目录
- 序言
- 文件
- 程序文件&数据文件
- 程序文件
- 数据文件
- 文本文件&二进制文件
- 文件名
- 操作初阶
- 打开&关闭文件
- fopen
- 读写文件
- fputc & fgetc
- 文件缓冲区
- 文件指针
- 操作进阶
- 打开方式
- "w"(只写)
- "r"(只读)
- "a"(追加)
- 文件的顺序读写
- fgets & fputs
- fprintf&fscanf
- fwrite&fread
- 对比一组函数
- sscanf & sprintf
- 文件的随机读写
- fseek
- ftell
- rewind
- 文件结束标志
- 文本文件 & 二进制文件
- 文件结束的判定
- feof
序言
我们需要谈谈C语言的文件操作,在实际开发中,这个模块的内容是很少使用的,不过为了知识的完整性和后面Linux的学习,这里还是需要见见的.
文件
大家可能听说过一个名词持久化存储 ,那么什么是持久化存储呢?听着十分高大上,实际上本质就是把数据用文件保存起来.在之前我们所有的程序都是打印在显式中的,数据保存再内存中,当我们这个程序一结束,里面所有的信息都没有了,比如说我们的之前模拟的通讯录.所以我们今天的文件就是为了解决这样的内容,我们需要把程序的数据保存下来.在Windows下,创建一个文件是十分简单的,鼠标右健就可以选择了.
程序文件&数据文件
既然存在文件,那么我们肯定会对文件经行一个分类.按照一般情况我们把文件分成两类.程序文件和数据文件.
程序文件
所谓的程序文件就是我们前面一直写C语言代码的文件,也就是.c文件,当然如果我们后面学习了其他的语言,例如C++,它的后缀文件是.cpp,这些都是程序文件.除此之外,像这些源代码经过编译后产生的目标文件和可执行程序(Windows环境下后缀是.exe)也都是程序文件.这里我们我想谈一下目标文件.在Windows环境下,目标文件的后缀是.obj,在Linux下是.o.大家了解就可以了.
数据文件
那么什么是数据文件呢?数据文件就像是我们经过程序文件运行后的都到的结果,例如我们前面的写的通讯录,我们发现如果我们把每一次自己添加的信息在程序结束后,我们把这些信息存储到一个文件中,那么这个文件我们就称之为数据文件.这里我想和大家的.两种文件的分类并不是那么严格,我们只需要了解有这个分类就可以了.例如如果程序是想拷贝我们程序的源代码,那么我们想问这个拷贝文件时程序文件还是数据文件?所以大家了解就好.
文本文件&二进制文件
我们这里从另外一种层面来把文件再次进行归类.在计算机中,根据数据的组织形式,数据文件被称为文本文件或者二进制文件.和上面一样,我们也是只了解就好.
- 文本文件 ASCII码组成 人们能够看懂
- 二进制文件 01组成 人看不懂
文件名
我们知道,在生活中,我们的名字可以标识我们是谁,有人一叫张三,我们就能想出这个人是谁.文件同样如此,我们这么多文件,请问我们计算机该如何管理,这里就是给文件起一个名字,例如这个文件叫做file.txt.此时file.txt就是一个文件名.那么这里还有一个问题,我们知道如果一个班级里面只有一个张三,我们一个班级存在我们领班也存在一个张三,此时哦们说张三的时候,这个时候我们就会对是哪一个张三感到疑惑.此时我们就会说是1班的张三或者2班的张三,我们会在它们前面一个修饰限制作为区分.文件也是如此.我们正式提出文件名概念.
一个文件要有一个唯一的文件标识,以便用户识别和引用。文件名包含3部分:文件路径+文件名主干+文件后缀
例如: c:\code\test.txt
有的时候我们为了方便起见,把文件主干名当作文件名,
操作初阶
在正式谈文件操作之前,我们需要一些前置的知识.个文件我们首先想到是是它文件内容,但是有一点我们也不能忽视,就是它的属性,什么是属性呢?简单的来说就是可以描述一个文件轮廓的数据,例如我们说一个人名字叫什么,多高,是男是女…这些加在一起就可以描述出一个人的简单轮廓.文件也需要如此,我们看一下VS2013中是如何对文件经行描述的,它是一个叫FILE类型的结构体.
struct _iobuf {
char *_ptr;
int _cnt;
char *_base;
int _flag;
int _file;
int _charbuf;
int _bufsiz;
char *_tmpfname;
};
typedef struct _iobuf FILE;
打开&关闭文件
这里我们正式的谈文件操作.先来写比较简单的.
我们在想,究竟什么才算是打开一个文件,是不是把所有的文件都放在内存中,还是其它的呢?这里我想和大家说一下我的理解.前面我们谈了一个叫FILE的结构体,我在想如果我们能拿到我们想要的文件属性,我们把这些属性初始化给一个结构体,我们得到这个结构体不就是非常不错的吗?想一想,这个结构体相比叫一整个文件,占据的内存肯定会更少.所幸的是编译器也是这么设计的.不同的是编译器返回给用户的是一个指针.
好了,我们先来看看C语言是如何通过代码来打开一个文件,这也是C语言强大的表现之一.我们要谈的是一个函数,这是C语言标准库提供给我们的.
fopen
fopen是一个打开文件的函数,有两个参数,返回值是一个指向文件类型的指针,如果我们打开文件出错,此时返回值是一个空指针,并且错误码被设置.

多的不说,我们先来看一下整个文件是如何用的,后面再说它的细节.
