).flatMap(x -> Arrays.stream(x)).forEach(System.out::println);
Stream.of(arr1, arr2, arr3).flatMap(Arrays::stream).forEach(System.out::println);
}
输出结果
a
b
e
f
h
j
有状态
- distinct:元素去重
- sorted:元素排序
- limit:获取前面的指定数量的元素
- skip:跳过前面指定数量的元素,获取后面的元素
- concat:把两个stream合并成一个stream
distinct
@Test
public void testDistinct() {
List<String> list = new ArrayList<String>() {
{
add("user1");
add("user2");
add("user2");
add("user2");
}
};
list.stream().distinct().forEach(System.out::println);
}
输出结果
user1
user2
sorted
@Test
public void testSorted1() {
String[] arr1 = {"abc", "a", "bc", "abcd"};
// 按照字符长度排序
System.out.println("lambda表达式");
Arrays.stream(arr1).sorted((x, y) -> {
if (x.length() > y.length())
return 1;
else if (x.length() < y.length())
return -1;
else
return 0;
}).forEach(System.out::println);
// Comparator.comparing是一个键提取的功能
System.out.println("方法引用");
Arrays.stream(arr1).sorted(Comparator.comparing(String::length)).forEach(System.out::println);
}
输出结果
lambda表达式
a
bc
abc
abcd
方法引用
a
bc
abc
abcd
reversed
/**
* 倒序
* reversed(),java8泛型推导的问题,所以如果comparing里面是非方法引用的lambda表达式就没办法直接使用reversed()
* Comparator.reverseOrder():也是用于翻转顺序,用于比较对象(Stream里面的类型必须是可比较的)
* Comparator.naturalOrder():返回一个自然排序比较器,用于比较对象(Stream里面的类型必须是可比较的)
*/
@Test
public void testSorted2_() {
String[] arr1 = {"abc", "a", "bc", "abcd"};
System.out.println("reversed(),这里是按照字符串长度倒序排序");
Arrays.stream(arr1).sorted(Comparator.comparing(String::length).reversed()).forEach(System.out::println);
System.out.println("Comparator.reverseOrder(),这里是按照首字母倒序排序");
Arrays.stream(arr1).sorted(Comparator.reverseOrder()).forEach(System.out::println);
System.out.println("Comparator.naturalOrder(),这里是按照首字母顺序排序");
Arrays.stream(arr1).sorted(Comparator.naturalOrder()).forEach(System.out::println);
}
输出结果
reversed(),这里是按照字符串长度倒序排序
abcd
abc
bc
a
Comparator.reverseOrder(),这里是按照首字母倒序排序
bc
abcd
abc
a
Comparator.naturalOrder(),这里是按照首字母顺序排序
a
abc
abcd
bc
thenComparing
/**
* thenComparing
* 先按照首字母排序
* 之后按照String的长度排序
*/
@Test
public void testSorted3() {
String[] arr1 = {"abc", "a", "bc", "abcd"};
Arrays.stream(arr1).sorted(Comparator.comparing(this::firstChar).thenComparing(String::length)).forEach(System.out::println);
}
public char firstChar(String x) {
return x.charAt(0);
}
输出结果
a
abc
abcd
bc
limit
/**
* limit,限制从流中获得前n个数据
*/
@Test
public void testLimit() {
Stream.iterate(1, x -> x + 2).limit(3).forEach(System.out::println);
}
输出结果
1
3
5
skip
/**
* skip,跳过前n个数据
*/
@Test
public void testSkip() {
Stream.iterate(1, x -> x + 2).skip(1).limit(3).forEach(System.out::println);
}
输出结果
3
5
7
concat
/**
* 可以把两个stream合并成一个stream(合并的stream类型必须相同)
* 只能两两合并
*/
@Test
public void testConcat(){
// 1,3,5
Stream<Integer> stream1 = Stream.iterate(1, x -> x + 2).limit(3);
// 3,5,7
Stream<Integer> stream2 = Stream.iterate(1, x -> x + 2).skip(1).limit(3);
Stream.concat(stream1,stream2).distinct().forEach(System.out::println);
