🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
介绍
构建一个 CNN
为什么将 CNN 用于图像处理?
图像作为输入
CNN 的应用
分类
本地化
检测
分割
CNN 的构建模块
卷积层
练习 4.01:计算卷积层的输出形状
池化层
练习 4.02:计算一组卷积层和池化层的输出形状
全连接层
旁注——从 PyTorch 下载数据集
活动 4.01:为图像分类问题构建 CNN
数据扩充
使用 PyTorch 进行数据扩充
活动 4.02:我实施数据扩充
批量归一化
使用 PyTorch 进行批量归一化
活动 4.03:实施批归一化
概括
本章解释了训练卷积神经网络( CNN ) 的过程——即发生在不同层中的计算(通常可以在 CNN 架构中找到)及其在训练过程中的目的。您将学习如何改进计算机视觉模型通过对模型应用数据增强和批量归一化来提高性能。到本章结束时,您将能够使用 CNN 使用 PyTorch 解决图像分类问题。这将是在计算机视觉领域实施其他解决方案的起点。
介绍
在上一章中,解释了最传统的神经网络架构并将其应用于现实生活中的数据问题。在本章中,我们将探讨 CNN 的不同概念,它们主要用于解决计算机视觉问题(即图像处理)。
尽管现在所有的神经网络领域都很流行,但 CNN 可能是所有神经网络架构中最受欢迎的。这主要是因为,虽然他们在许多领域工作,但他们特别擅长处理图像,而技术的进步使得可以收集和存储大量图像,这使得使用图像来应对当今各种各样的挑战成为可能。图像作为输入数据。
从图像分类到物体检测,CNN 正被用于诊断癌症患者和检测系统中的欺诈行为,以及构建将彻底改变未来的深思熟虑的自动驾驶车辆。
本章将重点解释 CNN 在处理图像时优于其他架构的原因,并更详细地解释其架构的构建块。它将涵盖构建 CNN 以解决图像分类数据问题的主要编码结构。
此外,我们将探讨数据扩充和批量归一化的概念,它们将用于提高模型的性能。本章的最终目标是比较三种不同方法的结果,以便使用 CNN 解决图像分类问题。
构建一个 CNN
CNN 是处理图像数据问题时的理想架构。然而,它们通常未被充分利用,因为它们通常用于图像分类任务,尽管它们的能力扩展到图像处理领域的其他领域。本章不仅会解释 CNN 如此擅长理解图像的原因,还会确定可以处理的不同任务,并提供一些实际应用示例。
此外,本章将探讨 CNN 的不同构建块及其使用 PyTorch 的应用,最终构建一个模型,使用 PyTorch 的一个数据集进行图像分类来解决数据问题。
为什么将 CNN 用于图像处理?
图像是像素矩阵,那么为什么不直接将矩阵展平为向量并使用传统的神经网络架构对其进行处理呢?答案是,即使是最简单的图像,也有一些像素相关性会改变图像的含义。例如,猫眼、汽车轮胎甚至物体边缘的表示都是由以特定方式布置的几个像素构成的。如果我们将图像展平,这些依赖关系就会丢失,传统模型的准确性也会丢失:
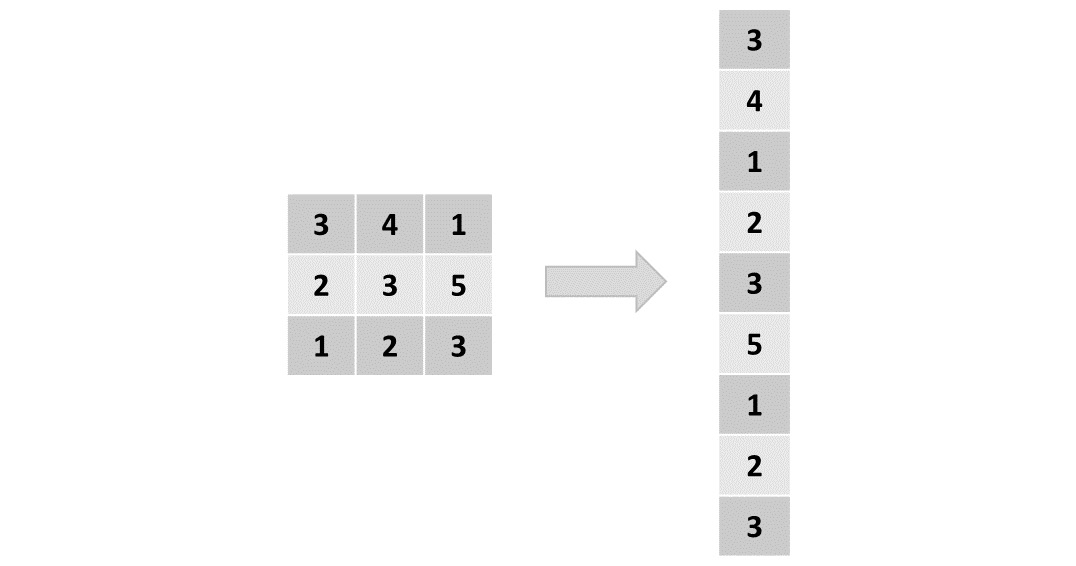
图 4.1:展平矩阵的表示
CNN 能够捕获图像的空间依赖性,因为它将图像作为矩阵进行处理,并根据过滤器的大小一次分析图像的整个块。例如,使用大小为 3 x 3 的过滤器的卷积层将一次分析 9 个像素,直到它覆盖整个图像。
图像的每个块都被赋予一组参数(权重和偏差),这些参数将参考该组像素与整个图像的相关性,具体取决于手头的过滤器。这意味着垂直边缘过滤器将为包含垂直边缘的图像块分配更大的权重。据此,通过减少参数数量和分块分析图像,CNN 能够更好地呈现图像。
图像作为输入
正如我们之前提到的,CNN 的典型输入是矩阵形式的图像。矩阵的每个值代表图像中的一个像素,其中数字由颜色的强度决定,取值范围为 0 到 255。
在灰度图像中,白色像素由数字 255 表示,黑色像素由数字 0 表示。灰色像素是介于两者之间的任何数字,具体取决于颜色的强度;灰色越浅,数字越接近 255。
彩色图像通常使用 RGB 系统表示,该系统将每种颜色表示为红色、绿色和蓝色的组合。在这里,每个像素将具有三个维度,每个维度对应一种颜色。每个维度的值都在 0 到 255 之间。这里,颜色越深,数字越接近 255。
根据前一段,给定图像的矩阵是三维的。这里,第一维是指图像的高度(以像素为单位),第二维是指图像的宽度(以像素为单位),第三维称为通道,指的是图像的配色方案。
彩色图像的通道数为三个(RGB 系统中每种颜色一个通道)。另一方面,灰度图像只有一个通道:

图 4.2:图像的矩阵表示——左边是彩色图像;右边是灰度图像
与文本数据相比,输入 CNN 的图像不需要太多预处理。图像通常按原样提供,最常见的变化如下:
- 归一化像素值以加快学习过程并提高性能
- 缩小图像尺寸(即减小宽度和长度)以加快学习过程
标准化输入的最简单方法是取每个像素的值并将其除以 255,这样我们最终得到的值介于 0 和 1 之间。然而,不同的方法用于标准化图像,例如均值居中技术. 在大多数情况下,选择一个或另一个的决定是一个偏好问题;但是,在使用预训练模型时,强烈建议您使用与第一次训练模型相同的技术。此信息通常可在预训练模型的文档中找到。
CNN 的应用
尽管 CNN 主要用于计算机视觉问题,但重要的是要提到它们解决其他学习问题的能力,主要是关于分析数据序列。例如,已知 CNN 在文本、音频和视频序列上表现良好,有时与其他网络架构相结合,或者将序列转换为 CNN 可以处理的图像。使用具有数据序列的 CNN 可以解决的一些特定数据问题包括文本的机器翻译、自然语言处理和视频帧标记等。
CNN 可以执行适用于所有监督学习问题的不同任务;但是,本章将重点介绍计算机视觉。以下是对每项任务的简要说明,以及每项任务的真实示例。