int main()
{
//打开一个名为test.txt的文件
FILE* pf = fopen("test.txt", "w");
if (pf == NULL)
{
printf("打开文件失败\n");
return 0;
}
// 写文件
return 0;
}
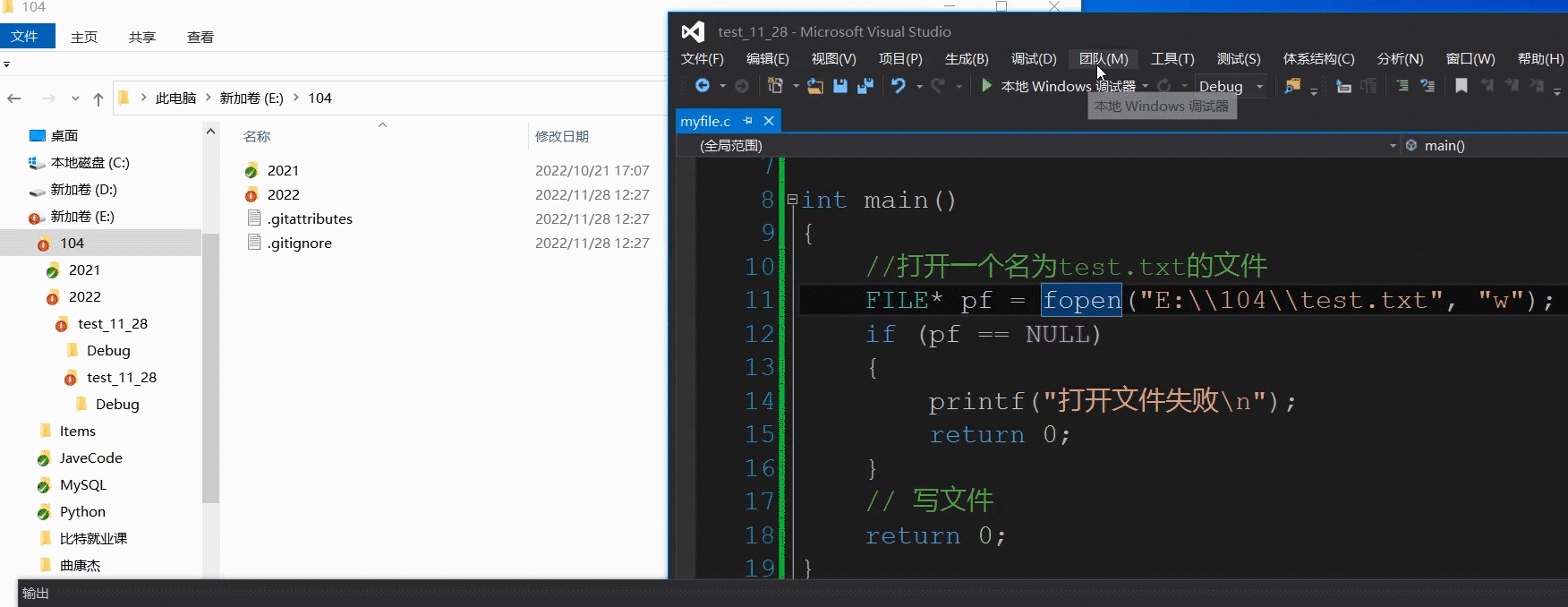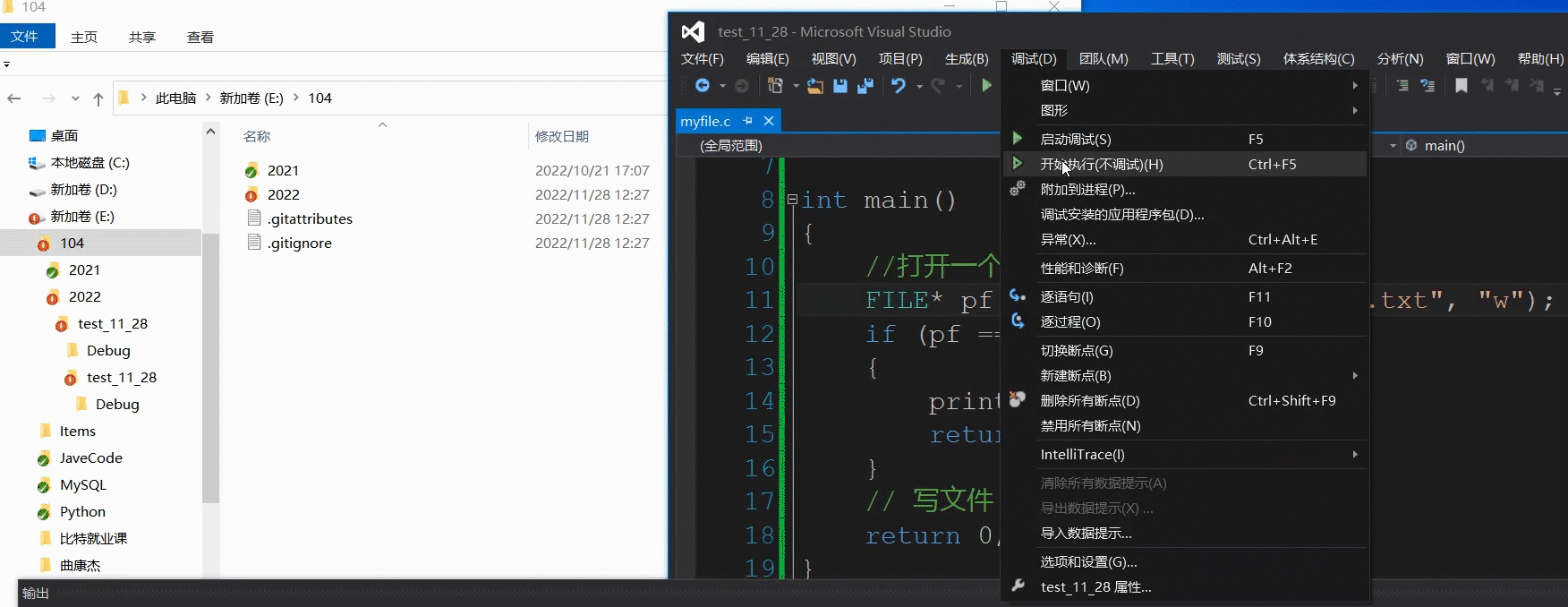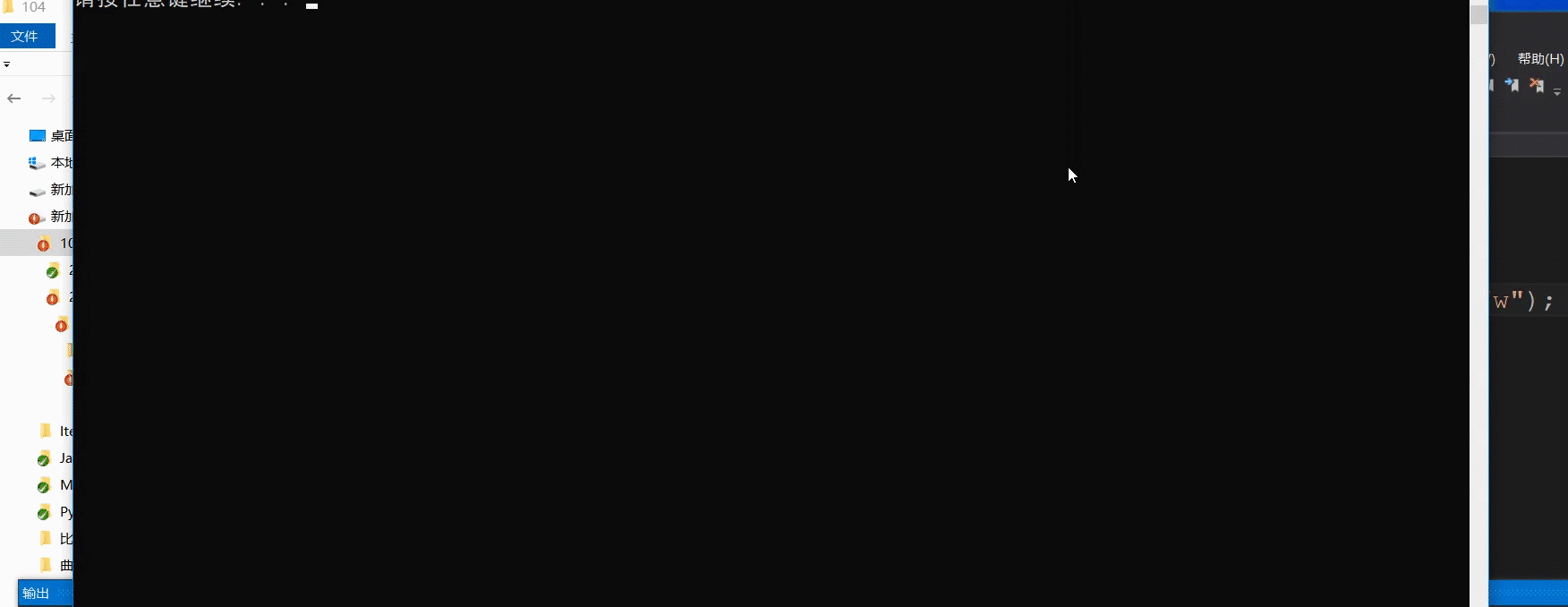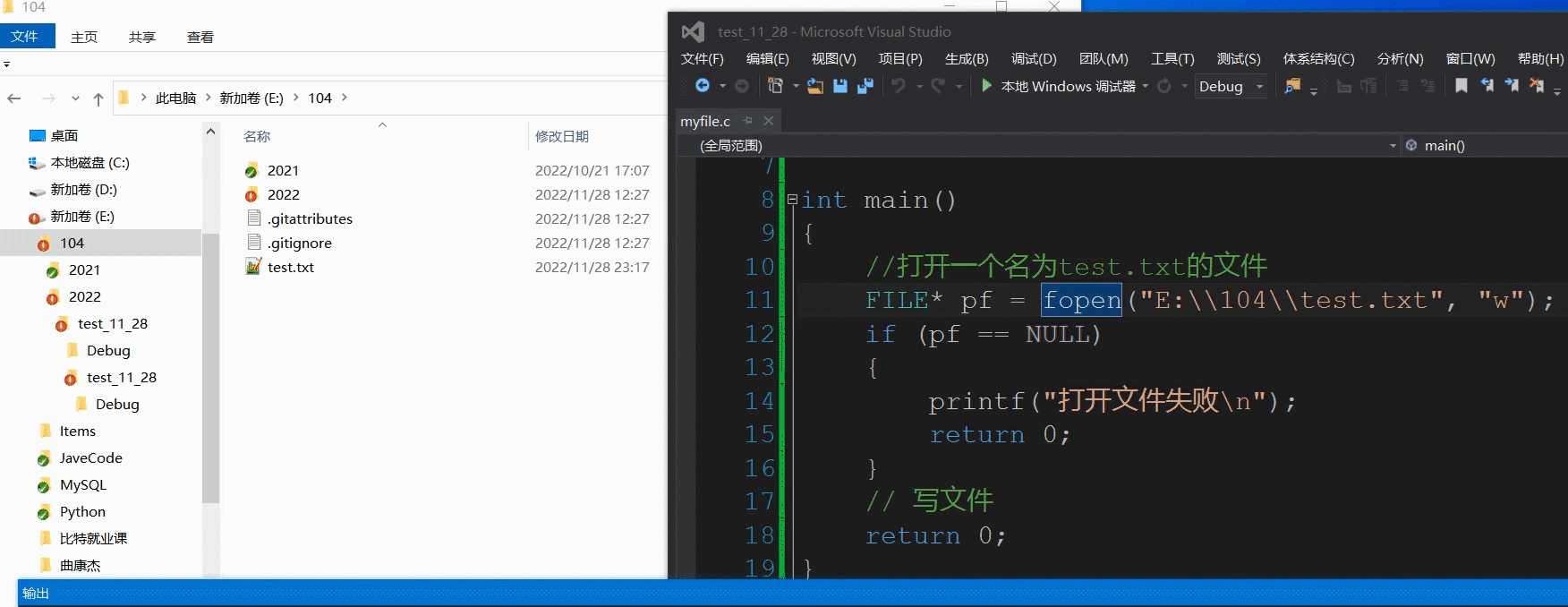
下面我们来来回答两个问题,先来说简单的.你不是说文件名包含三个部分,我这里就是一个主干,我是如何知道我们要创建的文件在哪里?这里我们解释一下,要是我们不指定创建文件的位置,计算机默认是在该代码所在的目录下,至于原因是什么,这里我们放在Linux中在谈.当然,如果我们想要指定路径创建,这里我们也是允许的,我们把文件名写全就可以了.
int main()
{
//打开一个名为test.txt的文件
FILE* pf = fopen("E:\\104\\test.txt", "w");
if (pf == NULL)
{
printf("打开文件失败\n");
return 0;
}
// 写文件
return 0;
}
好了,回答第二个问题,我们已经知道了第一个参数的作用,那么请问第二个是什么意思.如果你要是仔细看我们上面的动图你就会会发现,我们在最开始的时候,是不存在file.txt文件的,当我们程序运行完了,这个文件出现了.此时我们就要谈第二个参数的作用了.这个参数可以认为我们是如何打开文件的,或者说是以何种手段打开文件.例如"w"就是我们打开一个文件,如果这个文件不存在,我们就创建它.C语言为我们提供很多打开方式,我先列举出来,后面把重点的用一下.
