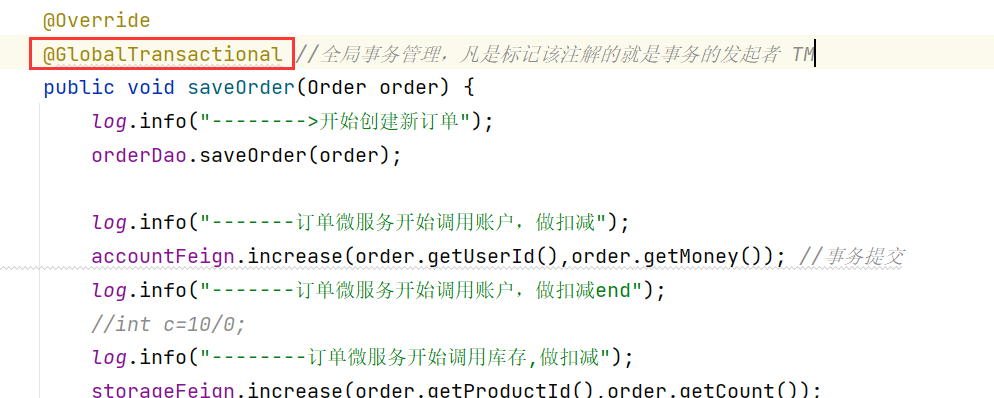
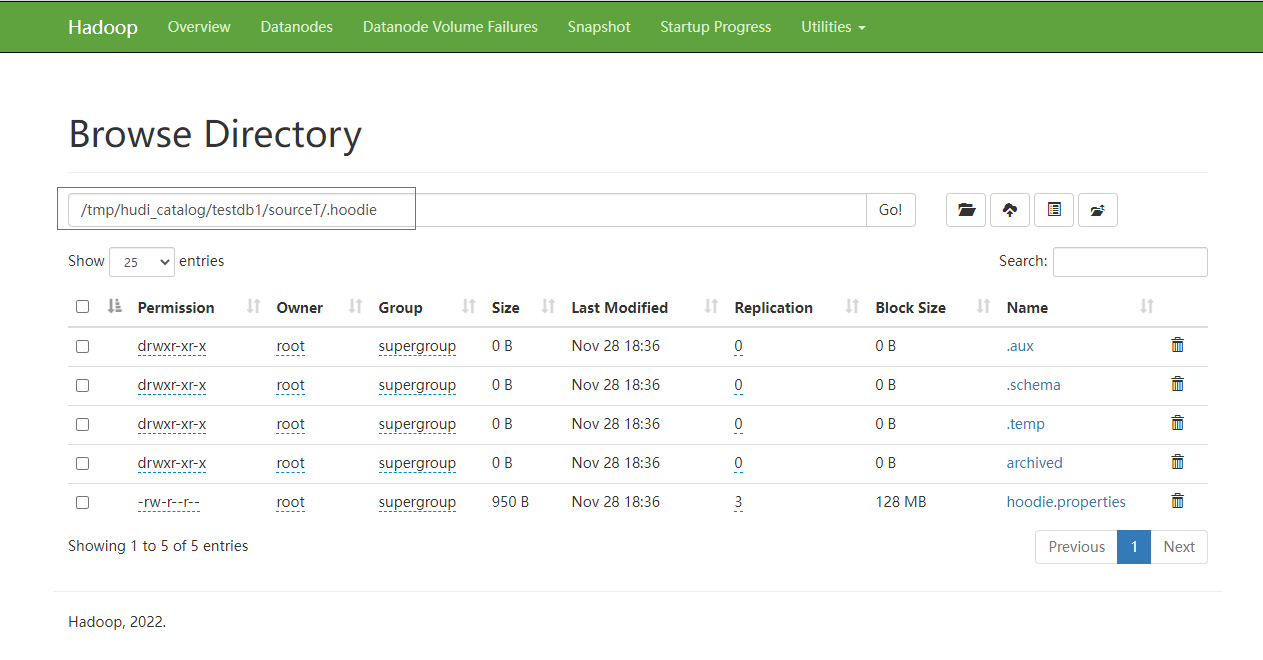
安装监控平台
通过 grafana(前端) + prometheus(时序数据库) + node_exporter(硬件资源收集器) 安装监控系统
node_exporter 安装在被压测的服务器上,因为我本机已经安装过,所以只需要通过find 命令找到node所在位置,执行 `./node_exporter` 启动收集器就可以。
没有安装过的可以直接解压tar包到指定目录后执行命令。
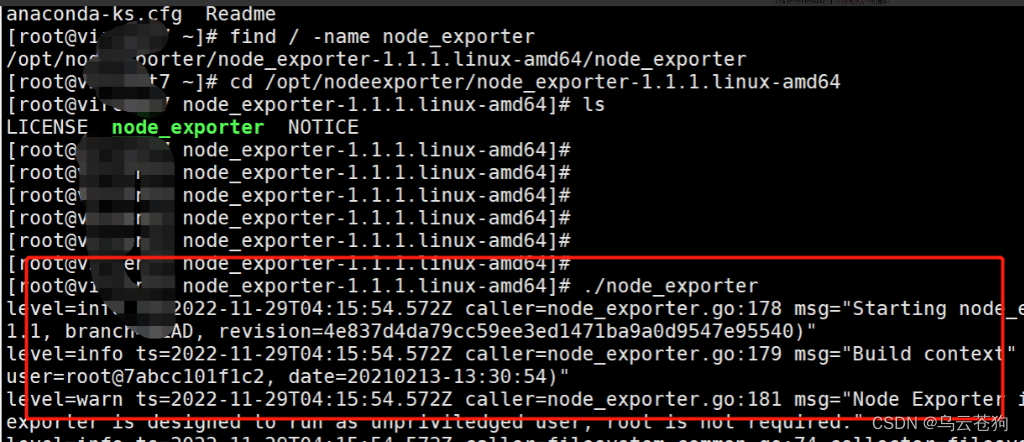
端口:9100
在监控服务器上安装prometheus
tar.gz包,解压 然后启动 `./prometheus 默认端口: 9090
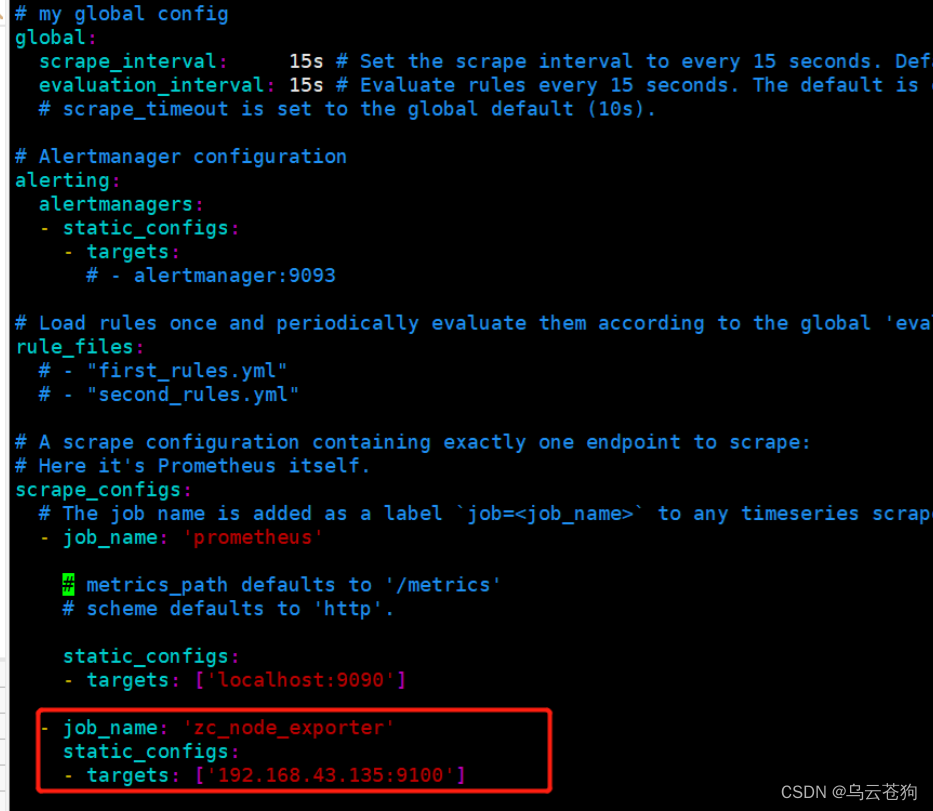
