背景与现状
图像修复是一个长期存在的低层次视觉问题,旨在从损坏的输入图像中获取高质量图像,例如去模糊、去噪、去雾、去雨以及超分辨等。
L
=
D
(
H
)
+
γ
\mathbf{L} = \mathbf{D}(\mathbf{H}) + \gamma
L=D(H)+γ
其中,L是低质量图像,H是高质量图像,
D
,
γ
D, \gamma
D,γ分别表示成像和传输过程中的退化函数和噪声
图像修复是一个典型的不可逆问题,因为任何原始输入都有很多候选项。为了限定无限的可行解,传统方法通过对不同的修复任务设计不同的先验知识,将图像修复转化为一个MAP问题:
H
^
=
arg max
H
log
P
(
L
∣
H
)
+
log
P
(
H
)
\mathbf{\hat{H}}= \underset {\mathbf{H}} { \operatorname {arg\,max}} \log P(\mathbf{L}|\mathbf{H}) + \log P(\mathbf{H})
H^=HargmaxlogP(L∣H)+logP(H)
但是设计这样一个先验,通常具有很大的挑战,而且不可泛化
随着深度学习方法在高层次视觉任务中的使用,以及数据规模的增加,能够隐式的学习通用先验的CNN以及Transformer开始用于解决图像修复任务,并取得了SOTA效果。
目前图像修复的网络模型架构主要包括残差块、多尺度、多阶段、编码器-解码器。
当前面对的问题:图像修复的质量(空间细节、上下文信息);图像修复的模型系统复杂性
主流方法
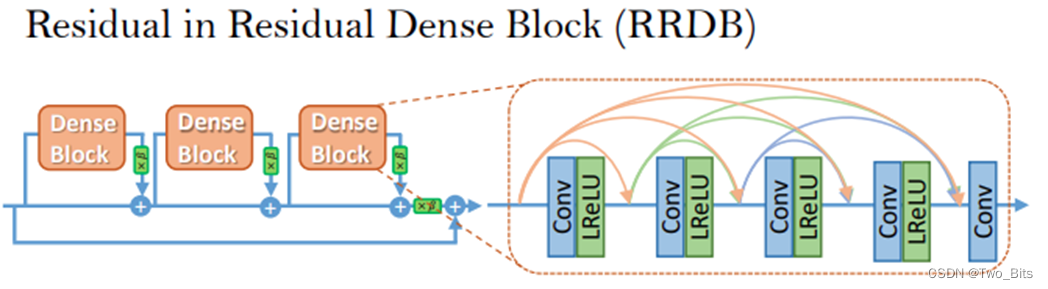
残差块结构 (2018年 ESRGAN)

