✨ 学习 Spark 和 Scala
一 🐦Spark 算子
spark常用算子详解(小部分算子使用效果与描述不同)
Spark常用的算子以及Scala函数总结
Spark常用Transformations算子(二)
- Transformation 算子(懒算子):不会提交spark作业,从一个RDD转换成另一个RDD
- Action 算子:触发 SparkContext 提交job作业,将数据输出到Spark系统。返回类型是一个其他的数据类型
ps.show 属于action算子
一 Transformation 算子(Value数据类型)
1. 输入分区与输出分区 一对一
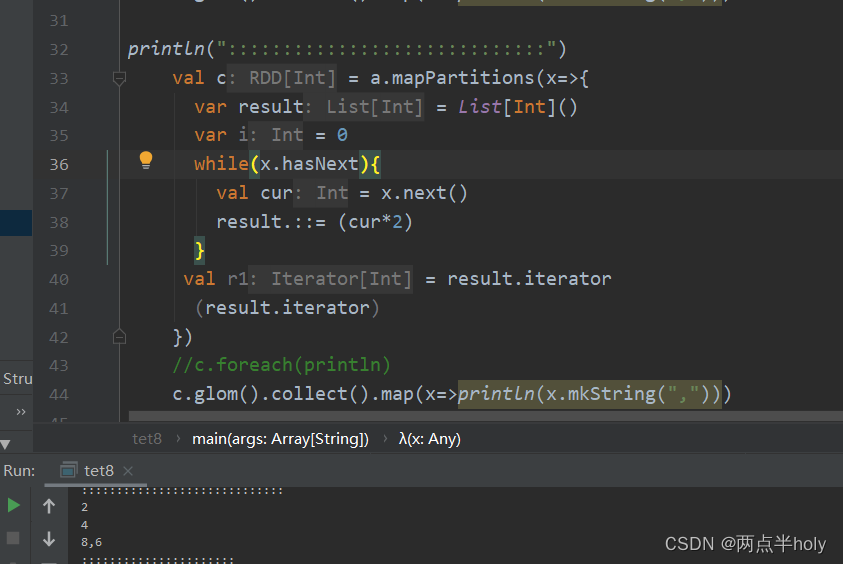
map,flatMap,mapPartirions
glom:算子将一个RDD分区中的元素 组成Array数组的形式 eg.RDD[Int] => RDD[Arrray[Int]]
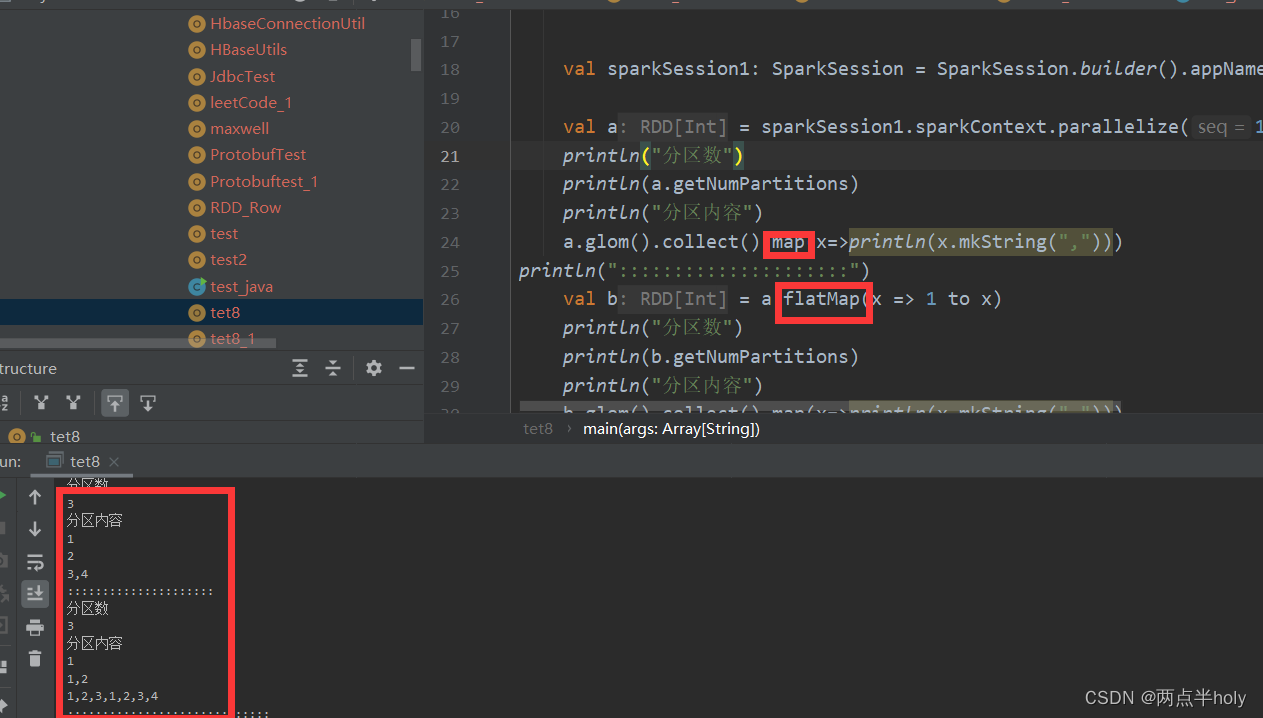

