时间轴
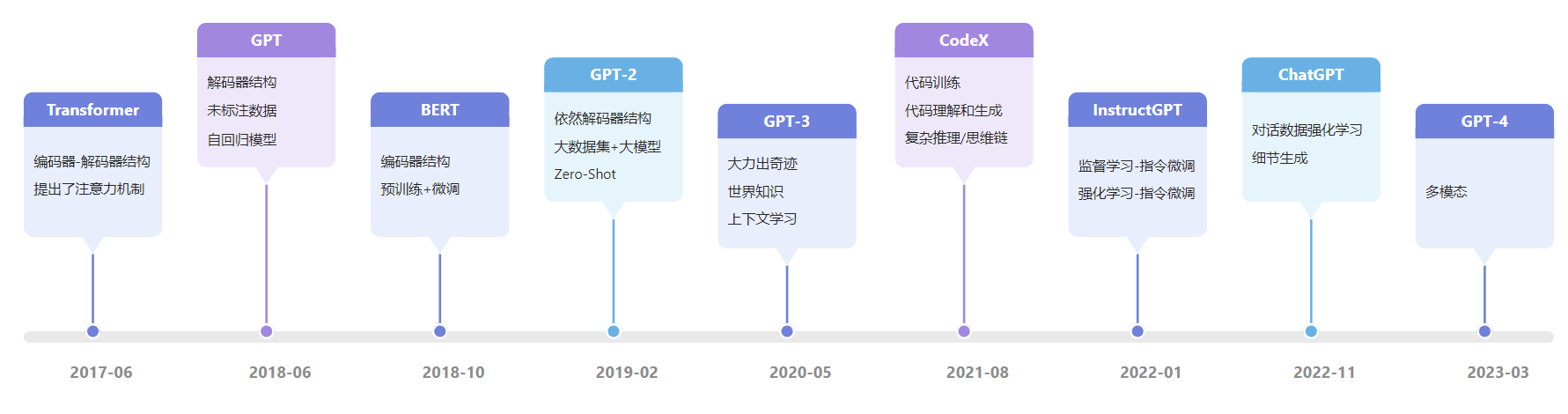
GPT

首先最初版的GPT,来源于论文Improving Language Understanding by Generative Pre-Training(翻译过来就是:使用通用的预训练来提升语言的理解能力)。GPT这个名字其实并没有在论文中提到过,后人将论文名最后三个单词的首字母拿出来,就将其简称为GPT。
读前先问
-
这篇论文大方向的目标是什么?
摘要第一句话就提到,自然语言理解中有很多任务,比如文本蕴涵、问答、情感相似度评估和文档分类等等。据此再深入想一下,其实所有这些任务的根本目的是想让模型理解语言想要表达的意思,并做出相应的回应。 -
这个方向目前有什么问题?
训练模型需要数据,虽然文本语料库很丰富,但是大部分都是未标注的数据,针对特定任务的标注数据很少,导致并不能充分发挥模型的性能。 -
这篇论文要解决什么问题?
大量未标注数据没有得到利用,而少量标注数据又不够用。 -
为什么会有这些问题?
互联网上的各种文本信息太多了,GPT-3的训练数据集就达到了45TB,但是数据标注的成本是很高的,而且有一定的限制(中国人只能标中文数据,不一定能标英文的数据,而图像标注中,中国的猫和外国的猫并没有什么不一样)。(我大二的时候还给达摩院做过外包,干的就是ASR语音识别标注,标一小时的数据好像就几块钱。) -
作者是怎么解决这些问题的?
GPT的解决方案就是先在没有标注的数据上预训练一个语言模型,然后在有标注的数据上再针对特定任务进行微调。在微调期间,还使用了任务感知进行输入的转换(后面详解),尽量减少了对模型架构的修改。
什么是语言模型?
简单讲就是单字接龙。
具体来说就是:给它“任意一段长的上文”,模型会据此生成“下一个字”。
语言模型最常见的应用就是手机输入法,它会根据你当前的输入给出可能的后续输入。
语言模型每次会将预测的新的词再添加到输入序列最后,作为下一次的输入,这也是一种称为自回归的想法。
- 怎么验证论文的解决方法是否有效?
摘要中提到,通过这种预训练+微调的方式可以让模型在特定任务上有巨大的增益,并且在很多自然语言理解的基准测试上都取得了很好的效果,刷新了12项任务中的9项SOTA。
介绍
深度学习模型训练需要大量的标注数据,这实际上限制了其本身在各个领域的发展,而一些研究表明,通过在大量未标注数据上通过无监督学习一个很好的表征,可以提升模型的性能。一个最典型的例子就是词嵌入模型。
怎么样更好的利用未标注数据进行无监督学习?
使用未标注的文本有一些困难:
- 不知道用什么样的优化目标学习文本表征最有效;
- 不知道怎么将学到的文本表征信息传递到下游的子任务。
在这篇论文中,作者就提出了一种两阶段方法,先用未标注数据进行预训练,再用标注数据进行微调。预训练阶段的目标就是通过语言模型学习通用的文本表征,可以尽量无损的迁移到下游任务中。
训练框架
无标签数据无监督预训练
假设我们有一段文本,里面每一个词表示为 U = { u 1 , … , u n } \mathcal{U}=\left\{u_{1}, \ldots, u_{n}\right\} U={u1,…,un},语言模型要根据 i i i前连续 k k k个词 u i − k , … , u i − 1 u_{i-k}, \ldots, u_{i-1} ui−k,…,ui−1预测第 i i i个词 u i u_{i} ui出现的概率,因此目标函数就是最大化似然估计: L 1 ( U ) = ∑ i log P ( u i ∣ u i − k , … , u i − 1 ; Θ ) L_{1}(\mathcal{U})=\sum_{i} \log P\left(u_{i} \mid u_{i-k}, \ldots, u_{i-1} ; \Theta\right) L1(U)=∑ilogP(ui∣ui−k,…,ui−1;Θ)。其中 k k k表示上下文窗口大小的超参数,是模型输入序列的长度,序列越长,网络看到的东西就越多。 Θ \Theta Θ模型采用了Transformer中的解码器,通过随机梯度下降进行训练。
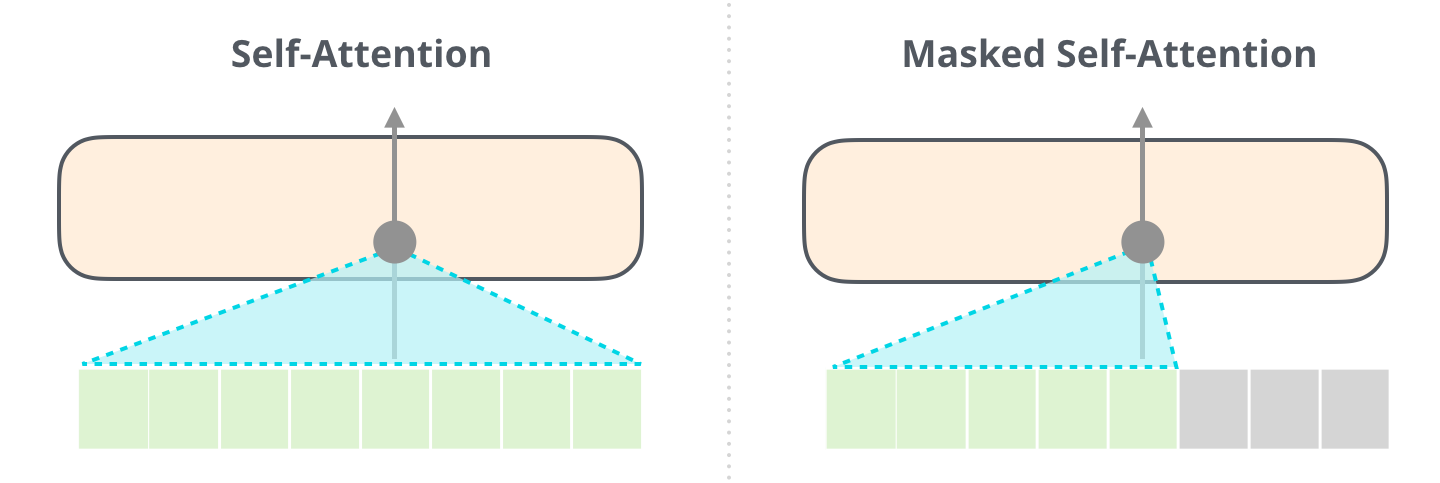
Transformer中编码器与解码器的区别?
编码器在对第i个元素抽取特征时能够看到序列中的所有元素。
解码器因为掩码的存在导致在对第i个元素抽取特征时只能看到当前元素和之前的序列。
详细解释:如果要预测 u u u这个词的概率,就把 u u u之前的 k k k个词拉出来记为 U = ( u − k , … , u − 1 ) U=\left(u_{-k}, \ldots, u_{-1}\right) U=(u−k,…,u−1),然后进行词嵌入投影,再加上一个位置信息编码,就得到第一层的输入: h 0 = U W e + W p h_{0} =U W_{e}+W_{p} h0=UWe+Wp。
接下来要做
n
n
n层一样的Transformer块:
h
i
=
transformer-block
(
h
i
−
1
)
∀
i
∈
[
1
,
n
]
h_{i} =\text{transformer-block}\left(h_{i-1}\right) \forall i \in[1, n]
hi=transformer-block(hi−1)∀i∈[1,n]。
拿到最后一个Transformer块的输出,再做一个Softmax就得到概率分布:
P
(
u
)
=
softmax
(
h
n
W
e
T
)
P(u) =\text{softmax}\left(h_{n} W_{e}^{T}\right)
P(u)=softmax(hnWeT)。
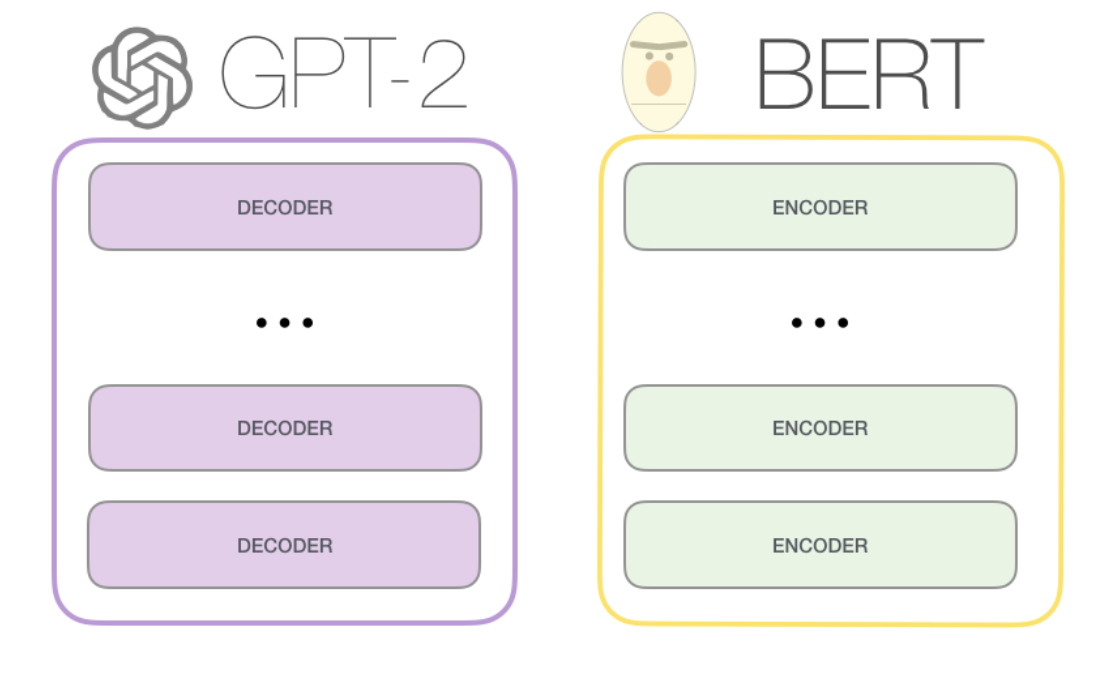
GPT和BERT的区别
● BERT做的任务类似于完形填空,用的是自注意力层,所以在预测的时候既能看到之前的词,也能看到之后的词,对应了Transformer的编码器。GPT在预测的时候只能看到当前词及其之前的词,用的是带掩码的自注意力层,对应了Transformer的解码器。
● 对于目标函数的选取,GPT选择的是一个更难的目标——预测未来,难度要比完形填空更大。(这也是一开始GPT的效果不如BERT的效果的原因之一)
● GPT选择去解决更大更难的问题,因此要出效果更难一些。Transformer和BERT来源于Google,一开始想解决的问题其实都比较小,比如Transformer最开始提出其实是要解决机器翻译的问题,BERT则是将计算机视觉中先预训练模型再微调子任务的套路搬到了自然语言处理中,单纯为了提升模型的效果。
有标签数据的有监督微调
简单讲:给一个长度为 m m m的词序列,然后知道序列的标签是 y y y,以此进行训练。
