提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 一、摘要
- 二、MobileNet-V1核心点介绍:普通卷积和深度可分离卷积
- 三、两个超参数
- 四。后续实验
前言
今天重温一下轻量化经典论文MobileNet-V1(V1指第一版本)
论文地址:https://arxiv.org/pdf/1704.04861v1.pdf
打算每天温习一个经典论文,看能坚持多久。
一、摘要
我们提出了一类名为mobilenet的高效模型,用于移动和嵌入式视觉应用程序。mobilenet基于一种流线型的架构,使用深度可分离卷积来构建轻量级的深度神经网络。我们引入了两个简单的全局超参数,可以有效地在延迟和准确性之间进行权衡。这些超参数允许模型构建者根据问题的约束为他们的应用程序选择合适大小的模型。我们在资源和准确性的权衡上进行了大量的实验,并在ImageNet分类中显示了与其他流行模型相比的强大性能。然后,我们在广泛的应用和用例中展示了mobilenet的有效性,包括对象检测、细粒度分类、人脸属性和大规模地理定位。
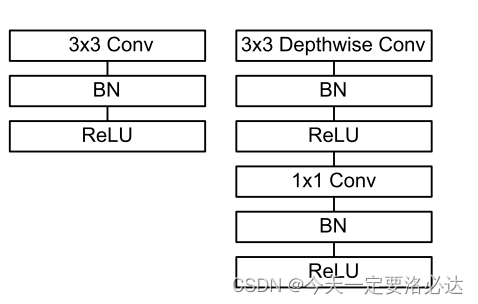
对,这个网络之所以能够减少计算量和参数量,就是多亏了这个深度可分离卷积depth-wise separable convolutions
二、MobileNet-V1核心点介绍:普通卷积和深度可分离卷积
首先看一下普通卷积的工作原理和计算量:
A standard convolutional layer takes as input a DF ×DF × M feature map F and produces a DF × DF × N feature map G where DF is the spatial width and height of a square input feature map1, M is the number of input channels (input depth), DG is the spatial width and height of a square output feature map and N is the number of output channel (output depth).
标准卷积层以DF × DF × M特征图F作为输入,得到DF × DF × N特征图G,其中DF为方形输入特征图map1的空间宽度和高度,M为输入通道数(输入深度),DG为正方形输出特征图的空间宽度和高度,N为输出通道数(输出深度)。
计算量是:

然后,深度可分离卷积的定义如下:
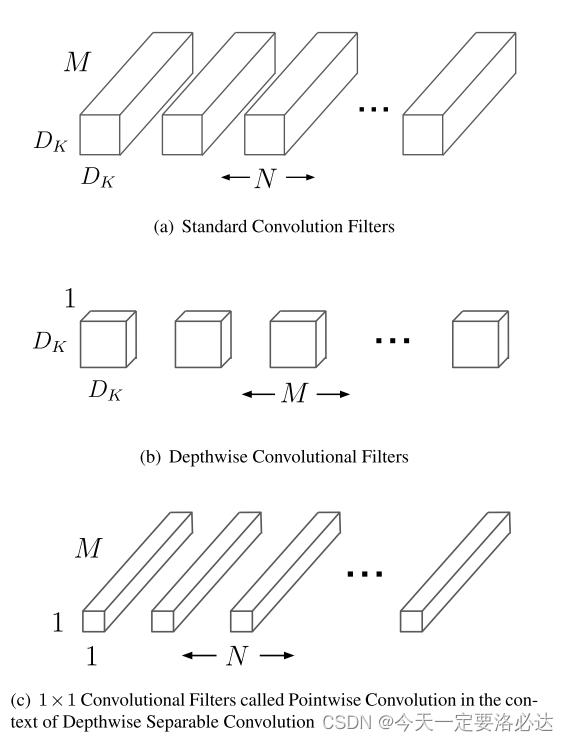
The MobileNet model is based on depthwise separable convolutions which is a form of factorized convolutions which factorize a standard convolution into a depthwise convolution and a 1×1 convolution called a pointwise con-volution.
深度可分卷积这是一种分解卷积的形式它将一个标准卷积分解为深度卷积和一个1×1卷积(点卷积)。
Depthwise separable convolution are made up of two layers: depthwise convolutions and pointwise convolutions. We use depthwise convolutions to apply a single filter per each input channel (input depth). Pointwise convolution, a simple 1×1 convolution, is then used to create a linear com- bination of the output of the depthwise layer. MobileNets= use both batchnorm and ReLU nonlinearities for both lay-ers.
