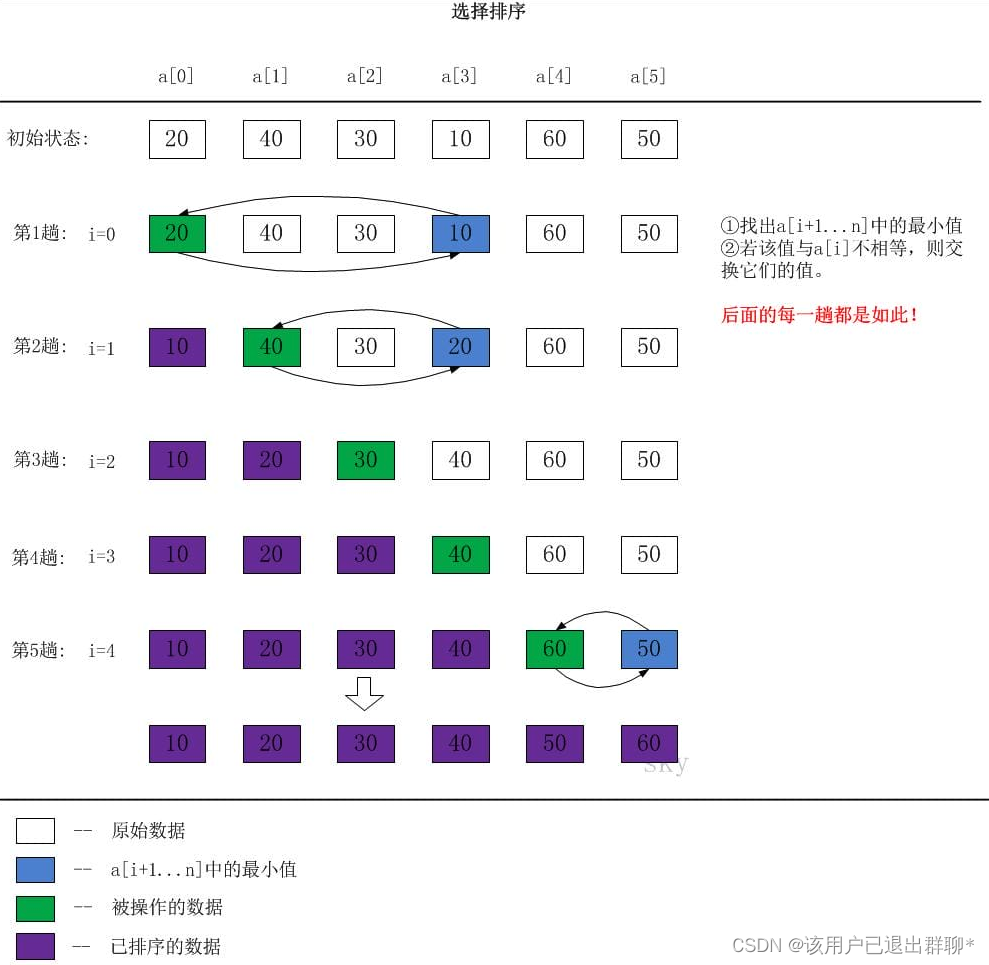
堆空间和栈空间
堆空间和栈空间是计算机内存中的两个存储区域,主要的区别有以下几点:
- 分配方式:栈空间中的内存由编译器或解释器自动分配和释放,无需手动干预。堆空间中的内存则需要由程序员手动申请和释放。
- 内存大小:栈空间通常比堆空间小,而且大小是固定的。堆空间则可以根据需要动态分配和释放内存,大小相对较大。
- 存储方式:栈空间采用“先进后出”的存储方式,也就是说,最后进入栈空间的数据最先被处理,先进入栈空间的数据最后被处理。堆空间则没有这种先后顺序,数据可以随时存取和修改。
- 存储内容:栈空间通常用于存储局部变量、函数参数、函数调用信息等。堆空间则用于存储动态分配的内存,例如使用
malloc()、calloc()、realloc()等函数申请的内存。
总之,堆空间和栈空间都是计算机内存中的存储区域,其主要区别在于分配方式、内存大小、存储方式和存储内容等方面。了解堆空间和栈空间的区别可以帮助程序员更好地管理内存,避免出现内存泄漏、栈溢出等问题。
python存储
在 Python 中,所有的变量都是对象,对象在内存中存储的位置可以是堆空间或栈空间,具体取决于对象的类型和使用方式。
一般来说,Python 中的数字、字符串等基本类型的对象都存储在栈空间中,而复杂的对象如列表、字典、对象实例等则存储在堆空间中。当这些对象被作为参数传递给函数时,它们的引用会被压入栈空间中,函数返回时再从栈空间中弹出这些引用,但实际的对象并没有被复制,仍然存在于堆空间中。
# 数字、字符串等基本类型的对象存储在栈空间中
a = 1 # a 存储在栈空间中,值为 1
b = "hello" # b 存储在栈空间中,值为 "hello"
# 列表、字典等复杂类型的对象存储在堆空间中
c = [1, 2, 3] # c 存储在栈空间中,指向的对象 [1, 2, 3] 存储在堆空间中
d = {"name": "Alice", "age": 20} # d 存储在栈空间中,指向的对象 {"name": "Alice", "age": 20} 存储在堆空间中
# 对象实例也存储在堆空间中
# 类定义本身是在编译时创建的,因此类本身是存储在代码段中的。但是,当创建类的实例时,实例对象是动态分配的,其大小不固定,需要存储在堆空间中。
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
e = Person("Bob", 30) # e 存储在栈空间中,指向的对象 Person("Bob", 30) 存储在堆空间中
需要注意的是,Python 中的垃圾回收机制会自动管理堆空间中的内存,当堆空间中的对象不再被引用时,垃圾回收机制会自动回收这些内存,释放给操作系统。而栈空间中的内存则由编译器或解释器自动管理,当栈空间中的变量超出作用域或函数返回时,这些变量所占用的内存就会被自动释放。
在 Python 中,列表和字典等复杂类型的对象是动态分配的,其大小不固定。为了方便存储和管理,这些对象通常存储在堆空间中。
当定义一个列表或字典时,Python 会先在栈空间中分配一块空间,用于存储该变量的引用。该引用指向一个在堆空间中分配的内存块,该内存块中存储了实际的列表或字典对象。因为列表和字典等对象的大小不固定,可能需要动态地调整内存大小,所以通常使用动态内存分配方式,即在堆空间中分配一块较大的内存池,然后根据实际需要动态地申请和释放内存块。
