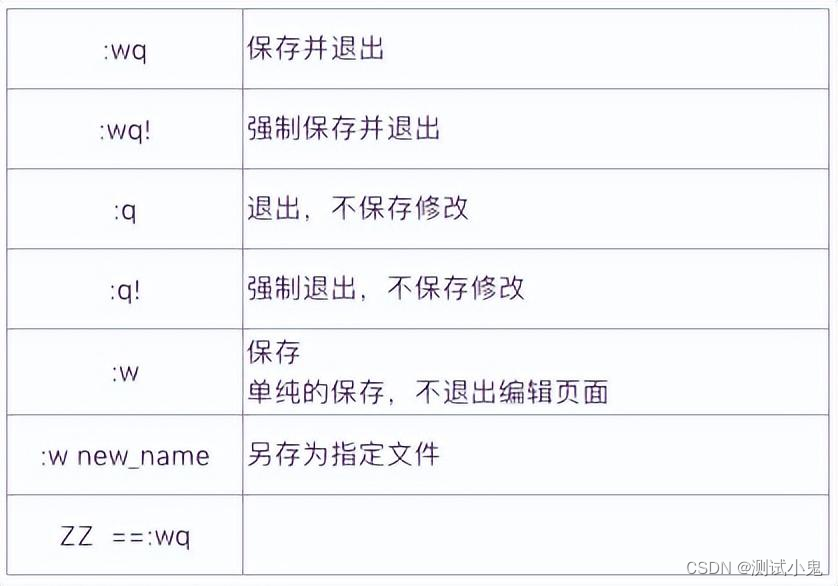
kitti数据集预处理
- 0.引言
- 0.1.calib
- 0.2.oxts(gps/imu)
- 0.3.velodyne
- 0.4.image_2/3
- 0.5.kitti-step/panoptics
- 0.6.label
- 1.create_kitti_depth_maps
- 2.create_kitti_masks
- 3.create_kitti_metadata
- 4.extract_dino_features
- 5.run_pca
0.引言
- 官网
- 参考链接1
- 参考链接2
注:velodyne_reduced为图像在三维空间内的视椎体的数据(训练使用)
└── KITTI_DATASET_ROOT
├── training <-- 7481 train data
| ├── image_2 <-- for visualization
| ├── calib <-- camera inner and outter parameters
| ├── label_2 <--label for trainning and evaluate
| ├── velodyne<--lidar data
| └── velodyne_reduced <-- empty directory,reduced by image size frustum
└── testing <-- 7518test data
├── image_2 <-- for visualization
├── calib
├── velodyne
└── velodyne_reduced <-- empty directory