分类
这是计算机视觉中最常见的任务。主要思想是将图像的一般内容分类为一组类别,称为标签。
例如,分类可以确定图像是狗、猫还是任何其他动物。这种分类是通过输出图像属于每个类的概率来完成的,如下图所示:

图 4.3:分类任务
本地化
定位的主要目的是生成一个边界框来描述物体在图像中的位置。输出由类标签和边界框组成。
此任务可用于传感器以确定对象是在屏幕的左侧还是右侧:

图 4.4:本地化任务
检测
此任务包括对图像中的所有对象执行对象定位。输出由多个边界框以及多个类标签(每个框一个)组成。
此任务用于构建自动驾驶汽车,目的是能够定位交通标志、道路、其他汽车、行人以及可能与确保安全驾驶体验相关的任何其他对象:

图 4.5:检测任务
分割
这里的任务是输出图像中存在的每个对象的类标签和轮廓。这主要用于标记图像的重要对象以供进一步分析。
例如,该任务可用于严格界定患者肺部图像中肿瘤对应的区域。下图描述了如何勾勒出感兴趣的对象并为其分配标签:

图 4.6:分割任务
从本节开始,本章将重点介绍如何使用 PyTorch 的图像数据集训练模型来执行图像分类。
CNN 的构建模块
深度卷积网络是一种将图像作为输入并通过一系列具有过滤器、池化层和完全连接( FC ) 层的卷积层以最终应用softmax激活函数将图像分类为类标签的网络。与 ANN 一样,这种形式的分类是通过为每个类标签指定一个介于 0 和 1 之间的值来计算图像属于每个类标签的概率来执行的。具有较高概率的类标签被选为该图像的最终预测。
下面是对每一层的详细解释,以及如何在 PyTorch 中定义这些层的代码示例。
卷积层
这是从图像中提取特征的第一步。目标是通过学习图像小部分的特征来维持附近像素之间的关系。
数学运算发生在这一层,其中给出了两个输入(图像和过滤器)并获得了一个输出。正如我们之前解释的,此操作包括卷积滤波器和与滤波器大小相同的图像部分。对图像的所有子部分重复此操作。
笔记
重新访问第 2 章神经网络的构建块的CNN 简介部分,以提醒在输入和过滤器之间执行的精确计算。
生成的矩阵的形状取决于输入的形状,其中大小为 ( h x w x c ) 的图像矩阵和大小为( f h x f w x c )的滤波器将根据以下等式:
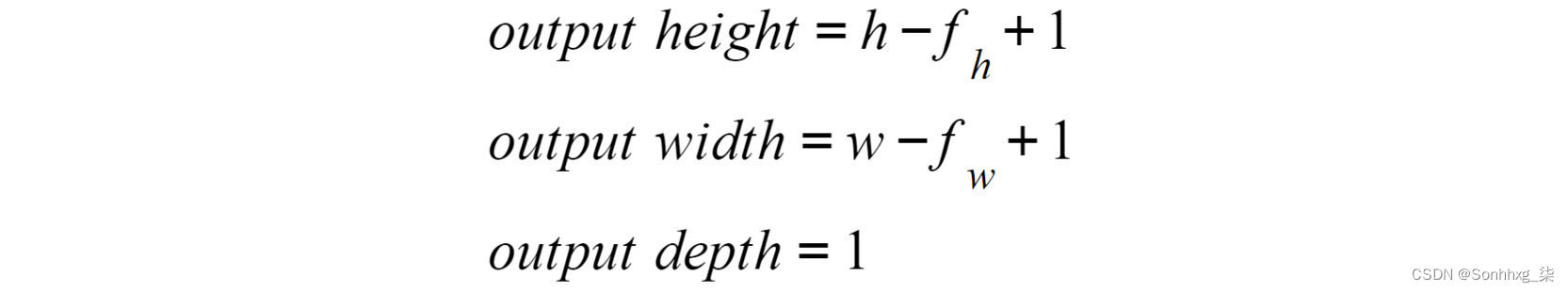
图 4.7:卷积层的输出高度、宽度和深度
这里,h是指输入图像的高度,w是宽度,c是深度(也称为通道),fh和fw是用户设置的关于滤波器大小的值。
下图以矩阵的形式描述了这种维度转换,其中左边的矩阵代表彩色图像,中间的矩阵代表应用于图像所有通道的单个过滤器,矩阵到右边是图像和过滤器计算的输出:

图 4.8:输入、过滤器和输出的尺寸
值得一提的是,在单个卷积层中,可以将多个滤波器应用于同一图像,且形状相同。考虑到这一点,将两个过滤器应用于其输入的卷积层的输出形状,就其深度而言,等于二,如下图所示:
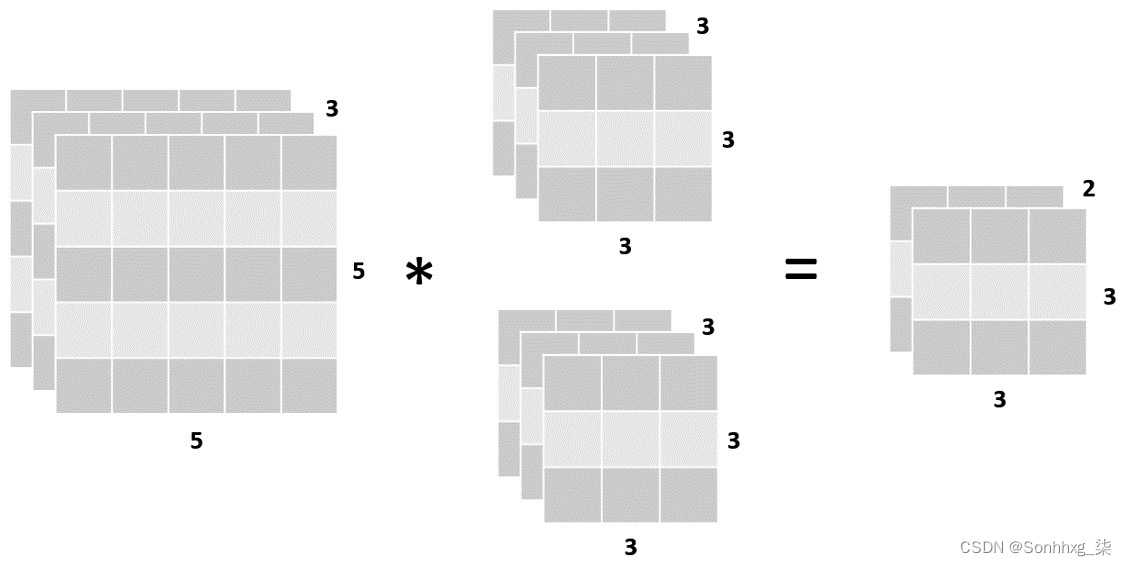
图 4.9:具有两个过滤器的卷积层
这些过滤器中的每一个都会执行不同的操作,以发现图像的不同特征。例如,在具有两个过滤器的单个卷积层中,这些操作可以是垂直边缘检测和水平边缘检测。随着网络层数的增加,过滤器将执行更复杂的操作,这些操作会利用先前检测到的特征——例如,通过使用边缘检测器的输入来检测人的轮廓。
过滤器通常在每一层中增加。这意味着,虽然第一个卷积层有 8 个滤波器,但通常创建第二个卷积层使其具有两倍的数量 (16),第三个使其再次具有两倍的数量 (32),依此类推.
然而,重要的是要提到,在 PyTorch 中,与在许多其他框架中一样,您应该只定义要使用的过滤器数量,而不是过滤器的类型(例如,垂直边缘检测器)。每个过滤器配置(它包含的用于检测特定特征的数字)都是系统变量的一部分。
卷积层的主题还有两个额外的概念要介绍,如下。
填充
顾名思义,填充参数用零填充图像。这意味着它向图像的每一侧添加额外的像素(用零填充)。
下图显示了每边都填充了一个图像的示例:

图 4.10:用一个填充的输入图像的图形表示
这用于在输入矩阵通过过滤器后保持输入矩阵的形状。这是因为,尤其是在前几层中,目标应该是尽可能多地保留原始输入中的信息,以便从中提取最多的特征。
为了更好地理解填充的概念,请考虑以下场景。
将 3 x 3 过滤器应用于形状为 32 x 32 x 3 的彩色图像将产生形状为 30 x 30 x 1 的矩阵。这意味着下一层的输入已缩小。但是,通过向输入图像添加 1 的填充,输入的形状变为 34 x 34 x 3,这导致使用相同过滤器的输出为 32 x 32 x 1。
使用填充时,可以使用以下等式计算输出宽度:
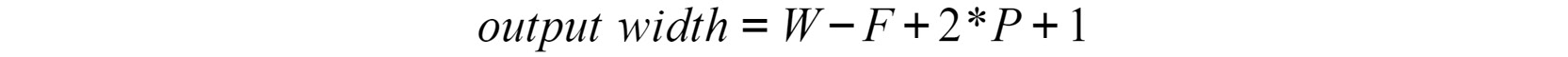
图 4.11:使用填充应用卷积层后的输出宽度
这里,W指的是输入矩阵的宽度,F指的是滤波器的宽度,P指的是padding。可以采用相同的等式来计算输出的高度。
要获得与输入形状相同的输出矩阵,请使用以下等式计算填充值(考虑到我们将在下一节中定义的步幅等于 1):
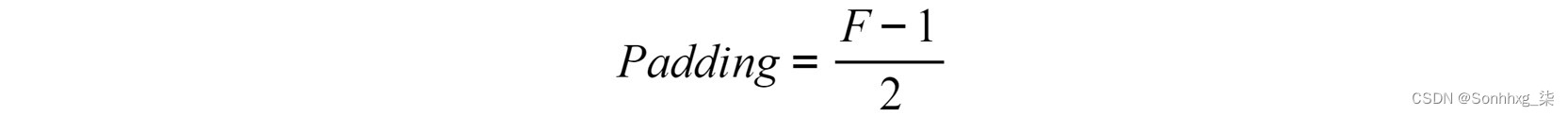
图 4.12:填充数字以获得与输入形状相同的输出矩阵
请记住,输出通道的数量(深度)将始终等于已应用于输入的过滤器数量。
步幅
此参数指的是过滤器将在输入矩阵上水平和垂直移动的像素数。正如我们目前所见,过滤器通过图像的左上角,然后向右移动一个像素,依此类推,直到它在垂直和水平方向上通过图像的所有部分。这个例子是一个步长等于 1 的卷积层,这是这个参数的默认配置。