2. 输入分区与输出分区多对一
union:我测试代码分区是叠加 网上别人文档是取最大分区 存疑。输出分区应大于输入分区,或者说输入2+2输出4。
cartesian:取笛卡儿积。问题同union


3. 输入分区与输出分区多对多
groupby Key 算子 也是shuffle类算子。 (默认分区数与原RDD分区数一致可以重新指定)
sortby key 算子 也是shuffle类算子。 (默认分区数与原RDD分区数一致可以重新指定,默认使用范围分区器) 在spark ui界面查看 job sortby算子会触发一个job 这个Job是用于评估数据分布,评估结果用于后续的排序操作,并不是真正的排序操作。
4. 输出分区为输入分区子集
distnct 算子:也是 shuffle类算子 。map reducebykey map (默认分区数与原RDD分区数一致可以重新指定)
filter 算子:过滤算子
subtract 算子:也是 shuffle类算子 。RDD1 去除 RDD1与RDD2交集的 剩下的RDD1 (默认分区数与原RDD分区数一致可以重新指定)
intersection 算子: 也是 shuffle类算子 。返回两个RDD的交集并去重 (默认分区数与原RDD分区数一致可以重新指定)
sample 算子。采样 将 RDD 这个集合内的元素进行采样,获取所有元素的子集。用户可以设定是否有放回的抽样、百分比、随机种子,进而决定采样方式。内部实现是生成 SampledRDD(withReplacement, fraction, seed)。函数参数设置:withReplacement=true,表示有放回的抽样。withReplacement=false,表示无放回的抽样。
关于spark的sample()算子参数详解
takeSample:算子 不使用相对比例采样,而是按设定的采样个数进行采样
println("distinct")
val d1:RDD[String] = sparkSession1.sparkContext.makeRDD(Array("hello","hello","world"))
val distinctRDD:RDD[String] = d1.map((_,1))
.reduceByKey(_+_)
.map(_._1)
distinctRDD.foreach(println)




5. Cache 型算子
cache:算子将RDD元素从磁盘缓存到内存 相当于 persist(MEMORY_ONLY)函数。分区一对一的
persist:算子有缓存 内存 磁盘 压缩等多个参数可选
二 Transformation 算子(Key - Value数据类型)
1. 输入分区与输出分区一对一
mapValues:算子 对value处理 可以用map代替