详细解释:把整个序列放入预训练好的模型中,然后拿最后一个Transformer块的输出 h n m h_{n}^{m} hnm,之后乘以一个输出层 W y W_{y} Wy,最后再做一个Softmax,就得到了预测标签的概率: P ( y ∣ x 1 , … , x m ) = softmax ( h l m W y ) P\left(y \mid x^{1}, \ldots, x^{m}\right)=\operatorname{softmax}\left(h_{l}^{m} W_{y}\right) P(y∣x1,…,xm)=softmax(hlmWy)。微调任务中所有带标签的序列对都输入模型,计算真实标签的概率,然后做最大似然估计: L 2 ( C ) = ∑ ( x , y ) log P ( y ∣ x 1 , … , x m ) L_{2}(\mathcal{C})=\sum_{(x, y)} \log P\left(y \mid x^{1}, \ldots, x^{m}\right) L2(C)=∑(x,y)logP(y∣x1,…,xm)。
在做微调的时候其实有两个目标函数,第一个就是语言模型的目标函数,给定一个序列然后预测序列的下一个词,第二个是给定一个完整的序列,然后预测序列对应的标签。
作者发现,将语言模型作为微调的辅助任务一方面可以提升模型的泛化能力,另一方面可以加速模型收敛。
所以有标签数据的有监督微调最终优化的目标函数就是: L 3 ( C ) = L 2 ( C ) + λ ∗ L 1 ( C ) L_{3}(\mathcal{C}) = L_{2}(\mathcal{C}) + \lambda * L_{1}(\mathcal{C}) L3(C)=L2(C)+λ∗L1(C),其中 λ \lambda λ是超参数。
模型架构
GPT使用了12层带掩码自注意力头的Transformer解码器(维度768,带12个注意力头),掩码可以让模型看不见未来的信息,得到的模型泛化能力更强。序列长度为512,位置编码的长度是3072。模型使用Adam进行优化,GELU作为激活函数,最大学习率是2.5e-4,batchsize为64,训练了100个epoch。
数据使用BPE编码,有40000个字节对,用ftfy library2清理原始文本,标准化了一些标点符号和空格,然后用spaCy tokenizer。
任务感知的输入变换
知道了微调任务是什么形式之后,接下来要考虑的就是怎么样把NLP中各种各样的子任务表示成我们想要的形式——一个序列加一个标签。
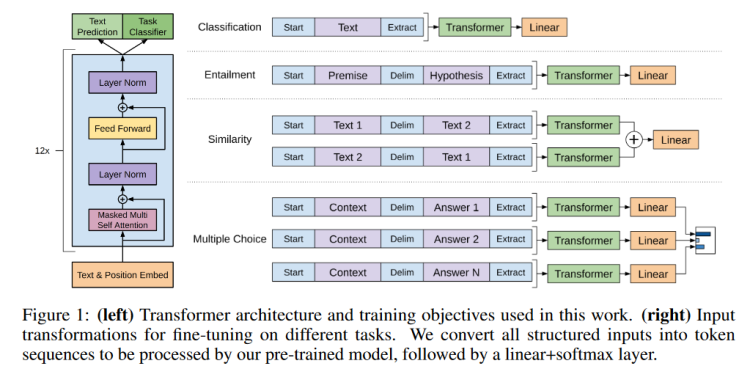
- 文本分类任务:给定一段文本,判断所属的标签。在文本开始前放一个表示开始的token,在结束后放一个表示抽取的token,通过Transformer之后,将最后一个token抽取的特征通过一个线性层,投影到多分类标签。
- 文本蕴含任务:给定一个前提,然后提出一个假设,判断假设的内容是否包含在前提中。在文本开始前放一个表示开始的token,然后两段话中间放一个表示分隔符的token,最后放一个表示抽取的token,同样通过Transformer之后,将最后一个token抽取的特征通过一个线性层,投影到二分类标签。
- 文本相似判断:给定两段话,判断两段话表示的意思是否相似。因为相似是一个对称的关系,A和B相似,那么B和A也是相似的,但是在语言模型中序列是有先后顺序的,所以论文中做了两个序列。第一个序列是Text1在前,Text2在后,第二个序列是Text2在前,Text1在后。两个序列分别通过Transformer之后,将最后一个token抽取的特征加在一起再通过一个线性层,投影到二分类标签。
- 选择题:给定问题和多个选项,选择认为最正确的选项。如果有N个选项,就构造N个序列,问题在前,选项在后。每个序列分别通过Transformer和线性层,给每一个选项算一个置信度,最后算一个Softmax。
虽然每个任务的目标不一样,但是都可以构造成一个序列的形式,然后通过预训练完的Transformer模型,进行下游任务。
实验
无监督训练数据集
在无标签数据无监督预训练阶段,作者使用了BooksCorpus数据集训练语言模型,这个数据集包含了7000多本没有发布的书籍,含有很多长文本,能够让模型学习更长的上下文依赖关系。因为书籍没有发布,所以很难在下游数据集上见到,更能验证模型的泛化能力。
有监督微调数据集
有监督未微调阶段的训练参数大部分跟无监督预训练阶段一致。分类器增加了一个比例为0.1的Dropout层。对于大部分下游任务,学习率设置为6.25e-5,batchsize设置为32。在有监督微调数据集上快速训练了3个epoch。
有监督微调阶段用到的数据集就比较多了,主要包括四块:自然语言推理、问答、语义相似度和分类。
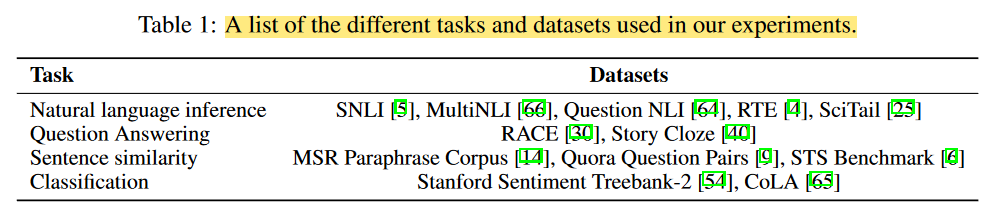
自然语言推理任务上的实验结果:
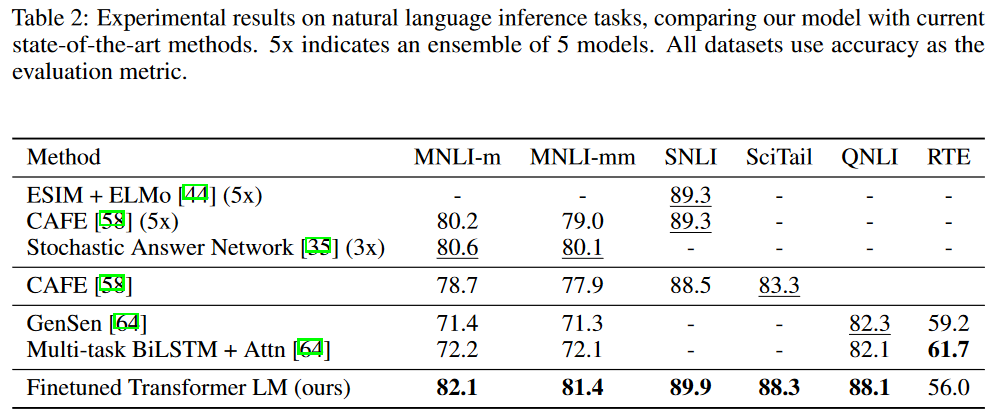
问答和常识推理任务上的实验结果:
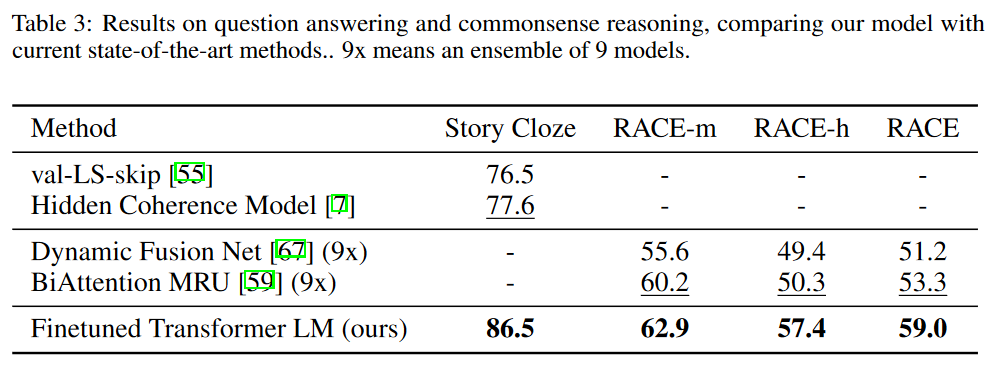
语义相似度和分类任务上的实验结果:
分析
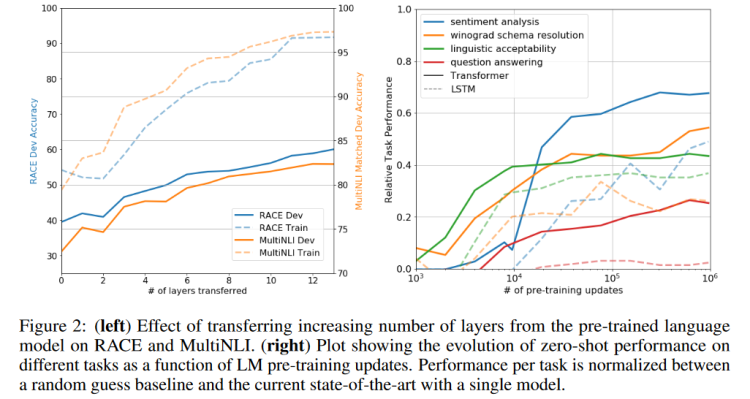
模型层数的影响
越多越强悍。
Zero-Shot能力
直接将预训练好的模型不经过监督微调直接执行任务。
横轴表示训练次数,纵轴表示相对任务表现,0就表示随机猜的基线,1就表示当时的SOTA结果。
在没有见过数据的Zero-Shot任务中,GPT的模型要比基于LSTM的模型稳定,且随着训练次数的增加,GPT的性能也逐渐提升,表明GPT有非常强的泛化能力,能够用到和有监督任务无关的其它NLP任务中。
总结
在这篇论文中,介绍了一种在自然语言理解中,先用未标注数据进行预训练,再用标注数据进行微调的框架。通过在大量文本语料库上进行预训练,模型可以获得令人意想不到的世界知识和处理长文本依赖的能力,并且可以迁移到下游任务中。
其实我觉得重点是发现了GPT的零样本推理能力,这也是后面GPT-2和GPT-3的主要卖点。
GPT-2
GPT发表的4个月后,Google发表了BERT,不同的是,BERT采用的是Transformer的编码器结构,而且BERT做了两个模型,BERT-BASE的模型深度和宽度跟GPT一样,而BERT-LARGE的参数量是BERT-BASE的三倍,效果也比GPT要更好。
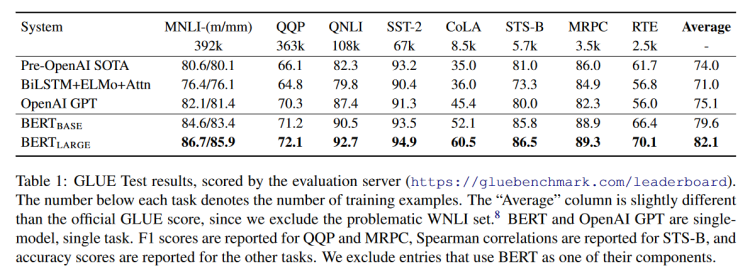
BERT效果更好的原因一方面是模型更大了,另外一方面是采用的数据集也更大了。那OpenAI就很不爽了,估计心想不过就是把模型和数据集都增大了而已,我上我也行。但是单纯把之前的工作拿过来炒冷饭再加点料没什么意思,而且估计是没打过,因为GPT-2的论文里并没有直接把GPT-2的效果跟BERT的效果放在一起对比的内容,所以论文就换了一个思路,转而说明GPT-2具有Zero-Shot的能力。

