1.MySQL 事务的四大特性说一下?
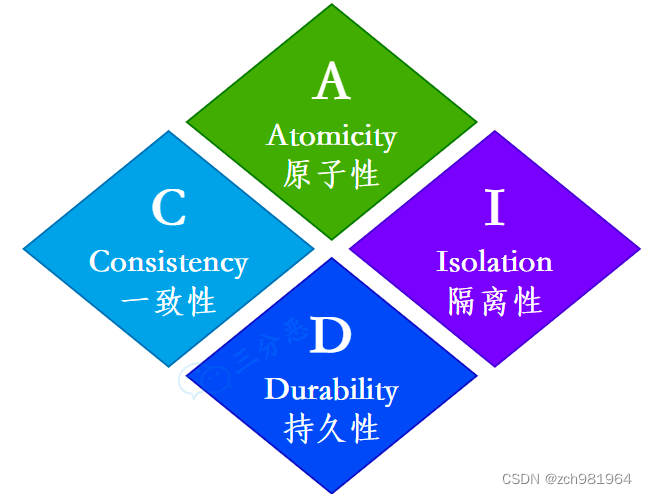
- 原子性:事务作为一个整体被执行,包含在其中的对数据库的操作要么全部被执行,要么都不执行。
- 一致性:指在事务开始之前和事务结束以后,数据不会被破坏,假如 A 账户给 B 账户转 10 块钱,不管成功与否,A 和 B 的总金额是不变的。
- 隔离性:多个事务并发访问时,事务之间是相互隔离的,即一个事务不影响其它事务运行效果。简言之,就是事务之间是进水不犯河水的。
- 持久性:表示事务完成以后,该事务对数据库所作的操作更改,将持久地保存在数据库之中。
2.那 ACID 靠什么保证的呢?
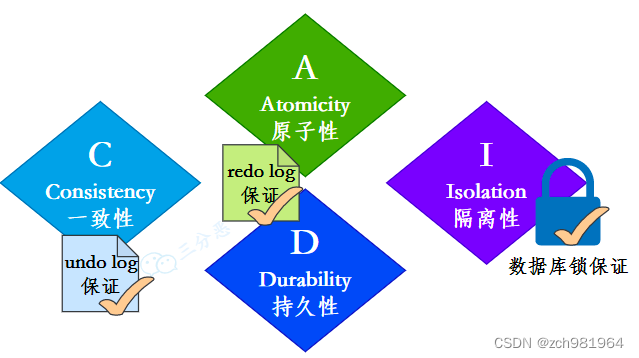
- 事务的隔离性是通过数据库锁的机制实现的。
- 事务的一致性由 undo log 来保证:undo log 是逻辑日志,记录了事务的 insert、update、deltete 操作,回滚的时候做相反的 delete、update、insert 操作来恢复数据。
- 事务的原子性和持久性由 redo log 来保证:redolog 被称作重做日志,是物理日志,事务提交的时候,必须先将事务的所有日志写入 redo log 持久化,到事务的提交操作才算完成。
3.事务的隔离级别有哪些?MySQL 的默认隔离级别是什么?
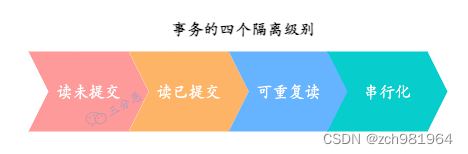
事务的四个隔离级别
- 读未提交(Read Uncommitted)
- 读已提交(Read Committed)
- 可重复读(Repeatable Read)
- 串行化(Serializable)
MySQL 默认的事务隔离级别是可重复读 (Repeatable Read)。
4.什么是幻读,脏读,不可重复读呢?
- 事务 A、B 交替执行,事务 A 读取到事务 B 未提交的数据,这就是脏读。
- 在一个事务范围内,两个相同的查询,读取同一条记录,却返回了不同的数据,这就是不可重复读。
- 事务 A 查询一个范围的结果集,另一个并发事务 B 往这个范围中插入 / 删除了数据,并静悄悄地提交,然后事务 A 再次查询相同的范围,两次读取得到的结果集不一样了,这就是幻读。
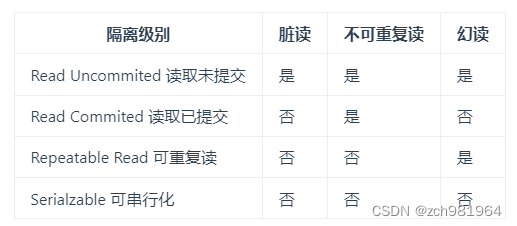
不同的隔离级别,在并发事务下可能会发生的问题:
5.事务的各个隔离级别都是如何实现的?
