1.介绍
论文:Image-to-Image Translation with Conditional Adversarial Networks
论文地址:https://arxiv.org/abs/1611.07004
图像处理的很多问题都是将一张输入的图片转变为一张对应的 输出图片,比如灰度图、彩色图之间的转换、图像自动上色等。
什么是 pix2pixGAN:pix2pixGAN主要用于图像之间的转换,又称图像翻译。作者证明了这种方法在从标签图合成照片(synthesizing photos from label map)、从边缘图重建对象(reconstructing objects from edge maps)以及给图像上色(colorizing images)等多种任务中是有效的。
与普通GAN的区别:普通GAN的生成器G输入的是随机向量(噪声),输出是图像; 判别器D接收的输入是图像(生成的或是真实的),输出是对或者错 。这样G和D联手就能输出真实的图像。Pix2pixGAN本质上是一个cGAN,图片x作为此cGAN的条件, 输入到生成器G中。G的输出是生成的图片G(x)。 D则需要分辨出{x,G(x)}和{x, y}。其中x是需要转换的图片,y是x对应的真实图片。

2.生成器与判别器的设计
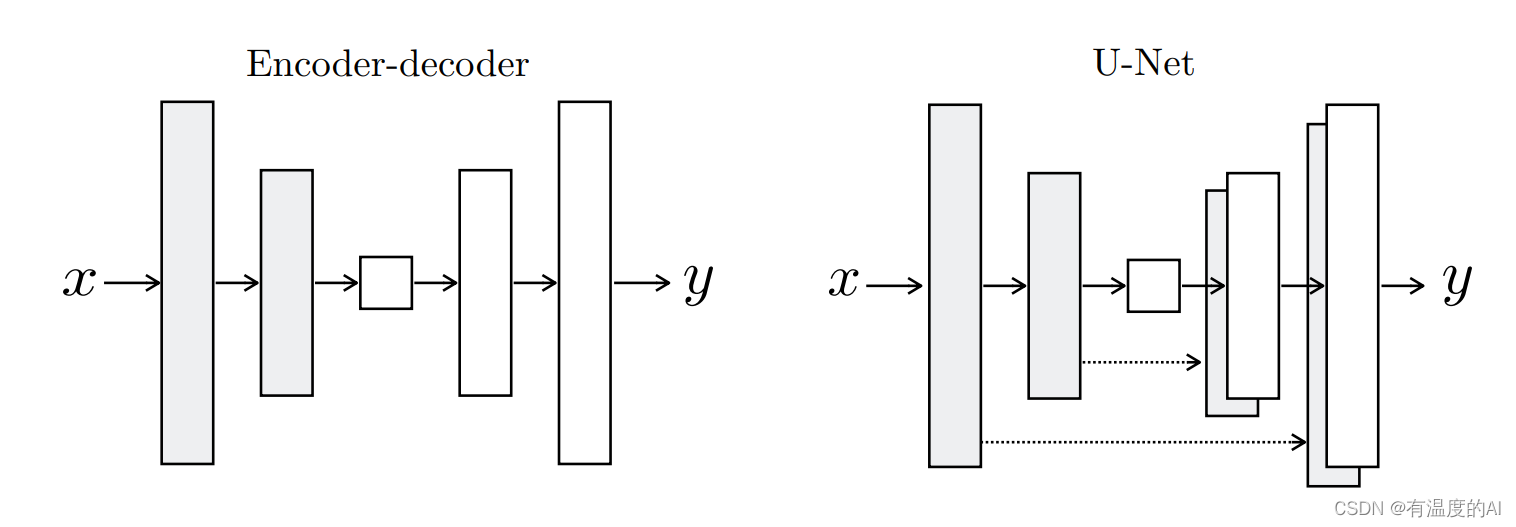
生成器G的设计:生成器G采用了Encoder-Decoder模型,参考U-Net的结构。
判别器D的设计:D中要输入成对的图像。判别器D的输入与cGAN中的不同,因为除了要生成真实图像之外,还要保证生成的图像和输入图像是匹配的。Pix2Pix论文中将判别器D实现为Patch-D,所谓Patch,是指无论生成的图像有多大,将其切分为多个固定大小的Patch输入进D去判断。这样设计的好处是:D的输入变小,计算量小,训练速度快。
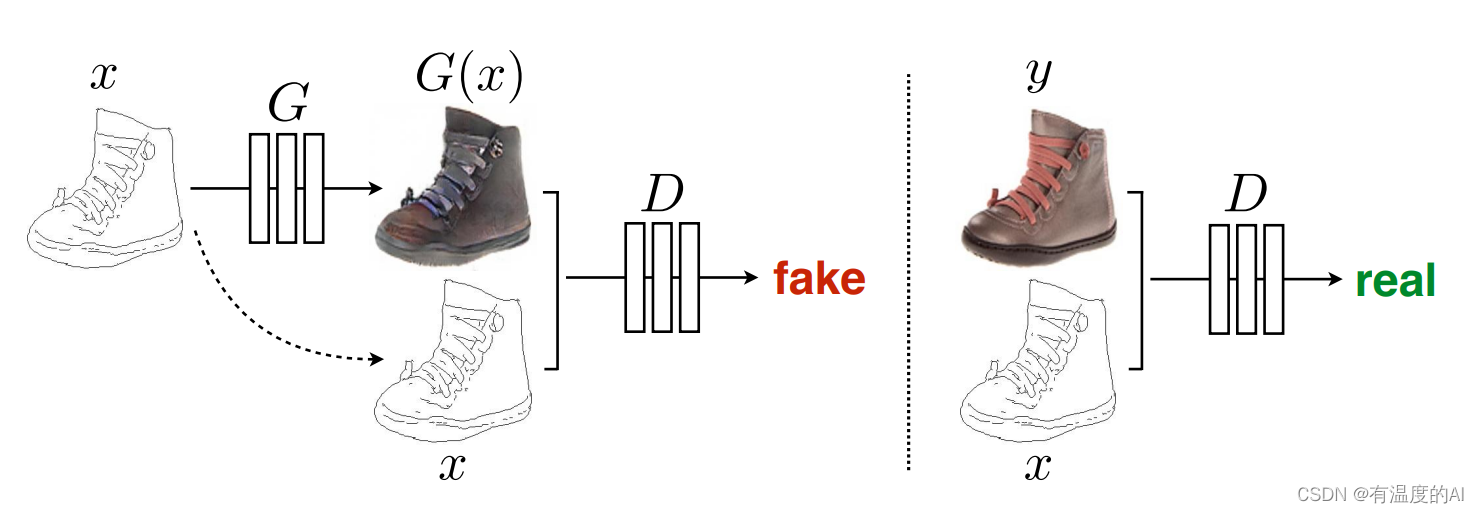

3.损失函数
D网络损失函数(使用二元交叉熵损失BCELoss)
输入真实的成对图像希望判定为1,即{x, y};输入原图与生成图像希望判定为0,即{x,G(x)}。
G网络损失函数(使用二元交叉熵损失BCELoss和L1loss)
L1loss保证输入和输出之间的一致性;
输入原图与生成图像希望判定为1,即{x,G(x)}。
4.模型搭建
import torch
from PIL import Image
import os
import torch.nn as nn
import torch.nn.functional as F
from torchvision import transforms, datasets, utils
import matplotlib.pyplot as plt
import numpy as np
import torch.optim as optim
from torchvision.datasets import ImageFolder
from torch.utils.data.dataset import Dataset
import tqdm
import glob
imgs_path = glob.glob('D:\cnn\All_Classfication/base_data/train/*.jpg') #获取训练集中的.jpg图片
annos_path = glob.glob('D:\cnn\All_Classfication/base_data/train/*.png') #获取训练集中的.png图片
transform = transforms.Compose([transforms.ToTensor(),
transforms.Resize((256, 256)),
transforms.Normalize(mean=0.5, std=0.5)]) #Normalize为转化到-1~1之间
# 定义数据读取
class GANDataset(Dataset):
def __init__(self, imgs_path, annos_path): #初始化
super(GANDataset, self).__init__()
self.imgs_path = imgs_path #定义属性
self.annos_path = annos_path#定义属性
def __len__(self):
return len(self.imgs_path)
def __getitem__(self, index): #对数据切片
img_path = self.imgs_path[index]
anno_path = self.annos_path[index]
# 从文件中读取图像
jpg = Image.open(img_path)
jpg = transform(jpg)
png = Image.open(anno_path)
png = png.convert('RGB') #因为anno_path为单通道图片,使用convert方法还原回三通道
png = transform(png)
return jpg, png
train_dataset = GANDataset(imgs_path, annos_path) #创建dataset
dataloader = torch.utils.data.DataLoader(train_dataset, batch_size=4, shuffle=True)
jpg_batch, png_batch = next(iter(dataloader)) #查看,返回一个批次的训练数据
# print(jpg_bath.shape)
# print(png_bath.shape)
# 查看训练集
# plt.figure(figsize=(8, 12))
# for i, (anno, img) in enumerate(zip(png_batch[:3], jpg_batch[:3])): #zip代表元组
# # 因为dataset返回的数据是tensor,需要转为numpy格式,因为Normalize为转化到-1~1之间,所以加1再除以2将其转化到0~1之间
# anno = (anno.permute(1, 2, 0).numpy() + 1) / 2
# img = (img.permute(1, 2, 0).numpy() + 1) / 2
# plt.subplot(3, 2, 2*i+1)
# plt.title('input_img')
# plt.imshow(anno)
# plt.subplot(3, 2, 2*i+2)
# plt.title('output_img')
# plt.imshow(img)
# plt.show()
#定义下采样模块
class Downsample(nn.Module):
def __init__(self, in_channels, out_channels):
super(Downsample, self).__init__()
self.conv_relu = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=2, padding=1),
nn.LeakyReLU(inplace=True)
)
self.bn = nn.BatchNorm2d(out_channels)
def forward(self, x, is_bn=True): #is_bn用于确定是否使用bn层,默认为True
x = self.conv_relu(x)
if is_bn:
x = self.bn(x)
return x
#定义上采样模块
class Upsample(nn.Module):
def __init__(self, in_channels, out_channels):
super(Upsample, self).__init__()
self.upconv_relu = nn.Sequential(
nn.ConvTranspose2d(in_channels, out_channels, kernel_size=3, stride=2, padding=1, output_padding=1),
nn.LeakyReLU(inplace=True)
)
self.bn = nn.BatchNorm2d(out_channels)
def forward(self, x, is_drop=False): #is_drop用于确定是否使用drop层,默认为False
x = self.upconv_relu(x)
x = self.bn(x)
if is_drop:
x = F.dropout2d(x)
return x
# 定义生成器,包含6个下采样层,6个上采样层
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.down1 = Downsample(3, 64) #3,256,256 -- 64,128,128
self.down2 = Downsample(64, 128) #64,128,128 -- 128,64,64
self.down3 = Downsample(128, 256) #128,64,64 -- 256,32,32
self.down4 = Downsample(256, 512) #256,32,32 -- 512,16,16
self.down5 = Downsample(512, 512) #512,16,16 -- 512,8,8
self.down6 = Downsample(512, 512) #512,8,8 -- 512,4,4
self.up1 = Upsample(512, 512) #512,4,4 -- 512,8,8
self.up2 = Upsample(1024, 512) #1024,8,8 -- 512,16,16
self.up3 = Upsample(1024, 256) #1024,16,16 -- 256,32,32
self.up4 = Upsample(512, 128) #512,32,32 -- 128,64,64
self.up5 = Upsample(256, 64) #256,64,64 -- 64,128,128
#128,128,128 -- 3,256,256
self.last = nn.ConvTranspose2d(128, 3, kernel_size=3, stride=2, padding=1, output_padding=1)
def forward(self, x):
x1 = self.down1(x)
x2 = self.down2(x1)
x3 = self.down3(x2)
x4 = self.down4(x3)
x5 = self.down5(x4)
x6 = self.down6(x5)
x6 = self.up1(x6, is_drop=True)
x6 = torch.cat([x6, x5], dim=1)
x6 = self.up2(x6, is_drop=True)
x6 = torch.cat([x6, x4], dim=1)
x6 = self.up3(x6, is_drop=True)
x6 = torch.cat([x6, x3], dim=1)
x6 = self.up4(x6)
x6 = torch.cat([x6, x2], dim=1)
x6 = self.up5(x6)
x6 = torch.cat([x6, x1], dim=1)
x6 = torch.tanh(self.last(x6))
return x6
# 定义判别器 将条件(anno)与图片(生成的或真实的)同时输入到判别器中进行判定 concat
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.down1 = Downsample(6, 64)
self.down2 = Downsample(64, 128)
self.conv1 = nn.Conv2d(128, 256, 3)
self.bn = nn.BatchNorm2d(256)
self.last = nn.Conv2d(256, 1, 3)
# 判别器的输入为成对的图片,anno为结构图,img为真实的或生成的图片
def forward(self, anno, img):
x = torch.cat([anno, img], dim=1) #batch_size,6,256,256
x = self.down1(x, is_bn=False) #batch_size,64,128,128
x = self.down2(x) #batch_size,128,64,64
x = F.dropout2d(self.bn(F.leaky_relu(self.conv1(x)))) #batch_size,256,62,62
x = torch.sigmoid(self.last(x)) #batch_size,1,60,60
return x
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
gen = Generator().to(device)
dis = Discriminator().to(device)
# 判别器优化器
d_optimizer = torch.optim.Adam(dis.parameters(), lr=1e-4, betas=(0.5, 0.999)) #通过减小判别器的学习率降低其能力
# 生成器优化器
g_optimizer = torch.optim.Adam(gen.parameters(), lr=1e-3, betas=(0.5, 0.999))
# 绘图函数,将每一个epoch中生成器生成的图片绘制
def gen_img_plot(model, epoch, test_anno, test_real): # model为Generator,test_anno为结构图,test_real为真实图片
generate = model(test_anno).permute(0, 2, 3, 1).detach().cpu().numpy() #detach()截断梯度,将通道维度放在最后
test_anno = test_anno.permute(0, 2, 3, 1).cpu().numpy() #1,3,256,256 -- 1,256,256,3
test_real = test_real.permute(0, 2, 3, 1).cpu().numpy() #1,3,256,256 -- 1,256,256,3
plt.figure(figsize=(10, 10))
title = ['Input image', 'Ground truth', 'Generate image']
display_list0 = [test_anno[0], test_real[0], generate[0]]
for i in range(3):
plt.subplot(3, 3, i + 1)
plt.title(title[i])
plt.imshow((display_list0[i]+1)/2) #从-1~1 --> 0~1
plt.axis('off')
display_list1 = [test_anno[1], test_real[1], generate[1]]
for i in range(3,6):
plt.subplot(3, 3, i + 1)
# plt.title(title[i])
plt.imshow((display_list1[i-3]+1)/2) #从-1~1 --> 0~1
plt.axis('off')
display_list2 = [test_anno[2], test_real[2], generate[2]]
for i in range(6,9):
plt.subplot(3, 3, i + 1)
# plt.title(title[i])
plt.imshow((display_list2[i-6]+1)/2) #从-1~1 --> 0~1
plt.axis('off')
# plt.show()
plt.savefig('./imageP2P/image_at_{}.png'.format(epoch))
test_imgs_path = glob.glob('D:\cnn\All_Classfication/base_data/val/*.jpg') #获取验证集中的.jpg图片
test_annos_path = glob.glob('D:\cnn\All_Classfication/base_data/val/*.png') #获取验证集中的.png图片
test_dataset = GANDataset(test_imgs_path, test_annos_path) #创建dataset
test_dataloader = torch.utils.data.DataLoader(test_dataset, batch_size=4, shuffle=True)
imgs_batch, annos_batch = next(iter(test_dataloader)) #查看,返回一个批次的测试数据
# print(jpg_bath.shape)
# print(png_bath.shape)
# 查看测试集
# plt.figure(figsize=(8, 12))
# for i, (anno, img) in enumerate(zip(annos_batch[:3], imgs_batch[:3])): #zip代表元组
# # 因为dataset返回的数据是tensor,需要转为numpy格式,因为Normalize为转化到-1~1之间,所以加1再除以2将其转化到0~1之间
# anno = (anno.permute(1, 2, 0).numpy() + 1) / 2
# img = (img.permute(1, 2, 0).numpy() + 1) / 2
# plt.subplot(3, 2, 2*i+1)
# plt.title('input_img')
# plt.imshow(anno)
# plt.subplot(3, 2, 2*i+2)
# plt.title('output_img')
# plt.imshow(img)
# plt.show()
annos_batch, imgs_batch = annos_batch.to(device), imgs_batch.to(device)
# 定义cGAN损失
loss_fn = torch.nn.BCELoss() # 二元交叉熵损失
LAMBDA = 7 #L1损失的权重
# pix2pixGAN训练
D_loss = []
G_loss = []
for epoch in range(100):
D_epoch_loss = 0 #记录判别器每个epoch损失
G_epoch_loss = 0 #记录生成器每个epoch损失
count = len(dataloader) #len(dataloader)返回批次数
count1 = len(train_dataset) #len(train_dataset)返回样本数
for step, (imgs, annos) in enumerate(tqdm.tqdm(dataloader)): #注意dataloader输出的图片和标签的顺序
annos = annos.to(device)
imgs = imgs.to(device)
#-------------------------------------#
# 判别器损失
d_optimizer.zero_grad()
disc_real_output = dis(annos, imgs) #输入真实的成对图像希望判定为1,即{x, y}
d_real_loss = loss_fn(disc_real_output, torch.ones_like(disc_real_output, device=device))
d_real_loss.backward() # 反向传播
gen_output = gen(annos) #结构图通过生成器生成图片
disc_gen_output = dis(annos, gen_output.detach()) #输入原图与生成图像希望判定为0,即{x,G(x)}
d_fake_loss = loss_fn(disc_gen_output, torch.zeros_like(disc_gen_output, device=device))
d_fake_loss.backward() # 反向传播
# 判别器总损失
disc_loss = d_real_loss + d_fake_loss
d_optimizer.step() #优化
# -------------------------------------#
# -------------------------------------#
# 生成器损失
g_optimizer.zero_grad()
disc_gen_out = dis(annos, gen_output) #输入原图与生成图像希望判定为1,即{x,G(x)}
gen_loss_celoss = loss_fn(disc_gen_out, torch.ones_like(disc_gen_out, device=device))
gen_l1_loss = torch.mean(torch.abs(gen_output - imgs)) #L1loss度量生成图像与原结构图之间的距离
# 生成器总损失
gen_loss = gen_loss_celoss + LAMBDA*gen_l1_loss
gen_loss.backward() #反向传播
g_optimizer.step() #优化
# -------------------------------------#
with torch.no_grad():
D_epoch_loss += disc_loss.item() # 将每一个批次的loss累加
G_epoch_loss += gen_loss.item() # 将每一个批次的loss累加
with torch.no_grad():
D_epoch_loss /= count # 求得每一轮的平均loss
G_epoch_loss /= count # 求得每一轮的平均loss
D_loss.append(D_epoch_loss)
G_loss.append(G_epoch_loss)
print('epoch:', epoch)
gen_img_plot(gen, epoch, annos_batch, imgs_batch)
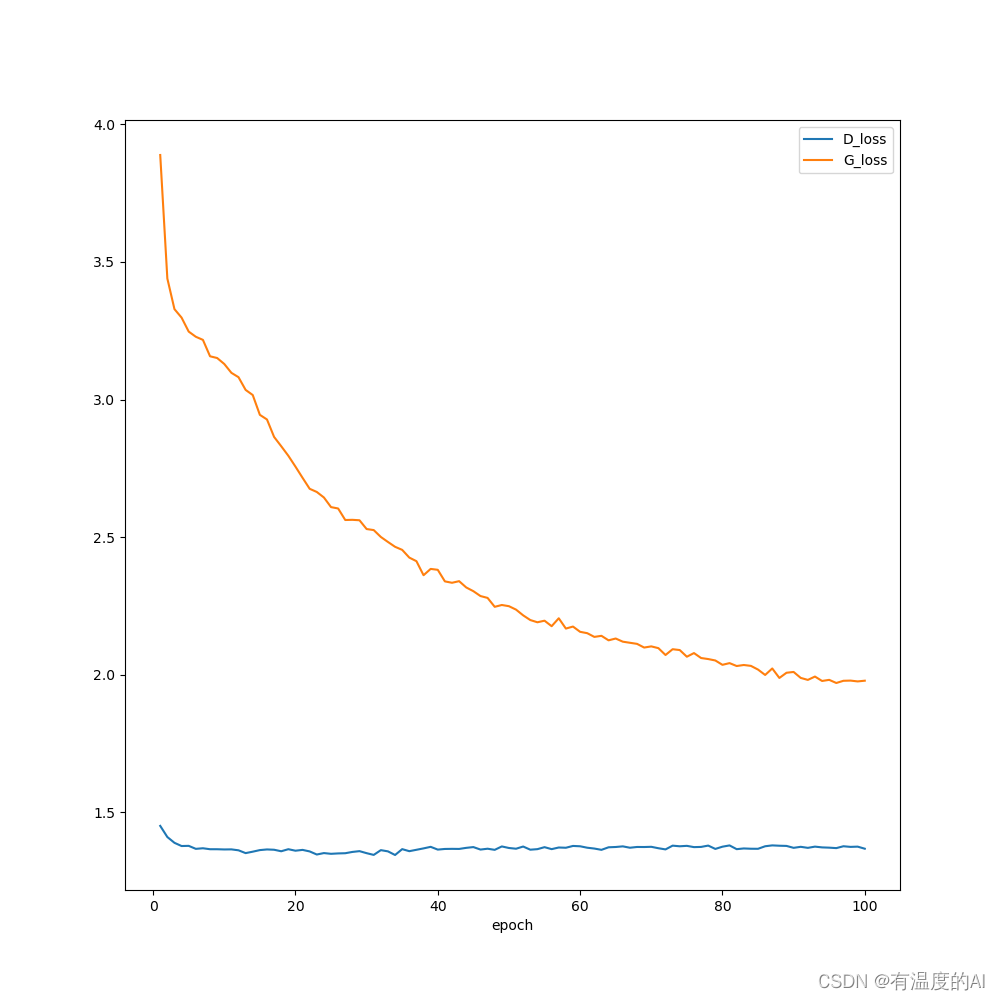
plt.figure(figsize=(10, 10))
plt.plot(range(1, len(D_loss) + 1), D_loss, label='D_loss')
plt.plot(range(1, len(G_loss) + 1), G_loss, label='G_loss')
plt.xlabel('epoch') # 横轴名称
plt.legend()
plt.savefig('./imageP2P/loss.png') # 保存图片