读前先问
- 这篇论文大方向的目标是什么?
让模型理解语言想要表达的意思,并做出相应的回应。 - 这个方向目前有什么问题?
自然语言处理任务,例如问答、机器翻译、阅读理解和摘要,通常需要对任务特定数据集的监督学习来训练。问题是,一方面会让模型只能处理特定的任务,另外一方面特定的数据集也需要收集和标注。 - 这篇论文要解决什么问题?
如何仅利用未标注数据就能训练出具有多任务处理能力的模型。 - 为什么会有这些问题?
文本信息太多,标注数据太贵。 - 作者是怎么解决这些问题的?
收集了一个包含百万网页的数据集WebText,只在这个数据集上进行预训练,不进行任何监督学习,也能让模型学会各种自然语言处理的任务。 - 怎么验证论文的解决方法是否有效?
摘要中提到,15亿参数的GPT-2模型,在零样本推理的设定下,已经能够在8个测试数据集中的7个取到SOTA的效果。
介绍
现在的机器学习系统虽然在很多任务上的表现都很强悍,但它们都是通过大数据集、大模型和监督学习训练出来的,这就导致这些系统对于数据分布的变化和任务的变化会有些脆弱和敏感。模型的泛化能力不够强,也就是我在任务A数据集上训练的模型没有办法直接用在任务B上,所以现在的系统只能算是一个领域的专家,而不是一个全才。OpenAI的目标一直是做通用人工智能,因此他们也希望训练一个通用的模型,可以执行各种任务而不需要人工再去标注数据集。
作者猜测,在单个数据集上进行单个任务的训练可能是造成当前系统泛化性不强的原因之一。因此,为了提高模型的泛化性和鲁棒性,应该在多个领域的多个任务上同时训练和评估模型的性能,也就是多任务学习。
但是在NLP领域,多任务应用的并不多,更多的还是采用预训练模型微调的套路。这样还是有两个问题:①针对每个下游任务还是需要重新训练,②还是需要收集有标签的数据。
GPT-2还是在做语言模型,但是在做下游任务的时候采用了Zero-Shot的设定,这个设定的意思是说在下游任务中不需要修改模型架构,不需要任何的标注信息,也不需要重新训练。
方法
GPT-2和GPT采用的模型架构是一样的,不同点在于对下游任务数据的处理。GPT中将下游任务的数据进行了标注和处理,加入了一些特殊的token表示开始、分隔和提取,这些token在预训练阶段模型是没有见过的,因此微调阶段模型重新训练之后才会认识。
在Zero-Shot的设定下,做下游任务时模型不能再被调整,因此就没有办法再引入一些新的token。换句话讲,下游任务的输入在预训练阶段应该都见过,这就要求模型的输入在形式上要更接近人类的自然语言。
在语言模型中,只有一个学习任务,给定输入来预测输出的概率: p ( o u t p u t ∣ i n p u t ) p(output|input) p(output∣input)。通用系统应该能够执行许多不同的任务,即使输入相同,但是任务不同,输出应该也是不同的,因此它的目标就变成了给定输入和任务来预测输出的概率: p ( o u t p u t ∣ i n p u t , t a s k ) p(output|input, task) p(output∣input,task)。
这个地方作者给了两个例子:
- 机器翻译。如果你想将英语翻译成法语,那么输入可以表达为:(translate to french, english text, french text)。这个输入就是prompt,也可以叫提示词。
- 阅读理解。输入可以表达为:(answer the question, document, question, answer)。
此方法并不是GPT-2论文中首次提出的,至于为什么可以这么做,作者也花了很长一段去解释。大概意思就是说,如果你的模型足够强大,见过的语料足够多,那么它就可以理解提示词表达的意思。另外一个原因可能是与这些提示词类似的表达原本就在训练语料中出现过,因此模型已经见过多次了。

训练数据集
作者希望训练一个通用的模型,因此数据集也必须包含各种领域的各种任务。
Common Crawl是一个公开的网页抓取项目,它从互联网上获取各种各样近乎无限的文本,但是数据质量太差,信噪比太低,毕竟很多网页中的信息是没有高质量文本的。
GPT-2一开始也在Common Crawl数据集上做过实验,但是结果并不好,因此最终并没有采用这个数据集,而且自己又搞了一个网页爬虫,去爬了Reddit。至于Common Crawl,后面在训练GPT-3的时候还是采用了的。
GPT-2的训练数据集采用的是Reddit,这是一个新闻聚合平台,它的形式是每个人都可以提交自己感兴趣的网页,然后别的用户可以投票,也可以发表自己的意见,投票会产生一个叫karma的东西,karma越高说明越多人觉得这个网页有价值。GPT-2中就将至少有3个karma的网页都爬下来,有4千5百万个链接,整理成了一个文本数据集WebText,其中包含了8百万篇文档,一共有40GB。数据集也做了一些清洗,去掉了维基百科的文档,因为这些内容可能和测试集数据有重叠。
模型
有了更大的数据集之后,就可以训练更大的模型了,作者设计了4个模型。
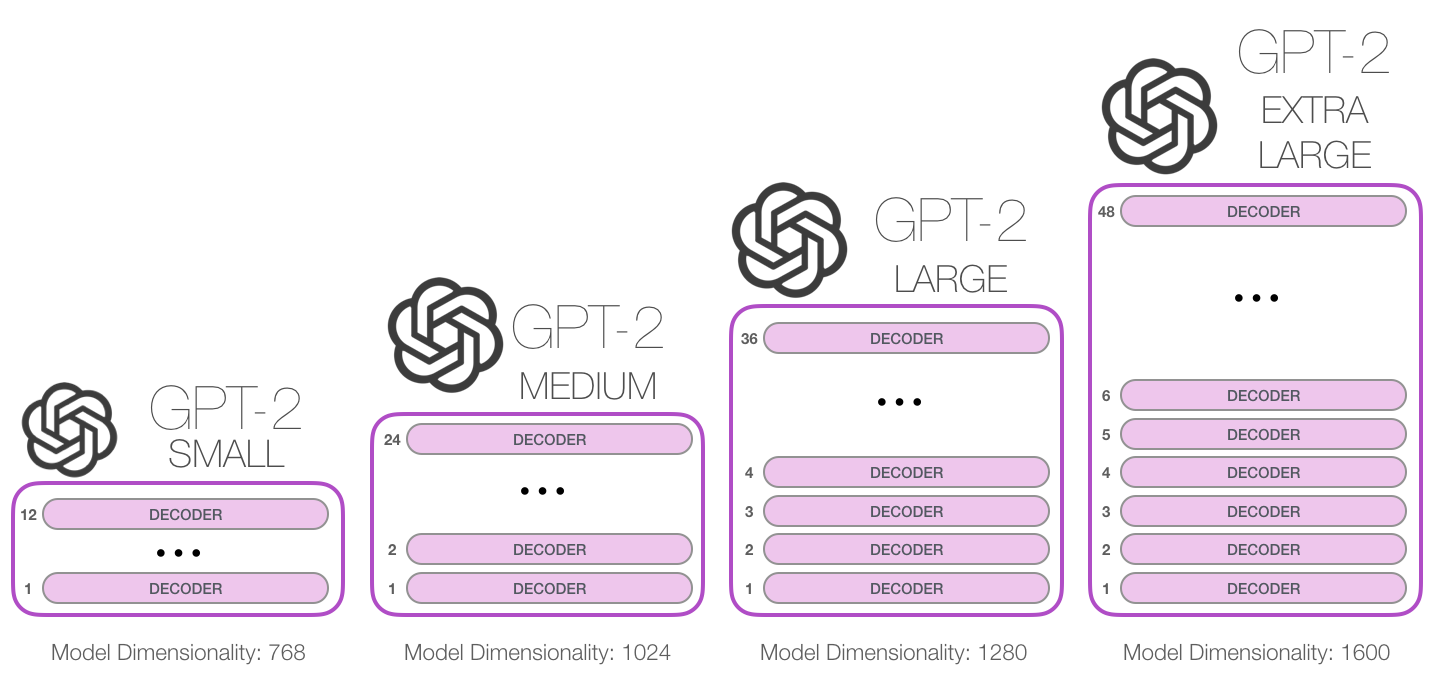
第一个模型的规模其实跟GPT是一样的,也跟BERT-BASE是一样的,第二个模型的规模就跟BERT-LARGE是一样的,在此基础上,作者又训练了两个更大的模型。
实验
GPT-2的实验并没有直接跟GPT或BERT进行对比,估计是比不过,但是它换了一个思路,发现GPT-2的Zero-Shot能力非常强,因此实验这部分GPT-2对比的都是别的同样做Zero-Shot的工作。
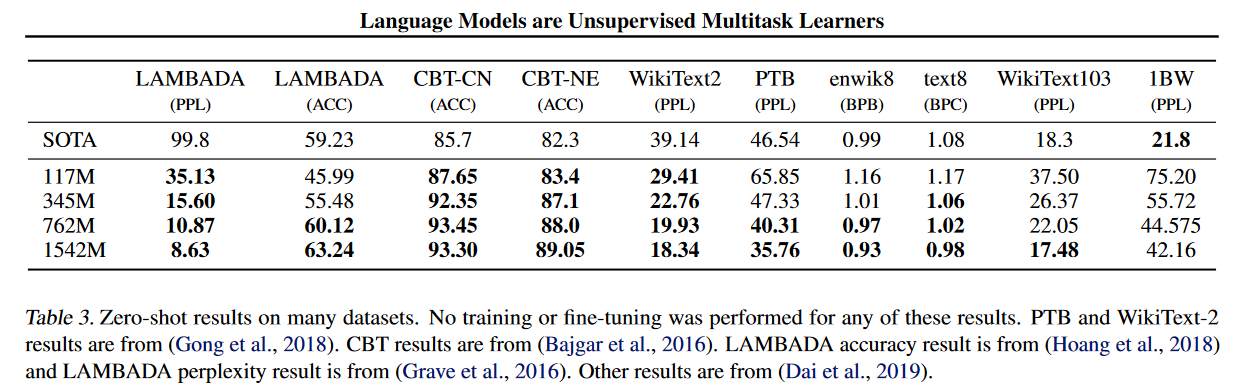
当然针对GPT中的几个任务:阅读理解、翻译、摘要和问答,GPT2中也还是做了对应的实验的。横轴表示的模型的规模,纵轴表示相应任务的指标。可以发现GPT-2在前面三个任务上的表现还算不错,在问答任务上还差一点意思。但是可以发现的话,随着模型规模的增大,效果也是在上升的,因此还是有很大的提升空间。

