Kafka
- 1、什么是消息队列
- 2、消息队列有什么用
- 3、Kafka 的多分区以及多副本机制有什么好处呢
- 4、Zookeeper 在 Kafka 中的作用知道吗
- 5、Kafka 如何保证消息的消费顺序
- 6、Kafka 如何保证消息不丢失
- 7、Kafka 如何保证消息不重复消费
- 7、Kafka为什么快/吞吐量大
1、什么是消息队列
我们可以把消息队列看作是一个存放消息的容器,当我们需要使用消息的时候,直接从容器中取出消息供自己使用即可。由于队列 Queue 是一种先进先出的数据结构,所以消费消息时也是按照顺序来消费的。参与消息传递的双方称为 生产者 和 消费者 ,生产者负责发送消息,消费者负责处理消息。
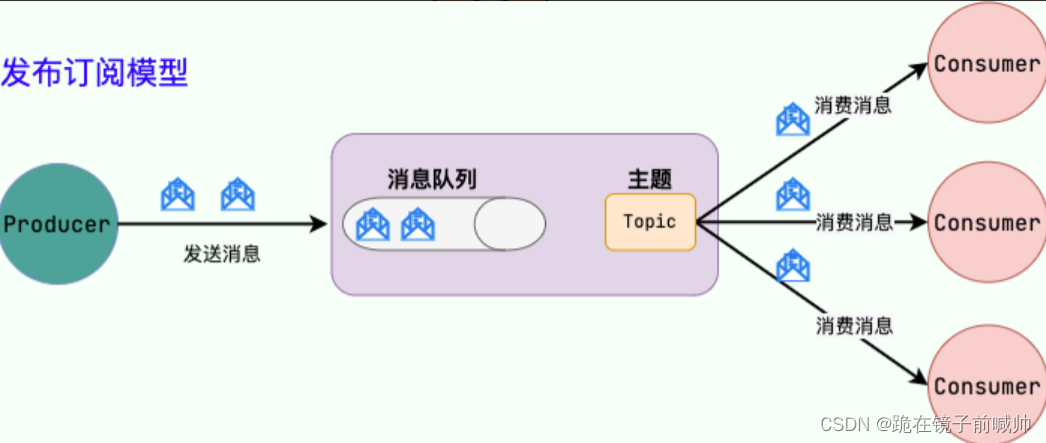
2、消息队列有什么用
通常来说,使用消息队列能为我们的系统带来下面三点好处:
- 应用解耦
举个常见业务场景:下单扣库存,用户下单后,订单系统去通知库存系统扣减。传统做法就是1订单系统直接调用库存系统:

- 如果库存系统无法访问,下单就会失败,订单和库存系统存在耦合关系
- 如果业务又接入一个营销积分服务,那订单下游系统要扩充,如果未来接入越来越多下游系统,那订单系统代码需要经常修改
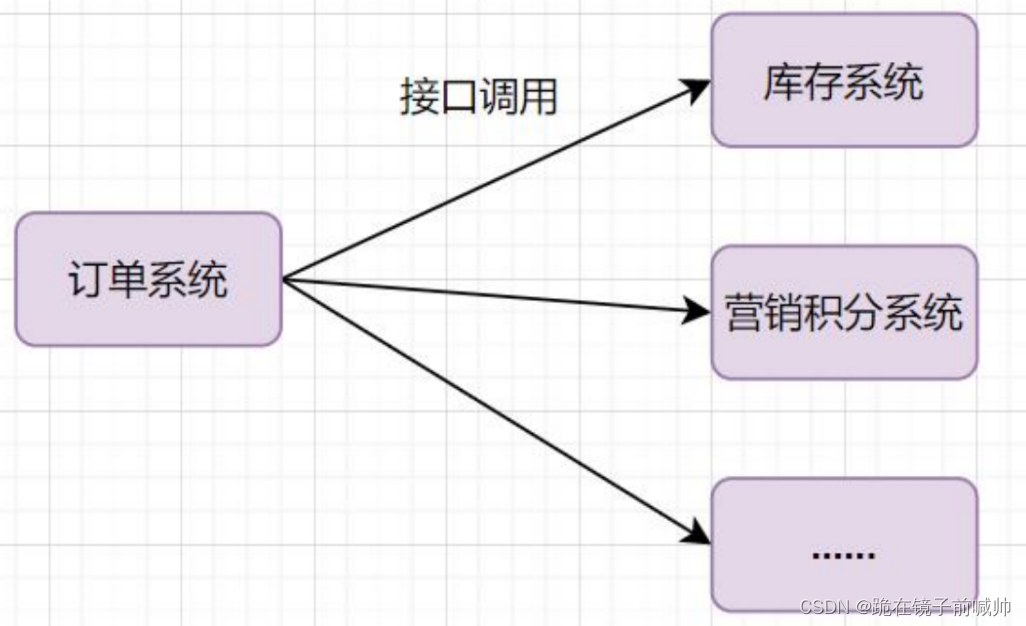
如何解决这个问题呢?可以引入消息队列
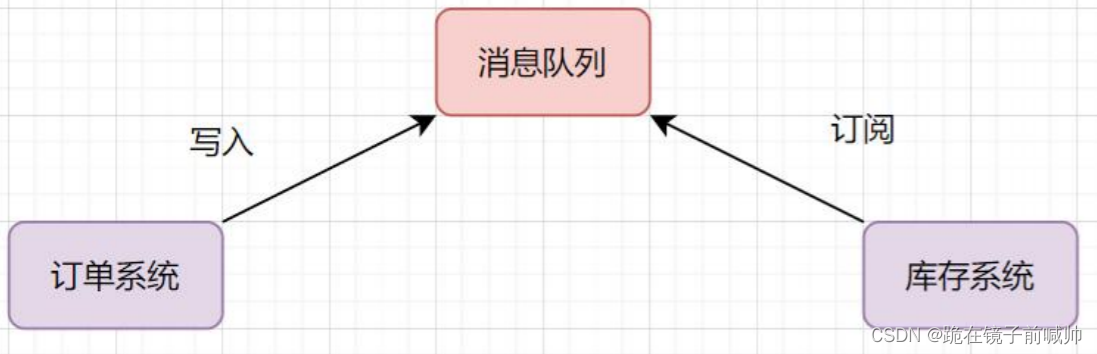
- 订单系统:用户下单后,消息写入到消息队列,返回下单成功。
- 库存系统:订阅下单消息,获取下单信息,进行库存操作。
- 削峰/限流。
流量削峰也是消息队列的常用场景。我们做秒杀实现的时候,需要避免流量暴涨,打垮应用系统的风险。可以在应用前面加入消息队列。