在prometheus yml 文件配置 node_exporter的地址
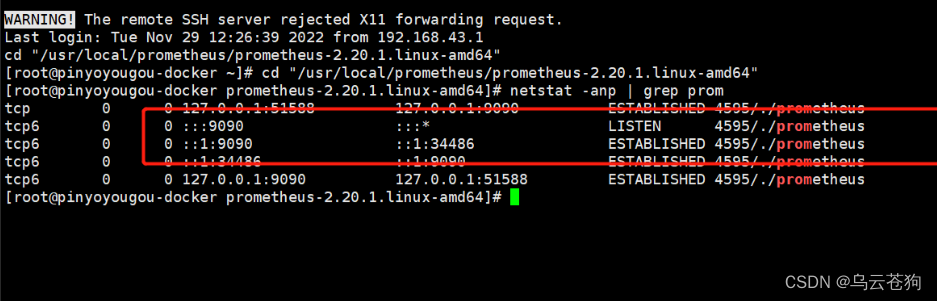
查看启动是否已经成功了
在监控服务器上安装grafana 启动 `systemctl restat grafana-server` 默认端口: 3000
- 安装grafana
yum install grafana-7.4.3-1.x86_64.rpm -y
启动:systemctl restart grafana-server
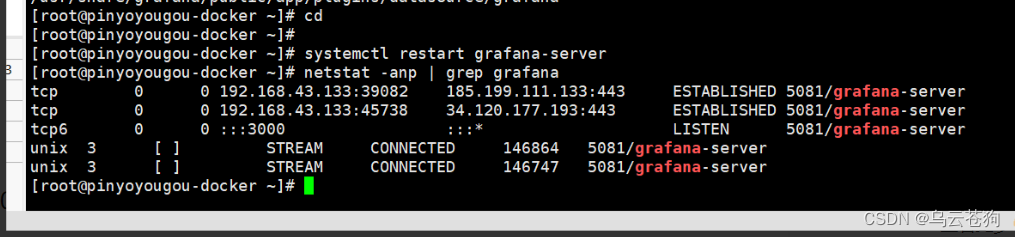
启动成功
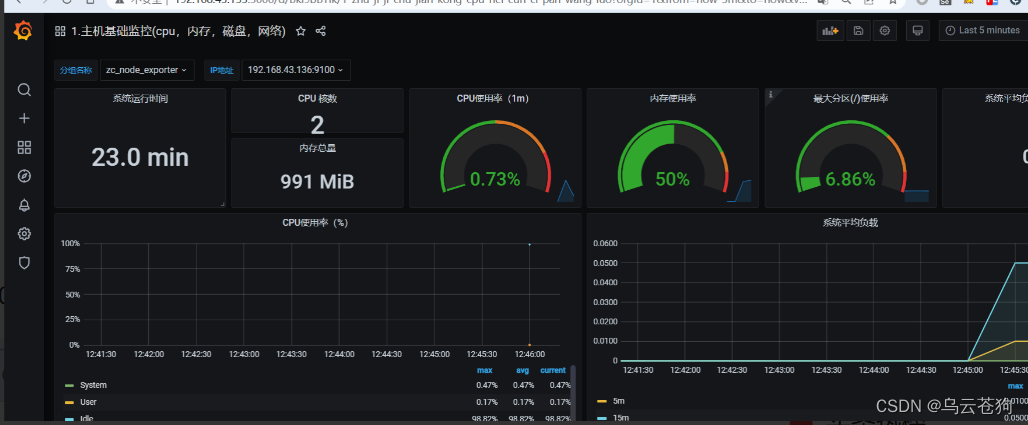
升级grafana
1.停服务
systemctl stop grafana-server.service
2.备份