读未提交
读未提交,就不用多说了,采取的是读不加锁原理。
- 事务读不加锁,不阻塞其他事务的读和写
- 事务写阻塞其他事务写,但不阻塞其他事务读;
读取已提交&可重复读
读取已提交和可重复读级别利用了ReadView和MVCC,也就是每个事务只能读取它能看到的版本(ReadView)。
- READ COMMITTED:每次读取数据前都生成一个 ReadView
- REPEATABLE READ :在第一次读取数据时生成一个 ReadView
串行化
串行化的实现采用的是读写都加锁的原理。
串行化的情况下,对于同一行事务,写会加写锁,读会加读锁。当出现读写锁冲突的时候,后访问的事务必须等前一个事务执行完成,才能继续执行。
6.MVCC 了解吗?怎么实现的?
MVCC(Multi Version Concurrency Control),中文名是多版本并发控制,简单来说就是通过维护数据历史版本,从而解决并发访问情况下的读一致性问题。关于它的实现,要抓住几个关键点,隐式字段、undo 日志、版本链、快照读&当前读、Read View。
版本链
对于 InnoDB 存储引擎,每一行记录都有两个隐藏列DB_TRX_ID、DB_ROLL_PTR
- DB_TRX_ID,事务 ID,每次修改时,都会把该事务 ID 复制给DB_TRX_ID;
- DB_ROLL_PTR,回滚指针,指向回滚段的 undo 日志。

假如有一张user表,表中只有一行记录,当时插入的事务 id 为 80。此时,该条记录的示例图如下:
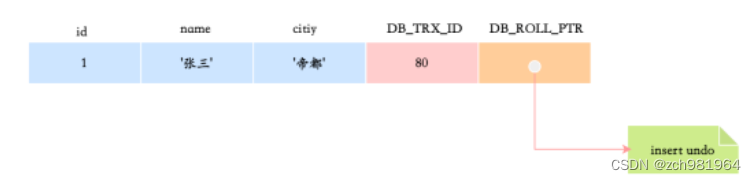
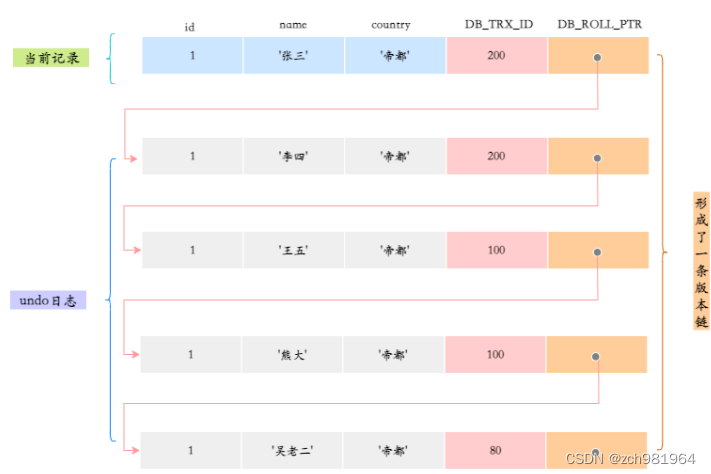
接下来有两个DB_TRX_ID分别为100、200的事务对这条记录进行update操作,整个过程如下:

由于每次变动都会先把undo日志记录下来,并用DB_ROLL_PTR指向undo日志地址。因此可以认为,**对该条记录的修改日志串联起来就形成了一个版本链,**版本链的头节点就是当前记录最新的值。如下:
ReadView
对于Read Committed和Repeatable Read隔离级别来说,都需要读取已经提交的事务所修改的记录,也就是说如果版本链中某个版本的修改没有提交,那么该版本的记录时不能被读取的。所以需要确定在Read Committed和Repeatable Read隔离级别下,版本链中哪个版本是能被当前事务读取的。于是就引入了ReadView这个概念来解决这个问题。
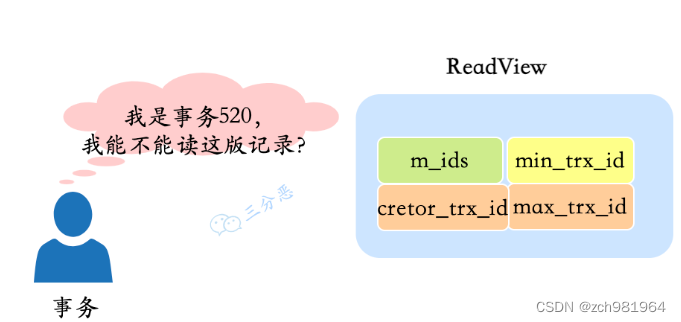
Read View 就是事务执行快照读时,产生的读视图,相当于某时刻表记录的一个快照,通过这个快照,我们可以获取:
-
m_ids :表示在生成 ReadView 时当前系统中活跃的读写事务的事务 id 列表。
-
min_trx_id :表示在生成 ReadView 时当前系统中活跃的读写事务中最小的 事务 id ,也就是 m_ids 中的最小值。
-
max_trx_id :表示生成 ReadView 时系统中应该分配给下一个事务的 id 值。
-
creator_trx_id :表示生成该 ReadView 的事务的 事务 id
有了这个 ReadView ,这样在访问某条记录时,只需要按照下边的步骤判断记录的某个版本是否可见: -
如果被访问版本的 DB_TRX_ID 属性值与 ReadView 中的 creator_trx_id 值相同,意味着当前事务在访问它自己修改过的记录,所以该版本可以被当前事务访问。
-
如果被访问版本的 DB_TRX_ID 属性值小于 ReadView 中的 min_trx_id 值,表明生成该版本的事务在当前事务生成 ReadView 前已经提交,所以该版本可以被当前事务访问。
-
如果被访问版本的 DB_TRX_ID 属性值大于 ReadView 中的 max_trx_id 值,表明生成该版本的事务在当前事务生成 ReadView 后才开启,所以该版本不可以被当前事务访问。
-
如果被访问版本的 DB_TRX_ID 属性值在 ReadView 的 min_trx_id 和 max_trx_id 之间,那就需要判断一下 trx_id 属性值是不是在 m_ids 列表中,如果在,说明创建 ReadView 时生成该版本的事务还是活跃的,该版本不可以被访问;如果不在,说明创建 ReadView 时生成该版本的事务已经被提交,该版本可以被访问。
如果某个版本的数据对当前事务不可见的话,那就顺着版本链找到下一个版本的数据,继续按照上边的步骤判断可见性,依此类推,直到版本链中的最后一个版本。如果最后一个版本也不可见的话,那么就意味着该条记录对该事务完全不可见,查询结果就不包含该记录。