假设秒杀系统每秒最多可以处理 2k个请求,每秒却有 5k 的请求过来,可以引入消息队列,秒杀系统每秒从消息队列拉 2k 请求处理得了。
有些伙伴担心这样会出现消息积压的问题,首先秒杀活动不会每时每刻都那么多请求过来,高峰期过去后,积压的请求可以慢慢处理;其次,如果消息队列长度超过最大数量,可以直接抛弃用户请求或跳转到错误页面。
- 异步处理
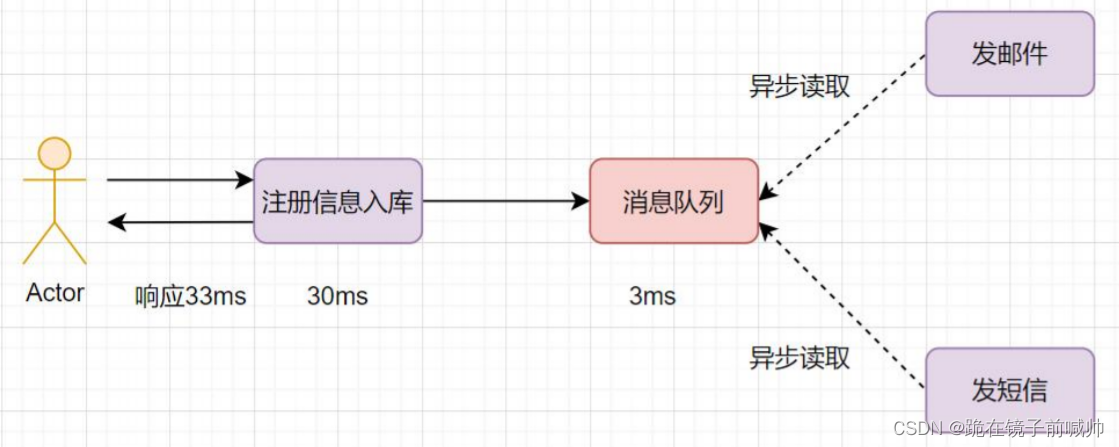
我们经常会遇到这样的业务场景:用户注册成功后,给它发个短信和发个邮件。如果注册信息入库 30ms,发短信、邮件也 30ms,三个动作串行执行的话,会比较耗时,响应 90ms

如果采用并行执行的方式,可以减少响应时间。注册信息入库后,同时异步发短信和邮件。如何实现异步呢,用消息队列即可,就是说,注册信息入库成功后,写入到消息队列(这个一般比较快,如只需要 3ms),然后异步读取发邮件和短信。
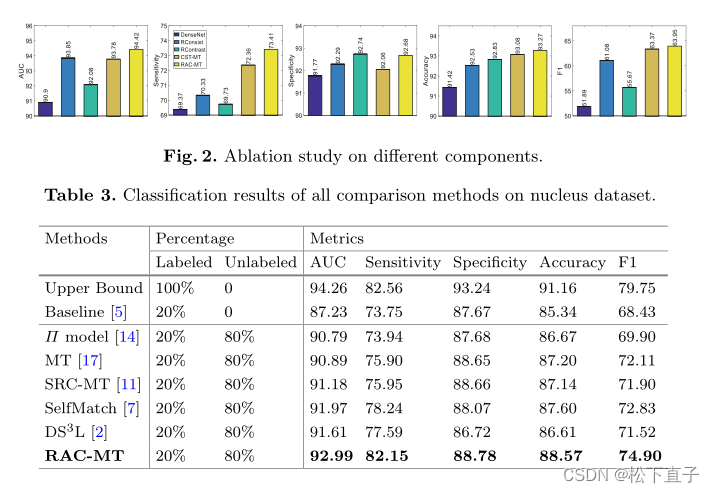
3、Kafka 的多分区以及多副本机制有什么好处呢
- Kafka 通过给特定 Topic 指定多个 Partition,而各个 Partition 可以分布在不同的 Broker 上,这样便能提供比较好的并发能力(负载均衡)。
- Partition 可以指定对应的 Replica 数,这也极大地提高了消息存储的安全性,提高了容灾能力,不过也相应的增加了所需要的存储空间。
4、Zookeeper 在 Kafka 中的作用知道吗
- Broker 注册 :在 Zookeeper 上会有一个专门用来进行 Broker 服务器列表记录的节点。每个 Broker 在启动时,都会到 Zookeeper 上进行注册,即到 /brokers/ids 下创建属于自己的节点。每个 Broker 就会将自己的 IP 地址和端口等信息记录到该节点中去。