需要注意的是,在 Python 中,对象的引用和实际的对象是分开存储的,因此,当多个变量引用同一个对象时,它们都指向同一个内存块。这也就意味着,当其中一个变量改变了对象的值时,其他引用该对象的变量也会受到影响。这种引用方式在 Python 中被称为“对象引用语义”,与其他编程语言的“值传递语义”不同。
题外话1
在 Python 中,类的生命周期指的是从类被创建到被销毁的整个过程。在程序运行时,当 Python 解释器遇到类定义语句时,会创建一个类对象,并将其存储在代码段中。类对象包含了类的属性和方法等信息,并可以用于创建类的实例对象。
类对象的生命周期与程序的运行周期一致,即从程序开始运行到程序结束。在程序运行期间,类对象一直存在于内存中,可以用于创建多个实例对象,调用类的方法等操作。当程序运行结束时,Python 解释器会自动销毁类对象,并释放其占用的内存空间。
需要注意的是,类的生命周期与实例对象的生命周期是不同的,它们是独立的对象,存储在不同的空间中,具有不同的生命周期。类对象的创建和销毁由 Python 解释器自动管理,程序员无需手动干预。
题外话2
在 Python 中,数字、字符串等基本类型的对象都是不可变的,其大小是固定的,因此可以直接存储在栈空间中。
栈空间通常用于存储函数调用时的局部变量和函数参数等信息。当函数被调用时,操作系统会为函数分配一块栈空间,用于存储函数调用时需要使用的局部变量和参数等信息。这些信息通常是在函数调用时创建的,当函数返回时,栈空间也会被自动销毁,这样可以确保内存的高效使用和安全性。
在 Python 中,数字、字符串等基本类型的对象都是不可变的,它们的值在创建后就不会发生变化。因此,Python 可以将它们直接存储在栈空间中,不需要像列表、字典等可变类型一样,动态调整内存大小,从而提高了程序的执行效率。而对于可变类型的对象,Python 通常会将它们存储在堆空间中,这样可以动态调整内存大小,确保程序的灵活性和可靠性。
题外话3
栈是一种具有后进先出(Last In First Out)特性的数据结构,它非常适合用于存储函数调用时的局部变量和函数参数等信息。这是因为函数调用过程中,会按照调用顺序依次进入栈中,而在函数返回时,则会按照相反的顺序依次从栈中弹出。因此,栈空间被广泛应用于函数调用和局部变量存储的原因,主要有以下几个方面:
- 快速分配和回收内存:栈空间的大小通常是固定的,由操作系统预先分配好,因此在使用栈空间时,可以快速地分配和回收内存空间,不需要像堆空间那样进行复杂的内存管理。
- 访问速度快:由于栈空间是连续的内存块,访问起来非常快速,而且在 CPU 中已经内置了栈指针,因此对于栈的操作也比较高效。
- 存取方式简单:栈空间只允许在栈顶进行存取操作,因此存取方式非常简单,不需要像堆空间那样进行指针操作等。
- 便于实现递归:由于函数调用过程本质上也是一种递归调用,栈空间可以很方便地实现递归操作,而且由于栈空间的大小固定,可以很好地控制递归的深度和内存的使用。
总之,栈空间由于具有快速分配和回收内存、访问速度快、存取方式简单、便于实现递归等优点,因此非常适合用于存储函数调用时的局部变量和函数参数等信息。