当步幅等于 2 时,位移将是两个像素,如下图所示:
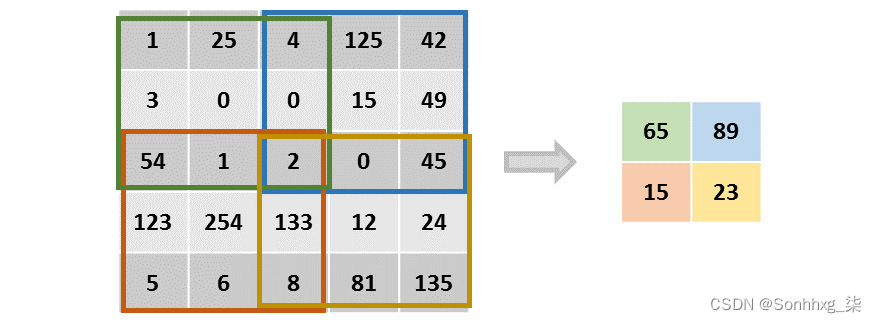
图 4.13:步长为 2 的卷积层的图形表示
可以看出,初始操作发生在左上角;然后,通过向右移动两个像素,第二次计算发生在右上角。接下来,计算向下移动两个像素以在左下角执行计算,最后,通过再次向右移动两个像素,最终计算发生在右下角。
笔记
图 4.12中的数字是编造的,并非实际计算。重点应该放在方框上,这些方框解释了步幅等于 2 时的换档过程。
使用步幅时,可以使用以下等式来计算输出宽度:
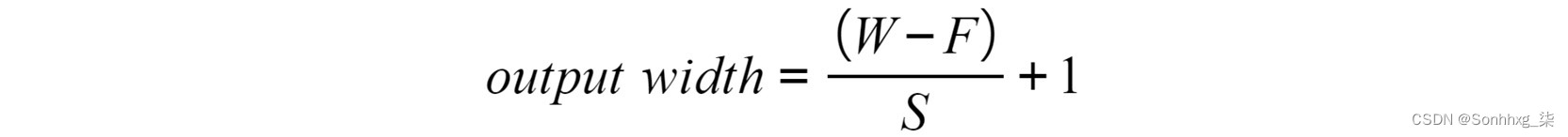
图 4.14:使用步幅的卷积层的输出宽度
这里,W指的是输入矩阵的宽度,F指的是滤波器的宽度,S指的是步幅。可以采用相同的等式来计算输出的高度。
引入这些参数后,计算从卷积层导出的矩阵的输出形状(宽度和高度)的最终方程如下:
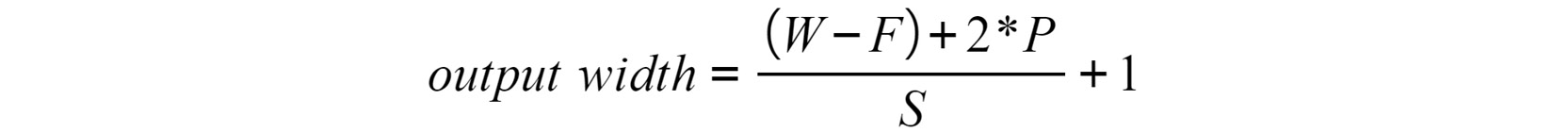
图 4.15:使用填充和步幅的卷积层后的输出宽度
只要值为float,就应该向下舍入。这基本上意味着忽略了输入的某些区域,并且没有从中提取任何特征。
最后,一旦输入通过所有过滤器,输出就会被馈送到激活函数以打破线性,类似于传统神经网络的过程。虽然有几个激活函数可以应用于此步骤,但首选的是 ReLU 函数,因为它在 CNN 中显示出出色的结果。我们在这里获得的输出成为后续层的输入,通常是池化层。
练习 4.01:计算卷积层的输出形状
使用给定的方程式,考虑以下情况并计算输出矩阵的形状:
笔记
本练习不需要编码,而是包含基于我们之前提到的概念的计算。
- 计算从卷积层导出的矩阵的输出形状,输入形状为 64 x 64 x 3,过滤器形状为 3 x 3 x 3:
Output height = 64 -3 + 1 = 62 Output width = 64 - 3 + 1 = 62 Output depth = 1 - 计算从卷积层导出的矩阵的输出形状,输入形状为 32 x 32 x 3,10 个形状为 5 x 5 x 3 的滤波器,填充为 2:
Output height = 32 - 5 + (2 * 2) + 1 = 32 Output width = 32-5 + (2 * 2) + 1 = 32 Output depth = 10 - 计算从卷积层导出的矩阵的输出形状,输入形状为 128 x 128 x 1,五个滤波器形状为 5 x 5 x 1,步幅为 3:
Output height = (128 - 5)/ 3 + 1 = 42 Output width = (128 - 5)/ 3 + 1 = 42 Output depth = 5 - 计算从卷积层导出的矩阵的输出形状,输入形状为 64 x 64 x 1,过滤器形状为 8 x 8 x 1,填充为 3,步幅为 3:
Output height = ((64 - 8 + (2 * 3)) / 3) +1 = 21.6 ≈ 21 Output width = ((64 - 8 + (2 * 3)) / 3) +1 = 21.6 ≈ 21 Output depth = 1
这样,您就成功计算了从卷积层导出的矩阵的输出形状。
在 PyTorch 中编写卷积层非常简单。使用自定义模块,只需要创建网络类。该类应包含定义网络架构(即网络层)的__init__方法和定义在信息通过层时要对其执行的计算的forward方法,如以下代码片段所示:
import torch.nn as nn
import torch.nn.functional as F
class CNN_network(nn.Module):
def __init__(self):
super(CNN_network, self).__init__()
self.conv1 = nn.Conv2d(3, 18, 3, 1, 1)
def forward(self, x):
x = F.relu(self.conv1(x))
return x在定义卷积层时,从左到右传递的参数是指输入通道、输出通道(过滤器数量)、内核大小(过滤器大小)、步幅和填充。
前面的示例包含一个卷积层,该层具有三个输入通道、18 个滤波器,每个滤波器的大小为 3,步长和填充等于 1。
另一种有效的方法,等同于前面的示例,包括自定义模块的语法和Sequential容器的使用的组合,如以下代码片段所示:
import torch.nn as nn
class CNN_network(nn.Module):
def __init__(self):
super(CNN_network, self).__init__()
self.conv1 = nn.Sequential(nn.Conv2d(3, 18, 3, 1, 1), \
nn.ReLU())
def forward(self, x):
x = self.conv1(x)
return x在这里,层的定义发生在Sequential容器内。通常,一个容器包括一个卷积层、一个激活函数和一个池化层。一组新层包含在其下方的不同容器中。
在前面的示例中,卷积层和激活层都定义在Sequential容器中。因此,在前向方法中,不需要通过激活函数传递卷积层的输出,因为它已经使用容器进行了处理。
池化层
通常,池化层是特征选择步骤的最后一部分,这就是为什么池化层大多位于卷积层之后。正如我们在前面的章节中解释的那样,这个想法是从图像的子部分中提取最相关的信息。池化层的大小通常为二,步长等于它的大小。