| 打开方式 | 含义 | 如果文件不存在 |
|---|---|---|
| “r” | 为了输入数据,打开一个已经存在的文本文件 | 出错 |
| “w” | 为了输出数据,打开一个文本文件 | 建立一个新的文件 |
| “a” | 向文本文件尾添加数据 | 出错 |
| “rb” | 为了输入数据,打开一个二进制文件 | 出错 |
| “wb” | 为了输出数据,打开一个二进制文件 | 建立一个新的文件 |
| “ab” | 向一个二进制文件尾添加数据 | 出错 |
| “r+” | 为了读和写,打开一个文本文件 | 出错 |
| “w+” | 为了读和写,建议一个新的文件 | 建立一个新的文件 |
| “a+” | 打开一个文件,在文件尾进行读写 | 建立一个新的文件 |
| “rb+” | 为了读和写打开一个二进制文件 | 出错 |
| “wb+” | 为了读和写,新建一个新的二进制文件 | 建立一个新的文件 |
| “ab+” | 打开一个二进制文件,在文件尾进行读和写 | 建立一个新的文件 |
### fcolse
这个非常简单,就像我们之前申请了动态内存需要释放一样,当我们不用了文件之后,也需要关闭文件.这里提供了一个函数,用一下就行了.

int main()
{
FILE* pf = fopen("test.txt", "w");
if (pf == NULL)
{
printf("打开文件失败\n");
return 0;
}
// 写文件
// 关闭文件
fclose(pf);
pf = NULL; // 好习惯
return 0;
}
读写文件
打开文件后,我们就可以进行往文件的内容进行读写操作了,这里我们将会遇到一对函数,毕竟现在还在初阶,扫一下盲,打消初学者心中的害怕.
fputc & fgetc
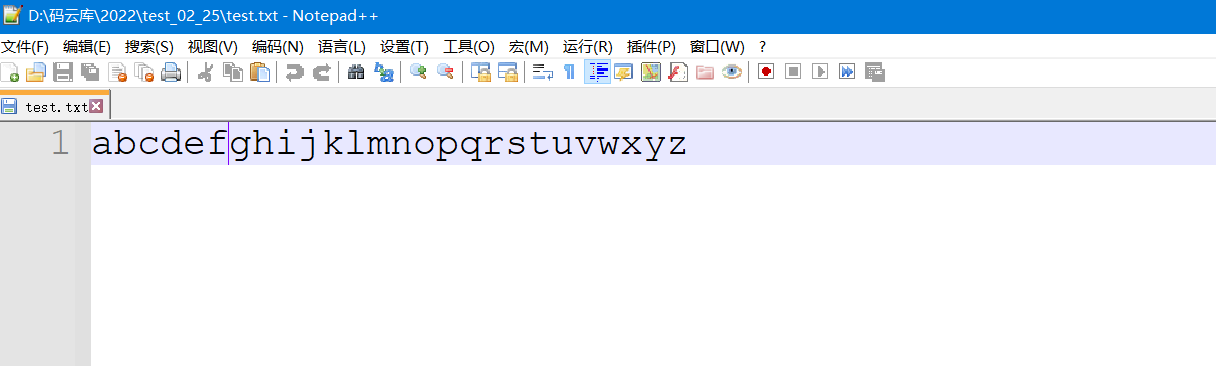
fputc函数是往指定文件中写入数据的函数,不过它是一个一个字符写入.

int main()
{
FILE* pf = fopen("test.txt", "w");
if (pf == NULL)
{
printf("%s\n", strerror(errno));
return 1;
}
//写文件
for (int ch = 'a';ch <= 'z'; ch++)
{
fputc(ch, pf);
}
printf("\n");
fclose(pf); //关闭文件
pf = NULL;
return 0;
}
fgetc函数从文件中读取一个字符,并且文件指针往后走一个(这个后面谈),返回的是这个字符的ASCII码值,当读取到文件尾是返回EOF.

#include<stdio.h>
#include<string.h>
#include<errno.h>
int main()
{
FILE* pf = fopen("test.txt", "r"); //以读的的形式打开一个名为test.txt的文件
if (pf == NULL)
{
printf("%s\n", strerror(errno));
return 1;
}
//写文件
int ch = 0;
while ((ch = fgetc(pf)) != EOF)
{
printf("%c", ch);
}
printf("\n");
fclose(pf); //关闭文件
pf = NULL;
return 0;
}
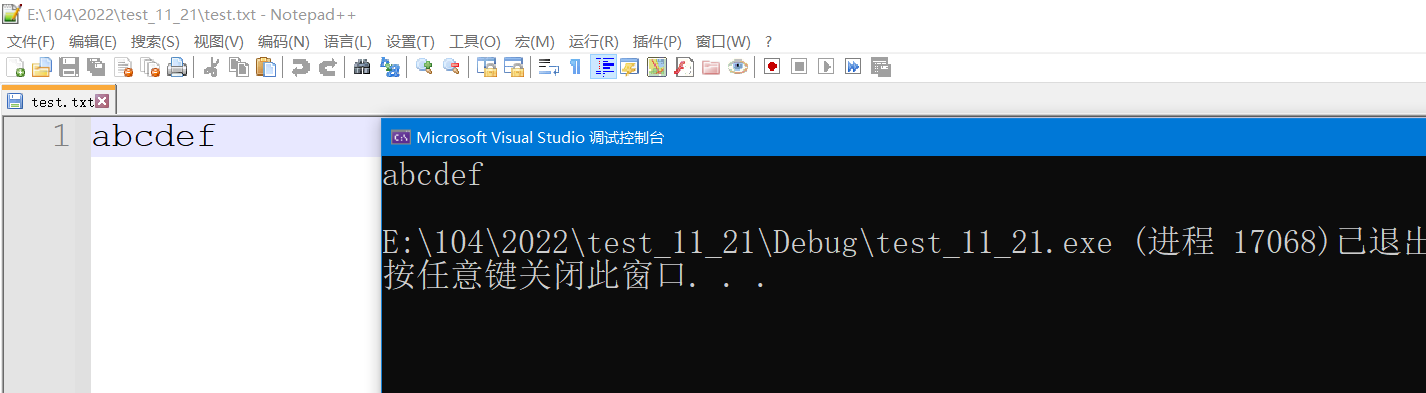
这个时候,我们就可以用写函数把写一个拷贝文件程序了.