}
输出结果
1
3
5
7
终结操作
非短路操作
- forEach:遍历
- toArray:将流转换为Object数组
- reduce : 归约,可以将流中的元素反复结合起来,得到一个值
- collect:收集,将流装换为其他形式,比如List,Set,Map
- max:返回流的最大值,无方法参数
- min:返回流中的最小值,无方法参数
- count:返回流中的元素总个数,无方法参数
- summaryStatistics:获取汇总统计数据,比如最大值,最小值,平均值等
forEach
@Test
public void testForEach() {
List<String> list = new ArrayList<String>() {
{
add("a");
add("b");
}
};
list.stream().forEach(System.out::println);
}
输出结果
a
b
reduce
@Test
public void testReduce() {
Optional<Integer> optional = Stream.of(1, 2, 3).filter(x -> x > 1).reduce((x, y) -> x + y);
System.out.println(optional.get());
}
输出结果
5
collect
收集是非常常用的一个操作。 将流装换为其他形式。接收到一个Collector接口的实现,用于给Stream中的元素汇总的方法。用collect方法进行收集。方法参数为Collector。Collector可以由Collectors中的toList(),toSet(),toMap(Function(T,R) key,Function(T,R) value)等静态方法实现。
- toList(): 返回一个 Collector,它将输入元素到一个新的 List 。
- toSet() :返回一个 Collector,将输入元素到一个新的 Set 。
- toMap(Function<? super T,? extends K> keyMapper, Function<? super T,? extends U> valueMapper) :返回一个 Collector ,它将元素累加到一个 Map ,其键和值是将所提供的映射函数应用于输入元素的结果。
用户
@Data
@AllArgsConstructor
@ToString
public class User {
private String name;
private Integer age;
private Integer salary;
}
toList,toSet,toSet
@Test
public void testCollect() {
List<User> users = Arrays.asList(new User("张三", 19, 1000),
new User("张三", 58, 2000),
new User("李四", 38, 3000),
new User("赵五", 48, 4000)
);
List<String> collect = users.stream().map(x -> x.getName()).collect(Collectors.toList());
Set<String> collect1 = users.stream().map(x -> x.getName()).collect(Collectors.toSet());
Map<Integer, String> collect2 = users.stream().collect(Collectors.toMap(x -> x.getAge(), x -> x.getName()));
System.out.println(collect);
System.out.println(collect1);
System.out.println(collect2);
}
输出结果
[张三, 张三, 李四, 赵五]
[李四, 张三, 赵五]
{48=赵五, 19=张三, 38=李四, 58=张三}
groupingBy
Collectors.groupingBy()方法根据分类功能分组元素。这个是非常常用的操作。 比如你要对名字相同的进行分组。groupingBy(Function<? super T,? extends K> classifier)
@Test
public void testGroupby() {
List<User> users = Arrays.asList(new User("张三", 19, 1000),
new User("张三", 58, 2000),
new User("李四", 38, 3000),
new User("赵五", 48, 4000)
);
Map<String, List<User>> collect3 = users.stream().collect(Collectors.groupingBy(x -> x.getName()));
System.out.println(collect3);
}
输出结果
{李四=[StreamTest.User(name=李四, age=38, salary=3000)], 张三=[StreamTest.User(name=张三, age=19, salary=1000), StreamTest.User(name=张三, age=58, salary=2000)], 赵五=[StreamTest.User(name=赵五, age=48, salary=4000)]}
partitioningBy
如果只有两类,使用partitioningBy会比groupingBy更有效率,按照工资是否大于2500分组
@Test
public void testPartitioningBy() {
List<User> users = Arrays.asList(new User("张三", 19, 1000),
new User("张三", 58, 2000),
new User("李四", 38, 3000),
new User("赵五", 48, 4000)
);
Map<Boolean, List<User>> map = users.stream().collect(Collectors.partitioningBy(x -> x.getSalary() > 2500));
map.forEach((x, y) -> System.out.println(x + "->" + y));