多尺度结构 (2020 MIPNet 2022 MIRNetV2)
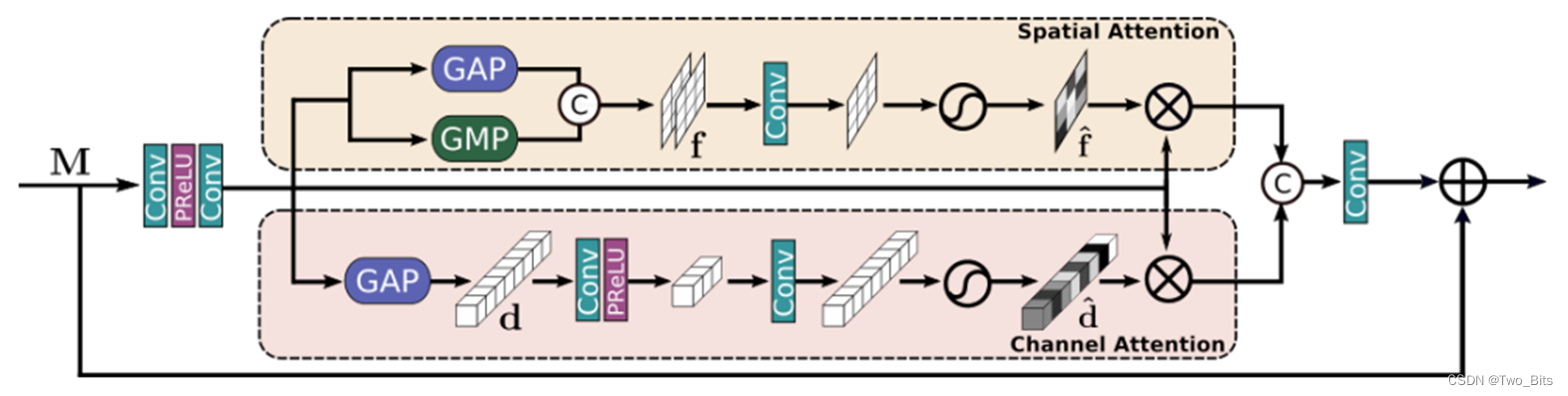
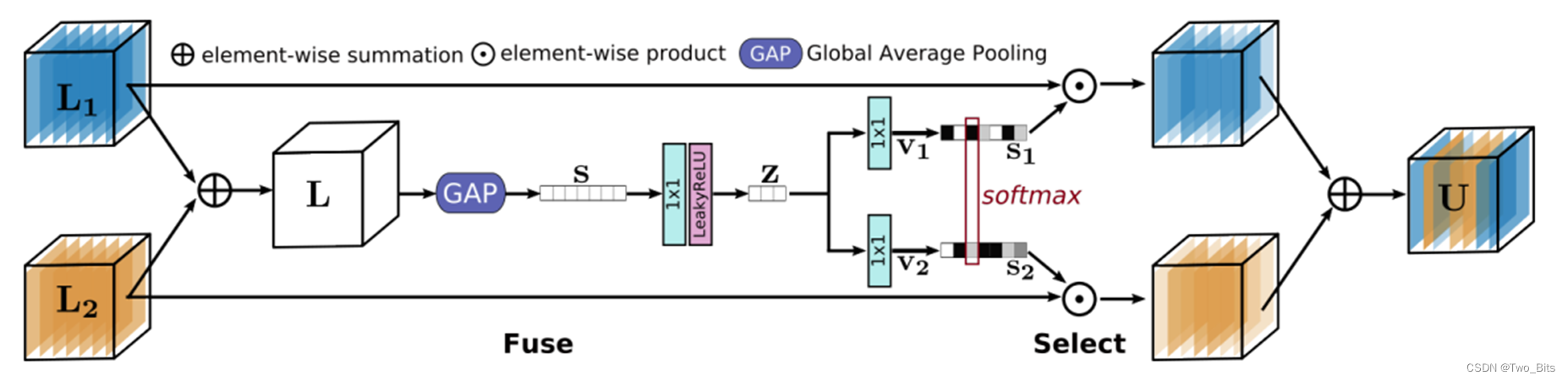
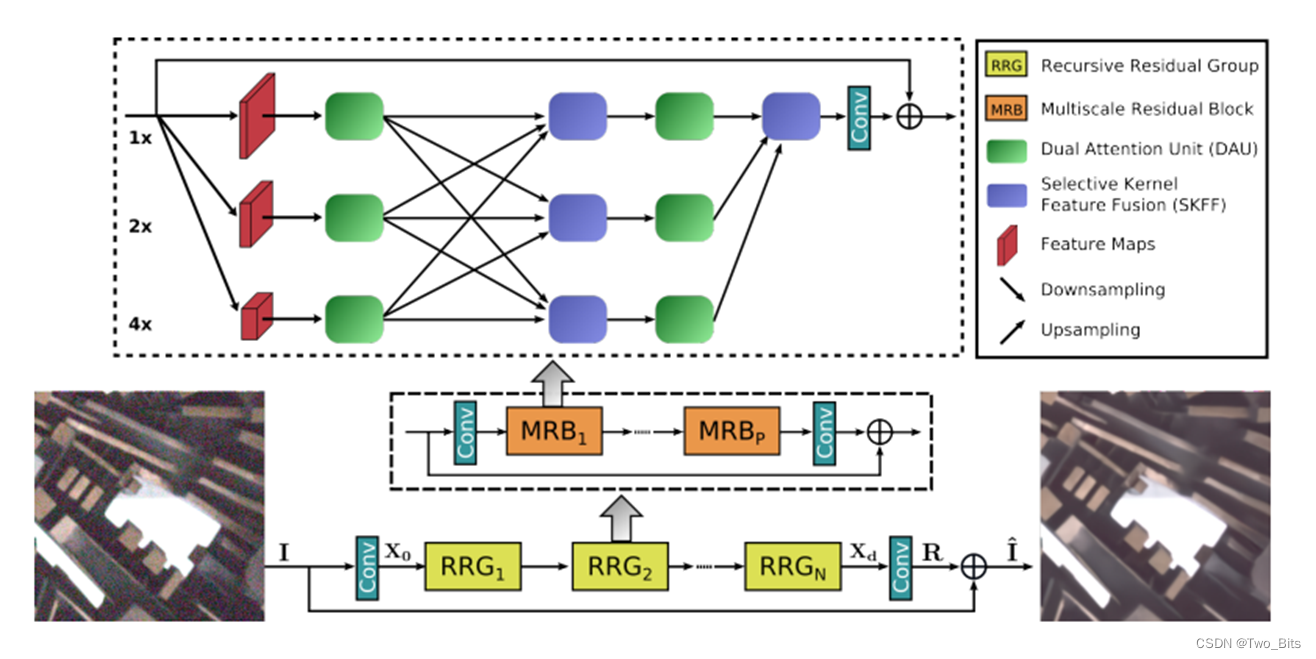 主要创新点:DAU和SKFF
主要创新点:DAU和SKFF
多阶段结构 (2021MPRNet)
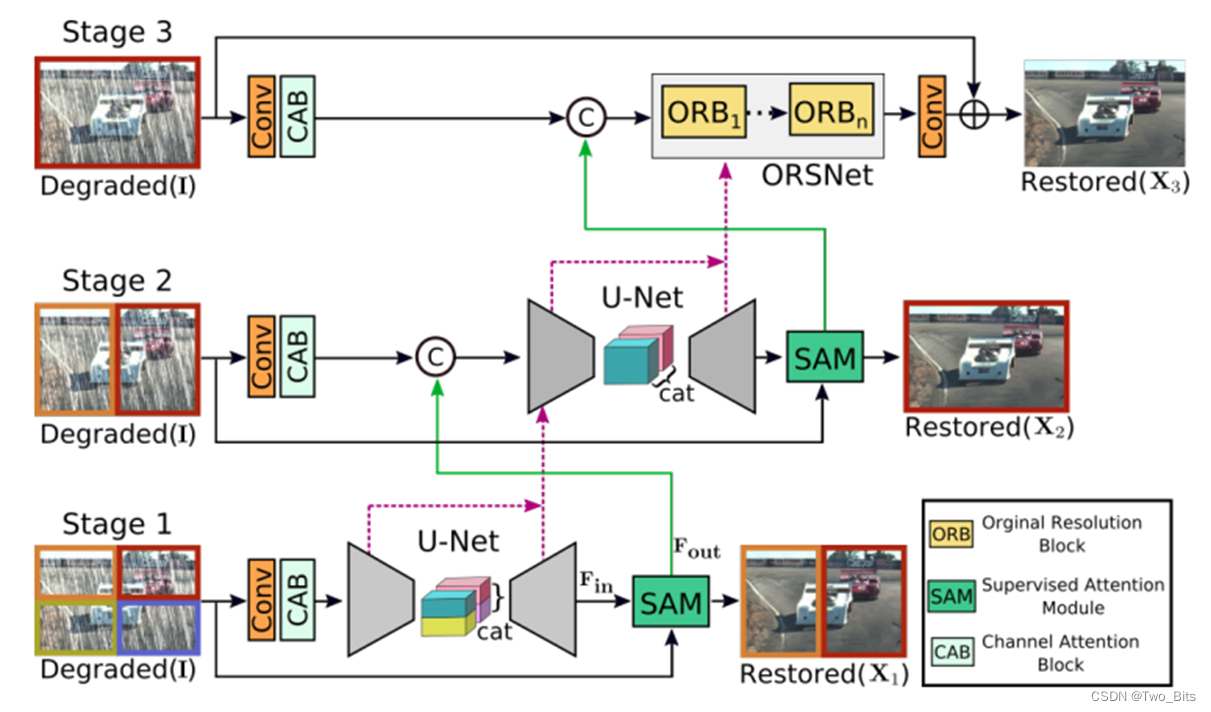