#include<stdio.h>
#include<string.h>
#include<errno.h>
//把test.c 的内容拷贝到 test.txt中
int main()
{
FILE* wpf = fopen("test.txt", "w");
FILE* rpf = fopen("test.c", "r");
if (rpf == NULL)
{
printf("%s\n", strerror(errno));
fclose(wpf);
wpf = NULL;
return 1;
}
//拷贝
int ch = 0;
while ((ch = fgetc(rpf)) != EOF)
{
fputc(ch, wpf);
}
//关闭文件
fclose(rpf);
rpf = NULL;
fclose(wpf);
wpf = NULL;
return 0;
}
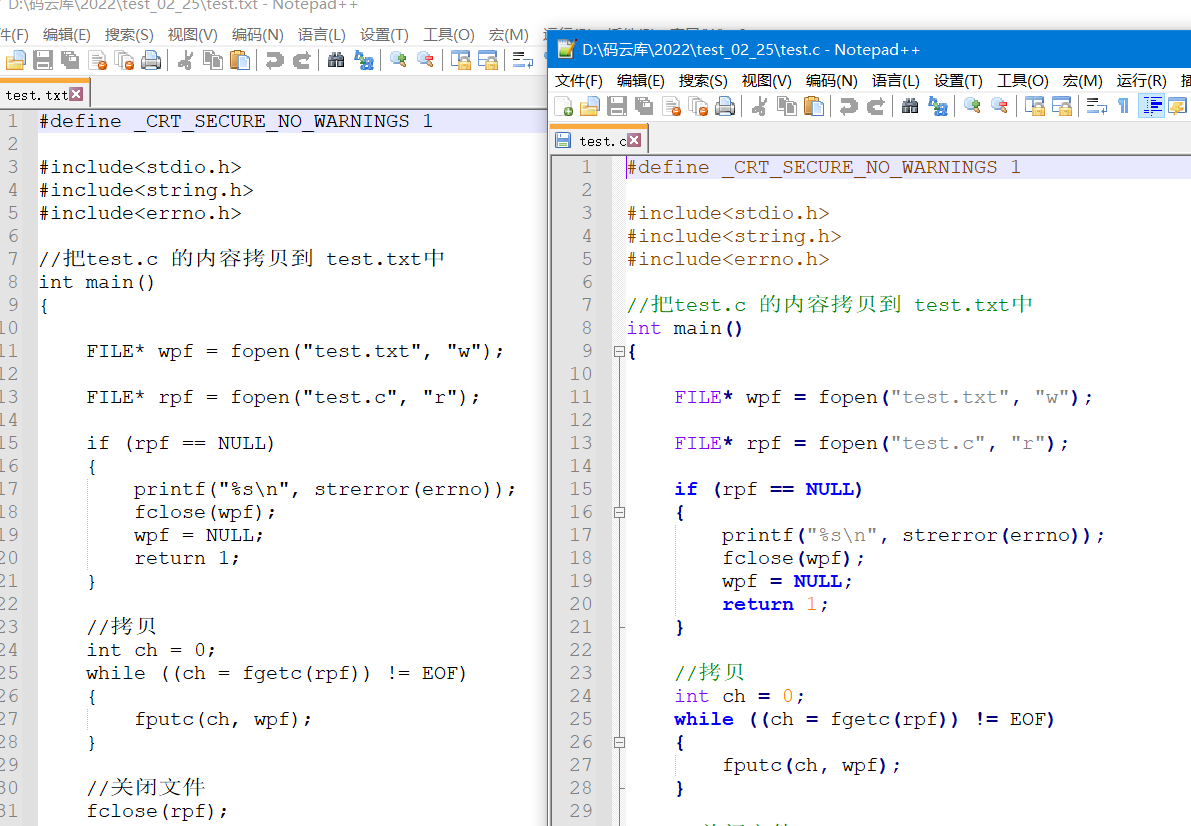
文件缓冲区
这里补充一下,上面我们已经知道了FILE.这里我们需要补充点东西.文件缓冲区.对一个FILE结构体来说,它里面会存在一个叫做缓冲区的概念,你可以把它理解成一片空间,在写文件时,数据会暂时保存在这个空间中,等到必要的时候才会刷新到硬盘中.
文件指针
缓冲文件系统中,关键的概念是“文件类型指针”,简称“文件指针”,也就是FILE*.那么这里面我们就可以看一下我们之前谈的标准输入和标准输出了,这里将会解释我们很早的博客如何使用它.

我们很容易的发现,它们三个都是FILE*的指针,那么它们肯定会指向一些东西.我们先把它们指向的写出来,知道就可以,等到Linux中我们重点分析.
- stdin 键盘
- stdout 显示器
- stderr 显示器
操作进阶
到这里,我们已经初步的认识文件了,这里我们需要把它给完整的谈一下,不是上面的草草了事.这里我们需要认识几个新的内容.
打开方式
上面一直没有谈打开的方式,毕竟大家还对文件有点不太熟悉.这里我那重点的谈几个.
“w”(只写)
这个上面我们已经说过了,以读的形式打开一个已经存在的文本文件,如果这个文件不存在,我们就创建它.那么要是这个文件存在,并且里面存在内容呢?这个是我们要考虑的.
int main()
{
FILE* pf = fopen("test.txt", "w");
// 这里就不判断了
fclose(pf);
pf = NULL; // 好习惯
return 0;
}

此时我们就会发现,如果以"w"的方式打开,那么原本的文件内容就会被清空.
“r”(只读)
上面还没有测试过打开文件失败的场景,这里试一下吧,如果以读的形式打开,当文件不存在的时候,就会出错.