2. 单个RDD聚集算子
combineByKey:combineByKey的使用 也是 shuffle类算子 。
reduceBykey:通过key值相同会去聚合 也是 shuffle类算子 。reuduceByKey 会在map端 先进行本地combine (预聚合),减少传输到reduce端的数据量,减少网络传输的开销。只有reduceByKey处理不了的时候,会用 groupByKey().map() 代替
eg.SparkStreaming 算子:reduceByKeyAndWindow 窗口函数 每10秒计算一下前15秒的内容
- 存储上一个window的reduce值
- 计算出上一个window的begin 时间到 重复段的开始时间的reduce 值 =》 oldRDD
- 重复时间段的值结束时间到当前window的结束时间的值 =》 newRDD
- 重复时间段的值等于上一个window的值减去oldRDD =》coincodeRDD
- coincodeRDD + newRDD
//PairRDDFunction ,PairRDD属于RDD RDD的方法也通用 PairRDD 就是键值对的RDD 也是 RDD[Tuple2[]]
def reduceByKey(func: (V, V) => V): RDD[(K, V)] = self.withScope {
reduceByKey(defaultPartitioner(self), func)
}
//入参的func 必须是(V,V)=>V的类型 操作两个Value;返回的结果必须是(Key,Value)
//可以用self和this访问自身成员
//withScope 源码参照
private[spark] def withScope[U](body: => U): U = RDDOperationScope.withScope[U](sc)(body)
Spark源码之withScope方法的理解
partitionBy:自定义分区器 也是 shuffle类算子 。
repartitionAndSortWithinPartitions(partitioner):该方法根据partitioner对RDD进行分区,并且在每个结果分区中按key进行排序。也是 shuffle类算子 。
coalesce(numPartitions):重新分区,减少RDD中分区的数量到numPartitions。也是 shuffle类算子 。
repartition(numPartitions):repartition是coalesce接口中shuffle为true的简易实现,即Reshuffle RDD并随机分区,使各分区数据量尽可能平衡。若分区之后分区数远大于原分区数,则需要shuffle。
aggregateBykey :也是 shuffle类算子 。没有使用过 对所有分区的元素先聚合再fold操作?
3. 两个RDD聚集算子
cogroup :合并两个RDD,生成一个新的RDD。实例中包含两个Iterable值,第一个表示RDD1中相同值,第二个表示RDD2中相同值(key值),这个操作需要通过partitioner进行重新分区,因此需要执行一次shuffle操作。(若两个RDD在此之前进行过shuffle,则不需要)
4. 连接
join:对两个需要连接的 RDD 进行 cogroup函数操作,将相同 key 的数据能够放到一个分区,在 cogroup 操作之后形成的新 RDD 对每个key 下的元素进行笛卡尔积的操作,返回的结果再展平,对应 key 下的所有元组形成一个集合。最后返回 RDD[(K, (V, W))]。
下 面 代 码 为 join 的 函 数 实 现, 本 质 是通 过 cogroup 算 子 先 进 行 协 同 划 分, 再 通 过flatMapValues 将合并的数据打散。
this.cogroup(other,partitioner).f latMapValues{case(vs,ws) => for(v<-vs;w<-ws)yield(v,w) }
图 20是对两个 RDD 的 join 操作示意图。大方框代表 RDD,小方框代表 RDD 中的分区。函数对相同 key 的元素,如 V1 为 key 做连接后结果为 (V1,(1,1)) 和 (V1,(1,2))。
leftOutJoin和rightOutJoin: LeftOutJoin(左外连接)和RightOutJoin(右外连接)相当于在join的基础上先判断一侧的RDD元素是否为空,如果为空,则填充为空。 如果不为空,则将数据进行连接运算,并
返回结果。
下面代码是leftOutJoin的实现。
if (ws.isEmpty) {
vs.map(v => (v, None))
} else {
for (v <- vs; w <- ws) yield (v, Some(w))
}
zip:拉齐算子 包括 zipWithIndex(下标为value) 该函数将RDD中的元素和这个元素在RDD中的ID(索引号)组合成键/值对,zipWithUniqueId 该函数将RDD中元素和一个唯一ID组合成键/值对,该唯一ID生成算法如下:
每个分区中第一个元素的唯一ID值为:该分区索引号,
每个分区中第N个元素的唯一ID值为:(前一个元素的唯一ID值) + (该RDD总的分区数)
该函数将RDD中的元素和这个元素在RDD中的ID(索引号)组合成键/值对。
所以分区不用值也不一样
通过SparkContext 提交作业 触发RDD DAG 的执行
/**
* Return an array that contains all of the elements in this RDD.
*
* @note This method should only be used if the resulting array is expected to be small, as
* all the data is loaded into the driver's memory.
*/
//collect 算子的方法
def collect(): Array[T] = withScope {
//提交Job
val results = sc.runJob(this, (iter: Iterator[T]) => iter.toArray)
//_* 变长参数
Array.concat(results: _*)
}
三 Action 算子
1. 无输出算子
foreach:对RDD的每个元素应用 f 函数操作,不返回 RDD 和 Array ,返回的Unit
2. 输出到HDFS
saveAsTextFile : 算子 通过调用 saveAsHadoopFile 进行实现:
this.map(x => (NullWritable.get(), new Text(x.toString))).saveAsHadoopFileTextOutputFormat[NullWritable, Text]
将 RDD 中的每个元素映射转变为 (null, x.toString),然后再将其写入 HDFS
/**
* Save this RDD as a compressed text file, using string representations of elements.
*/
//第一个参数:Path为保存的路径;第二个参数:codec为压缩编码格式;
def saveAsTextFile(path: String, codec: Class[_ <: CompressionCodec]): Unit = withScope {
// https://issues.apache.org/jira/browse/SPARK-2075
val nullWritableClassTag: ClassTag[NullWritable] = implicitly[ClassTag[NullWritable]]
val textClassTag: ClassTag[Text] = implicitly[ClassTag[Text]]
val r : RDD[(NullWritable,Text)] = this.mapPartitions { iter =>
val text:Text = new Text()
iter.map { x =>
text.set(x.toString)
(NullWritable.get(), text)
}
}
RDD.rddToPairRDDFunctions(r)(nullWritableClassTag, textClassTag, null)
.saveAsHadoopFile[TextOutputFormat[NullWritable, Text]](path, codec)
}
saveAsObjectFile 算子:将分区中的每10个元素组成一个Array,然后将这个Array序列化,映射为(Null,BytesWritable(Y))的元素,写入HDFS为SequenceFile的格式。
下面代码为函数内部实现。
map(x=>(NullWritable.get(),new BytesWritable(Utils.serialize(x))))
图24中的左侧方框代表RDD分区,右侧方框代表HDFS的Block。 通过函数将RDD的每个分区存储为HDFS上的一个Block。
3. Scala集合和数据类型
collect 算子 相当于 toArray, toArray 已经过时不推荐使用, collect 将分布式的 RDD 返回为一个单机的 scala Array 数组。在这个数组上运用 scala 的函数式操作。
图 25中左侧方框代表 RDD 分区,右侧方框代表单机内存中的数组。通过函数操作,将结果返回到 Driver 程序所在的节点,以数组形式存储。
collectAsMap: 对(K,V)型的RDD数据返回一个单机HashMap。 对于重复K的RDD元素,后面的元素覆盖前面的元素。
lookup(key:K):Seq[V]查找
Lookup函数对(Key,Value)型的RDD操作,返回指定Key对应的元素形成的Seq。 这个函数处理优化的部分在于,如果这个RDD包含分区器,则只会对应处理K所在的分区,然后返回由(K,V)形成的Seq。 如果RDD不包含分区器,则需要对全RDD元素进行暴力扫描处理,搜索指定K对应的元素。