}
输出结果
false->[StreamTest.User(name=张三, age=19, salary=1000), StreamTest.User(name=张三, age=58, salary=2000)]
true->[StreamTest.User(name=李四, age=38, salary=3000), StreamTest.User(name=赵五, age=48, salary=4000)]
max、min
@Test
public void testMaxAndMin() {
String[] arr = new String[]{"b", "ab", "abc", "abcd", "abcde"};
Stream.of(arr).max(Comparator.comparing(String::length)).ifPresent(System.out::println);
Stream.of(arr).min(Comparator.comparing(String::length)).ifPresent(System.out::println);
}
输出结果
abcde
b
count
@Test
public void testCount(){
String[] arr = new String[]{"b", "ab", "abc", "abcd", "abcde"};
long count = Stream.of(arr).count();
System.out.println(count);
}
输出结果
5
summaryStatistics
我们可以使用summaryStatistics方法获得stream中元素的各种汇总数据
@Test
public void testSummaryStatistics() {
//计算 count, min, max, sum, and average for numbers
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
// IntSummaryStatistics stats = numbers.stream().collect(Collectors.summarizingInt(x -> x));
IntSummaryStatistics stats = numbers
.stream()
.mapToInt(x -> x)
.summaryStatistics();
System.out.println("List中最大的数字 : " + stats.getMax());
System.out.println("List中最小的数字 : " + stats.getMin());
System.out.println("所有数字的总和 : " + stats.getSum());
System.out.println("所有数字的平均值 : " + stats.getAverage());
}
输出结果
List中最大的数字 : 10
List中最小的数字 : 1
所有数字的总和 : 55
所有数字的平均值 : 5.5
短路操作
- anyMatch:检查是否有一个元素匹配,方法参数为断言型接口
- allMatch:检查是否匹配所有元素,方法参数为断言型接口
- findFirst:返回第一个元素,无方法参数
- findAny:返回当前流的任意元素,无方法参数
- noneMatch:检查是否没有匹配所有元素,方法参数为断言型接口
anyMatch
@Test
public void testAnyMatch() {
String[] arr = new String[]{"b", "ab", "abc", "abcd", "abcde"};
Boolean aBoolean = Stream.of(arr).anyMatch(x -> x.startsWith("a"));
System.out.println(aBoolean);
}
输出结果
true
findFirst
@Test
public void testFindFirst() {
String[] arr = new String[]{"b", "ab", "abc", "abcd", "abcde"};
String str = Stream.of(arr).parallel().filter(x -> x.length() > 3).findFirst().orElse("noghing");
System.out.println(str);
}
输出结果
abcd
findAny
/**
* findAny
* 找到所有匹配的元素
* 对并行流十分有效
* 只要在任何片段发现了第一个匹配元素就会结束整个运算
*/
@Test
public void testFindAny() {
String[] arr = new String[]{"b", "ab", "abc", "abcd", "abcde"};
Optional<String> optional = Stream.of(arr).parallel().filter(x -> x.length() > 2).findAny();
optional.ifPresent(System.out::println);
}
输出结果
abc
Optional类型
通常聚合操作会返回一个Optional类型,Optional表示一个安全的指定结果类型,所谓的安全指的是避免直接调用返回类型的null值而造成空指针异常,调用optional.ifPresent()可以判断返回值是否为空,或者直接调用ifPresent(Consumer<? super T> consumer)在结果不为空时进行消费操作;调用optional.get()获取返回值。通常的使用方式如下:
@Test
public void testOptional() {
List<String> list = new ArrayList<String>() {
{
add("user1");
add("user2");
}
};
Optional<String> opt = Optional.of("user3");
opt.ifPresent(list::add);
list.forEach(System.out::println);
}
输出结果
user1
user2
user3
使用Optional可以在没有值时指定一个返回值,例如
@Test
public void testOptional2() {
Integer[] arr = new Integer[]{4, 5, 6, 7, 8, 9};