cp -rpv /var/lib/grafana /opt/grafana_bak/grafana_data$(date +%Y%m%d%H%M)
cp -rpv /usr/share/grafana /opt/grafana_bak/grafana_share$(date +%Y%m%d%H%M)
cp -rpv /etc/grafana /opt/grafana_bak/grafana_conf$(date +%Y%m%d%H%M)
3.升级
wget https://mirrors.tuna.tsinghua.edu.cn/grafana/yum/rpm/grafana-6.1.2-1.x86_64.rpm --no-check-certificate
yum install grafana-6.1.2-1.x86_64.rpm -y
systemctl restart grafana-server.service
安装 stress-ng: 性能测试模拟工具
该工具可以模拟服务器 各种压力情况和 重现 磁盘 IO cpu 性能导致的问题
# 安装epel源,更新系统
yum install -y epel-release.noarch && yum -y update
# 安装stess-ng 的工具
yum install -y stress-ng模拟 进程上下文切换导致的问题
多个线程运行时,如:由第一个线程切到第二个,第二个切到第三个,依次类推,就如同win系统,切到不同的软件程序, 在切换过程中需要保存资源,不然在切换进程中会导致资料丢失
输出一个shell 用于模拟
# nproc -得到当前电脑cpu的核数
# (( proc_cnt = `nproc`*10 )); 变量赋值 cpu核*10
# --cpu $proc_cnt $proc_cnt 是shell编程中变量的引用
# --pthread 每个进程有多少个线程
# --timeout 超时时间,在命令执行多长时间之后自动结束
(( proc_cnt = `nproc`*10 )); stress-ng --cpu $proc_cnt --pthread 1 --timeout 150启动成功
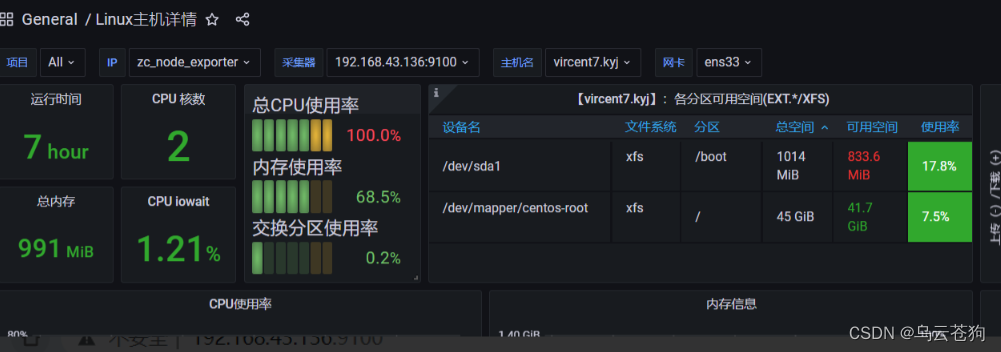
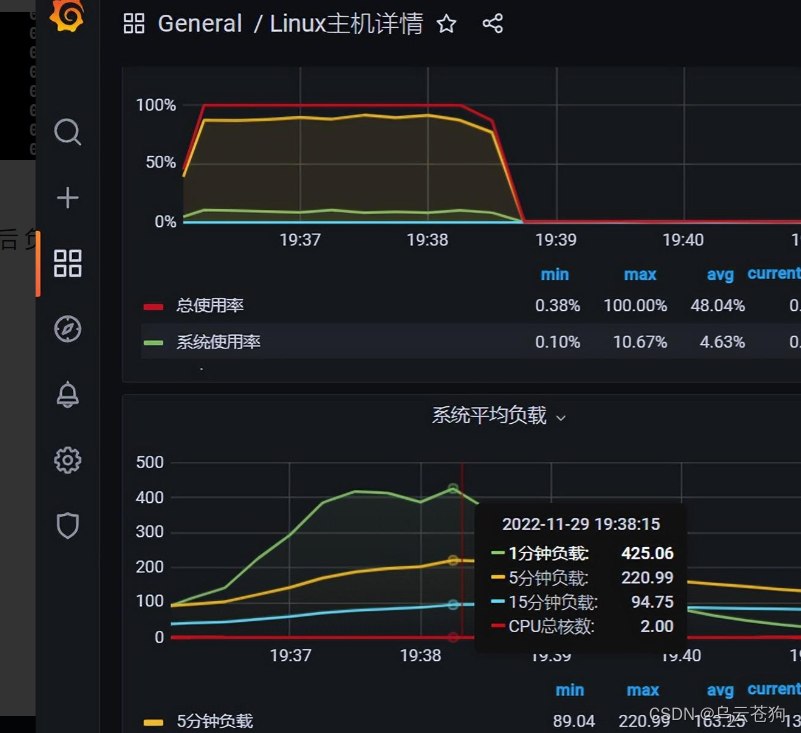
loadaverage 有持续上升 cpu被100% 使用 us + sy + si=100%
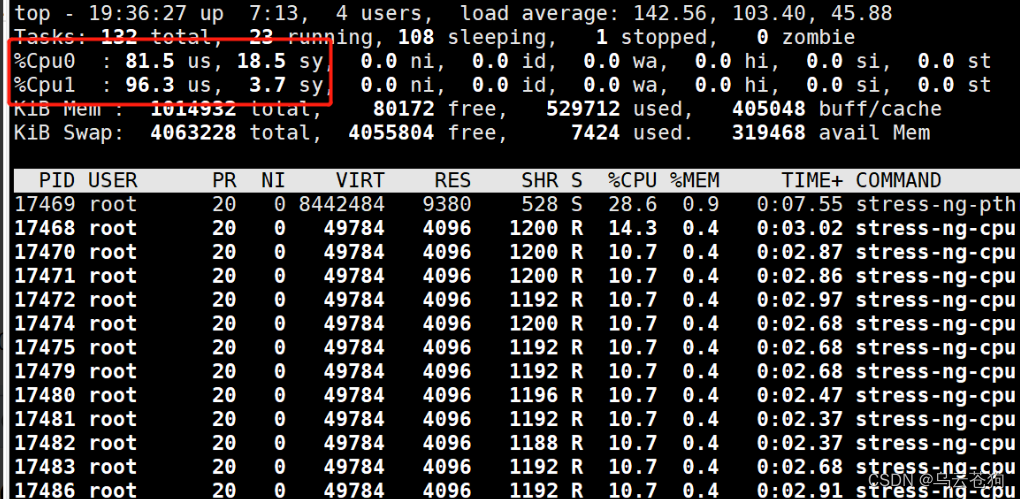
load average 和us 较高
stressng 进程停止后 负载和us ys 开始减低
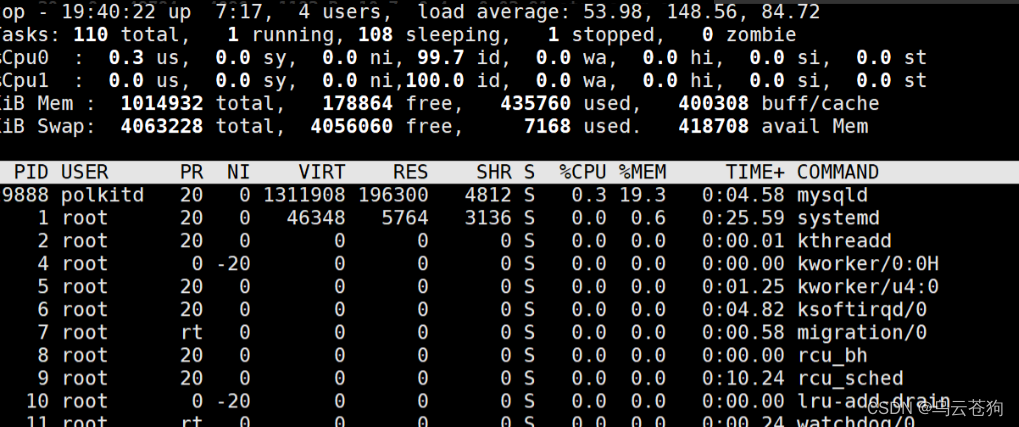
cpu负载达到100
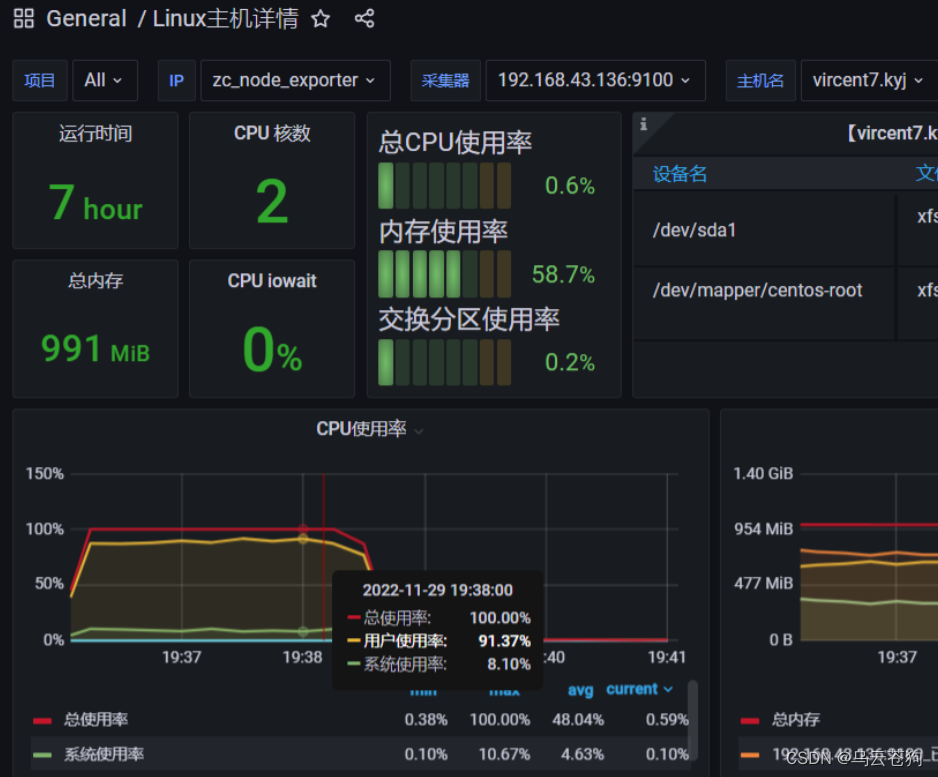
系统平均负载 远大于cpu数量
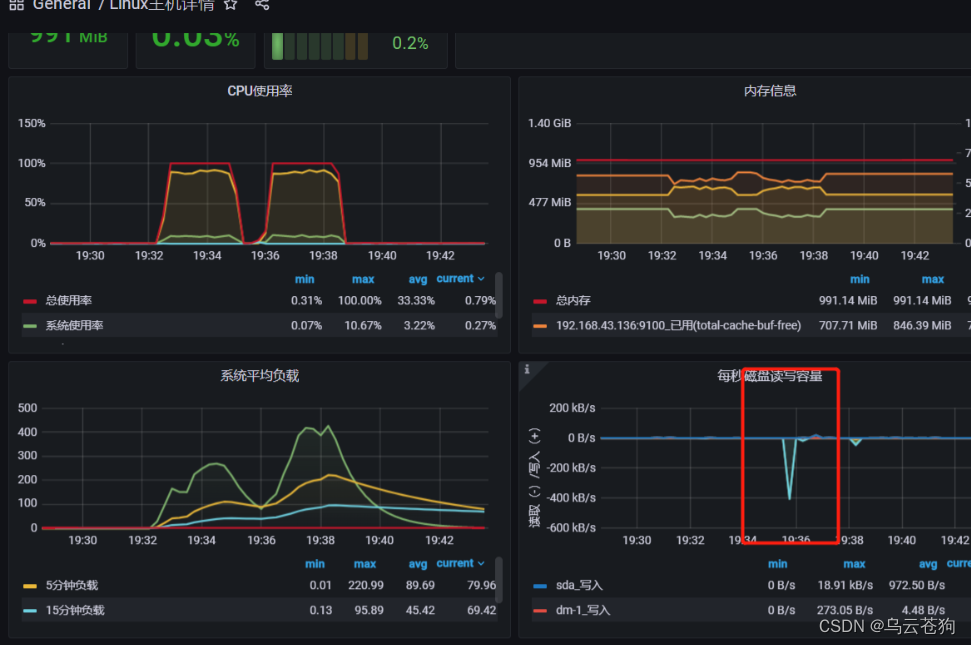