传感器:
1惯性导航系统(GPS / IMU):OXTS RT 3003
1台激光雷达:Velodyne HDL-64E
2台灰度相机,1.4百万像素:Point Grey Flea 2(FL2-14S3M-C)
2个彩色摄像头,1.4百万像素:Point Grey Flea 2(FL2-14S3C-C)
4个变焦镜头,4-8毫米:Edmund Optics NT59-917
0.1.calib
calib文件是相机、雷达、惯导等传感器的矫正数据。
P0: 7.215377000000e+02 0.000000000000e+00 6.095593000000e+02 0.000000000000e+00 0.000000000000e+00 7.215377000000e+02 1.728540000000e+02 0.000000000000e+00 0.000000000000e+00 0.000000000000e+00 1.000000000000e+00 0.000000000000e+00
P1: 7.215377000000e+02 0.000000000000e+00 6.095593000000e+02 -3.875744000000e+02 0.000000000000e+00 7.215377000000e+02 1.728540000000e+02 0.000000000000e+00 0.000000000000e+00 0.000000000000e+00 1.000000000000e+00 0.000000000000e+00
P2: 7.215377000000e+02 0.000000000000e+00 6.095593000000e+02 4.485728000000e+01 0.000000000000e+00 7.215377000000e+02 1.728540000000e+02 2.163791000000e-01 0.000000000000e+00 0.000000000000e+00 1.000000000000e+00 2.745884000000e-03
P3: 7.215377000000e+02 0.000000000000e+00 6.095593000000e+02 -3.395242000000e+02 0.000000000000e+00 7.215377000000e+02 1.728540000000e+02 2.199936000000e+00 0.000000000000e+00 0.000000000000e+00 1.000000000000e+00 2.729905000000e-03
R_rect 9.999239000000e-01 9.837760000000e-03 -7.445048000000e-03 -9.869795000000e-03 9.999421000000e-01 -4.278459000000e-03 7.402527000000e-03 4.351614000000e-03 9.999631000000e-01
Tr_velo_cam 7.533745000000e-03 -9.999714000000e-01 -6.166020000000e-04 -4.069766000000e-03 1.480249000000e-02 7.280733000000e-04 -9.998902000000e-01 -7.631618000000e-02 9.998621000000e-01 7.523790000000e-03 1.480755000000e-02 -2.717806000000e-01
Tr_imu_velo 9.999976000000e-01 7.553071000000e-04 -2.035826000000e-03 -8.086759000000e-01 -7.854027000000e-04 9.998898000000e-01 -1.482298000000e-02 3.195559000000e-01 2.024406000000e-03 1.482454000000e-02 9.998881000000e-01 -7.997231000000e-01
P0、1、2、3分别代表左边灰度相机、右边灰度相机、左边彩色相机和右边彩色相机的投影矩阵。
P = K [ R , t ] = [ f x 0 c x 0 0 f y c y 0 0 0 1 0 ] [ r 11 r 12 r 13 t x r 21 r 22 r 23 t y r 31 r 32 r 33 t z 0 0 0 1 ] P=K[R ,t] =\begin{bmatrix} f_x & 0 & c_x & 0 \\ 0 & f_y & c_y & 0 \\ 0 & 0 & 1 & 0 \end{bmatrix} \begin{bmatrix} r_{11} & r_{12} & r_{13} & t_x \\ r_{21} & r_{22} & r_{23} & t_y \\ r_{31} & r_{32} & r_{33} & t_z \\ 0 & 0 & 0 & 1 \end{bmatrix} P=K[R,t]= fx000fy0cxcy1000 r11r21r310r12r22r320r13r23r330txtytz1
用于将世界坐标点转换为相机坐标,以及将相机坐标转换为像素坐标。
-
R_rect:为0号相机的修正矩阵,大小为3x3,目的是为了使4个相机成像达到共面的效果,保证4个相机光心在同一个xoy平面上。在进行外参矩阵变化之后,需要于R0_rect相乘得到相机坐标系下的坐标。
-
Tr_velo_cam:激光雷达与相机之间的外参矩阵,用于将激光雷达坐标系中的点转换为相机坐标系中的点.
T v e l o 2 c a m = [ R v e l o c a m t v e l o c a m 0 T 1 ] T_{velo2cam} = \begin{bmatrix} R^{cam}_{velo} & t^{cam}_{velo} \\ \mathbf{0}^T & 1 \end{bmatrix} Tvelo2cam=[Rvelocam0Ttvelocam1]
-
综上所述,点云坐标在相机坐标系中的坐标等于:
内参矩阵 * 外参矩阵 * R0校准矩阵 * 点云坐标, 即:P * R0_rect *Tr_velo_to_cam * x -
Tr_imu_velo:IMU与激光雷达之间的外参矩阵,用于将IMU测量值转换为激光雷达坐标系中的值。
1、将 Velodyne 坐标中的点 x 投影到左侧的彩色图像中 y,使用公式 y = P2 * R0_rect * Tr_velo_to_cam * x
2、将 Velodyne 坐标中的点 x 投影到右侧的彩色图像中 y,使用公式 y = P3 * R0_rect * Tr_velo_to_cam * x
3、将 Velodyne 坐标中的点 x 投影到编号为 0 的相机(参考相机)坐标系中,使用公式 R0_rect * Tr_velo_to_cam * x
4、将 Velodyne 坐标中的点 x 投影到编号为 0 的相机(参考相机)坐标系中,再投影到编号为 2 的相机(左彩色相机)的照片上,使用公式 P2 * R0_rect * Tr_velo_to_cam * x
0.2.oxts(gps/imu)
OXTS (GPS/IMU) 对于每一帧,我们将 30 个不同的 GPS/IMU 值存储在一个文本文件中:地理坐标,包括高度、全球方向、速度、加速度、角速率、精度和卫星信息。加速度和角速率均使用两个坐标系指定,一个附加到车身 (x, y, z),另一个映射到该位置的地球表面的切平面 (f, l, u) .我们有时会遇到与 OXTS 设备的短暂(约 1 秒)通信中断,为此我们对所有值进行线性插值并将最后 3 个条目设置为“-1”以指示丢失的信息。 dataformat.txt 中提供了更多详细信息。开发工具包中提供了转换实用程序。
49.015003823272 8.4342971002335 116.43032836914 0.035752 0.00903 -2.6087069803847 -6.811441479104 -11.275641809511 13.172716663769 -0.12475264293164 -0.032919903047354 -0.44519814607457 0.042957369847256 10.209865300506 -0.34030092211055 -0.31686915378551 10.209117821189 0.0090951755733632 -0.023140741253985 -0.017909034508194 0.0089018002187228 -0.022495299354602 -0.018809330937153 0.027658633371879 0.012727922061358 4 11 6 6 6
- 参考