Integer result = Stream.of(arr).filter(x -> x > 9).max(Comparator.naturalOrder()).orElse(-1);
System.out.println(result);
Integer result1 = Stream.of(arr).filter(x -> x > 9).max(Comparator.naturalOrder()).orElseGet(() -> -1);
System.out.println(result1);
Integer result2 = Stream.of(arr).filter(x -> x > 9).max(Comparator.naturalOrder()).orElseThrow(RuntimeException::new);
System.out.println(result2);
}
输出结果
-1
-1
java.lang.RuntimeException
原始类型流
在数据量比较大的情况下,将基本数据类型(int,double…)包装成相应对象流的做法是低效的,因此,我们也可以直接将数据初始化为原始类型流,在原始类型流上的操作与对象流类似,我们只需要记住两点
- 原始类型流的初始化
- 原始类型流与流对象的转换
/**
* 原始类型流的初始化
*/
@Test
public void testRawStream1() {
IntStream intStream = IntStream.of(1, 3);
IntStream stream1 = IntStream.rangeClosed(0, 1);
IntStream stream2 = IntStream.range(0, 1);
intStream.forEach(System.out::println);
System.out.println("包括右边界");
stream1.forEach(System.out::println);
System.out.println("不包括右边界");
stream2.forEach(System.out::println);
}
输出结果
1
3
包括右边界
0
1
不包括右边界
0
流与原始类型流的转换
@Test
public void testRawStream2() {
IntStream intStream = IntStream.of(1, 3);
Stream<Integer> stream = intStream.boxed();
IntStream intStream1 = stream.mapToInt(Integer::new);
intStream1.forEach(System.out::println);
}
输出结果
1
3
并行流
可以将普通顺序执行的流转变为并行流,只需要调用顺序流的parallel() 方法即可,如
Stream.iterate(1, x -> x + 1).limit(10).parallel();
并行流的执行顺序
我们调用peek方法来瞧瞧并行流和串行流的执行顺序,peek方法顾名思义,就是追踪流内的数据,peek方法声明为Stream peek(Consumer<? super T> action);加入打印程序可以观察到通过流内数据,见如下代码:
public void peek1(int x) {
System.out.println(Thread.currentThread().getName() + ":->peek1->" + x);
}
public void peek2(int x) {
System.out.println(Thread.currentThread().getName() + ":->peek2->" + x);
}
public void peek3(int x) {
System.out.println(Thread.currentThread().getName() + ":->final result->" + x);
}
/**
* peek,监控方法
* 串行流和并行流的执行顺序
*/
@Test
public void testPeek() {
Stream<Integer> stream = Stream.iterate(1, x -> x + 1).limit(10);
stream.peek(this::peek1).filter(x -> x > 5)
.peek(this::peek2).filter(x -> x < 8)
.peek(this::peek3)
.forEach(System.out::println);
}
@Test
public void testPeekParallel() {
Stream<Integer> stream = Stream.iterate(1, x -> x + 1).limit(10).parallel();
stream.peek(this::peek1).filter(x -> x > 5)
.peek(this::peek2).filter(x -> x < 8)
.peek(this::peek3)
.forEach(System.out::println);
}
testPeek方法输出结果
main:->peek1->1
main:->peek1->2
main:->peek1->3
main:->peek1->4
main:->peek1->5
main:->peek1->6
main:->peek2->6
main:->final result->6
6
main:->peek1->7
main:->peek2->7
main:->final result->7
7
main:->peek1->8
main:->peek2->8
main:->peek1->9
main:->peek2->9
main:->peek1->10
main:->peek2->10
testPeekParallel输出结果
main:->peek1->7
ForkJoinPool.commonPool-worker-9:->peek1->6
ForkJoinPool.commonPool-worker-2:->peek1->3
main:->peek2->7
ForkJoinPool.commonPool-worker-9:->peek2->6
ForkJoinPool.commonPool-worker-9:->final result->6
main:->final result->7
7
6