- Topic 注册 : 在 Kafka 中,同一个Topic 的消息会被分成多个分区并将其分布在多个 Broker 上,这些分区信息及与 Broker 的对应关系也都是由 Zookeeper 在维护。比如我创建了一个名字为 my-topic 的主题并且它有两个分区,对应到 zookeeper 中会创建文件夹:/brokers/topics/my-topic/Partitions/0、/brokers/topics/my-topic/Partitions/1。
- 负载均衡 :上面也说过了 Kafka 通过给特定 Topic 指定多个 Partition, 而各个 Partition 可以分布在不同 Broker 上,这样便能提供比较好的并发能力。 对于同一个 Topic 的不同 Partition,Kafka 会尽力将这些 Partition 分布到不同的 Broker 服务器上。当生产者产生消息后也会尽量投递到不同 Broker 的 Partition 里面。当 Consumer 消费的时候,Zookeeper 可以根据当前的 Partition 数量以及 Consumer 数量来实现动态负载均衡。
5、Kafka 如何保证消息的消费顺序
- 1 个 Topic 只对应一个 Partition。
- (推荐)发送消息的时候指定 key/Partition。
6、Kafka 如何保证消息不丢失
丢失消息有 3 种不同的情况,针对每一种情况有不同的解决方案。
- 生产者丢失消息的情况
- Kafka 弄丢了消息
- 消费者丢失消息的情况
生产者丢失消息的情况
生产者调用send方法发送消息之后,消息可能因为网络问题并没有发送过去。所以,我们不能默认在调用send方法发送消息之后消息发送成功了。为了确定消息是发送成功,我们要判断消息发送的结果。可以采用为其添加回调函数的形式,如果消息发送失败的话,我们检查失败的原因之后重新发送即可!