int main()
{
FILE* pf = fopen("mytest.txt", "r");
if (pf == NULL)
{
printf("%s\n", strerror(errno));
return 1;
}
return 0;
}
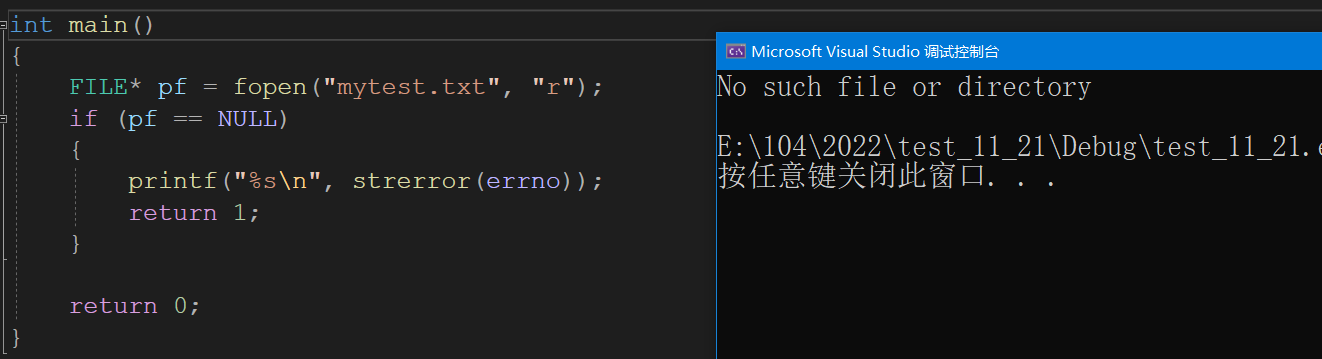
“a”(追加)
上面我们发现只读的话,程序会把文件清空,这个不是我们想要的,这里又出现了一种方式,我们以"a"的方式打开文件,如果这个文件不存在,就会出错,如果存在了,并且里面含有内容,我们是在文件的末尾插入数据,并不会清空原本的数据.
int main()
{
FILE* pf = fopen("test.txt", "a");
//写文件
for (int ch = 'a'; ch <= 'z'; ch++)
{
fputc(ch, pf);
}
fclose(pf); //关闭文件
pf = NULL;
return 0;
}

文件的顺序读写
现在我们要开始认识读写文件的其他函数,大家看一下标题就会明白,我们是顺序读写,这里解释一下,我们简单的认为顺序读写就是把一个文件从头到尾的读或者写.这样理解是有必要的,后面我们将会学习到随机读写.
fgets & fputs
上面我们的都是一个一个字符读取,fgets是一次性几个字符的读取,使用方法是一样的.

int main()
{
FILE* pf = fopen("test.txt", "r");
char buffer[1024] = { 0 };
while (fgets(buffer, sizeof(buffer),pf) != NULL)
{
printf("%s", buffer);
memset(buffer, '\0', sizeof(buffer));
}
fclose(pf); //关闭文件
pf = NULL;
return 0;
}

这里需要我们注意的是,我们该如何理解这个函数.我们先把函数给拿下来,这里分析一下.算是补充一下字符串那里没说谈的.
char *fgets( char *string, int n, FILE *stream );
我们重点谈一下这个n.这个n表示我们一次性要从stream 中读入的最多字符个数.想一想,我们这里是C语言,也就是字符串的最后面默认是’\0’.好了,条件已经够了,这里开始分析这个函数了.假设stream中存在足够多的字符,如果sizeof(string)的空间小于或者等于n,那么我们一次性会会读取sizeof(string)-1个字符,原因就是我们要保证最后一个是’\0’.
int main()
{
FILE* pf = fopen("test.txt", "r");
char buffer[4] = { 0 };
while (fgets(buffer, sizeof(buffer),pf) != NULL)
{
printf("%s", buffer);
memset(buffer, '\0', sizeof(buffer));
}
fclose(pf); //关闭文件
pf = NULL;
return 0;
}

fputs一个一次性写入多个字符的函数.
int main()
{
FILE* pf = fopen("test.txt", "w");
char buffer[10] = { 'a', 'b', 'c', 'd', 'e', 'f','\n'};
for (int i = 0; i < 5; i++)
{
fputs(buffer, pf);
}
fclose(pf); //关闭文件
pf = NULL;
return 0;
}
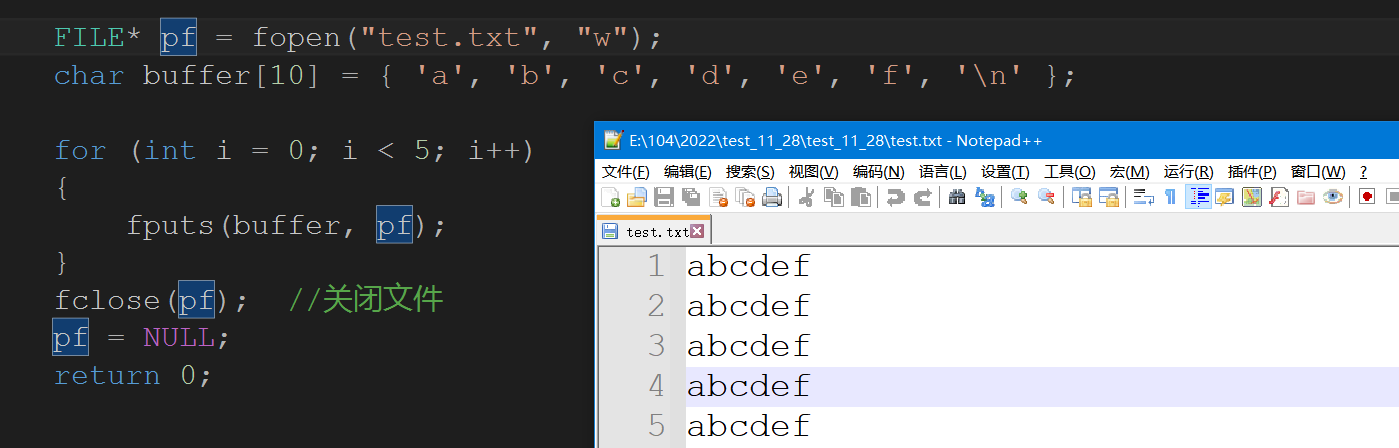
fprintf&fscanf
我们前面一直用格式话输入输出,今天我们再来看一下文件的格式话输入输出.如果你会printf/scanf,那么这组函数对你也不是问题.
fprintf格式化的向文件种打印数据.