在 MySQL 中, READ COMMITTED 和 REPEATABLE READ 隔离级别的的一个非常大的区别就是它们生成 ReadView 的时机不同。
READ COMMITTED 是每次读取数据前都生成一个 ReadView,这样就能保证自己每次都能读到其它事务提交的数据;REPEATABLE READ 是在第一次读取数据时生成一个 ReadView,这样就能保证后续读取的结果完全一致。
7.数据库读写分离了解吗?
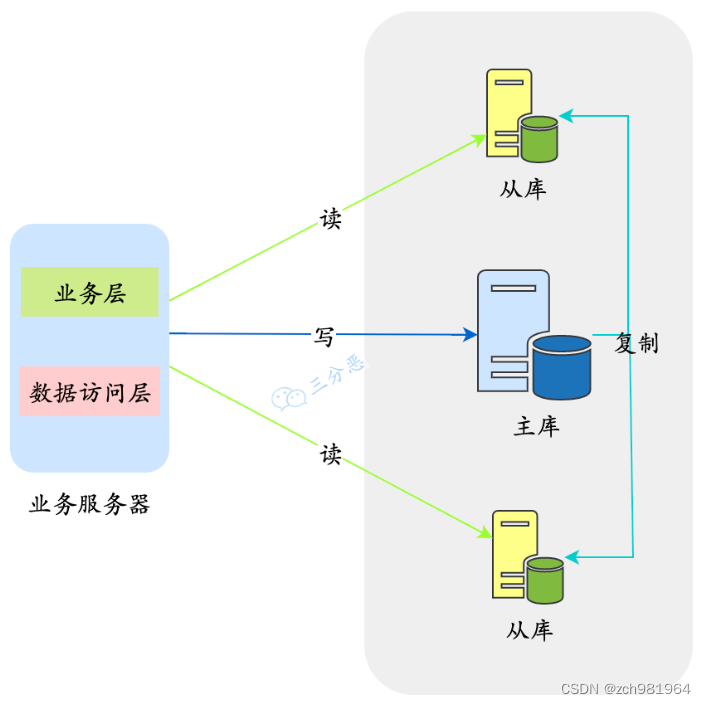
读写分离的基本原理是将数据库读写操作分散到不同的节点上,下面是基本架构图:
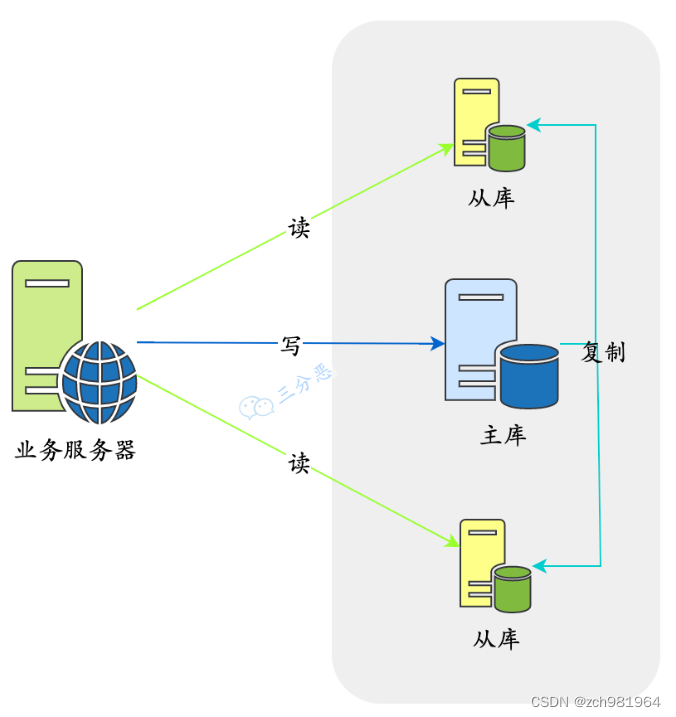
读写分离的基本实现是:
- 数据库服务器搭建主从集群,一主一从、一主多从都可以。
- 数据库主机负责读写操作,从机只负责读操作。
- 数据库主机通过复制将数据同步到从机,每台数据库服务器都存储了所有的业务数据。
- 业务服务器将写操作发给数据库主机,将读操作发给数据库从机。
8.那读写分离的分配怎么实现呢?
将读写操作区分开来,然后访问不同的数据库服务器,一般有两种方式:程序代码封装和中间件封装。
- 程序代码封装
程序代码封装指在代码中抽象一个数据访问层(所以有的文章也称这种方式为 “中间层封装” ) ,实现读写操作分离和数据库服务器连接的管理。例如,基于 Hibernate 进行简单封装,就可以实现读写分离:
目前开源的实现方案中,淘宝的 TDDL (Taobao Distributed Data Layer, 外号:头都大了)是比较有名的。
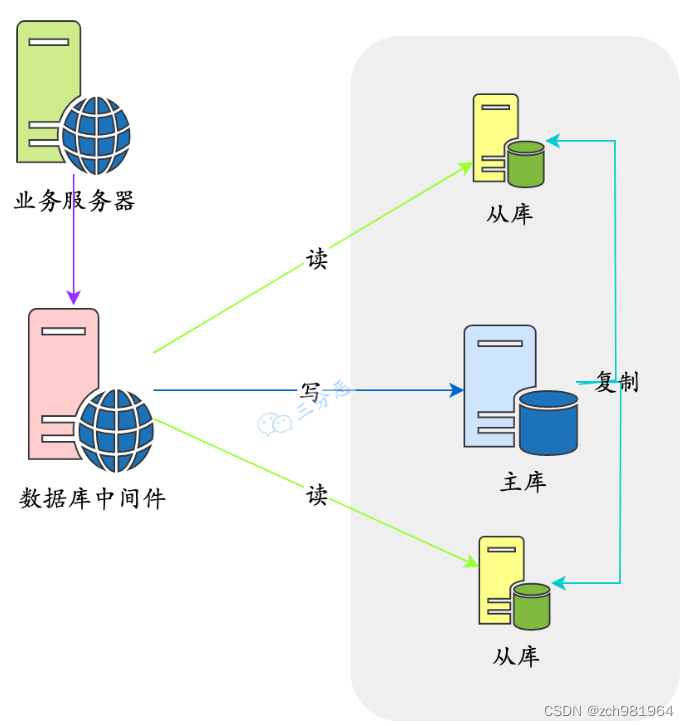
2. 中间件封装
中间件封装指的是独立一套系统出来,实现读写操作分离和数据库服务器连接的管理。中间件对业务服务器提供 SQL 兼容的协议,业务服务器无须自己进行读写分离。
对于业务服务器来说,访问中间件和访问数据库没有区别,事实上在业务服务器看来,中间件就是一个数据库服务器。
其基本架构是:
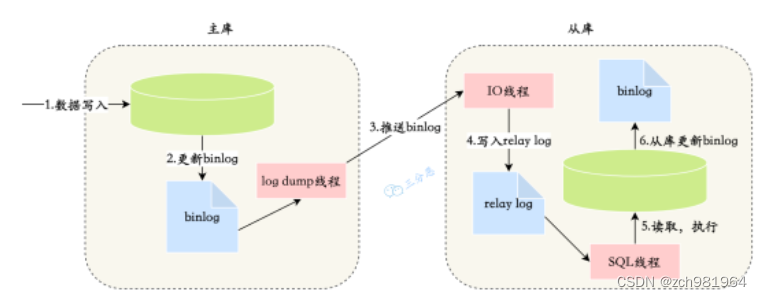
9.主从复制原理了解吗?