其中,每个字段的含义如下:
lat:纬度,单位为度
lon:经度,单位为度
alt:海拔高度,单位为米
Roll:横滚角,单位为弧度
Pitch:俯仰角,单位为弧度
Yaw:偏航角,单位为弧度
vn:北向速度,单位为米/秒
ve:东向速度,单位为米/秒
vf:车体前向速度,单位为米/秒
vl:车体横向速度,单位为米/秒
vu:车体垂直速度,单位为米/秒
ax:X轴方向加速度,单位为米/秒^2
ay:Y轴方向加速度,单位为米/秒^2
az:Z轴方向加速度,单位为米/秒^2
af:前向加速度,单位为米/秒^2
al:横向加速度,单位为米/秒^2
au:垂直加速度,单位为米/秒^2
wx:X轴方向角速度,单位为弧度/秒
wy:Y轴方向角速度,单位为弧度/秒
wz:Z轴方向角速度,单位为弧度/秒
wf:前向角速度,单位为弧度/秒
wl:横向角速度,单位为弧度/秒
wu:垂直角速度,单位为弧度/秒
pos_accuracy:GPS位置精度,单位为米
vel_accuracy:GPS速度精度,单位为米/秒
navstat:GPS状态,0代表无效,1代表GPS解算成功
numsats:使用的GPS卫星数
posmode:GPS定位模式,如下所示:
0:没有GPS定位
1:单点定位(SPS)
2:差分GPS定位(DGPS)
3:精密GPS定位(PPS)
4:实时动态差分GPS定位(Real Time Kinematic,RTK)
5:浮点解(Float RTK)
6:估算定位
7:手动输入定位
8:模拟定位
velmode:GPS速度模式,如下所示:
0:没有GPS速度
1:仅使用GPS速度测量
2:仅使用IMU速度测量
3:GPS和IMU速度融合
orimode:GPS姿态模式,如下所示:
0:没有GPS姿态
1:仅使用GPS姿态测量
2:仅使用IMU姿态测量
3:GPS和IMU姿态融合
0.3.velodyne
Velodyne 为了提高效率,Velodyne 扫描存储为浮点二进制文件,点云数据以浮点二进制文件格式存储,每行包含8个数据,每个数据由四位十六进制数表示(浮点数),每个数据通过空格隔开。一个点云数据由四个浮点数数据构成,分别表示点云的x、y、z、r(强度 or 反射值)。虽然每次扫描的点数不是恒定的,但平均每个文件/帧的大小约为 1.9 MB,对应于 120,000 个 3D 点和反射率值。请注意,Velodyne 激光扫描仪围绕其垂直轴连续旋转(逆时针),可以使用时间戳文件将其考虑在内。
每个velodyne文件包含了一个完整的激光雷达扫描周期内采集到的所有点的坐标和反射强度值,数据的存储格式如下:
float x; // 点的x坐标,单位为米
float y; // 点的y坐标,单位为米
float z; // 点的z坐标,单位为米
float intensity;// 反射强度值,无单位
每个点占据16个字节,分别表示点的x、y、z坐标和反射强度值,数据类型都是浮点数形式,其中:
- x、y、z分别表示点在三维空间中的坐标,单位为米。它们的数据类型是float,通常采用IEEE 754浮点数格式表示。
- intensity表示点的反射强度值,是一个无符号整数。它的取值范围通常是0~255,取值越大表示反射强度越强。反射强度值并不是Velodyne激光雷达所测量到的真实物理量,而是一种近似反映激光束与目标之间反射关系的量。
0.4.image_2/3
image文件以8位PNG格式存储.
0.5.kitti-step/panoptics
STEP 全称 The Segmenting and Tracking Every Pixel benchmark, 包括 21 个训练序列和 29 个测试序列。该数据集基于 KITTI Tracking Evaluation 和 Multi-Object Tracking and Segmentation (MOTS) 基准。
该数据集为每个像素添加了密集的像素分割标记。在这个基准中,每个像素都有一个语义标签,所有属于最显著对象类别(汽车和行人)的像素都有一个唯一的跟踪 ID 。
- 参考论文

0.6.label
对于参考相机视野内的每个动态对象,我们以 3D 边界框轨迹的形式提供注释,以 Velodyne 坐标表示。我们定义了“汽车”、“货车”、“卡车”、“行人”、“人(坐着的)”、“骑自行车的人”、“电车”和“杂项”(例如,拖车、赛格威)的类。 tracklets 存储在 date_drive_tracklets.xml 中。每个对象都分配有一个类及其 3D 大小(高度、宽度、长度)。对于每一帧,我们提供对象的 3D 平移和旋转,如图所示。请注意,我们仅提供偏航角,而其他两个角度均假定为接近于零。此外,指定了遮挡和截断的级别。