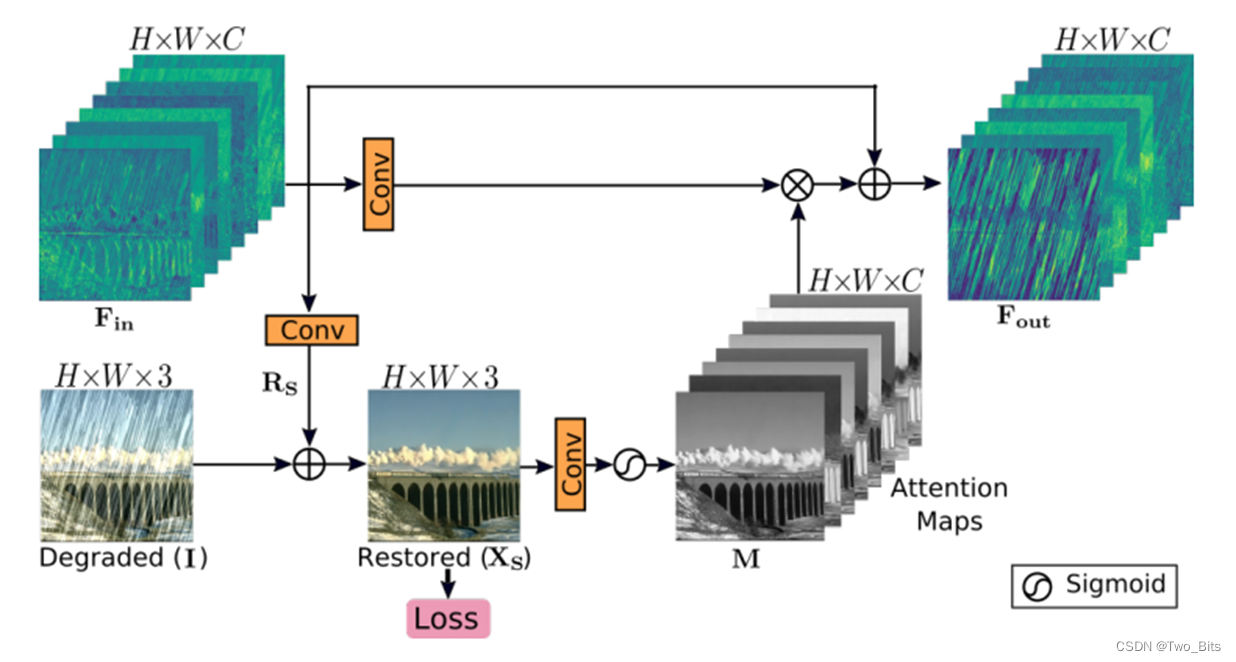
主要创新点: SAM
编码器-解码器结构 (2022Restormer)
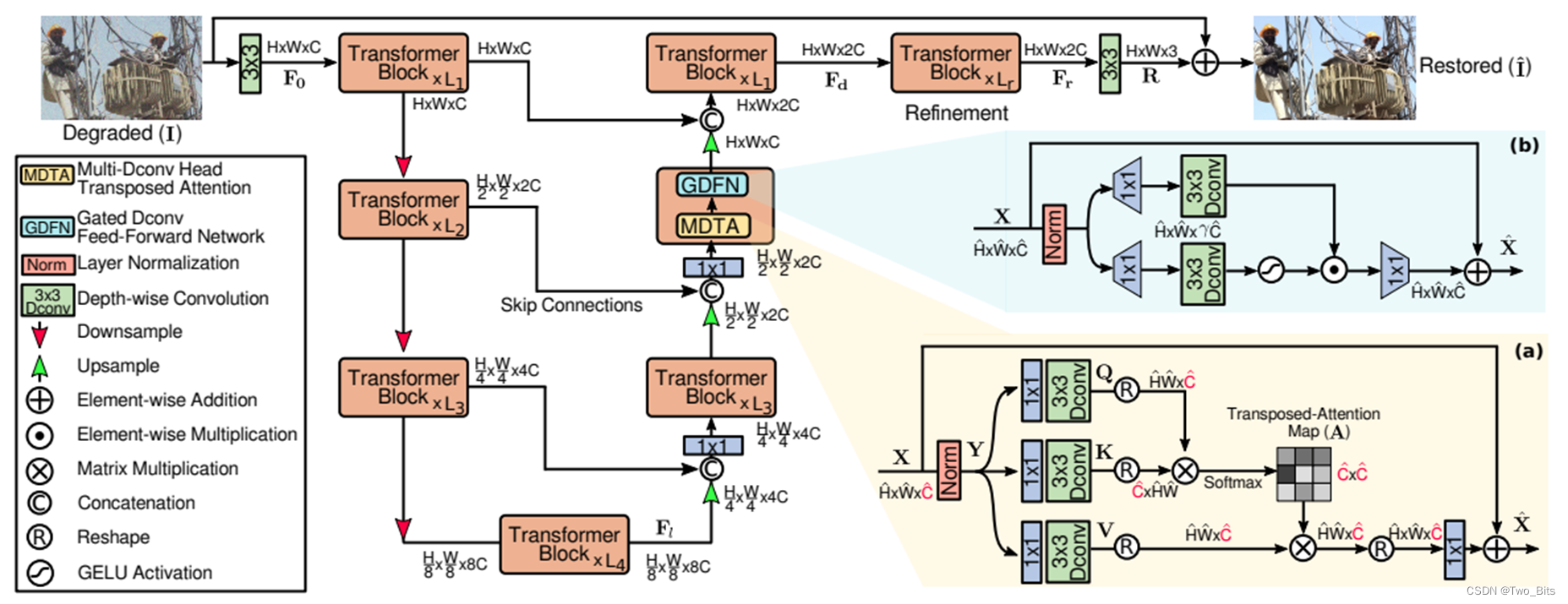
主要创新点: 线性复杂度的注意力机制(就是转置),门控前馈神经网络
编码器-解码器结构(2022Uformer)
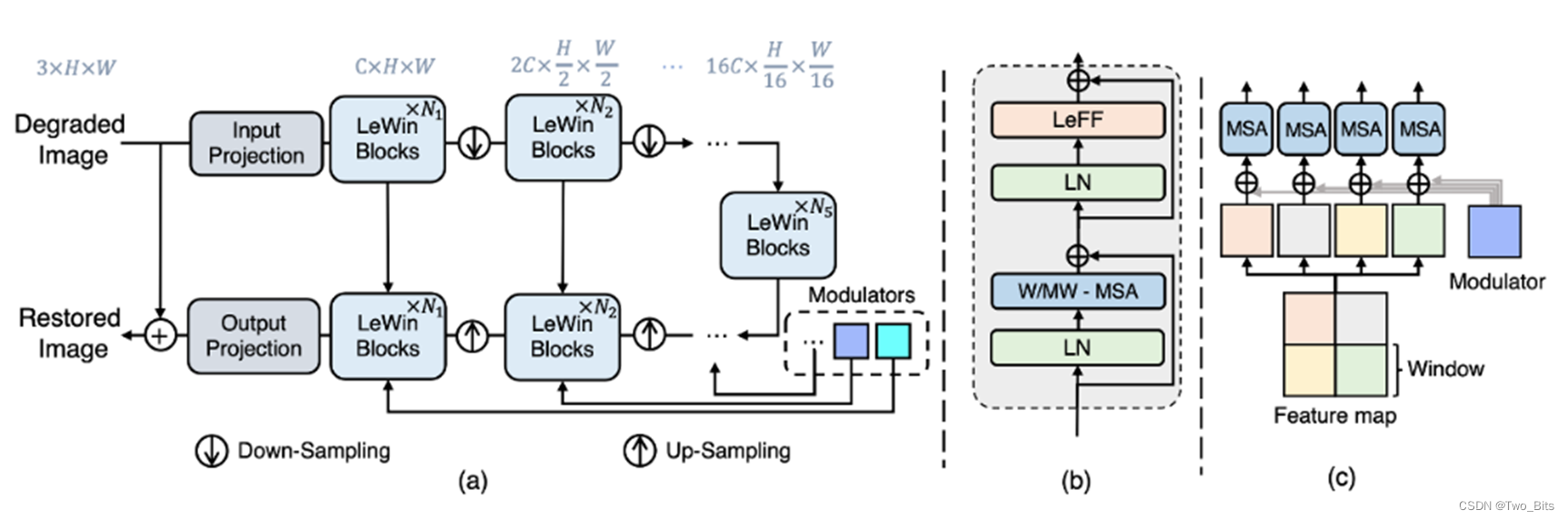
主要创新点 : LeFF和modulator (对这个模块的作用存疑,提升的太大了)