深度可分离卷积由两层组成:深度卷积和点卷积。我们使用深度卷积来为每个输入通道(输入深度)应用一个过滤器。然后使用点态卷积(一个简单的1×1卷积)创建深度层输出的线性组合。mobilenet在这两层都使用批处理规范和ReLU非线性。
计算量是:

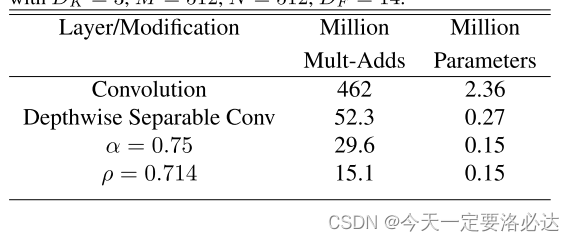
那么一和普通卷积对比就发现计算量少得多了:
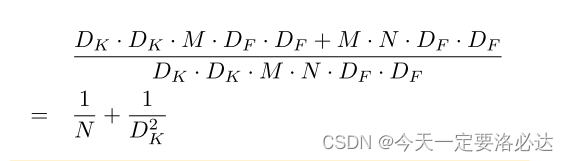
结论里写到:
MobileNet uses 3 × 3 depthwise separable convolutions which uses between 8 to 9 times less computation than stan- dard convolutions at only a small reduction in accuracy as seen in Section 4.
MobileNet使用3 × 3深度可分离卷积,它使用的计算量比标准卷积少8到9倍,仅在精度上有很小的降低,如第4节所示:
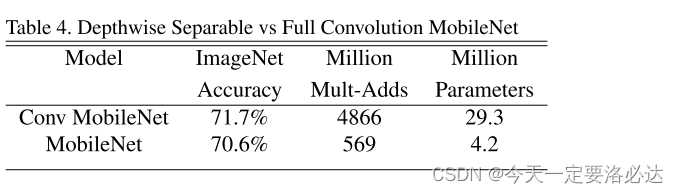
(Mult-Adds概念:在深度学习中,Mult-Adds是指乘加运算的数量,通常用于评估神经网络模型的计算量。Mult-Adds数量是基于模型的结构和参数进行计算的,它与模型的实际计算时间有关。Mult-Adds数量越多,模型的计算时间就越长。