总结
GPT-2这篇论文证明了,在足够大也多样化的数据集上无监督训练的语言模型,依然能够在多个领域和数据集上表现良好,即使是在Zero-Shot的设定下,8个测试任务中也有7个达到了SOTA的效果。这也一下打通了GPT系列的任督二脉,到了GPT-3就开始狂飙了。
GPT-3
GPT-2虽然提出发现了一个非常有意思的现象,也就是预训练模型具有Zero-Shot能力,但是它的效果还是差强人意,因此GPT-3就是为了解决GPT-2效果不大行的问题。GPT-3在Zero-Shot的设定上也退了一步,并没有追求完全的Zero-Shot,从论文题目上也可以看出来,它追求的是Few-Shot。Few-Shot的意思是说,提供少量的学习样例,就可以让模型掌握新的知识。
GPT-3是一篇技术报告,并不是论文。(那我们就跳过读前先问了)

摘要
OpenAI训练一个名叫GPT-3的自回归语言模型,有1750亿个可学习的参数,比之前任何非稀疏的语言模型要大了10倍。因为模型规模巨大,下游任务如果还要微调的话,成本会非常高,因此GPT-3对于所有的子任务,都不用做任何的梯度更新或微调。GPT-3在很多NLP的数据集上取得了很好的成绩,包括翻译、问答、完形填空等等,并且可以通过Few-Shot学会新的任务。
介绍
背景:近几年在NLP领域预训练模型+下游任务微调的模式越来越流行,但是这有一个最大的限制:下游任务需要标注数据集和微调。
但是去掉这个限制是有必要的:
- 从实际应用的角度来看,每一项下游任务都需要大量的标注数据集,但是下游任务数不胜数,如果每个任务都要收集数据集并微调的话,耗时耗力也不可持续;
- 在下游任务上微调之后的效果好并不一定能说明预训练的大模型具有泛化性,有可能是过拟合了预训练数据集中包含的一部分微调任务的数据,导致在微调任务上的效果是比较好的。但是同一个任务换一个语种,可能效果就没有那么好了。因此,如果下游任务不允许做微调,那么拼的就是预训练模型的泛化性;
- 从人类的角度看,我们去做一个新的任务时并不需要巨大的数据集数据集,可能给一两个例子看一看就学会了。
作者提出了这些问题之后,就给出了自己的解决方案:Few-Shot。
GPT-3是一个有1750亿参数的模型,然后作者还训练了一系列不同大小的模型来进行对比,对于每个任务,采用三种办法进行评估:
- Few-Shot:对于每个任务,提供10~100个参考样例;
- One-Shot:对于每个任务,只提供1个参考样例;
- Zero-Shot:对于每个任务,不提供任何参考样例。
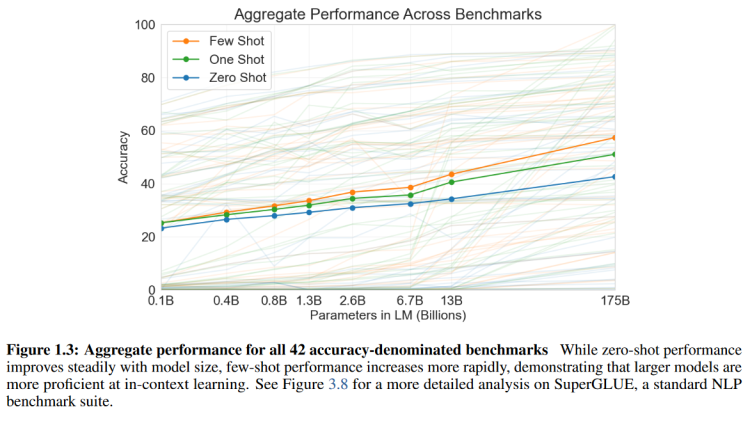
x x x轴表示的是语言模型的参数量大小, y y y轴是准确率,图片中的虚线是子任务的指标,实线是所有任务的平均。从一些虚线中也可以看出,很多任务的能力都是在模型达到了一定规模之后才迅速提升的,也就是涌现。
方法
在方法这一块首先对比了一下传统的微调和Few-Shot、One-Shot、Zero-Shot的区别。


模型架构
GPT-3的模型架构跟GPT-2是一样的,还是Transformer的解码器结构,然后也做了一丢丢修改,比如换用了Sparse Transformer。
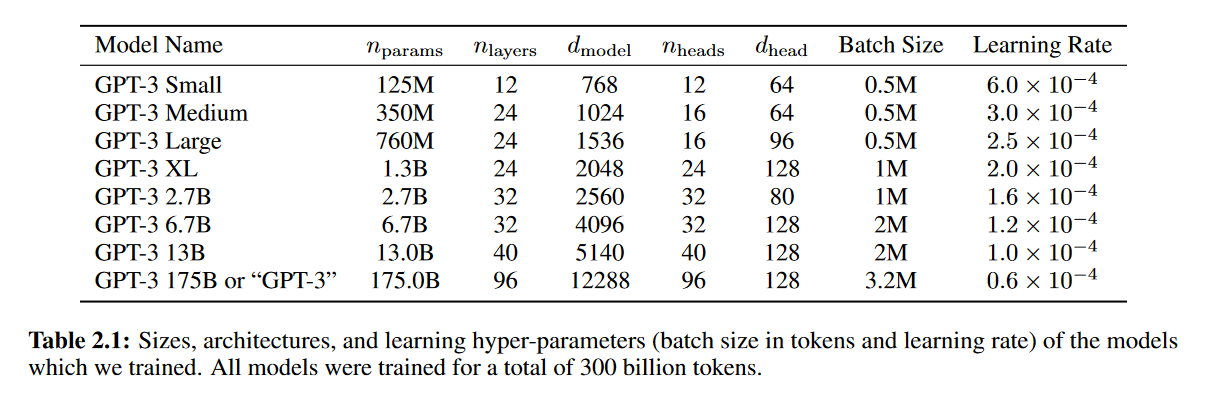
这些参数怎么定出来的?作者说他是按照另外一篇论文里的缩放原则,增加层数的时候增加了宽度,因为计算复杂度跟宽度是平方关系,跟层数是线性关系,但整体来说GPT-3的模型是比较偏扁一点的。
训练数据
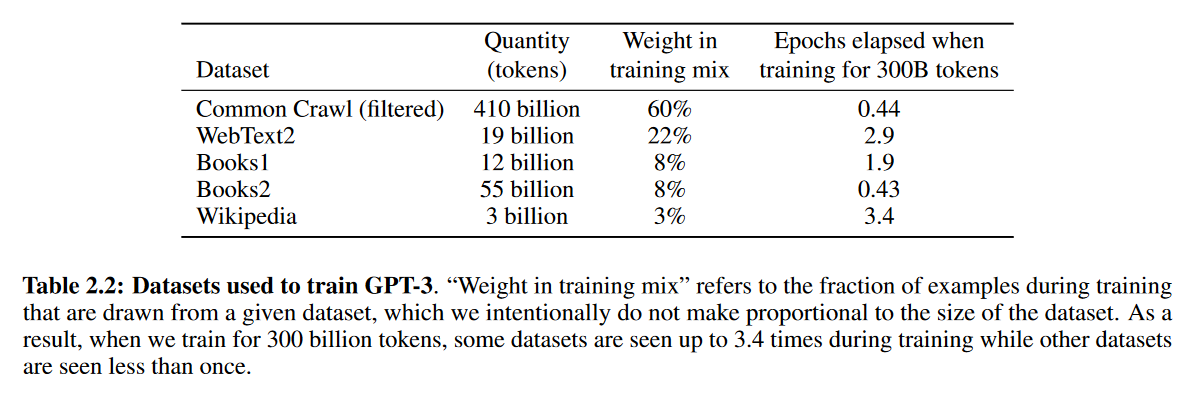
基于CommonCrawl,但是做了一些处理:
- 将CommonCrawl的样本作为负例,之前训练GPT2的数据集作为正例,训练一个分类模型,然后再将这个模型应用于CommonCrawl,如果一篇文章的得分偏向于正例的话,就认为这个网页内容是高质量的;
- 在数据集内部和跨数据集之间,做了文档级的模糊去重;
- 又加入了一些收集的高质量数据集,提升数据集的多样性;
训练过程
(接下来就是最可气的部分——模型训练过程,1750亿参数的模型分布式训练,肯定是非常麻烦的,我当时分布式训练一个35亿参数的模型花了差不多一个月的时间研究,然后中间还有各种坑,结果他在论文里6、7句话就把训练过程一笔带过了。)
根据前人的研究,越大的模型应该使用越大的batchsize,但是需要更小的学习率。训练过程中也采用了数据并行和模型并行,然后是在一个高带宽的V100 GPU集群上训练的。