struct Person
{
char name[15];
int age;
char sex[10];
};
int main()
{
FILE* pf = fopen("test.txt", "w"); // 按照二进制写问文件
struct Person per = { "张三", 18, "男" };
fprintf(pf,"%s %d %s\n", per.name, per.age, per.sex);
fclose(pf);
pf = NULL;
return 0;
}
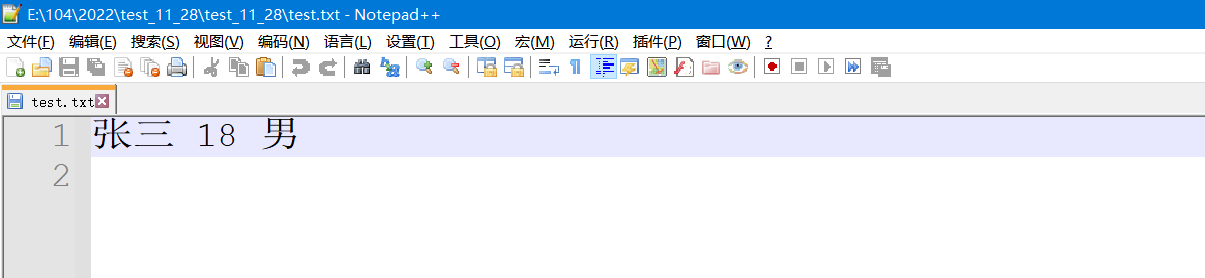
fscanf是一个读取函数.也是很简单的.
int main()
{
FILE* pf = fopen("test.txt", "r");
struct Person per ;
fscanf(pf, "%s %d %s\n", &per.name, &per.age, &per.sex);
printf("%s %d %s\n", per.name, per.age, per.sex);
fclose(pf);
pf = NULL;
return 0;
}
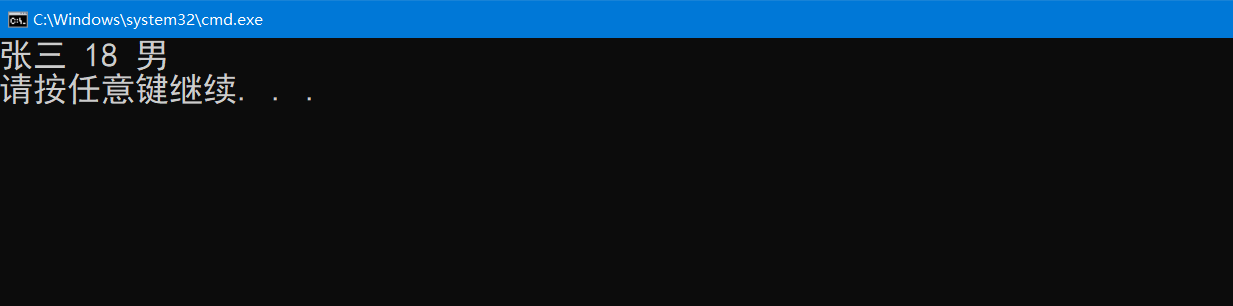
注意,使用fscanf的时候,他遇到’\n’就会停止读取.
int main()
{
FILE* pf = fopen("test.txt", "r");
char ch[100] = { 0 };
fscanf(pf, "%s", ch);
printf("%s", ch);
return 0;
}
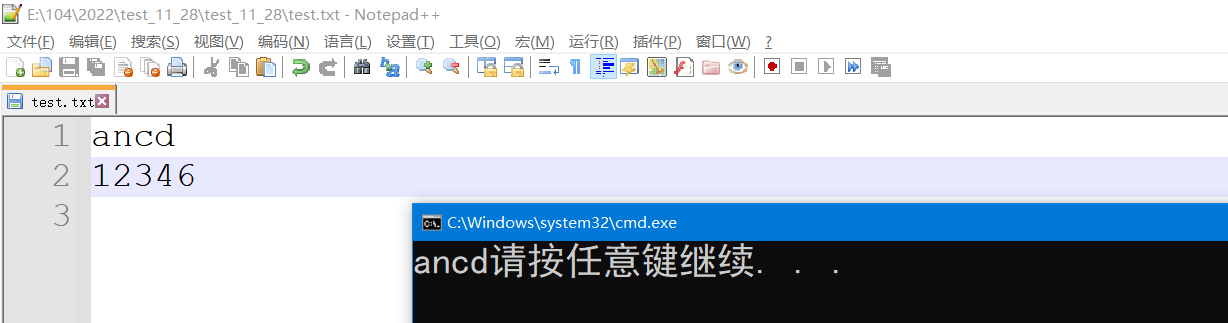
fwrite&fread
最后一组顺序读取的函数,这个还是比较简单的.
fwrite是一个向文件中写入的函数,里面的参数还是比较多的.第一个参数buffer指向要被写的数据元素,即为起始地址,第二个参数size是每个要写元素的大小,第三个参数count是要被写的元素个数.这个函数没有什么要说的.
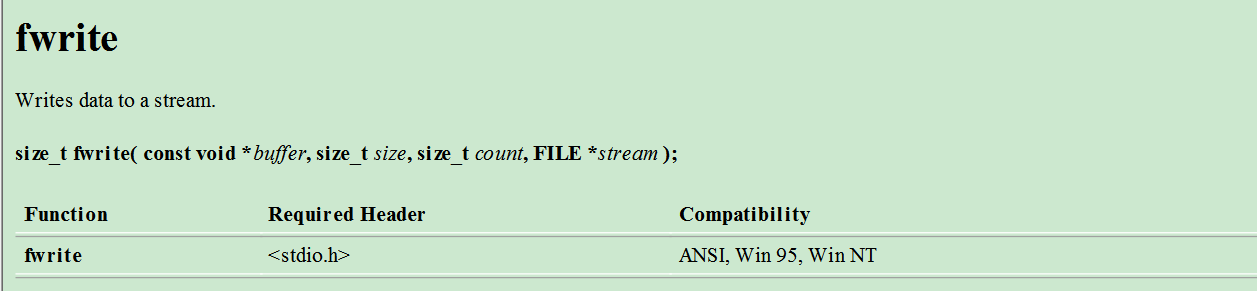
int main()
{
FILE* pf = fopen("test.txt", "w");
char* buffer = "我是一个学习者";
for (int i = 0; i < 5; i++)
{
fwrite(buffer, strlen(buffer), sizeof(char), pf);
}
fclose(pf); //关闭文件
pf = NULL;
return 0;
}
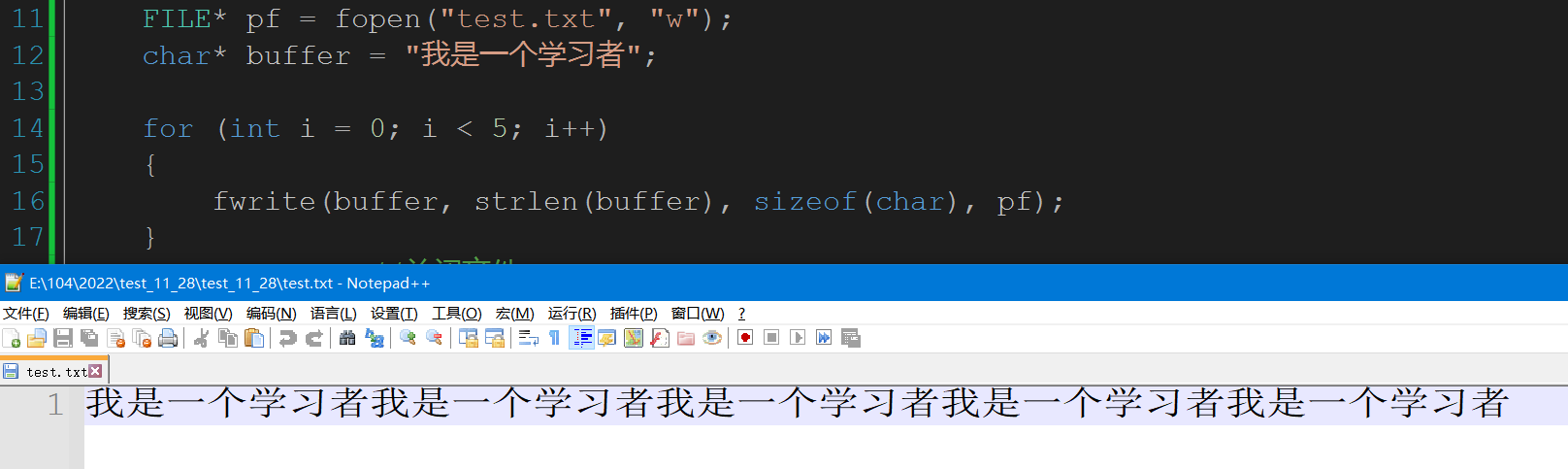