- master 数据写入,更新 binlog
- master 创建一个 dump 线程向 slave 推送 binlog
- slave 连接到 master 的时候,会创建一个 IO 线程接收 binlog,并记录到 relay log 中继日志中
- slave 再开启一个 sql 线程读取 relay log 事件并在 slave 执行,完成同步
- slave 记录自己的 binglog
10.主从同步延迟怎么处理?
主从同步延迟的原因
一个服务器开放N个链接给客户端来连接的,这样有会有大并发的更新操作, 但是从服务器的里面读取 binlog 的线程仅有一个,当某个 SQL 在从服务器上执行的时间稍长 或者由于某个 SQL 要进行锁表就会导致,主服务器的 SQL 大量积压,未被同步到从服务器里。这就导致了主从不一致, 也就是主从延迟。
主从同步延迟的解决办法
解决主从复制延迟有几种常见的方法:
-
写操作后的读操作指定发给数据库主服务器
例如,注册账号完成后,登录时读取账号的读操作也发给数据库主服务器。这种方式和业务强绑定,对业务的侵入和影响较大,如果哪个新来的程序员不知道这样写代码,就会导致一个 bug。 -
读从机失败后再读一次主机
这就是通常所说的 “二次读取” ,二次读取和业务无绑定,只需要对底层数据库访问的 API 进行封装即可,实现代价较小,不足之处在于如果有很多二次读取,将大大增加主机的读操作压力。例如,黑客暴力破解账号,会导致大量的二次读取操作,主机可能顶不住读操作的压力从而崩溃。 -
关键业务读写操作全部指向主机,非关键业务采用读写分离
例如,对于一个用户管理系统来说,注册 + 登录的业务读写操作全部访问主机,用户的介绍、爰好、等级等业务,可以采用读写分离,因为即使用户改了自己的自我介绍,在查询时却看到了自我介绍还是旧的,业务影响与不能登录相比就小很多,还可以忍受。
参考书籍(访问密码: 6798):
深入浅出MySQL++数据库开发、优化与管理维护+第2版+唐汉明.pdf: https://url31.ctfile.com/f/40632231-735785515-c1ff5b?
高性能MySQL(第3版).pdf: https://url31.ctfile.com/f/40632231-735785459-780d3e?
SQL查询的艺术.pdf: https://url31.ctfile.com/f/40632231-735785297-8c1d65?
MySQL技术内幕 InnoDB存储引擎 第2版.pdf:https://url31.ctfile.com/f/40632231-735784839-1a2df2?
SQLite 权威指南.pdf: https://url31.ctfile.com/f/40632231-735784840-d76185?
MySQL必知必会.pdf:https://url31.ctfile.com/f/40632231-735784664-7f7ca8?
MongoDB权威指南.pdf:https://url31.ctfile.com/f/40632231-735784624-2dafdf?
![[附源码]Python计算机毕业设计Django常见Web漏洞对应POC应用系统](https://img-blog.csdnimg.cn/3e56d44262cb4c6d9150eaaca452156a.png)

![[附源码]SSM计算机毕业设计学生档案管理系统JAVA](https://img-blog.csdnimg.cn/17b78f408ce44f82ad68b9f603d58753.png)



![[附源码]计算机毕业设计springboot基于Java酒店管理系统](https://img-blog.csdnimg.cn/ff90b6abd5af4748a6580e4ad0bc5a7f.png)