内存和磁盘没有多大影响
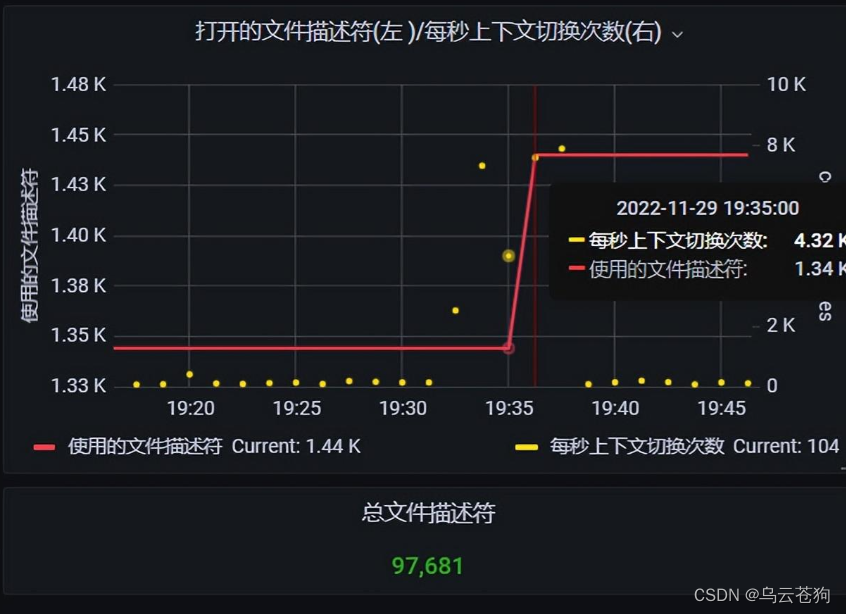
上下文切换达到顶点,有大量的上下文切换
使用vmstat 查看 每s打印一次信息 (vmstat是 虚拟内存统计的缩写 ,可以对虚拟内存,进程,cpu 活动进行监控)
system中 cs 的数值比较高 ------肯定有大量的上下文切换。
procs:
r 显示多少进程在等待,
b 显示多少进程在不可中断的休眠
memory:
swod显示多少块被换出磁盘
free显示剩下的空闲块
buff正在被用作缓冲区的块
cache正在被用作操作系统的缓存
swap:
SI 交换分区中的换入
SO 交换分区中的换出
io:
显示了多少块(BYTE)设备 读取 (bi)写(bo) 通常反映了硬I/0
system:
显示每秒中断(in)和上下文切换(CS)的数量
CPU:
显示所有的CPU时间花费在各类操作的百分比,包括执行用户代码(非内核),执行系统代码(内核),空闲和等待IO
us sy id wa st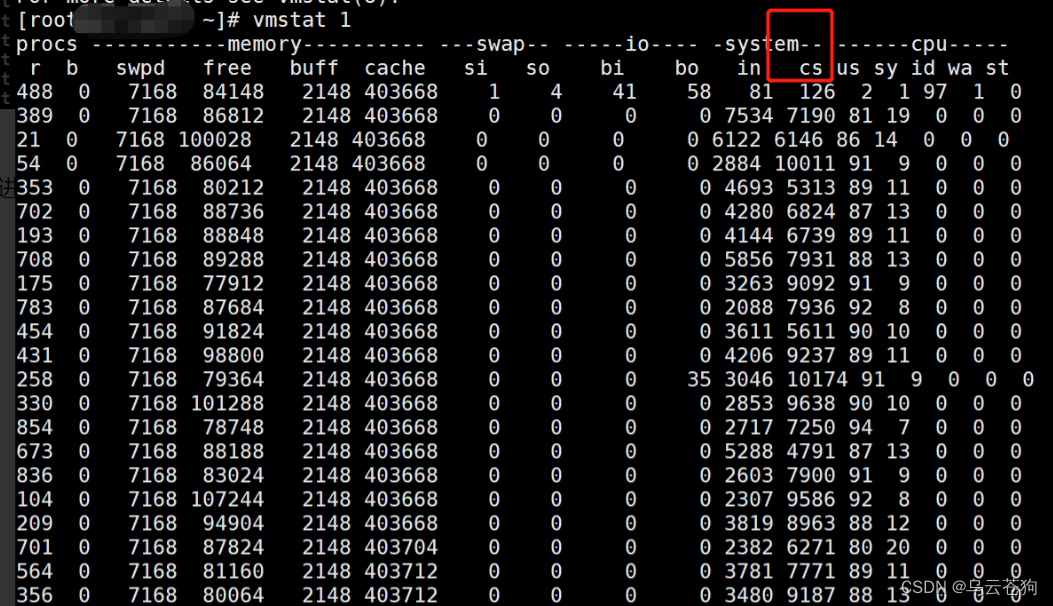
上下文交换cs,cpu us 和sy较高
但是从上图的数据没办法确定 具体是那个线程导致频繁的抢占cpu进行上下文切换,所以这个时候需要使用 pidstat 查看 具体的上下文数据 pidstat -w 1
- -u 用于查看cpu的数据
- -w 看cpu的上下文数据
- UID PID
- cswch/s 自愿上下文切换次数
- nvcswch/s 非自愿上下文切换次数
- Command
显示的是 上下文切换的数据比较大的进程
得出具体进程和进程id
分析得出的结论:
- 通过top命令得到 loadaverage 一直在增加,us+ys≈ 100%,us 较高,sy较低
- 通过vmstat命令得出 procs 的r 线程等待队列长度,正在运行和等待的CPU进程数很大
procs -r
r : 数字 显示cpu中有多少个进程正在等待
如果r列是数字,大于cpu核数,那么说明现在现在有大量的进程在等待cpu进行计算,现在可能出现了cpu不够用的情况。----cpu成了我们的性能瓶颈,此时,可能需要去增加cpu数量;或者减少运行的进程数
b : 数字 现在有多少进程正在不可中断的休眠. 如果这个数字过大,就说明,资源不够用。- 通过vmstat命令得出 system 的in(每秒中断次数) 和 cs(上下文切换次数) 都很大
system
显示每秒中断(in)和上下文切换(CS)的数量- vmstat:free、buff、cache变化不大
- pidstat: nvcswch/s 非自愿上下文切换在逐步升高
排查思路:
使用top 查看总体情况,再使用 vmstat 对虚拟内存,进程,cpu 活动进行监控,分析出cs 上下文数值,再通过pidstat 查看频繁切换上下文信息的 pid