在卷积神经网络(Convolutional Neural Network, CNN)中,Mult-Adds数量通常是卷积核大小、输入通道数、输出通道数、卷积层输出的宽度和高度等因素的函数:

三、两个超参数
第一个:Width Multiplier:(用来Thinner Models)
虽然基本的MobileNet架构已经很小,而且延迟很低,但很多时候,一个特定的用例或应用程序可能需要模型更小、更快。为了构造这些更小、计算成本更低的模型,我们引入了一个非常简单的参数α,称为宽度乘子。宽度乘子α的作用是在每一层均匀地细化网络。对于给定的图层和宽度乘子α时,输入通道数sm为α m,输出通道数N为αN。
第二个:Resolution Multiplier:(用来 Reduced Representation)
第二个降低神经网络计算成本的超参数是分辨率乘子ρ。我们将其铺到输入图像上,每一层的内部表示随后被相同的乘法器减少。在实践中,我们隐式地通过设置输入分辨率来设置ρ。
两个操作之后计算量变成了 这样:
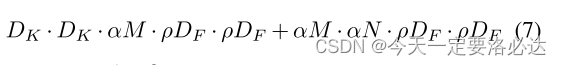
效果当然是不错的:可进一步减少数据量
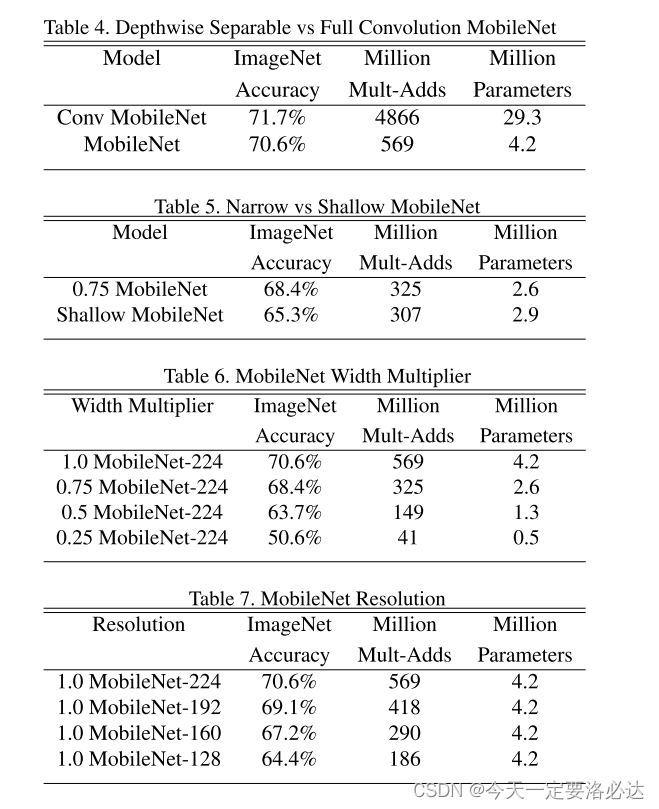
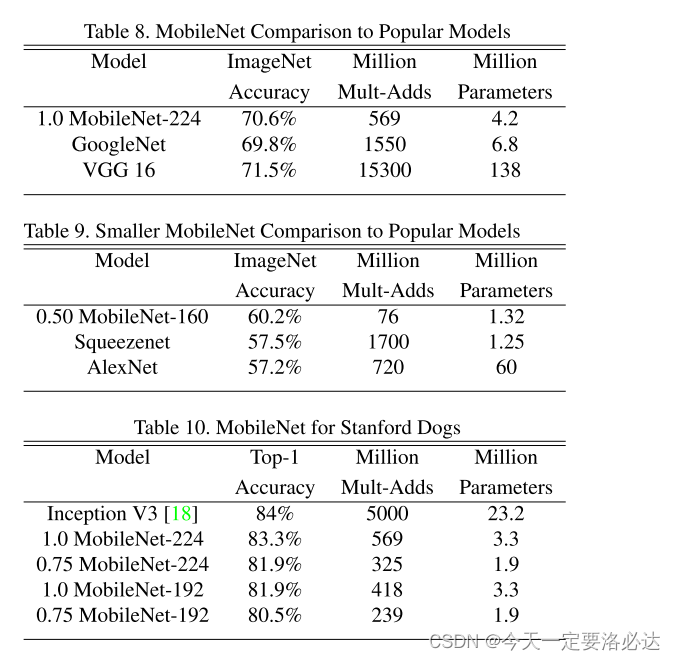
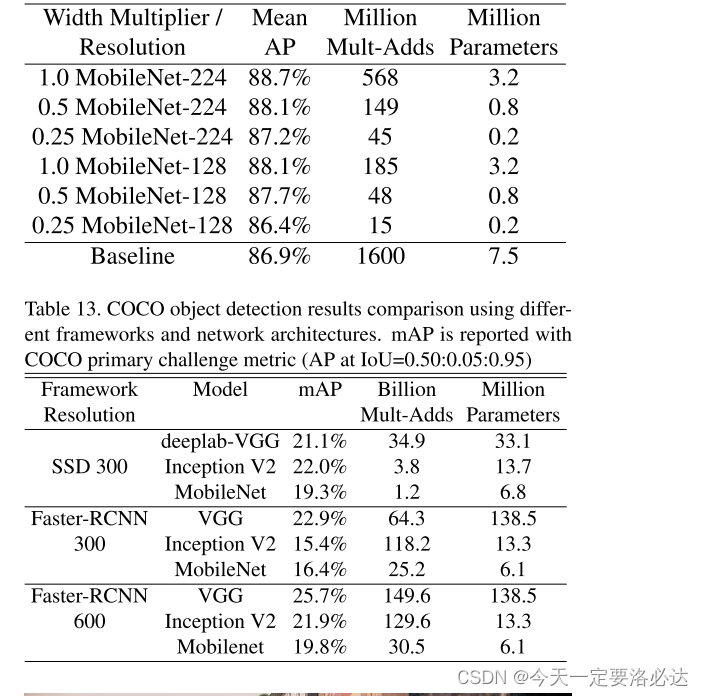
四。后续实验
后续在细粒度,人脸识别,目标检测上做了很多对比实验,下面是一些截图: