上篇文章介绍了加载图片并圈选图片中文字区域的程序实现方式,本文基于此实现识别圈选区域文字内容的程序。主要识别语言包括英文和中文。IronOCR包中自带英文语言包,项目还需安装中文语言包,建议直接安装IronOcr.Languages.Chinese语言包,该包中支持以下类型的语言设置,也即设置IronOCR的识别语言时,安装了上述包即可指定以下截图中的OcrLanguage枚举选项。

圈选图片识别文本的程序的大致思路是加载并显示图片,用户圈选要是识别的文本,选择文本语言,然后调用IronOCR识别文本并显示结果。上一篇文章中,用户圈选图片后,会自动将圈选区域另存为一bitmap对象实例。本文中直接使用该实例识别文本。
OcrInput类的构造函数如下图所示,从其中可以看到可以指定本地图片路径,也可以传入流对象或图片对象等,其中Image类和AnyBitmap类并不是System.Drawing命名空间下的类,而是IronSoftware.Drawing和SixLabors.ImageSharp下的类。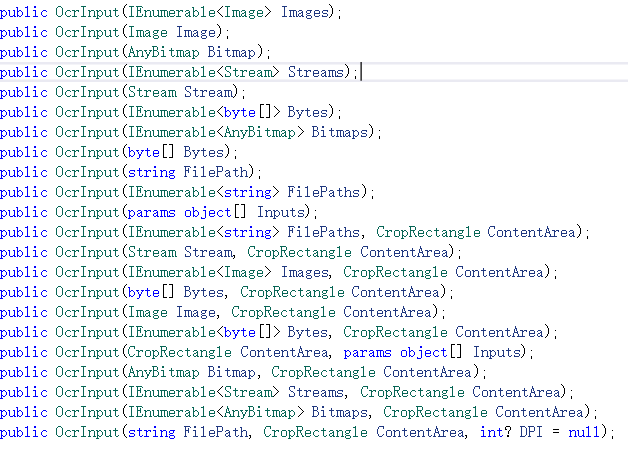
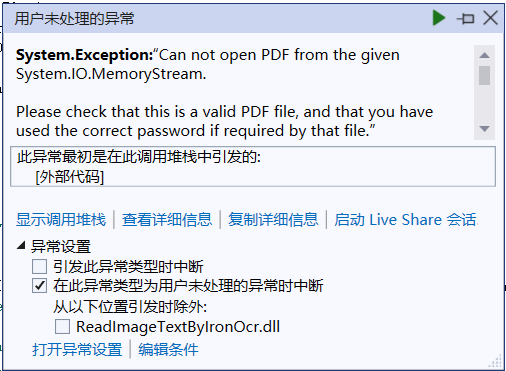
采用传入流对象的方式创建OcrInput对象实例,主要代码如下所示。但是在运行过程中会报如下截图的错误。从错误信息来看,应该是将传入的流对象内容当成了PDF文本,进而导致程序异常。
var Ocr = new IronTesseract();
Ocr.Language = (comboLanguage.SelectedIndex == 0) ? OcrLanguage.ChineseSimplifiedBest : OcrLanguage.EnglishBest;
using (MemoryStream ms = new MemoryStream())
{
m_selectImage.Save(ms, ImageFormat.Bmp);
using (var input = new OcrInput(ms))
{
var Result = Ocr.Read(input);
txtOcrResult.Text = Result.Text;
}
}
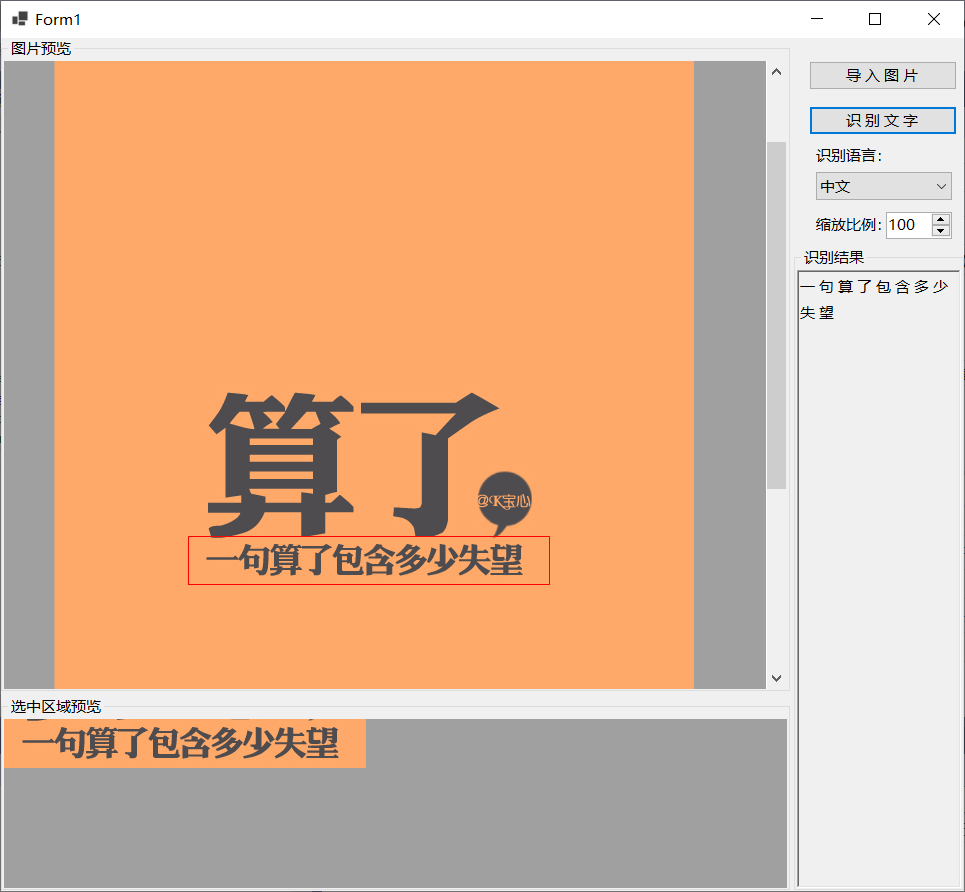
将流对象转存入IronSoftware.Drawing.AnyBitmap对象内容,然后再基于AnyBitmap对象创建OcrInput对象实例,程序即可正常运行及识别文本。主要代码及程序运行效果如下所示:
var Ocr = new IronTesseract();
Ocr.Language = (comboLanguage.SelectedIndex == 0) ? OcrLanguage.ChineseSimplifiedBest : OcrLanguage.EnglishBest;
using (MemoryStream ms = new MemoryStream())
{
m_selectImage.Save(ms, ImageFormat.Bmp);
IronSoftware.Drawing.AnyBitmap bitmap = new IronSoftware.Drawing.AnyBitmap(ms);
using (var input = new OcrInput(ms))
{
var Result = Ocr.Read(input);
txtOcrResult.Text = Result.Text;
}
}
后续还会继续增加功能,比如支持屏幕截图后识别文本,或者是识别文本后翻译文本内容(如识别英文并翻译为中文)。
参考文献:
[1]https://ironsoftware.com/csharp/ocr/examples/simple-csharp-ocr-tesseract/