count : 返回整个RDD的元素个数
top:返回最大的K个元素 ·top返回最大的k个元素。·take返回最小的k个元素。·takeOrdered返回最小的k个元素,并且在返回的数组中保持元素的顺序。·first相当于top(1)返回整个RDD中的前k个元素,可以定义排序的方式Ordering[T]。返回的是一个含前k个元素的数组。
reduceByKeyLocally: 实现的是先reduce再collectAsMap的功能,先对RDD的整体进行reduce操作,然后再收集所有结果返回为一个HashMap。

reduce: 规约操作 scala当中的reduce可以对集合当中的元素进行归约操作。
reduce包含reduceLeft和reduceRight。reduceLeft就是从左向右归约,reduceRight就是从右向左归约。
(1 to 9).reduceLeft( _ * _) //相当于1 * 2 * 3 * 4 * 5 * 6 * 7 * 8 * 9
(1 to 9).reduceLeft( _ + _) //相当于1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9
(1 to 9).reduce(_ + _) //默认是reduceLeft
fold :RDD牵涉到多个分区时,每个分区的初始值都会被累加一次 在累加的时候会再加一次
Spark算子 - fold
2*(2*1*2)*(2*3*4) = 192

四 有状态算子
val wordAndOne: DStream[(String, Int)] = words.map((_, 1))
/*
参数1: reduce 计算规则
参数2: 窗口长度
参数3: 窗口滑动步长. 每隔这么长时间计算一次.
*/
val count: DStream[(String, Int)] =
wordAndOne.reduceByKeyAndWindow((x: Int, y: Int) => x + y,Seconds(15), Seconds(10))
countByWindow(windowLength, slideInterval): 返回一个滑动窗口的元素个数
countByValueAndWindow(windowLength, slideInterval, [numTasks]): 对(K,V)对的DStream调用,返回(K,Long)对的新DStream,其中每个key的的对象的v是其在滑动窗口中频率。如上,可配置reduce任务数量。
// Shuffle 性能优化
new SparkConf().set("spark.shuffle.consolidateFiles","true")
spark.shuffle.consolidateFiles: 是否开启 shuffle block file 的合并,默认为 false;
spark.reducer.maxSizeInFlight: reduce task 的拉取缓存,默认 48M
spark.shuffle.file.buffer : map task 的写磁盘缓存,默认 32k;
spark.shuffle.io.maxRetries: 拉取失败的最大重试次数,默认 3 次;
spark.shuffle.io.retryWait : 拉取失败的重试间隔,默认 5s
spark.shuffle.memoryFraction: 用于 reduce 端聚合的内存比例,默认 0.2, 超过比例就会溢出到磁盘上;
StructuredStreaming
🎋 Spark 内存模型

https://blog.csdn.net/j904538808/article/details/78854742?utm_medium=distribute.pc_relevant.none-task-blog-baidulandingword-2&spm=1001.2101.3001.4242