ForkJoinPool.commonPool-worker-13:->peek1->4
ForkJoinPool.commonPool-worker-4:->peek1->9
ForkJoinPool.commonPool-worker-11:->peek1->2
ForkJoinPool.commonPool-worker-6:->peek1->1
main:->peek1->8
main:->peek2->8
ForkJoinPool.commonPool-worker-2:->peek1->5
ForkJoinPool.commonPool-worker-4:->peek2->9
ForkJoinPool.commonPool-worker-9:->peek1->10
ForkJoinPool.commonPool-worker-9:->peek2->10
我们将stream.filter(x -> x > 5).filter(x -> x < 8).forEach(System.out::println)的过程想象成管道,我们在管道上加入的peek相当于一个阀门,透过这个阀门查看流经的数据
- 当我们使用顺序流时,数据按照源数据的顺序依次通过管道,当一个数据被
filter过滤,或者经过整个管道而输出后,第二个数据才会开始重复这一过程 - 当我们使用并行流时,系统除了主线程外启动了6个线程(我的电脑是6核12线程)来执行处理任务,因此执行是无序的,但同一个线程内处理的数据是按顺序进行的。
sorted()、distinct()等对并行流的影响
对于并行流执行sorted()、distinct(),会使得运行时间大大增加,这个说法是错误的,测试表明不管是filter()还是distinct().sorted(),并行流都比串行流高效
/**
* 生成一亿条0-100之间的记录
*/
@Test
public void testParallelDistinct() {
Random random = new Random();
List<Integer> list = Stream.generate(() -> random.nextInt(100)).limit(100000000).collect(Collectors.toList());
long begin1 = System.currentTimeMillis();
list.stream().filter(x -> (x > 10)).filter(x -> x < 80).count();
long end1 = System.currentTimeMillis();
System.out.println("串行流执行时间:" + (end1 - begin1));
list.stream().parallel().filter(x -> (x > 10)).filter(x -> x < 80).count();
long end2 = System.currentTimeMillis();
System.out.println("并行流执行时间:" + (end2 - end1));
long beginDis = System.currentTimeMillis();
list.stream().filter(x -> (x > 10)).filter(x -> x < 80).distinct().sorted().count();
long end1Dis = System.currentTimeMillis();
System.out.println("串行流执行排序时间:" + (end1Dis - beginDis));
list.stream().parallel().filter(x -> (x > 10)).filter(x -> x < 80).distinct().sorted().count();
long end2Dis = System.currentTimeMillis();
System.out.println("并行流执行排序时间:" + (end2Dis - end1Dis));
}
输出结果
串行流执行时间:2009
并行流执行时间:514
串行流执行排序时间:2023
并行流执行排序时间:699
总结
Java8中的lambda表达式可能一开始用的时候还不是很熟悉,但是只要熟悉了,你会发现非常的好用,而且lambda表达式结合stream API对集合的处理非常方便,在平常项目中可以非常的省时间,提高写代码的效率。
Stream 详解
Stream 中的常用方法:
| 方法 | 参数 | 作用 |
|---|---|---|
| filter | Predicate<? super T> predicate | 过滤 |
| map | Function<? super T, ? extends R> mapper | 转换 |
| flatMap | Function<? super T, ? extends Stream<? extends R>> mapper | 转换+扁平化 |
| distinct | 去重 | |
| sorted | Comparator<? super T> comparator | 排序 |
| limit | long n | 限量 |
| skip | long n | 跳过 |
| forEach | Consumer<? super T> action | 遍历 |
| anyMatch/allMatch | Predicate<? super T> predicate | 匹配 |
Collect 详解
Collect 中的常用方法:
| 方法 | 返回类型 | 作用 |
|---|---|---|
| toList | List | 转成一个 List |
| toSet | Set | 转成一个 Set |
| toMap | Map<K,U> | 转成一个 Map |
| joining | String | 拼接所有元素,返回一个 String |
| counting | Long | 返回元素个数 |
| minBy | Optional | 选出最小元素 |
| maxBy | Optional | 选出最大元素 |
| averagingInt | Double | 求平均值 |
| summingInt | Integer | 求和 |
| groupingBy | Map<K, List> | 对元素进行分组 |
| partitioningBy | Map<Boolean, List> | 将元素分成 true 和 false 两个分组 |