然后他说是在附录中有详细的参数,但真的就只是参数,说了下Adam的参数、学习率和窗口大小等等,也没有说具体分布式训练这一块怎么切分,或者用了什么框架。

实验结果
GPT-3有特别多的作者,这是这些作者并不是挂个名而已的,实际上在论文的最后就有说明每一位作者的贡献,大部分人都是来对GPT-3做各种实验的,因此实验结果这一部分特别多。
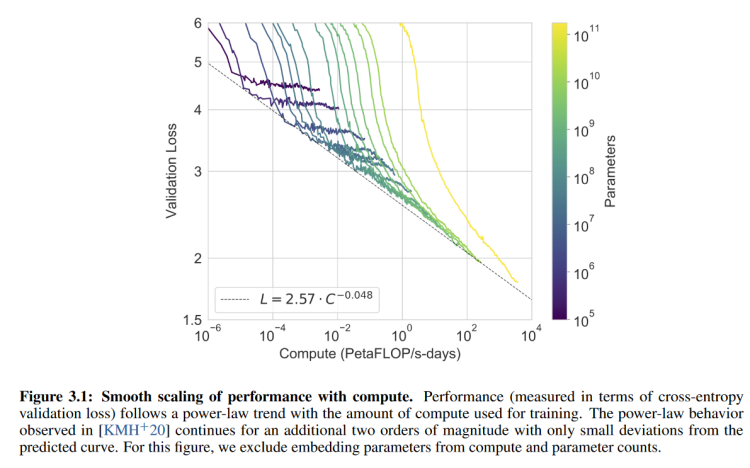
不同大小的模型在训练的时候跟计算量的关系。x轴表示的是计算量,y轴表示的是验证集的损失,每一根线表示的是一个参数的模型。
完形填空
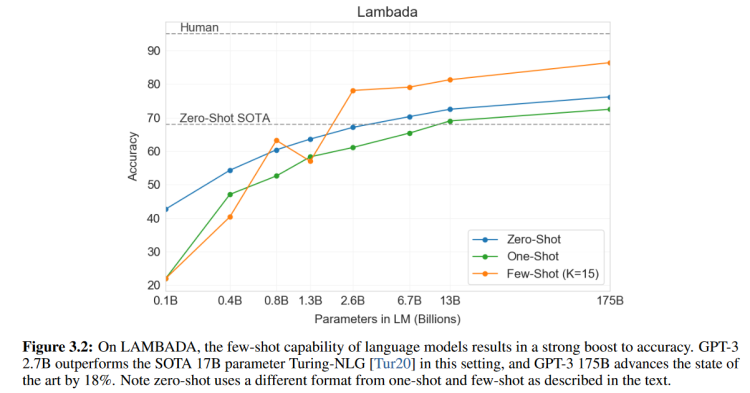
x轴表示的是模型参数规模,y轴表示的是在Lambada测试集上的准确率。但是有几个奇怪的地方我没有想通:
- 为什么模型参数量比较小的时候,Few-Shot和One-Shot的效果比Zero-Shot要差那么多?
- 为什么One-Shot的效果一直比Zero-Shot的效果要差?
- 1.3B的Few-Shot为什么会突然间出现一个波动?
问答
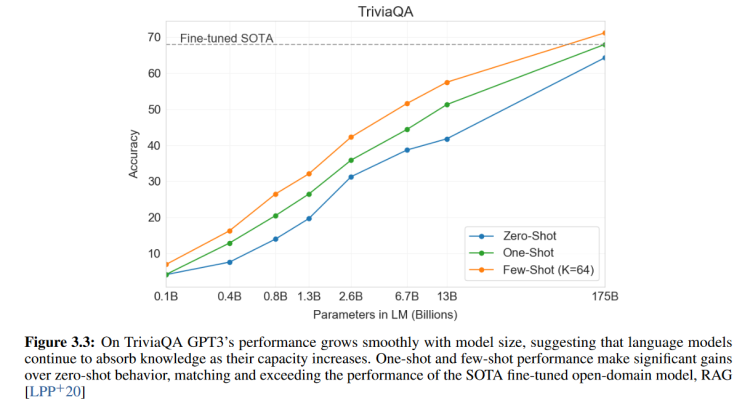
x轴表示的是模型参数规模,y轴表示的是在TriviaQA测试集上的准确率。这个就很符合预期,随着模型规模的增加,效果也一直增加,而且Few-Shot的效果要比One-Shot要好,One-Shot的效果要比Zero-Shot的效果要好。
翻译

x轴表示的是模型参数规模,y轴表示的是翻译任务的BLEU。这里并没有再对比Zero-Shot、One-Shot和Few-Shot,而是对比的不同语言之间的差距。
数学
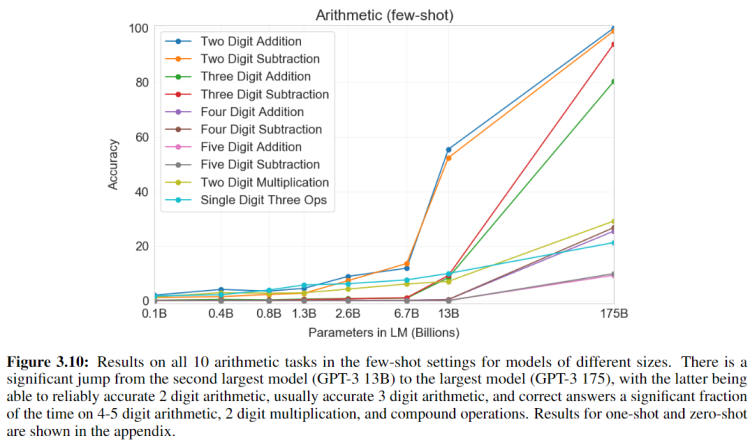
后面的一些实验结果也都大差不差,作者还试了让GPT-3参加SAT考试(美国高考),以及生成一些新闻稿,效果都非常的惊艳。
局限性和影响力
作者在这里花了很大的篇幅讨论GPT-3的一些局限性和可能造成的影响,不过并不涉及很多技术,所以在这不再讨论。
总结
初代GPT-3展示了三个重要能力:
● 语言生成:遵循提示词(prompt),然后生成补全提示词的句子。这也是今天人类与语言模型最普遍的交互方式。能力来自于语言建模的训练目标 (language modeling)。
● 上下文学习 (in-context learning): 给定任务的几个示例,然后为新的测试用例生成解决方案。此能力来源及为什么上下文学习可以泛化,仍然难以溯源。 直觉上,这种能力可能来自于同一个任务的数据点在训练时按顺序排列在同一个 batch 中。
● 世界知识:包括事实性知识 (factual knowledge) 和常识 (commonsense)。来自 3000 亿单词的训练语料库。
虽然初代的 GPT-3 可能表面上看起来很弱,但后来的实验证明,初代 GPT-3 有着非常强的潜力。这些潜力后来被代码训练、指令微调 (instruction tuning) 和基于人类反馈的强化学习 (reinforcement learning with human feedback, RLHF) 解锁,最终体展示出极为强大的突现能力。
GPT-3.5系列
GPT-3.5 的进化树:
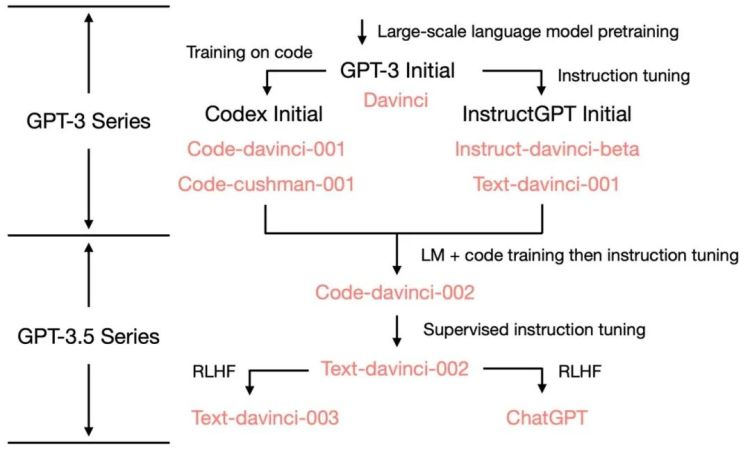
OpenAI 发布的初代GPT-3模型索引名为davinci。然后又发布了Codex的论文,这是根据120 亿参数的 GPT-3 变体进行微调的,命名为Code-davinci-001。后来这个 120 亿参数的模型演变成 OpenAI API 中的Code-cushman-001。之后OpenAI 发布了指令微调 (instruction tuning) 相关的论文,其监督微调 (supervised instruction tuning) 的部分对应了Instruct-davinci-beta和Text-davinci-001。
有的这两项技术之后,OpenAI又在此基础上通过语言模型+代码训练然后再进行指令微调的方式,训练出了Code-davinci-002,在此基础上又通过监督指令微调 (supervised instruction tuned) 训练出了Text-davinci-002模型,最后就是通过基于人类反馈的强化学习训练除了Text-davinci-003和 ChatGPT。
我们关注Code-davinci-002和Text-davinci-002,这两兄弟是第一版的 GPT3.5 模型,一个用于代码,另一个用于文本。它们表现出了几种与初代 GPT-3 不同的重要能力:
● 响应人类指令:以前,GPT-3 的输出主要训练集中常见的句子。现在的模型会针对指令 / 提示词生成更合理的答案(而不是相关但无用的句子)。
● 泛化到没有见过的任务:当用于调整模型的指令数量超过一定的规模时,模型就可以自动在从没见过的新指令上也能生成有效的回答。这种能力对于上线部署至关重要,因为用户总会提新的问题,模型得答得出来才行。
● 代码生成和代码理解:这个能力很显然,因为模型用代码训练过。
● 利用思维链 (chain-of-thought) 进行复杂推理:初代 GPT-3 的模型思维链推理的能力很弱甚至没有。code-davinci-002 和 text-davinci-002 是两个拥有足够强的思维链推理能力的模型。
这些能力从何而来?与之前的模型相比,两个主要区别是指令微调和代码训练。
具体来说:
● 响应人类指令的能力是指令微调的产物。遵循指令和泛化的能力可能都已经存在于基础模型中,后来只是通过指令微调解锁了这些能力而已。这主要是因为指令数据量大小比预训练数据量少了几个数量级。
● 对没有见过的指令做出反馈的泛化能力是在指令数量超过一定程度之后自动出现的,T0、Flan 和 FlanPaLM 论文进一步证明了这一点
● 使用思维链进行复杂推理的能力可能是代码训练的产物。原因:最初的 GPT-3 没有接受过代码训练,它不能做思维链。Text-davinci-001 模型,虽然经过了指令微调,但第一版思维链论文报告中说它的它思维链推理的能力非常弱 —— 所以指令微调可能不是思维链存在的原因,代码训练才是模型能做思维链推理的最可能原因。
CodeX
Codex 是为 GitHub Copilot 提供支持的模型,精通十几种编程语言,可以用自然语言生成代码。

