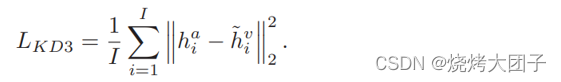目录
论文链接
研究背景
LIBS 的整体框架
序列级知识蒸馏
上下文级知识蒸馏
最长公共子序列 (LCS)
帧级别知识蒸馏
论文链接
[1911.11502] Hearing Lips: Improving Lip Reading by Distilling Speech Recognizers (arxiv.org)
研究背景
这篇文章针对由于唇语识别动作具有模糊性,提取判别特征比较困难,所以唇语识别的性能不如语音识别的问题提出了LIBS方法,通过学习语音识别器来加强唇语识别,给定一个预先训练好的语音识别器,然后从语音识别器中提取特征,作为补充线索来帮助唇读器的训练,分为序列级别、上下文级别和帧级别来进行知识蒸馏。
LIBS 的整体框架
LIBS 的整体框架,教师处理语音识别,学生网络处理唇读,语音识别器和唇读器都基于注意力的序列到序列架构。

唇读器输入视频帧序列xv,y是目标字符序列。预训练的语音识别器读入音频帧序列 x^a,输出预测的字符序列 y。同时,编码器隐藏特征ha、序列向量sa、上下文向量ca也可以得到,用来指导唇读器的训练。LIBS方法的训练目标就是最小化损失函数:
![]()
其中 LKD1、LKD2 和 LKD3 构成多粒度知识蒸馏,分别工作在序列级、上下文级和帧级。 λ1、λ2 和 λ3 是相应的平衡权重。
序列级知识蒸馏
序列级知识蒸馏,序列向量 s包含输入序列的语义信息,对于一个视频帧序列xv和它对应的音频帧序列xa,它们的序列向量sa和sv应该是相同的,因为它们是同一事物的不同表达。因此,序列级知识蒸馏表示为:
![]()
t是一个简单的变换函数(例如线性或仿射函数),把特征嵌入到具有相同维度的空间中。
上下文级知识蒸馏
对于上下文级知识蒸馏,当解码器在某个时间步预测一个字符时,注意力机制使用上下文向量来总结与当前输出最相关的输入信息。所以如果唇读器和语音识别器在该时间步预测相同的字符的话,上下文向量 cv 和 ca 应该包含相同的信息。所以上下文级别的知识蒸馏应该使得 cv 和 ca 相同。考虑到语音识别的句子可能不完善,RNN 计算具有顺序性,所以即使预测句子中有相同的字符,它们对应的上下文向量也会因为位置不同而不同。
最长公共子序列 (LCS)
针对这个问题,文章中提出了一种基于最长公共子序列 (LCS) 的过滤方法来细化提取的特征。LCS 比较两个序列,找出两个序列中相同顺序的公共子序列,选择最长的序列。 因为LCS的公共子序列不一定是连续的,所以可以保留了字符之间的相对位置信息。

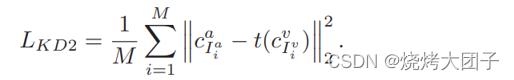
帧级别知识蒸馏
第三个级别是,帧级别知识蒸馏。因为知道视频和音频的对应关系后,如果直接将视频帧特征与对应的音频特征进行匹配的话,由于采样率不同,视频序列和音频序列长度不一致,并且数据的开头或结尾可能出现空白,就无法保证视频和音频严格同步。所以文章提出了通过首先学习视频和音频的对应关系,然后进行帧级别知识蒸馏的方法来解决这个问题。因为视频隐藏特征hv包含与音频特征ha 最相似的信息,并且语音信号包含与视觉信号互补的信息,所以使hv 和ha 相同可以增强唇读器提取视觉特征的能力。