Object coordinates. 对象坐标。此图说明了带注释的 3D 边界框相对于 3D Velodyne 激光扫描仪坐标系的坐标系。在z方向,物体坐标系位于物体的底部(与支撑面的接触点)。
以某个label文件为例:
Truck 0.00 0 -1.57 599.41 156.40 629.75 189.25 2.85 2.63 12.34 0.47 1.49 69.44 -1.56
Car 0.00 0 1.85 387.63 181.54 423.81 203.12 1.67 1.87 3.69 -16.53 2.39 58.49 1.57
Cyclist 0.00 3 -1.65 676.60 163.95 688.98 193.93 1.86 0.60 2.02 4.59 1.32 45.84 -1.55
DontCare -1 -1 -10 503.89 169.71 590.61 190.13 -1 -1 -1 -1000 -1000 -1000 -10
DontCare -1 -1 -10 511.35 174.96 527.81 187.45 -1 -1 -1 -1000 -1000 -1000 -10
DontCare -1 -1 -10 532.37 176.35 542.68 185.27 -1 -1 -1 -1000 -1000 -1000 -10
DontCare -1 -1 -10 559.62 175.83 575.40 183.15 -1 -1 -1 -1000 -1000 -1000 -10
以 Car 为例:
| label.txt | Car | 0.00 | 0 | 1.85 | 387.63 181.54 | 423.81 203.12 | 1.67 1.87 3.69 | -16.53 2.39 58.49 | 1.57 |
|---|---|---|---|---|---|---|---|---|---|
| 说明 | 类别 | truncated(截断程度), 0.00表示无截断 | occluded(遮挡率), 0表示无遮挡 | alpha([-pi, pi]) 观察角度 | 2D Bounding Box(BB) 左上角的坐标 | 2D BB 右下角的坐标 | 3D BB的height, width, length | 3D BB 位置在camera相机的坐标 | 置信度,用来绘制p/r曲线,越高越好 |
DontCare 划分出了不感兴趣的区域,区域内的物体不会被label。
每一行代表一个object,每一行都有16列分别表示不同的含义,具体如下:
- 第1列(字符串):代表物体类别(type)
总共有9类,分别是:Car、Van、Truck、Pedestrian、Person_sitting、Cyclist、Tram、Misc、DontCare。
其中DontCare标签表示该区域没有被标注,比如由于目标物体距离激光雷达太远。为了防止在评估过程中(主要是计算precision),将本来是目标物体但是因为某些原因而没有标注的区域统计为假阳性(false positives),评估脚本会自动忽略DontCare区域的预测结果。
- 第2列(浮点数):代表物体是否被截断(truncated)
数值在0(非截断)到1(截断)之间浮动,数字表示指离开图像边界对象的程度。
- 第3列(整数):代表物体是否被遮挡(occluded)
整数0、1、2、3分别表示被遮挡的程度。
- 第4列(弧度数):物体的观察角度(alpha)
取值范围为:-pi ~ pi(单位:rad),它表示在相机坐标系下,以相机原点为中心,相机原点到物体中心的连线为半径,将物体绕相机y轴旋转至相机z轴,此时物体方向与相机x轴的夹角(如下图所示,y轴垂直与屏幕)
- 第5~8列(浮点数):物体的2D边界框大小(bbox)
四个数分别是xmin、ymin、xmax、ymax(单位:pixel),表示2维边界框的左上角和右下角的坐标。
- 第9~11列(浮点数):3D物体的尺寸(dimensions)
分别是高、宽、长(单位:米)
- 第12-14列(浮点数):3D物体的位置(location)
分别是x、y、z(单位:米),特别注意的是,这里的xyz是在相机坐标系下3D物体的中心点位置。
- 第15列(弧度数):3D物体的空间方向(rotation_y)
取值范围为:-pi ~ pi(单位:rad),它表示,在照相机坐标系下,物体的全局方向角(物体前进方向与相机坐标系x轴的夹角),如下图所示。
- 第16列(浮点数):检测的置信度(score)
在这里插入图片描述
- 参考链接
1.create_kitti_depth_maps
利用 image 图片以及 lidar 数据获取深度信息。将KITTI数据集中的Velodyne点云投影到图像上,并生成深度图。具体实现过程如下:
-
1.读取KITTI数据集中的P矩阵,
R_rect矩阵和Tr_velo_cam矩阵,其中P矩阵是相机投影矩阵,R_rect矩阵是相机的畸变校正矩阵,Tr_velo_cam矩阵是Velodyne点云到相机坐标系的变换矩阵。 -
2.读取KITTI数据集中的oxts文件,包含了每个时刻的GPS位置、速度、姿态等信息。
-
3.对于每一帧图像,读取对应的Velodyne点云,将Velodyne点云从Velodyne坐标系转换到相机坐标系。
-
4.根据P矩阵将点云投影到图像上,并根据投影结果生成深度图。
-
5.将深度图写入到Parquet文件中。
Velodyne点云到相机坐标系的变换矩阵公式:
T
v
e
l
o
2
c
a
m
=
[
R
r
e
c
t
0
3
×
1
0
1
×
3
1
]
⋅
[
R
v
e
l
o
2
c
a
m
T
v
e
l
o
2
c
a
m
0
1
×
3
1
]
T_{velo2cam}=\begin{bmatrix}R_{rect} & 0_{3\times 1} \\ 0_{1\times 3} & 1 \end{bmatrix}\cdot\begin{bmatrix}R_{velo2cam} & T_{velo2cam} \\ 0_{1\times 3} & 1 \end{bmatrix}
Tvelo2cam=[Rrect01×303×11]⋅[Rvelo2cam01×3Tvelo2cam1]
将点云投影到图像上的公式:
[
u
v
1
]
=
[
P
1
,
1
P
1
,
2
P
1
,
3
P
1
,
4
P
2
,
1
P
2
,
2
P
2
,
3
P
2
,
4
P
3
,
1
P
3
,
2
P
3
,
3
P
3
,
4
]
⋅
[
X
Y
Z
1
]
\begin{bmatrix}u\\v\\1\end{bmatrix}=\begin{bmatrix}P_{1,1}&P_{1,2}&P_{1,3}&P_{1,4}\\P_{2,1}&P_{2,2}&P_{2,3}&P_{2,4}\\P_{3,1}&P_{3,2}&P_{3,3}&P_{3,4}\end{bmatrix}\cdot \begin{bmatrix}X\\Y\\Z\\1\end{bmatrix}
uv1
=
P1,1P2,1P3,1P1,2P2,2P3,2P1,3P2,3P3,3P1,4P2,4P3,4
⋅
XYZ1
在生成深度图时使用了scatter_min 函数对点云的深度值进行聚合,scatter_min 函数的公式如下:
y
i
=
min
j
∈
{
j
∣
i
n
d
e
x
j
=
i
}
(
x
j
)
y_i=\text{min}_{j\in\{j|index_j=i\}}(x_j)
yi=minj∈{j∣indexj=i}(xj)
其中, x x x 是输入的张量, y y y 是输出的张量, i n d e x index index 是用于聚合的索引。
- 参数:

- 相机标定文件:

- 读取图像、lidar等数据:

- 利用lider点云求像素的深度。


2.create_kitti_masks
生成静态物体的掩码。读取KITTI数据集中的oxts文件,然后遍历每一帧图像,将所有非运动物体(如建筑、路标等)标记为静态物体,并生成相应的掩码图像。
-
1.读取KITTI数据集中的oxts文件,获取车辆的运动状态和位置信息。
-
2.遍历每一帧图像,读取图像中的类别信息。
a. c a t e g o r y i , j category_{i,j} categoryi,j:第 i i i 帧图像中第 j j j 个像素点的类别信息。
-
3.将所有非运动物体(如建筑、路标等)标记为静态物体,即生成一个布尔类型的掩码图像,其中每个像素的值为 True 表示该像素对应的物体是静态的。
a. m o v e r i , j = { 1 , if c a t e g o r y i , j is a static object 0 , otherwise mover_{i,j} = \begin{cases} 1, & \text{if } category_{i,j} \text{ is a static object} \\ 0, & \text{otherwise} \end{cases} moveri,j={1,0,if categoryi,j is a static objectotherwise
-
4.对生成的掩码图像进行膨胀操作,使掩码图像中的静态物体区域更加明显。
a. k e r n e l i , j = { 1 , if i , j are within a circle of radius d i l a t i o n 0 , otherwise kernel_{i,j} = \begin{cases} 1, & \text{if } i,j \text{ are within a circle of radius } dilation \\ 0, & \text{otherwise} \end{cases} kerneli,j={1,0,if i,j are within a circle of radius dilationotherwise
b. m o v e r ′ = m o v e r ⊗ k e r n e l mover' = mover \otimes kernel mover′=mover⊗kernel -
5.将生成的掩码图像保存到KITTI数据集的指定位置中。
a. static_mask = mover’ <= 0
b. sky_mask = category == SKY_CLASS
其中,
- i i i 表示图像帧数,
- j j j 表示像素点索引,在上述公式中,
- ⊗ \otimes ⊗ 表示卷积运算,mover 表示运动物体掩码图像,mover’ 表示经过膨胀操作后的运动物体掩码图像,kernel 表示膨胀操作的卷积核,dilation 表示膨胀操作的半径,
- static_mask 表示静态物体掩码图像,
- sky_mask 表示天空掩码图像,
- c a t e g o r y i , j category_{i,j} categoryi,j 表示第 i i i 帧图像中第 j j j 个像素点的类别信息,
- SKY_CLASS 表示天空类别的类别码。 ⊗ \otimes ⊗ 表示卷积运算,
static_mask:

- 0(黑色),动态物体
- 1(白色),静态物体
sky_mask:

- 0(黑色),其他
- 1(白色),天空
该脚本主要是根据 kitti_step 中给定的数据进行划分出动态物体和静态物体,而 kitti_step 是数据集直接给定的,所以其实这里并没有什么算法上的应用。
- 参数读取:

- 这里创建了
static_02以及sky_02文件夹:


3.create_kitti_metadata
- 参数:

- 读取传感器标定文件:


(0)读取标定参数
(1)计算c2w
-
1.读取Kitti数据集中的校准文件,包含多个转换矩阵,如
Tr_imu_velo、Tr_velo_cam、R_rect、P2和P3。 -
2.计算
imu2velo、velo2cam_base、cam_base2rect等转换矩阵:-
imu2velo:从IMU坐标系到Velodyne坐标系的转换矩阵。
imu2velo = [ Tr_imu_velo 0 0 1 ] \text{imu2velo} = \begin{bmatrix} \text{Tr\_imu\_velo} & 0 \\ 0 & 1 \end{bmatrix} imu2velo=[Tr_imu_velo001] -
velo2cam_base:从Velodyne坐标系到相机基准坐标系的转换矩阵。
velo2cam_base = [ Tr_velo_cam 0 0 1 ] \text{velo2cam\_base} = \begin{bmatrix} \text{Tr\_velo\_cam} & 0 \\ 0 & 1 \end{bmatrix} velo2cam_base=[Tr_velo_cam001] -
cam_base2rect:从相机基准坐标系到矩形相机坐标系的转换矩阵。
cam_base2rect = [ R_rect 0 0 1 ] \text{cam\_base2rect} = \begin{bmatrix} \text{R\_rect} & 0 \\ 0 & 1 \end{bmatrix} cam_base2rect=[R_rect001]
-
-
3.计算
P22imu和P32imu,表示从第2个相机和第3个相机的投影矩阵到IMU坐标系的转换。
imu_pose:IMU的位姿矩阵。
imu_pose = [ Rz ∗ Ry ∗ Rx T 0 1 ] \text{imu\_pose} = \begin{bmatrix} \text{Rz} * \text{Ry} * \text{Rx} & \text{T} \\ 0 & 1 \end{bmatrix} imu_pose=[Rz∗Ry∗Rx0T1] -
4.读取
OXTS数据,获取GPS坐标(纬度、经度、高度)和欧拉角(Roll, Pitch, Heading)。将GPS坐标转换为Mercator坐标,计算IMU的平移向量。使用欧拉角计算IMU的旋转矩阵。根据IMU的平移向量和旋转矩阵,计算IMU的位姿矩阵。oxts = [float(x) for x in line.strip().split()] if scale is None: scale = _lat_to_scale(oxts[0]) imu_pose = torch.eye(4, dtype=torch.float64) imu_pose[0, 3], imu_pose[1, 3] = _lat_lon_to_mercator(oxts[0], oxts[1], scale) imu_pose[2, 3] = oxts[2] # From https://github.com/autonomousvision/kitti360Scripts/blob/master/kitti360scripts/devkits/convertOxtsPose/python/convertOxtsToPose.py rx = oxts[3] # roll ry = oxts[4] # pitch rz = oxts[5] # heading Rx = torch.DoubleTensor([[1, 0, 0], [0, np.cos(rx), -np.sin(rx)], [0, np.sin(rx), np.cos(rx)]]) # base => nav (level oxts => rotated oxts) Ry = torch.DoubleTensor([[np.cos(ry), 0, np.sin(ry)], [0, 1, 0], [-np.sin(ry), 0, np.cos(ry)]]) # base => nav (level oxts => rotated oxts) Rz = torch.DoubleTensor([[np.cos(rz), -np.sin(rz), 0], [np.sin(rz), np.cos(rz), 0], [0, 0, 1]]) # base => nav (level oxts => rotated oxts) imu_pose[:3, :3] = torch.matmul(torch.matmul(Rz, Ry), Rx)墨卡托坐标计算
_lat_lon_to_mercator:mx = scale * lon * π * er / 180 my = scale * er * log(tan((90 + lat) * π / 360))其中,mx和my分别表示墨卡托坐标的x和y坐标,lon和lat为经度和纬度,scale为经纬度到墨卡托坐标的缩放因子,er为地球平均半径。
墨卡托投影是一种地图投影方法,将地球表面的点映射到二维平面上。这里给出的数学公式是基于球体地球模型的墨卡托投影。
首先,需要将地理坐标(经度和纬度)转换为弧度,方法如下:
经度弧度 = 经度 × (π / 180) ; 纬度弧度 = 纬度 × (π / 180)
接下来,可以使用以下公式计算墨卡托平面坐标:
x = R × 经度弧度; y = R × ln[tan(π/4 + 纬度弧度/2)]
其中 R 是地球半径,一般取为 6378137 米,x 和 y 是墨卡托平面坐标。
需要注意的是,这种投影会在靠近极地地区产生较大的失真。因此,在这些区域使用墨卡托投影时应格外小心。