池化层通常会将输入的高度和宽度减半。考虑到这一点很重要,因为为了让卷积层找到图像中的所有特征,需要使用多个过滤器,而且此操作的输出可能会变得太大,这意味着需要考虑很多参数。池化层旨在通过保留最相关的特征来减少网络中的参数数量。从图像的子部分中选择相关特征可以通过获取最大数量或对该区域中的数字进行平均来实现。
对于图像分类任务,最常见的是使用最大池化层而不是平均池化层。这是因为前者在保留最相关特征是关键的任务中表现出更好的结果,而后者已被证明在平滑图像等任务中效果更好。
要计算输出矩阵的形状,请使用以下等式:
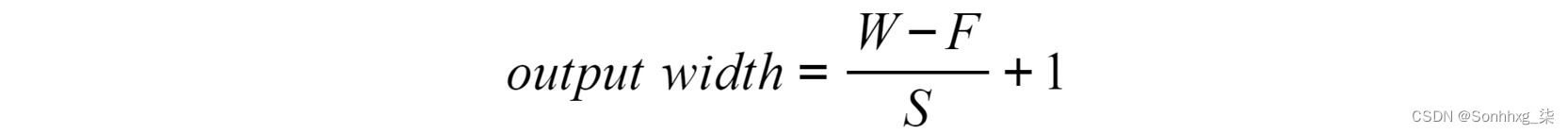
图 4.16:池化层后的输出矩阵宽度
这里,W指的是输入的宽度,F指的是过滤器的大小,S指的是步幅。可以采用相同的等式来计算输出高度。
输入的通道或深度保持不变,因为池化层将对图像的所有通道执行相同的操作。这意味着池化层的结果只会影响宽度和长度方面的输入。
练习 4.02:计算一组卷积层和池化层的输出形状
下面的练习将结合卷积层和池化层。目标是确定经过一组层后输出矩阵的大小。
笔记
本练习不需要编码,而是包含基于我们之前提到的概念的计算。
考虑以下几组层并在所有转换结束时指定输出层的形状,考虑大小为 256 x 256 x 3 的输入图像:
- 一个卷积层,有 16 个大小为 3 的过滤器,步长和填充为 1。
- 一个池化层,带有大小为 2 的过滤器和大小为 2 的步幅。
- 一个卷积层,有八个过滤器,大小为 7,步长为 1,填充为 3。
- 一个池化层,其过滤器大小为 2,步长也为 2。
经过每一层后矩阵的输出大小如下:
- 在第一个卷积层之后:
output_width/height = ((256 – 3) + 2 * 1)/1 + 1 = 256
output_channels = 应用了 16 个过滤器
output_matrix_size = 256 x 256 x 16
- 在第一个池化层之后:
output_width/height = (256 – 2) / 2 + 1 = 128
output_channels = 16 因为池化不影响通道数
output_matrix_size = 128 x 128 x 16
- 在第二个卷积层之后:
output_width/height = ((128 – 7) + 2 =* 3)/1 + 1 = 128
output_channels = 应用了 8 个过滤器
output_matrix_size = 128 x 128 x 8
- 在第二个池化层之后:
output_width/height = (128 – 2) / 2 + 1 = 64
output_channels = 8 因为池化不影响通道数
output_matrix_size = 64 x 64 x 8
这样,您就成功计算了从一系列卷积层和池化层导出的矩阵的输出形状。
使用与之前相同的编码示例,PyTorch 定义池化层的方式如以下代码片段所示:
import torch.nn as nn
import torch.nn.functional as F
class CNN_network(nn.Module):
def __init__(self):
super(CNN_network, self).__init__()
self.conv1 = nn.Conv2d(3, 18, 3, 1, 1)
self.pool1 = nn.MaxPool2d(2, 2)
def forward(self, x):
x = F.relu(self.conv1(x))
x = self.pool1(x)
return x可以看出,在__init__方法中向网络架构添加了一个池化层 ( MaxPool2d )。在这里,进入最大池化层的参数从左到右是过滤器的大小 ( 2 ) 和步幅 ( 2 )。接下来,更新前向方法以通过新的池化层传递信息。
同样,这里展示了一种同样有效的方法,使用自定义模块和顺序容器:
import torch.nn as nn
class CNN_network(nn.Module):
def __init__(self):
super(CNN_network, self).__init__()
self.conv1 = nn.Sequential(nn.Conv2d(3, 18, 3, 1, 1),\
nn.ReLU(),\
nn.MaxPool2d(2, 2))
def forward(self, x):
x = self.conv1(x)
return x正如我们之前提到的,池化层也包含在与卷积层相同的容器中,位于激活函数下方。后续的一组层(卷积层、激活层和池化层)将在下面定义,在一个新的Sequential容器中。
同样,forward方法不再需要单独调用每一层;相反,它通过包含层和激活函数的容器传递信息。
全连接层
在输入通过一组卷积层和池化层之后,在网络架构的末端定义一个或多个 FC 层。第一个 FC 层之前的层的输出数据从矩阵展平为向量,可以将其馈送到 FC 层(与传统神经网络的隐藏层相同)。
这些 FC 层的主要目的是考虑前面层检测到的所有特征,以便对图像进行分类。
不同的 FC 层通过一个激活函数传递,该函数通常是 ReLU 函数,除非它是最后一层,它将使用 softmax 函数输出输入属于每个类别标签的概率。
第一个 FC 层的输入大小对应于前一层的展平输出矩阵的大小。输出大小由用户定义,同样,与 ANN 一样,设置这个数字没有精确的科学依据。最后一个 FC 层的输出大小应等于类标签的数量。
要在 PyTorch 中定义一组 FC 层,请考虑以下代码片段:
class CNN_network(nn.Module):
def __init__(self):
super(CNN_network, self).__init__()
self.conv1 = nn.Conv2d(3, 18, 3, 1, 1)
self.pool1 = nn.MaxPool2d(2, 2)
self.linear1 = nn.Linear(32*32*16, 64)
self.linear2 = nn.Linear(64, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = self.pool1(x)
x = x.view(-1, 32 * 32 *16)
x = F.relu(self.linear1(x))
x = F.log_softmax(self.linear2(x), dim=1)
return x使用与上一节相同的编码示例,在__init__方法内将两个 FC 层添加到网络中。接下来,在forward函数内部,使用view()函数将池化层的输出展平。然后,它通过应用激活函数的第一个 FC 层。最后,数据连同其激活函数一起通过最后的 FC 层。
同样,使用与之前相同的编码示例,可以使用自定义模块和顺序容器向我们的模型添加 FC 层,如下所示:
import torch.nn as nn
class CNN_network(nn.Module):
def __init__(self):
super(CNN_network, self).__init__()
self.conv1 = nn.Sequential(nn.Conv2d(1, 16, 5, 1, 2,), \
nn.ReLU(), \
nn.MaxPool2d(2, 2))
self.linear1 = nn.Linear(32*32*16, 64)
self.linear2 = nn.Linear(64, 10)
def forward(self, x):
x = self.conv1(x)
x = x.view(-1, 32 * 32 *16)
x = F.relu(self.linear1(x))
x = F.log_softmax(self.linear2(x), dim=1)
return x可以看出,Sequential容器保持不变,在下面的__init__方法中添加了两个 FC 层。接下来,forward函数将信息传递到整个容器,然后将要传递给 FC 层的输出展平。
一旦定义了网络的架构,就可以按照与 ANN 相同的方式处理以下用于训练网络的步骤。
旁注——从 PyTorch 下载数据集
要从 PyTorch 加载数据集,请使用以下代码。除了下载数据集之外,以下代码还展示了如何使用数据加载器通过批量加载图像来节省资源,而不是一次全部加载:
from torchvision import datasets
import torchvision.transforms as transforms
transform = transforms.Compose([transforms.ToTensor(), \
transforms.Normalize((0.5, 0.5, 0.5), \
(0.5, 0.5, 0.5))])transform变量用于定义要对数据集执行的一组转换。在这种情况下,数据集将被转换为张量并在其所有维度上进行归一化。
train_data = datasets.MNIST(root='data', train=True,\
download=True, transform=transform)
test_data = datasets.MNIST(root='data', train=False,\
download=True, transform=transform)上述代码中,要下载的数据集为MNIST。这是一个流行的数据集,包含从 0 到 9 的手写灰度数字图像。PyTorch 数据集提供训练集和测试集。
从前面的代码片段可以看出,要下载数据集,必须定义数据的根,默认情况下,它应该定义为data。接下来,定义您是要下载训练数据集还是测试数据集。我们将下载参数设置为True。最后,我们使用之前定义的转换变量对数据集执行转换:
dev_size = 0.2
idx = list(range(len(train_data)))
np.random.shuffle(idx)
split_size = int(np.floor(dev_size * len(train_data)))
train_idx, dev_idx = idx[split_size:], idx[:split_size]考虑到我们需要第三组数据(验证集),前面的代码片段用于将训练集分成两组。首先,定义验证集的大小,然后定义将用于每个数据集的索引列表(训练集和验证集):
train_sampler = SubsetRandomSampler(train_idx)
dev_sampler = SubsetRandomSampler(dev_idx)在前面的代码片段中,PyTorch 的SubsetRandomSampler()函数用于通过随机采样索引将原始训练集划分为训练集和验证集。这将在以下步骤中用于生成将在每次迭代中输入模型的批次:
batch_size = 20
train_loader = torch.utils.data.DataLoader(train_data, \
batch_size=batch_size, \
sampler=train_sampler)
dev_loader = torch.utils.data.DataLoader(train_data, \