编码器-解码器结构(2022 NAFNet)
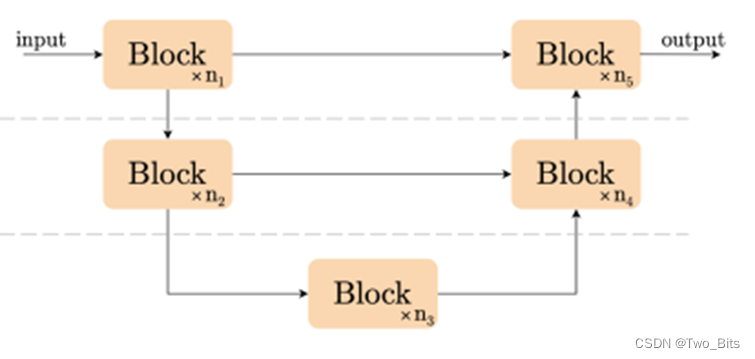
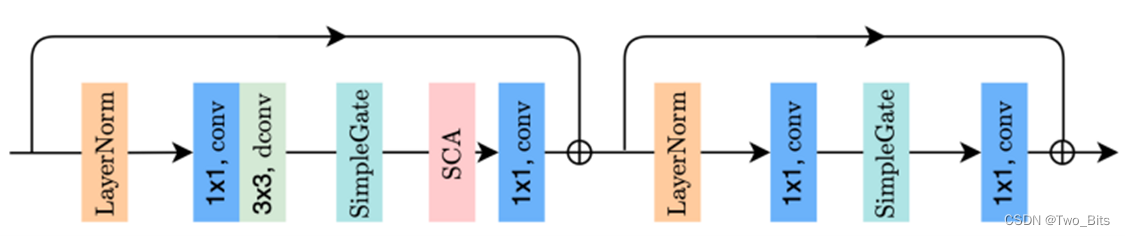
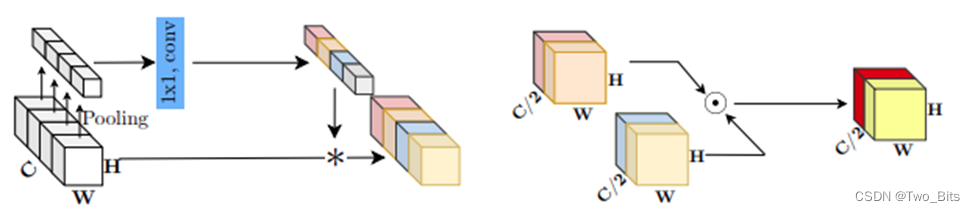
主要创新点:移除或替代了非线性激活函数,使模型系统复杂性降低。主要是提出了一个新的baseline,后续可以在其基础上进行做一些工作。
总结
感觉图像修复真的太吃设备了,动不动就跑几周,时间成本太大了