摘要
CodeX是一个基于GPT的语言模型,在GitHub公开可用的代码上进行了微调。GPT-3的创新点虽然是可以不做微调,但是CodeX属于GPT-3的一个应用,因此相当于做了定向应用优化。(不能自己打自己的脸)
CodeX其实只做了Python代码的训练,而Copilot是支持多语言的,因此它们并不完全一样。
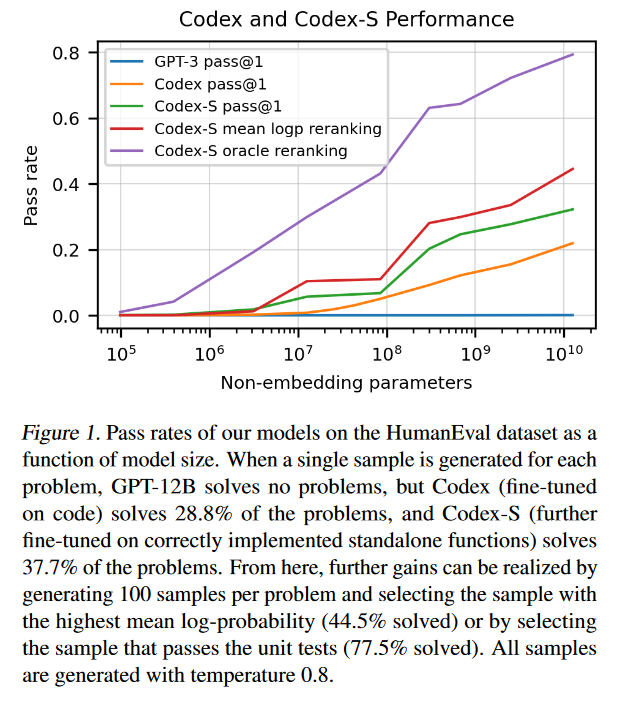
作者还发布了一个评估数据集——HumanEval,用来衡量从注释到代码的正确性。在这个数据集上,CodeX可以解决28.8%的问题,而GPT-3啥也不是,GPT-J可以解决11.4%。
在现实生活中,编程也不是一步到位的,经常需要迭代修改,因此增加了一个新的指标:多次生成只要有一个能通过即算正确。通过这种不断的重复生成,限定最多100次的前提下,有1次通过即可,Codex可以解决70.2%的问题。
介绍
在之前GPT-3的工作中,作者发现模型可以根据注释生成简单的Python代码,这种能力让人兴奋,因为GPT-3并没有在专门的代码数据上进行训练。在本文中,作者就研究了从注释生成Python函数代码的功能,并通过单元测试自动评估代码的正确性。
代码生成任务与自然语言生成任务有一点不同,在自然语言生成中,结果通常由人工进行评估,但是在代码生成中,结果可以由机器来进行评估。为了准确地对模型进行基准测试,作者就创建了一个包含164个带有单元测试的编程问题数据集,用于测试模型对语言的理解能力、对算法的实现和解决数学问题的能力。
在评估的时候,会让模型生成多个答案,只要有一个能通过单元测试即算通过。如果只能生成一个答案的话,120亿参数的模型能够解决28.8%的问题。为了进一步提升模型的性能,作者又收集了一个数据集,这个数据集跟评估模型的方式更加相近一点,在这个数据集上再进行微调,得到Codex-S模型,此时即使只允许生成一个答案的情况下,模型能够解决37.7%的问题,如果允许生成100次,其中只要有一个通过即算通过的情况下,能够解决77.5%的问题。
因为这是一篇比较偏向于应用方面的文章,而在实际编程的过程中,不可能由模型生成100个答案然后由用户进行选择,因此作者又提供了一个排序算法,选择平均概率估计的最大值,挑出第一的结果,也能解决44.5%的问题。
评估框架
代码正确性判断指标
在生成序列的时候,经常使用的一个指标叫BLUE,这个指标看的是生成的序列和真实的序列在一些子序列上的相似度,这是一个模糊匹配的指标,不需要完全匹配。
但是在生成代码的任务中,BLUE分数会有一些问题,因为即使生成的代码和目标代码在一些子序列上一致,也不代表生成的代码能够正确运行并达到预期的效果。
本文中使用的是一个叫 p a s s @ k pass@k pass@k的指标,这里的 k k k表示模型可以生成 k k k个不同的结果,其中只要有一个能够通过测试即算通过。然而,直接计算 p a s s @ k pass@k pass@k并不是很稳定,所以作者在这个地方是一次生成 n ( n > k ) n \ (n > k) n (n>k)个样本,每次从这 n n n个样本中随机采样 k k k个出来看看里面是不是有正确答案,其中正确答案的个数记为 c c c。具体的计算公式: pass @ k : = E Problems [ 1 − ( n − c k ) ( n k ) ] \text { pass } @ k:=\underset{\text { Problems }}{\mathbb{E}}\left[1-\frac{\left(\begin{array}{c} n-c \\ k \end{array}\right)}{\left(\begin{array}{l} n \\ k \end{array}\right)}\right] pass @k:= Problems E 1−(nk)(n−ck) 。

验证数据集
作者在HumanEval数据集上评估函数的正确性,这个数据集包含164个手写编程问题,每个问题包括函数的签名、注释、函数体和若干个单元测试。这些评估的数据集必须是人工生成的,因为如果采用网上找的代码,很可能就已经被包含的训练数据集中了,即数据泄露。
代码微调
数据收集
训练集是2020年5月从GitHub上5400万个代码仓库中收集的,包含179GB的Python文件,然后做了一些过滤:① 可能是自动生成的,② 平均一行长度大于100的,③ 最大一行长度大于1000的,④ 二进制文件。经过清洗之后,最终数据集大小为159GB。
方法
Codex是基于GPT-3模型进行训练的,但是比较令人惊讶的是,在预训练模型上再进行微调并没有对最终结果带来什么明显的提升,仅仅是收敛速度变快了。
因为代码的单词分布跟自然语言的文本分布不同,有很多的空格、缩进和换行,因此Codex在训练的时候添加了一组往外的token来表示不同长度的空格,这样相比于原来表示代码的方式可以节省大约30%的token。
论文中还提到在生成代码的时候采用了核采样的方法。普通的采样每次选择Softmax之后概率最大的token,这样并不能保证整个序列最终的概率最大,即不是全局最优,还有一个问题就是如果每次都选择概率最大的值,那么每次生成的结果都是固定的。一般来说改进的方法是通过树搜索,或者叫Beam Search,可以维护一定数量的当前最优候选,然后一直往下看,计算量上会增加一点,但是可以一次给出多个解。核采样还是在每个时刻对候选词都有一个概率,然后我们按照概率对token进行降序,保留累加概率达到0.95的所有token。
结果
因为评估指标
p
a
s
s
@
K
pass@K
pass@K是会生成多个结果的,因此生成时的参数该如何设置也有讲究,论文中也讨论了一下。