-
8.c2w:从图像坐标系到世界坐标系的转换矩阵。
c2w = imu_pose ∗ P22imu 或 imu_pose ∗ P32imu \text{c2w} = \text{imu\_pose} * \text{P22imu} \quad \text{或} \quad \text{imu\_pose} * \text{P32imu} c2w=imu_pose∗P22imu或imu_pose∗P32imu
(2)构造image_path, c2w, image.size[0], image.size[1], image_index, frame, depth_map,sky_mask_path,dino_0,backward_flow_path,forward_flow_path,backward_neighbor,forward_neighbor等数据

(3)计算图像的光束边界 get_bounds_from_depth()

Cameras类,使用nerfstudio库里面的实现:

返回射线束:

已知相机光束的方向 directions(尺寸为 (N, 3)),每个方向上的深度值 depth(尺寸为 (N,)),则可以计算世界坐标系下的点集 points(尺寸为 (N, 3))。
具体计算方法为:
points = item.c2w[:, 3].unsqueeze(0) + filtered_directions * filtered_depth * filtered_z_scale
bounds = [item.c2w[:, 3].unsqueeze(0), points]
if cur_min_bounds is not None:
bounds.append(cur_min_bounds.unsqueeze(0))
bounds.append(cur_max_bounds.unsqueeze(0))
bounds = torch.cat(bounds)
return bounds.min(dim=0)[0], bounds.max(dim=0)[0]


(4)时间戳归一化normalize_timestamp
已知每个图像的时间戳 item.time,以及最小帧 min_frame 和最大帧 max_frame。将时间戳归一化到 [-1, 1] 范围内。
具体计算方法为:
i
t
e
m
.
t
i
m
e
=
i
t
e
m
.
t
i
m
e
−
m
i
n
_
f
r
a
m
e
0.5
×
(
m
a
x
_
f
r
a
m
e
−
m
i
n
_
f
r
a
m
e
)
−
1
item.time = \frac{item.time - min\_frame}{0.5 \times (max\_frame - min\_frame)} - 1
item.time=0.5×(max_frame−min_frame)item.time−min_frame−1
divisor = 0.5 * (max_frame - min_frame)
item.time = (item.time - min_frame) / divisor - 1
其中,divisor为时间戳的缩放因子,item.time为图像的时间戳,min_frame和max_frame分别为帧范围的最小和最大值。
(5)相机位置归一化scale_bounds
已知所有图像的最小边界 min_bounds 和最大边界 max_bounds,计算场景原点 origin 和位姿缩放因子 pose_scale_factor。
具体计算方法为:
o r i g i n = m a x _ b o u n d s + m i n _ b o u n d s 2 origin = \frac{max\_bounds + min\_bounds}{2} origin=2max_bounds+min_bounds p o s e _ s c a l e _ f a c t o r = ∣ ∣ m a x _ b o u n d s − m i n _ b o u n d s 2 ∣ ∣ pose\_scale\_factor = ||\frac{max\_bounds - min\_bounds}{2}|| pose_scale_factor=∣∣2max_bounds−min_bounds∣∣
origin = (max_bounds + min_bounds) * 0.5
pose_scale_factor = ||(max_bounds - min_bounds) * 0.5||
item.c2w[:, 3] = (item.c2w[:, 3] - origin) / pose_scale_factor
其中,pose_scale_factor为位姿缩放因子,item.c2w为相机外参,origin为计算的原点,min_bounds和max_bounds分别为场景的最小和最大边界。

(5)write_metadata:
dataset/
├── origin
├── scene_bounds
├── pose_scale_factor
└── frames
├── frame_0
│ ├── image_index
│ ├── rgb_path
│ ├── depth_path
│ ├── feature_path
│ ├── backward_flow_path
│ ├── forward_flow_path
│ ├── backward_neighbor_index
│ ├── forward_neighbor_index
│ ├── c2w
│ ├── W
│ ├── H
│ ├── intrinsics
│ ├── time
│ ├── video_id
│ ├── is_val
│ ├── static_mask_path (optional)
│ ├── mask_path (optional)
│ └── sky_mask_path (optional)
├── frame_1
│ ├── ...
└── ...
- origin:场景的原点坐标。
- scene_bounds:场景的最小和最大边界。
- pose_scale_factor:位姿缩放因子。
- frames:数据集中的所有帧。
- image_index:图像索引。
- rgb_path:RGB图像的路径。
- depth_path:深度图像的路径。
- feature_path:特征图像的路径。
- backward_flow_path:向后光流的路径。—> 此时应该是空
- forward_flow_path:向前光流的路径。—> 此时应该是空
- backward_neighbor_index:后一个邻居帧的索引。
- forward_neighbor_index:前一个邻居帧的索引。
- c2w:从图像坐标系到世界坐标系的转换矩阵。
- W:图像的宽度。
- H:图像的高度。
- intrinsics:相机内参矩阵。
- time:图像捕获的时间。
- video_id:视频序列的ID。
- is_val:是否为验证帧。
- static_mask_path(可选):静态遮罩的路径。
- mask_path(可选):遮罩图像的路径。
- sky_mask_path(可选):天空遮罩图像的路径。
每个帧目录下的文件表示该帧的相关信息和数据。如果某些可选字段不存在,则不会包含在JSON中。



ImageMetadata 类
这个类对KITTI数据集中的图像、深度图、mask(遮罩)、天空mask、特征、光流等数据进行处理。类中有一系列的加载函数,这些函数可以实现对数据的缓存、读取、调整尺寸等操作。以下是对这段代码的理解和数学公式的表示。
首先,我们有类构造函数__init__,它接收以下参数:
image_path: 图像路径
c2w: 从相机坐标系到世界坐标系的转换矩阵
W, H: 图像的宽度和高度
intrinsics: 相机内参矩阵
image_index, time, video_id: 图像索引、时间戳和视频ID
depth_path: 深度图路径
mask_path, sky_mask_path: mask路径和天空mask路径
feature_path: 特征路径
backward_flow_path, forward_flow_path: 后向光流和前向光流路径
backward_neighbor_index, forward_neighbor_index: 后向和前向邻居索引
is_val: 布尔值,表示是否为验证集
pose_scale_factor: 位姿尺度因子
local_cache: 本地缓存路径
接下来是一系列加载函数,包括:
load_image(): 加载图像并调整尺寸(如果需要)。
load_mask(), load_sky_mask(): 加载mask和天空mask,并调整尺寸(如果需要)。
load_features(): 加载特征并调整尺寸(如果需要)。
load_depth(): 加载深度图,将深度值转换为米,并调整尺寸(如果需要)。
load_backward_flow(), load_forward_flow(): 加载后向光流和前向光流,以及对应的有效性mask。
- 对于加载图像,将图像调整为大小 W×H:
I' = resize(I, (W, H)) - 对于加载mask和天空mask,将它们调整为大小 W×H:
M' = resize(M, (W, H)),S' = resize(S, (W, H)) - 对于加载特征,将特征调整为大小 W×H:
F' = resize(F, (W, H)) - 对于加载深度图,将深度值转换为米,并调整尺寸为 W×H:
D' = resize(D, (W, H)) / pose_scale_factor - 对于加载光流,将光流调整为大小 W×H,并调整其X和Y值:
flow_x' = flow_x * (W / orig_W) flow_y' = flow_y * (H / orig_H) flow' = resize((flow_x', flow_y'), (W, H))
_load_flow函数主要负责加载光流数据。首先检查flow_path是否为None,如果为None,则返回全零光流和光流有效性张量。接下来,根据数据格式和来源加载光流数据。这里主要有两种方式:从Parquet文件加载和从VKITTI2格式的文件加载。
-
(1)从Parquet文件加载:
如果光流数据以Parquet格式存储,函数将读取对应的Parquet文件,并根据其内容解析光流数据。这里主要有两种情况:- 如果表格包含名为
flow的列,那么直接将其转换为张量,根据元数据中给定的形状调整形状。 - 如果表格不包含名为
flow的列,那么从表格中提取点对(point1_x, point1_y)和(point2_x, point2_y),并根据点对计算光流。这里,光流的计算方法是根据is_forward参数来决定:如果为True,则计算point2 - point1;如果为False,则计算point1 - point2。
- 如果表格包含名为
-
(2)从VKITTI2格式的文件加载:
如果光流数据以VKITTI2格式存储,函数将使用OpenCV(cv2)库加载文件,并根据文件内容解析光流数据。具体步骤如下:- 读取quantized_flow,将其转换为浮点数。
- 从quantized_flow中提取无效光流标志(第0通道),计算有效光流(第2和1通道)。这里,光流的计算方法是将其归一化到[-1, 1]的范围,并乘以图像的宽度和高度。
- 根据无效光流标志更新flow张量。
在完成光流数据的加载和解析后,函数将根据需要调整光流数据的尺寸,以确保其与其他数据具有相同的尺寸。最后,函数返回加载和处理后的光流数据和有效性信息。
需要注意的是,_load_flow函数本身并没有涉及到计算光流的数学理论。它主要是处理已经计算好的光流数据,将其加载到内存并进行必要的格式转换和尺寸调整。光流计算方法本身包括一系列复杂的数学理论和算法,如Lucas-Kanade方法、Horn-Schunck方法等。
4.extract_dino_features
从Vision Transformer (ViT)模型中提取特征、描述符和显著性图。ViTExtractor类有许多方法,例如创建模型、修改模型分辨率、预处理图像等。这个类的主要功能是从预训练的ViT模型中提取特征和描述符,以便在其他任务中使用。
-
1.对于一个输入图像,我们可以将其分解为多个小图像块,每个图像块的大小为 p × p,其中 p 是 ViT 的 patch size,例如 8 或 16。对于一个高度为 H、宽度为 W 的输入图像,我们可以得到 t = HW / p² + 1 个 tokens,其中 t 是 token 的数量。
-
2.在给定的层上,我们从 ViT 模型中提取特征。对于一个给定的 token,我们可以得到其 d 维特征表示,其中 d 是 ViT 的嵌入维度。
-
3.对于一个给定的 token,我们可以计算它的 log-binned descriptor。为了计算描述符,我们首先将提取的特征沿着空间维度进行平均池化,然后将这些特征连接起来。在计算过程中,我们使用了多个不同层次的池化核,以便捕捉不同尺度上的信息。我们可以用以下数学公式表示这一过程:
设 B 为批大小,h 为头数,t 为 token 数量,d 为嵌入维度,y 和 x 分别表示 token 在网格中的行和列索引,hierarchy 是分层的数量。对于每个层次 k,我们计算一个池化核大小为 3 k ∗ 3 k 3^k * 3^k 3k∗3k 的平均池化。然后,我们将得到的池化特征连接在一起,得到最终的描述符。
bin_x ∈ R^(B x (sub_desc_dim * num_bins) x (t-1))其中,sub_desc_dim 是子描述符的维度,num_bins 是 bin 的数量,bin_x 是最终的描述符矩阵。
-
4.对于给定的层和输入图像,我们可以计算特征和描述符。这些信息可以用于其他任务,例如图像检索、定位等。
-
假设输入图像 X 的尺寸为 HxW(高度x宽度),在预处理阶段,我们将图像转换为张量 T,尺寸为 BxCxHxW(批量大小x通道数x高度x宽度)。
-
在特征提取阶段,我们从模型中提取特定层的特定方面的特征 F,其尺寸为 Bxhxtxd(批量大小x头数x令牌数x嵌入维度)。
-
接下来,我们将特征 F 输入到 _log_bin 方法中,创建一个对数分箱描述符 D。描述符 D 的尺寸为 Bx1x(t-1)x(dxh)。
-
构造函数__init__初始化一个ViT模型,将其设为评估模式,并根据所需的模型类型和stride参数设置相应的参数。
-
create_model方法根据给定的模型类型,从facebookresearch/dino库中加载预训练的ViT模型。
-
_fix_pos_enc方法用于创建位置编码插值的方法。
-
patch_vit_resolution方法用于改变模型输出的分辨率,通过更改patch提取的步幅实现。
-
preprocess方法对输入图像进行预处理,包括缩放、标准化等。
-
_get_hook、_register_hooks和_unregister_hooks方法用于实现PyTorch的forward hook功能,用于在模型的指定层提取特定类型的特征。
-
_extract_features方法通过给定的模型,从输入的图像张量中提取特定类型的特征。
-
_log_bin方法用于创建一个log-binned描述符。
-
extract_descriptors方法从输入图像中提取描述符。
-
extract_saliency_map方法从输入图像中提取显著性图。
- 参数加载:

VIT模型参数:


最终描述子 (bin_x) 的数据格式是一个四维张量,具有以下形状:B x 1 x (t-1) x (d x h)
其中:
- B:批量大小(batch size),即一次处理的图像数量
- t:令牌的数量(number of tokens),即图像分割成的块数 + 1
- d:ViT中的嵌入维度(embedding dimension in the ViT)
- h:头的数量(number of heads),通常在PyTorch的约定中代替通道维度 BxCxHxW
这个张量表示的是批量中每个图像的局部描述子,它们分布在不同的空间位置上。
5.run_pca
- 参数加载:

- PCA类,使用的 sklearn 库中的实现:

对特征使用PCA降维:
-
1.加载元数据(metadata)和特征提取器的输出描述子(descriptor)。
-
2.对每个描述子(descriptor)执行如下操作:
- 将特征加载到CPU上:torch.load(buffer_from_stream(‘{}.pt’.format(frame[‘feature_path’])), map_location=‘cpu’)
- 计算并存储每个描述子的形状:num_patches_list.append([descriptor.shape[0], descriptor.shape[1]])
- 对描述子进行L2范数归一化:descriptor /= descriptor.norm(dim=-1, keepdim=True)
- 将描述子存储为NumPy数组:descriptors_list.append(descriptor.view(-1, descriptor.shape[2]).numpy())
-
3.将所有描述子连接到一个NumPy数组中:descriptors = np.concatenate(descriptors_list, axis=0)
-
4.应用PCA降维:
- 使用PCA降维描述子:pca_descriptors = PCA(n_components=hparams.n_components, random_state=42).fit_transform(descriptors)
- 降维后的数学表达式为: P C A ( X ) = X ⋅ V n PCA(X) = X \cdot V_{n} PCA(X)=X⋅Vn,其中 X X X 是原始描述子, V n V_{n} Vn 是PCA变换矩阵的前n个主成分.
-
5.按图像划分PCA描述子:
- 计算每个图像的累积和索引:split_idxs = np.cumsum(split_idxs)
- 根据累积和索引划分PCA描述子:pca_per_image = np.split(pca_descriptors, split_idxs[:-1], axis=0)
-
6.将PCA描述子重塑为原始形状并存储结果:
- 重塑并存储PCA描述子:img_pca.reshape((num_patches[0], num_patches[1], hparams.n_components))
- 将结果写入文件:pq.write_table(…)
-
7.删除临时文件(如果需要):fs.rm(tmp_path)