producer.send(new ProducerRecord<>(topic, message), new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception == null) {
System.out.println("发送成功");
} else {
System.out.println("发送失败");
}
}
});
另外这里推荐为 Producer 的 retries (重试次数)设置一个比较合理的值,一般是 3 ,但是为了保证消息不丢失的话一般会设置比较大一点。设置完成之后,当出现网络问题之后能够自动重试消息发送,避免消息丢失。另外,建议还要设置重试间隔,因为间隔太小的话重试的效果就不明显了,网络波动一次你3次一下子就重试完了。
Kafka 弄丢了消息
我们知道 Kafka 为 Partition 引入了多副本(Replica)机制。Partition 中的多个副本之间会有一个叫做 Leader 的家伙,其他副本称为 Follower。我们发送的消息会被发送到 Leader 副本,然后 Follower 副本才能从 Leader 副本中拉取消息进行同步。生产者和消费者只与 Leader 副本交互。你可以理解为其他副本只是 Leader 副本的拷贝,它们的存在只是为了保证消息存储的安全性。
试想一种情况:假如 Leader 副本所在的 Broker 突然挂掉,那么就要从 Fllower 副本重新选出一个 Leader ,但是 Leader 的数据还有一些没有被 Follower 副本的同步的话,就会造成消息丢失。
设置 acks = all
解决办法就是我们设置 acks = all。acks 是 Kafka 生产者(Producer) 很重要的一个参数。
acks 的默认值即为1,代表我们的消息被leader副本接收之后就算被成功发送。当我们配置 acks = all 表示只有所有 ISR 列表的副本全部收到消息时,生产者才会接收到来自服务器的响应. 这种模式是最高级别的,也是最安全的,可以确保不止一个 Broker 接收到了消息. 该模式的延迟会很高。
设置 replication.factor >= 3
为了保证 Leader 副本能有 Follower 副本能同步消息,我们一般会为 Topic 设置 replication.factor >= 3。这样就可以保证每个 Partition 至少有 3 个副本。虽然造成了数据冗余,但是带来了数据的安全性。
消费者丢失消息的情况
我们知道消息在被追加到 Partition(分区)的时候都会分配一个特定的偏移量(offset)。offset 表示 Consumer 当前消费到的 Partition(分区)的所在的位置。Kafka 通过偏移量(offset)可以保证消息在分区内的顺序性。
当消费者拉取到了分区的某个消息之后,消费者会自动提交了 offset。自动提交的话会有一个问题,试想一下,当消费者刚拿到这个消息准备进行真正消费的时候,突然挂掉了,消息实际上并没有被消费,但是 offset 却被自动提交了。
这种情况的解决办法也比较粗暴,我们手动关闭自动提交 offset,每次在真正消费完消息之后之后再自己手动提交 offset 。但是,细心的朋友一定会发现,这样会带来消息被重新消费的问题。比如你刚刚消费完消息之后,还没提交 offset,结果自己挂掉了,那么这个消息理论上就会被消费两次。
7、Kafka 如何保证消息不重复消费
- kafka出现消息重复消费的原因:服务端侧已经消费的数据没有成功提交 offset(根本原因)。
- Kafka 侧 由于服务端处理业务时间长或者网络链接等等原因让 Kafka 认为服务假死,触发了分区 rebalance。
① 消费消息服务做幂等校验,比如 Redis 的 set、MySQL 的主键等天然的幂等功能。这种方法最有效。这部分主要集中在消费端的编码层面,需要我们在设计代码时以幂等性的角度进行开发设计,保证同一数据无论进行多少次消费,所造成的结果都一样。处理方式可以在消息体中添加唯一标识,在处理消息前先检查下Mysql/Redis是否已经处理过该消息了,消费端进行确认此唯一标识是否已经消费过,如果消费过,则不进行之后处理。从而尽可能的避免了重复消费。
② 提高消费端的处理性能避免触发Balance,比如可以用多线程的方式来处理消息,缩短单个消息消费的时长。或者还可以调整消息处理的超时时间,也还可以减少一次性从Broker上拉取数据的条数。
7、Kafka为什么快/吞吐量大
- 顺序读写:Kafka每个分区对应一个日志文件,消息写入是追加到日志文件后面、顺序写磁盘的速度快于随机写。
- 批量发送:Kafka发送消息时将消息缓存到本地,达到一定数量或者间隔一定时间再发送,减少了网络请求的次数。
- 批量压缩:发送的时候对数据进行压缩。
- 页面缓存:Kafka大量使用了页面缓存,就是将数据写入磁盘前会先写入系统缓存,然后进行刷盘;读取数据也会先读取缓存,没有再读磁盘。虽然异步刷盘会因单点故障导致数据丢失,但是多副本的机制保障了数据的持久化。
- 零拷贝:Kafka使用了DMA的技术,使Socket缓冲池可以直接读取内核内存的数据,减少了数据拷贝到应用再拷贝到Socket缓冲池的过程,也减少了2次上下文切换。