batch_size=batch_size, \
sampler=dev_sampler)
test_loader = torch.utils.data.DataLoader(test_data, \
batch_size=batch_size)DataLoader()函数用于为每组数据批量加载图像。首先,包含集合的变量作为参数传递,然后定义批量大小。最后,我们在上一步中创建的采样器用于确保每次迭代中使用的批次都是随机创建的,这有助于提高模型的性能。此函数的结果变量(train_loader、dev_loader和test_loader)将分别包含特征和目标的值。
笔记
问题越复杂,网络越深,模型训练所需的时间就越长。考虑到这一点,本章中的活动可能比前几章中的活动花费更长的时间。
活动 4.01:为图像分类问题构建 CNN
在此活动中,CNN 将在 PyTorch 的图像数据集上进行训练(即,框架提供数据集)。要使用的数据集是 CIFAR10,它包含总共 60,000 张车辆和动物图像。有 10 个不同的类别标签(例如“飞机”、“鸟”、“汽车”、“猫”等)。训练集包含 50,000 张图像,而测试集包含剩余的 10,000 张图像。
笔记
要进一步探索此数据集,请访问以下 URL:https ://www.cs.toronto.edu/~kriz/cifar.html 。
让我们来看看我们的场景。你在一家人工智能公司工作,该公司根据客户的需求开发定制模型。您的团队目前正在创建一个模型,可以区分车辆图片和动物图片,更具体地说,可以识别不同种类的动物和不同类型的车辆。他们为您提供了一个包含 60,000 张图像的数据集来构建模型。
笔记
本章的活动可能需要很长时间才能在普通计算机(在 CPU 上)上进行训练。要在 GPU 上运行代码,本书的 GitHub 存储库中的每个活动都有一个等效文件。
- 导入所需的库。
- 设置要对数据执行的转换,这将是将数据转换为张量和像素值的归一化。
- 设置 100 张图像的批量大小,并从CIFAR10数据集中下载训练和测试数据。
- 使用 20% 的验证大小,定义将用于将数据集划分为这两个集合的训练和验证采样器。
- 使用DataLoader()函数定义要用于每组数据的批次。
- 定义网络的架构。使用以下信息来执行此操作:
Conv1:一个卷积层,将彩色图像作为输入并通过 10 个大小为 3 的过滤器。填充和步幅都应设置为 1。
Conv2:一个卷积层,将输入数据通过 20 个大小为 3 的过滤器。padding 和 stride 都应设置为 1。
Conv3:一个卷积层,将输入数据通过 40 个大小为 3 的过滤器。padding 和 stride 都应设置为 1。
在每个卷积层之后使用 ReLU 激活函数。
每个卷积层之后的池化层,过滤器大小和步幅为 2。
压平图像后,dropout 项设置为 20%。
Linear1:一个全连接层,它接收来自前一层的展平矩阵作为输入,并生成 100 个单元的输出。对该层使用 ReLU 激活函数。此处,dropout 项设置为 20%。
Linear2:一个全连接层,生成 10 个输出,每个类标签一个。对输出层使用log_softmax激活函数。
- 定义训练模型所需的所有参数。将纪元数设置为 50。
- 训练您的网络并确保保存训练集和验证集的损失值和准确性值。
- 绘制两组的损失和准确性。
- 检查模型在测试集上的准确率——它应该在 72% 左右。
笔记
可以通过此链接找到此活动的解决方案。
由于数据在每个时期都被打乱,结果将无法完全重现。但是,您应该能够获得与本书中获得的结果相似的结果。
此代码可能需要一些时间才能运行,这就是本书的 GitHub 存储库中提供等效 GPU 版本解决方案的原因。
数据扩充
学习如何有效地编写神经网络代码是开发性能良好的解决方案所涉及的步骤之一。此外,要开发出色的深度学习解决方案,找到一个我们可以为当前挑战提供解决方案的兴趣领域至关重要。但是一旦所有这些都完成了,我们通常会面临同样的问题:通过自收集或从 Internet 和其他可用资源下载数据集来获得适当大小的数据集以从我们的模型中获得良好的性能。
正如您想象的那样,即使现在可以收集和存储大量数据,但由于相关成本,这并非易事。因此,大多数时候,我们都在处理包含数万个条目的数据集,而在涉及图像时则更少。
在为计算机视觉问题开发解决方案时,这成为一个相关问题,主要有两个原因:
- 数据集越大,结果越好,而更大的数据集对于获得足够好的模型至关重要。考虑到训练模型是调整一堆参数的问题,因此它能够映射输入和输出之间的关系,这是正确的。这是通过最小化损失函数使预测值尽可能接近真实值来实现的。在这里,模型越复杂,需要的参数就越多。
考虑到这一点,有必要向模型提供相当数量的示例,以便它能够找到这样的模式,其中训练示例的数量应与要调整的参数数量成正比。
- 计算机视觉问题中最大的挑战之一是让您的模型在图像的多个变体上表现良好。这意味着图像不需要按照特定的对齐方式或具有设定的质量来提供,而是可以以其原始格式提供,包括不同的位置、角度、照明和其他失真。因此,有必要找到一种方法来为模型提供此类变化。
因此,设计了数据增强技术。简单的说,就是通过对已有的例子稍加修改,来增加训练例子数量的一种措施。例如,您可以复制当前可用的实例并向这些副本添加一些噪音以确保它们不完全相同。
在计算机视觉问题中,这意味着通过改变现有图像来增加训练数据集中的图像数量,这可以通过稍微改变当前图像来创建略有不同的复制版本来完成。
这些对图像的微小调整可以采用轻微旋转、框架中对象位置的变化、水平或垂直翻转、不同的配色方案和扭曲等形式。这种技术之所以有效,是因为 CNN 会将这些图像中的每一个都视为不同的图像。