上图的x轴表示采样数,从1~100,y轴表示
p
a
s
s
@
K
pass@K
pass@K指标,不同颜色的线表示生成代码时设置的参数temperature不一样,temperature=0表示每次都选择概率最大的结果,那不管采样多少次结果都是一样的,因此是一条直线。temperature越大,最终生成的多个结果的多样性就越大。下图是根据上图导出的在不同采样次数下的最优temperature。
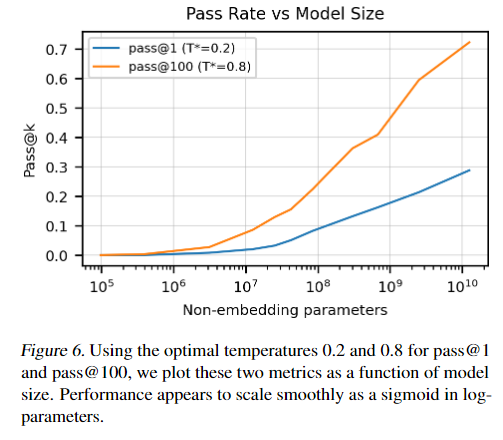
在设置最优参数的情况下,作者做了个实验观察模型参数大小对
p
a
s
s
@
K
pass@K
pass@K的影响,可以发现还是参数量越大模型效果越好。
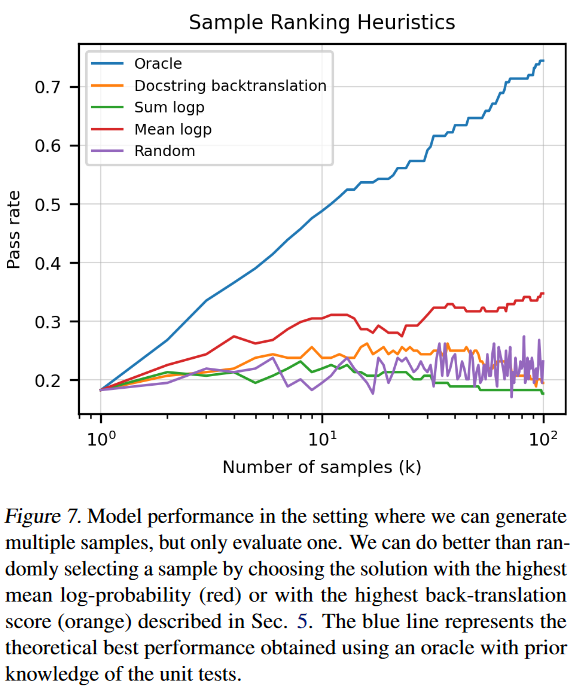
接下来作者又对比了几种方法:
● 蓝色:
K
K
K个结果中只要有1个通过即算通过;
● 橙色:在原本通过注释生成代码的基础上,又训练了一版通过代码生成注释的模型;
● 绿色:取概率之和最大的结果;
● 红色:取平均概率最大的结果;
● 紫色:随机取一个
监督微调
作者认为,前面从GitHub上收集的数据集中,包含了很多的类实现、配置文件和数据存储文件,这部分文件的内容与最终任务无关,因此可能会降低的模型的性能。为了让Codex能够更好的迁移到目标任务的分布,作者又收集了一个数据集,这个数据集是从各种在线评测网站上爬下来的,还有一部分来自持续集成的代码库。在新的数据集上又进行了一次监督微调,新的模型叫Codex-S。
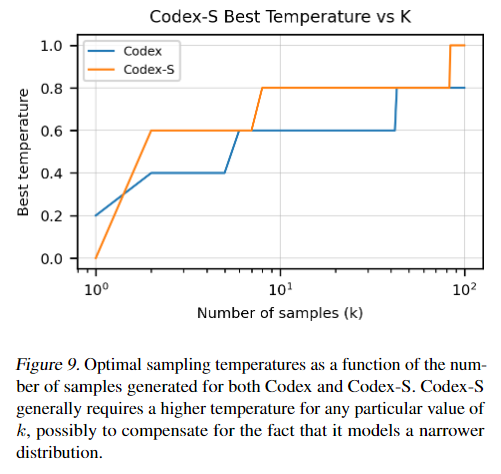
对比了Codex和Codex-S在不同采样数下的最优temperature。
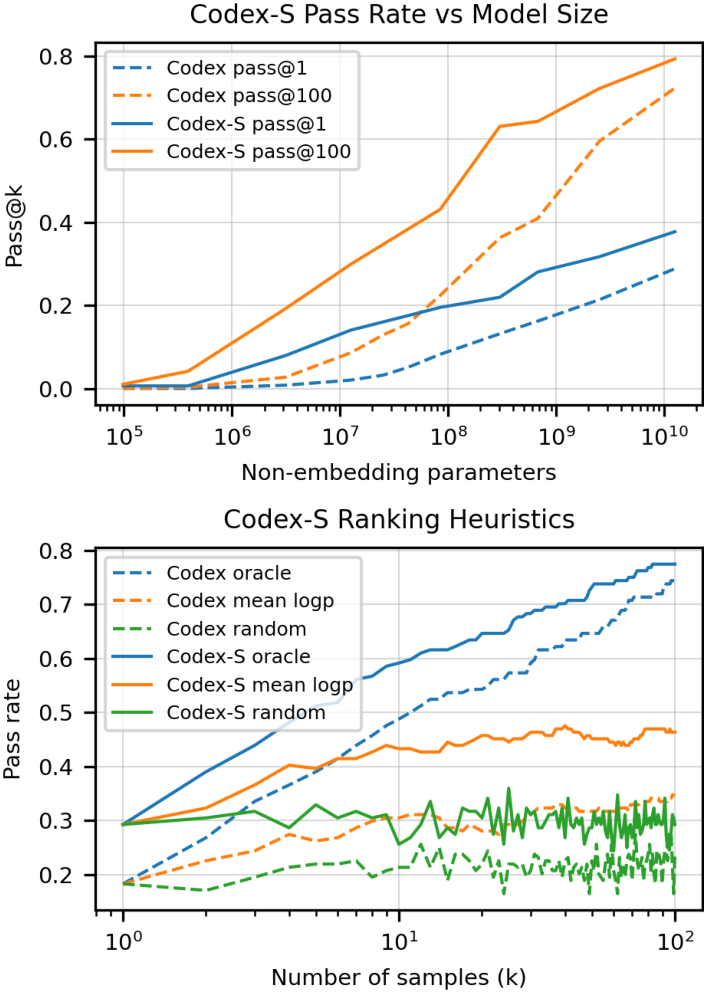
上图对比了Codex和Codex-S模型大小对
p
a
s
s
@
K
pass@K
pass@K的影响,下图对比了不同取法对
p
a
s
s
@
K
pass@K
pass@K的影响。
局限性
- 样本利用率不高
- 对长文本的处理不够好
- 对大局观的理解不够好
- 对数学计算不太擅长

InstructGPT

标题:训练语言模型使其服从人类的指令
背景:GPT-3虽然掌握了各种词语搭配和语法规则,还学会了编程,了解不同语言之间的关系,可以给出高质量的外语翻译,但是还有一个问题:尽管GPT-3拥有了海量的知识,但回答形式和内容不受约束。因为它知道的太多了,见到了一个人几辈子都读不完的资料,可以随意联想,会不受控制的乱说,什么丑闻、脏话和幻觉等全都有可能蹦出来。所以GPT-3的能力其实是非常强悍的,但是我们却很难指挥它。
InstructGPT的解决思路:用优质对话模板矫正GPT-3模型。具体做法就是不再用随便的互联网文本进行训练,而是把人工专门写好的“优质对话范例”喂给GPT-3,再去做单字接龙,以此来学习如何组织符合人类要求的回答。
举个例子:当用户询问如何毁灭世界时,不能让它真的回答怎么毁灭世界,而要回答“这是有害的行为”。
为什么不在一开始就直接教它最正确的对话方式和对话内容呢?
一方面,“优质对话范例”数量有限,所能提供的语言多样性不足,可能难以让模型学到广泛适用的语言规律,也无法涉猎各个领域。
另一方面,“优质对话范例”都需要人工专门标注,价格不菲。所以说不定未来有了足够多的“优质对话范例”之后,就会跳过预训练这一步,直接用“优质对话范例”进行监督学习。
摘要
语言模型越做越大并不意味着能让它们更好的遵循人类的指令,例如大语言模型会生成一些不真实的、有毒的或没有价值的答案,这是因为训练语言模型的目标函数(给定前文预测后文)不合适,并不是遵循人类的指令,换句话说,模型没有与用户对齐。我们希望语言模型是有用的、真诚的并且无害的。
这篇文章中,作者提出了一种通过人类的反馈进行微调的方法,来将语言模型与用户意图进行对齐。在对模型的评估中,13亿参数的InstructGPT模型效果比1750亿参数的GPT-3模型效果更好,并且在性能损失不大的情况下,有毒输出明显降低。
介绍
作者希望通过微调的方法来对齐语言模型与人类意图,具体的方法就是基于人类反馈进行强化学习(Reinforcement Learning from Human Feedback, RLHF)。
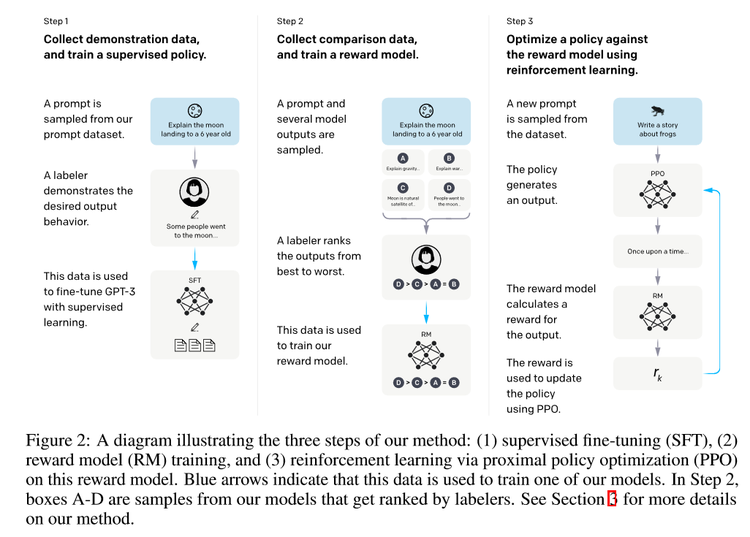
第一步:首先雇佣了40个人的标注团队,专门写了很多的提示词,然后将提示词发给OpenAI的API,之后将符合人类意图的模型结果整理成数据集,最后在这个数据集上通过监督学习来微调GPT-3。
第二步:我们对模型的多个输出进行打分并排序,收集成一个新的数据集,通过这个数据集训练一个打分模型。
第三步:通过打分模型,在第一步数据集的提示词上进行强化学习微调。最终训练出来的模型就是InstructGPT。
为什么要有第一步?
为了让InstructGPT遵循人类的规范。经过大规模预训练和有监督学习微调之后,模型已经变得非常强悍了,但是还有一些不足:InstructGPT的回答可能过于模板化,限制了其创造力,有可能变成模板复读机。我们希望InstructGPT还能生成一些超越模板但仍符合人类对话模式和价值取向的创新性回答。
为什么要有第二步和第三步?
激发更多的创意。这有点类似于试卷最后的附加题,按照正常学习的模板来做的话可能并不能得出正确结果,这时候就需要一些奇思妙想,因此如果能有一些创新的回答,就可以获得更高的分数。在这一步,不再要求它按照我们提供的对话范例做单字接龙,而是直接向它提问,让它自由回答,如果回答的很好,就给予奖励,如果回答的不好,就降低奖励,然后利用评分再去调整模型。
两步之后,既不会因为模板规范限制其表现,又可以引导它生成符合人类认可的优质回答。
最后对InstructGPT做了一系列的评估,结果如下:
● 标注人员觉得 InstructGPT 的输出比 GPT-3 的输出明显更好
● InstructGPT 模型在真实性方面比 GPT-3 有所改进
● InstructGPT 与 GPT-3 相比生成有毒内容的情况略有改善,但还是存在偏见
● RLHF 根据某一个目标函数微调可能会使得在其它任务上的性能下降(对齐税)
● 模型可以泛化到训练数据之外的预留数据上
● 公共 NLP 数据集(FLAN、T0)并不能反映我们的语言模型是如何生效的
● InstructGPT 对 RLHF 微调分布之外的指令也具有泛化性
● InstructGPT 还是会犯一些简单的错误
方法与细节
数据集
提示词数据集是怎么来的?
- 标注人员写了很多的提示词:① 随意写任何问题,确保多样性,② 给定一个主题来写指令,③ 根据用户的一些需求设计相应的提示词。基于以上数据训练了第一个InstructGPT模型。
- 将第一个模型放在Playground中,会有很多人去用,然后再将这些数据采集回来,再做一些筛选和切分。
基于这些提示词,作者构建了三个不同的数据集,然后进行微调:
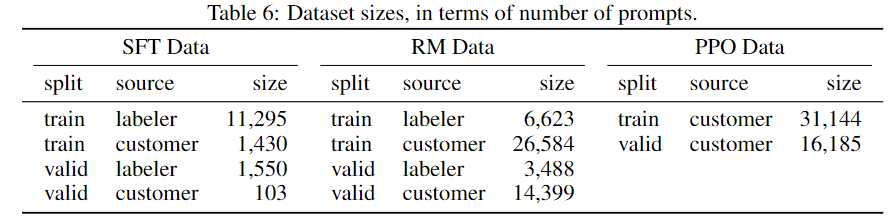
- SFT数据集:13k个样本,标注人员直接去写答案然后训练SFT模型
- RM数据集:33k个样本,用来训练打分模型
- PPO数据集:31k个样本,没有人工标注了,通过打分模型进行标注
任务
训练任务也有两个来源:
- 标注人员编写的提示词数据集;
- 早期InstructGPT的API中提交的提示词数据集;
训练任务也具有多样性,表1中包含了不同任务的占比,表2中提供了一些例子,更多的例子在附录中。
人工数据标注
从UPwork和ScaleAI雇佣了一个40个人的团队,来对数据进行打标签。

模型
- 监督学习微调(SFT):将GPT-3在人工标注数据集通过监督学习进行微调。
- 奖励模型
a. 将一个60亿参数的SFT模型后面的unembedding层去掉,(将Softmax替换为一个线性层),基于提示词和回复,直接输出一个奖励值的标量。
b. 损失函数,输入的标注是排序,并不是实际的奖励值,因此需要将排序转换为奖励值。具体来讲,对一个提示词,取出一对答案,假设 y w y_w yw的排序比 y l y_l yl要高,先把 x x x和 y w y_w yw通过奖励模型得到一个分数,然后把 x x x和 y l y_l yl也通过奖励模型得到一个分数,因为 y w y_w yw的排序比 y l y_l yl要高,因此我们希望前一个 r θ r_θ rθ的奖励要比后一个的大,然后通过一个Sigmoid函数,再做一个log,也就是逻辑回归的损失函数, loss ( θ ) = − 1 ( K 2 ) E ( x , y w , y l ) ∼ D [ log ( σ ( r θ ( x , y w ) − r θ ( x , y l ) ) ) ] \text{loss}(\theta)=-\frac{1}{\left(\begin{array}{c} K \\ 2 \end{array}\right)} E_{\left(x, y_{w}, y_{l}\right) \sim D}\left[\log \left(\sigma\left(r_{\theta}\left(x, y_{w}\right)-r_{\theta}\left(x, y_{l}\right)\right)\right)\right] loss(θ)=−(K2)1E(x,yw,yl)∼D[log(σ(rθ(x,yw)−rθ(x,yl)))]。对于每个提示词会生成K=9个答案,每次从K里面选出来两个,最终除以组合数进行标准化。 - 强化学习PPO模型:
objective
(
ϕ
)
=
E
(
x
,
y
)
∼
D
π
ϕ
R
L
[
r
θ
(
x
,
y
)
−
β
log
(
π
ϕ
R
L
(
y
∣
x
)
π
S
F
T
(
y
∣
x
)
)
]
+
γ
E
x
∼
D
pretrain
[
log
(
π
ϕ
R
L
(
x
)
)
]
\operatorname{objective}(\phi)= E_{(x, y) \sim D_{\pi_{\phi}^{\mathrm{RL}}}}\left[r_{\theta}(x, y)- \beta \log \left(\frac{\pi_{\phi}^{\mathrm{RL}}(y \mid x)}{\pi^{\mathrm{SFT}}(y \mid x)} \right)\right] + \gamma E_{x \sim D_{\text {pretrain }}}\left[\log \left(\pi_{\phi}^{\mathrm{RL}}(x)\right)\right]
objective(ϕ)=E(x,y)∼DπϕRL[rθ(x,y)−βlog(πSFT(y∣x)πϕRL(y∣x))]+γEx∼Dpretrain [log(πϕRL(x))]
a. π ϕ R L \pi_{\phi}^{\mathrm{RL}} πϕRL:可学习的策略,初始化的时候跟 π S F T \pi^{\mathrm{SFT}} πSFT一样
b. π S F T \pi^{\mathrm{SFT}} πSFT:监督学习微调训练出来的模型
c. E ( x , y ) ∼ D π ϕ R L E_{(x, y) \sim D_{\pi_{\phi}^{\mathrm{RL}}}} E(x,y)∼DπϕRL:第一项的 ( x , y ) (x,y) (x,y)来自当前的RL模型,每个提示词 x x x都通过模型生成一个 y y y,然后对 ( x , y ) (x,y) (x,y)进行打分,最大化分数来更新模型参数
d. r θ r_{\theta} rθ是不会发生改变的,并且它的训练数据分布来自于 π S F T \pi^{\mathrm{SFT}} πSFT,因此 π ϕ R L \pi_{\phi}^{\mathrm{RL}} πϕRL的更新可能会导致 y y y的分布发生变化, r θ r_{\theta} rθ的估算逐渐不准,因此通过KL散度 β log ( π ϕ R L ( y ∣ x ) π S F T ( y ∣ x ) ) \beta \log \left(\frac{\pi_{\phi}^{\mathrm{RL}}(y \mid x)}{\pi^{\mathrm{SFT}}(y \mid x)} \right) βlog(πSFT(y∣x)πϕRL(y∣x))控制更新幅度
e. 过于专注微调任务可能会导致模型偏移,因此又从GPT-3训练数据集中采样了一些数据,做语言模型损失函数 γ E x ∼ D pretrain [ log ( π ϕ R L ( x ) ) ] \gamma E_{x \sim D_{\text {pretrain }}}\left[\log \left(\pi_{\phi}^{\mathrm{RL}}(x)\right)\right] γEx∼Dpretrain [log(πϕRL(x))],如果 γ = 0 \gamma = 0 γ=0则模型为纯PPO,如果 γ ≠ 0 \gamma \neq 0 γ=0则模型为PPO-ptx
结果
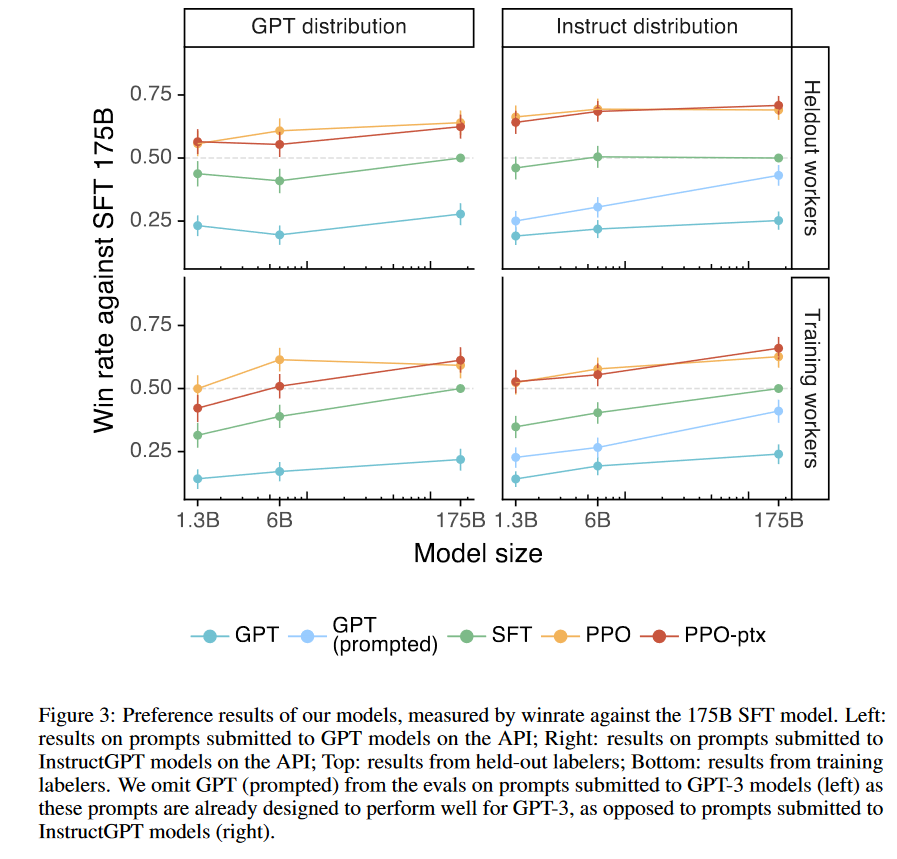
后面的论文中还有大量的篇幅讨论InstructGPT模型的效果和不足,包括能降低多少有害输出,能降低多少幻觉,以及跟其它一些大模型的对比,就不一一展示了,总的来说就是我们比较牛逼,感兴趣的可以看原论文。
总结
指令微调触发的能力:
● 指令微调不会为模型注入新的能力 —— 所有的能力都已经存在了。指令微调的作用是解锁 / 激发这些能力。这主要是因为指令微调的数据量比预训练数据量少几个数量级(基础的能力是通过预训练注入的)。
● 指令微调将 GPT-3 分化到不同的技能树。 有些更擅长上下文学习,如text-davinci-003,有些更擅长对话,如ChatGPT。
● 指令微调通过牺牲性能换取与人类的对齐(alignment)。OpenAI 的作者在他们的指令微调论文中称其为 “对齐税” (alignment tax)。许多论文都报道了code-davinci-002在基准测试中实现了最佳性能(但模型不一定符合人类期望)。
RLHF 触发的能力:
● 翔实的回应:text-davinci-003 的生成通常比 text-davinci-002长。ChatGPT 的回应则更加冗长,以至于用户必须明确要求“用一句话回答我”,才能得到更加简洁的回答。
● 公正的回应:ChatGPT 通常对涉及多个实体利益的事件(例如政治事件)给出非常平衡的回答。这也是RLHF的产物。
● 拒绝不当问题:这是内容过滤器和由 RLHF 触发的模型自身能力的结合,过滤器过滤掉一部分,然后模型再拒绝一部分。
● 拒绝知识范围之外的问题:例如,拒绝在2021 年 6 月之后发生的新事件(因为它没在这之后的数据上训练过)。这是 RLHF 最神奇的部分,因为它使模型能够隐式地区分哪些问题在其知识范围内,哪些问题不在其知识范围内。
有两件事情值得注意:
● 所有的能力都是模型本来就有的, 而不是通过RLHF 注入的。RLHF 的作用是触发 / 解锁突现能力。这个论点主要来自于数据量大小的比较:因为与预训练的数据量相比,RLHF 占用的计算量 / 数据量要少得多。
● 模型知道它不知道什么不是通过编写规则来实现的, 而是通过RLHF解锁的。这是一个非常令人惊讶的发现,因为 RLHF 的最初目标是让模型生成复合人类期望的回答,这更多是让模型生成安全的句子,而不是让模型知道它不知道的内容。