例如,下图显示了一只狗的三幅图像,虽然对于人眼来说是相同的图像但有某些变化,但对于神经网络来说是完全不同的:

图 4.17:增强图像
能够识别图像中的对象而不考虑变化的 CNN 被认为具有不变性。事实上,CNN 可以对每种类型的变化保持不变。
使用 PyTorch 进行数据扩充
使用torchvision包在 PyTorch 中执行数据扩充非常容易。这个包除了包含流行的数据集和模型架构外,还包含可以在数据集上执行的常见图像转换函数。
笔记
在本节中,将提及其中的一些图像变换。要获取可能转换的完整列表,请访问https://pytorch.org/docs/stable/torchvision/transforms.html。
与我们在上一个活动中使用的将数据集规范化并将其转换为张量的过程一样,执行数据扩充需要我们定义所需的转换,然后将它们应用于数据集,如以下代码片段所示:
transform = transforms.Compose([\
transforms.HorizontalFlip(probability_goes_here),\
transforms.RandomGrayscale(probability_goes_here),\
transforms.ToTensor(),\
transforms.Normalize((0.5, 0.5, 0.5), \
(0.5, 0.5, 0.5))])
train_data = datasets.CIFAR10('data', train=True, \
download=True, transform=transform)
test_data = datasets.CIFAR10('data', train=False, \
download=True, transform=transform)在这里,使用HorizontalFlip函数,要下载的数据将进行水平翻转(考虑一个概率值,该值由用户设置并确定将进行此转换的图像的百分比)。通过使用RandomGrayscale函数,图像将被转换为灰度(也考虑概率)。然后,将数据转换为张量并进行归一化。
考虑到模型是在迭代过程中训练的,其中训练数据被多次输入,这些转换确保第二次运行数据集不会将完全相同的图像输入模型。
此外,可以为不同的集合设置不同的变换。这很有用,因为数据扩充的目的是增加训练示例的数量,但用于测试模型的图像应该大部分保持不变。尽管如此,应该调整测试集的大小,以便将相同大小的图像提供给模型。
这可以通过以下方式完成:
transform = {"train": \
transforms.Compose([transforms.RandomHorizontalFlip\
(probability_goes_here),\
transforms.RandomGrayscale\
(probability_goes_here),\
transforms.ToTensor(),\
transforms.Normalize\
((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]), \
"test": transforms.Compose([transforms.ToTensor(),\
transforms.Normalize\
((0.5, 0.5, 0.5), \
(0.5, 0.5, 0.5)),\
transforms.Resize(size_goes_here)])}
train_data = datasets.CIFAR10('data', train=True, download=True, \
transform=transform["train"])
test_data = datasets.CIFAR10('data', train=False, download=True, \
transform=transform["test"])如我们所见,定义了一个字典,其中包含一组用于训练和测试集的转换。然后,可以调用字典以相应地将转换应用于每个集合。
活动 4.02:我实施数据扩充
在这个活动中,数据增强将被引入到我们在上一个活动中创建的模型中,以测试其准确性是否可以提高。让我们看看下面的场景。
您创建的模型很好,但其准确性未达到所需水平。您被要求考虑一种可以提高模型性能的方法。按照以下步骤完成此活动:
- 复制上一个活动中的笔记本。
- 更改转换变量的定义,使其除了将数据规范化和转换为张量外,还包括以下转换:
对于训练/验证集,概率为 50% (0.5) 的RandomHorizontalFlip函数和概率为 10% (0.1) 的 RandomGrayscale 函数。
对于测试集,不要添加任何其他转换。
- 训练模型 100 个时期。训练集和验证集的损失和准确性结果图应与此处显示的类似:
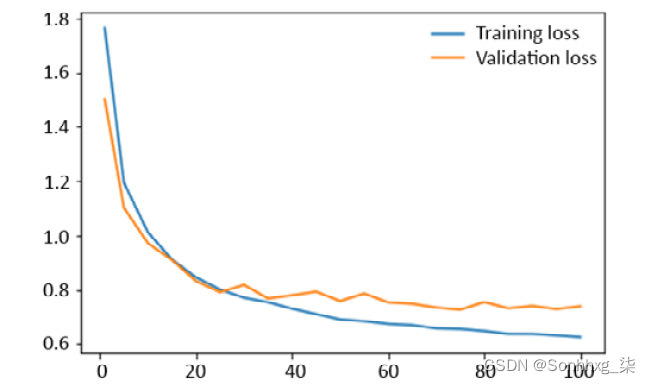
图 4.18:显示集合损失的结果图
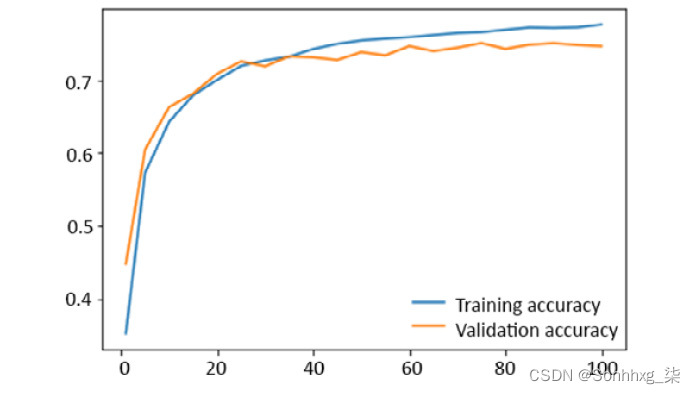
图 4.19:结果图显示了集合的准确性
笔记
由于每个时期的数据混洗,结果将无法完全重现。但是,您应该能够得到类似的结果。
- 计算所得模型在测试集上的准确率。
预期输出:模型在测试集上的性能应该在 75% 左右。
批量归一化
通常对输入层进行归一化以尝试加速学习,并通过将所有特征重新缩放到相同的比例来提高性能。那么,问题来了,如果模型受益于输入层的归一化,为什么不对所有隐藏层的输出进行归一化,以进一步提高训练速度呢?
批归一化,顾名思义,对隐藏层的输出进行归一化,以减少每一层的方差,也称为协方差偏移。这种协方差偏移的减少是有用的,因为它允许模型在遵循与用于训练它的图像不同分布的图像上也能很好地工作。
举个例子,一个网络的目的是检测动物是否是猫。当网络仅使用黑猫图像进行训练时,批量归一化可以帮助网络通过对数据进行归一化来对不同颜色的猫的新图像进行分类,从而使黑色和彩色猫图像都遵循相似的分布。此类问题如下图所示:

图 4.20:猫分类器——该模型可以识别有色猫,即使在仅使用黑猫进行训练后也是如此
此外,批量归一化为模型训练过程带来以下好处,最终帮助您获得性能更好的模型:
- 它允许设置更高的学习率,因为批归一化有助于确保没有任何输出太高或太低。更高的学习率相当于更快的学习时间。
- 它有助于减少过度拟合,因为它具有正则化效果。这使得可以将丢失概率设置为较低的值,这意味着在每次前向传递中忽略的信息较少。
笔记
我们不应该主要依靠批量归一化来处理过拟合。
正如我们在前几节中解释的那样,通过减去批均值并除以批标准差来对隐藏层的输出进行归一化。
此外,批量归一化通常在卷积层以及 FC 层(不包括输出层)上执行。
使用 PyTorch 进行批量归一化
在 PyTorch 中,添加批量归一化就像在网络架构中添加一个新层一样简单,考虑到有两种不同的类型,如下所述:
- BatchNorm1d:该层用于对二维或三维输入实现批量归一化。它接收来自上一层的输出节点数作为参数。这通常用于 FC 层。
- BatchNorm2d:这将批量归一化应用于四维输入。同样,它采用的参数是上一层的输出节点数。它通常用于卷积层,这意味着它接受的参数应该等于前一层的通道数。
据此,CNN中batch normalization的实现如下:
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(3, 16, 3, 1, 1)
self.norm1 = nn.BatchNorm2d(16)
self.pool = nn.MaxPool2d(2, 2)
self.linear1 = nn.Linear(16 * 16 * 16, 100)
self.norm2 = nn.BatchNorm1d(100)
self.linear2 = nn.Linear(100, 10)
def forward(self, x):
x = self.pool(self.norm1(F.relu(self.conv1(x))))
x = x.view(-1, 16 * 16 * 16)
x = self.norm2(F.relu(self.linear1(x)))
x = F.log_softmax(self.linear2(x), dim=1)
return x正如我们所见,批量归一化层最初的定义方式与__init__方法中的任何其他层类似。接下来,在forward方法中的激活函数之后,每个批归一化层都应用于其对应层的输出。
活动 4.03:实施批归一化
本次活动,我们将在之前活动的架构上进行batch normalization,看看能否进一步提升模型在测试集上的性能。让我们看看下面的场景。
您最近一次在绩效方面取得的进步给您的队友留下了深刻印象,现在他们对您的期望更高。他们要求你最后一次尝试改进模型,使准确率达到 80%。按照以下步骤完成此活动:
- 复制上一个活动中的笔记本。
- 向每个卷积层以及第一个 FC 层添加批量归一化。
- 训练模型 100 个时期。训练集和验证集的损失和准确性结果图应与此处显示的类似:

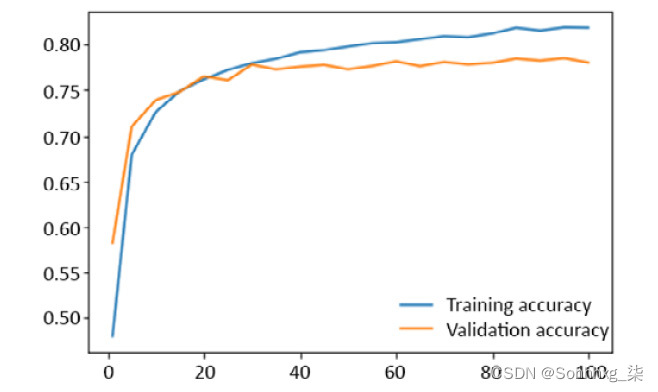
图 4.22:显示集合损失的结果图
- 计算所得模型在测试集上的准确率——它应该在 78% 左右。
笔记
可以通过此链接找到此活动的解决方案。
由于在每个 epoch 中对数据进行混洗,结果将无法完全重现。但是,您应该能够获得与本书中获得的结果相似的结果。
此代码可能需要一些时间才能运行,这就是本书的 GitHub 存储库中提供等效 GPU 版本解决方案的原因。
概括
本章重点介绍 CNN,它由一种在计算机视觉问题上表现出色的神经网络架构组成。我们首先解释了 CNN 广泛用于处理图像数据集的主要原因,并介绍了可以通过使用它们解决的不同任务。
本章通过解释卷积层、池化层以及最后的 FC 层的性质来解释网络架构的不同构建块。在每个部分中,都包含了对每一层的用途的解释,以及可用于在 PyTorch 中有效地对架构进行编码的代码片段。
这导致引入了一个图像分类问题,重点是对车辆和动物的图像进行分类。这个问题的目的是将 CNN 的不同构建块付诸实践,以解决图像分类数据问题。
接下来,引入数据增强作为一种工具,通过增加训练示例的数量来提高网络性能,而无需收集更多图像。该技术侧重于创建现有图像的变体,以创建“新”图像以提供给模型。
通过实施数据增强,本章的第二个活动旨在解决相同的图像分类问题,目的是比较结果。
最后,本章解释了batch normalization的概念。这包括规范化每个隐藏层的输出以加速学习。在解释了在 PyTorch 中应用批量归一化的过程之后,本章的最后一个活动旨在使用批量归一化解决相同的图像分类问题。
现在 CNN 的概念已经很清楚并且已经应用于解决计算机视觉问题,在下一章中,我们将探索 CNN 更复杂的应用来创建图像,而不仅仅是对它们进行分类。