这里我有一个问题,这里我们为何传入是strlen(buffer),不是我们字符串后面应该是一个’\0’吗?注意,这是字符串以’\0’是C语言的规定,文件可不是按照这个来的,所以我们只要把有效元素写入就好了,要是我们加了一个1,这里就会出现问题.
int main()
{
FILE* pf = fopen("test.txt", "w");
char* buffer = "我是一个学习者";
for (int i = 0; i < 5; i++)
{
fwrite(buffer, strlen(buffer)+1, sizeof(char), pf);
}
fclose(pf); //关闭文件
pf = NULL;
return 0;
}

fread函数是一个读取函数,很简单.
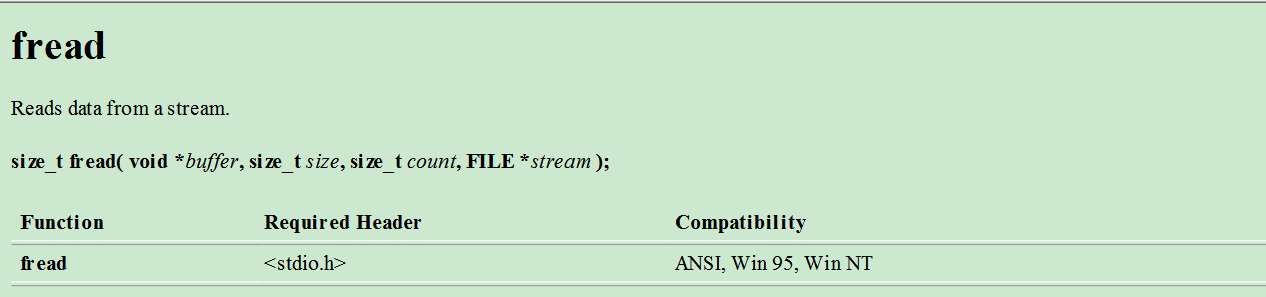
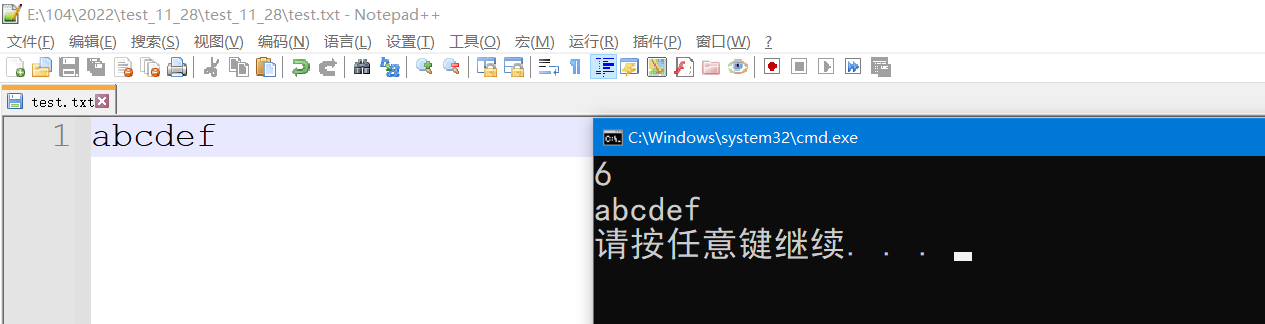
int main()
{
FILE* pf = fopen("test.txt", "r");
char buffer[1024] = { 0 };
memset(buffer, '\0', sizeof(buffer));
int s = fread(buffer, sizeof(char), sizeof(buffer), pf);
// abcde -- 5个有效字符
buffer[s] = '\0'; // C语言模式
printf("%d\n", s);
printf("%s\n", buffer);
fclose(pf); //关闭文件
pf = NULL;
return 0;
}
对比一组函数
我们这里对比一组函数,详细的谈一下.
适用于标准输入/输出流的格式化的输入/输出语句
scanf:按照一定的格式从键盘输入数据
printf:按照一定的格式把数据打印(输出)到屏幕上
适用于所有的输入/输出流的格式化输入/输出语句
fscanf:按照一定的格式从输入流(文件/stdin)输入数据
fprintf:按照一定的格式向输出流(文件/stdout)输出数据
sscanf & sprintf
sprintf:把格式化的数据按照一定的格式转换为字符串

struct Person
{
char name[15];
int age;
char sex[10];
};
int main()
{
struct Person per = { "张三", 18, "男" };
char buffer[100];
sprintf(buffer, "%s %d %s\n", per.name, per.age, per.sex);
printf("%s\n", buffer);
return 0;
}
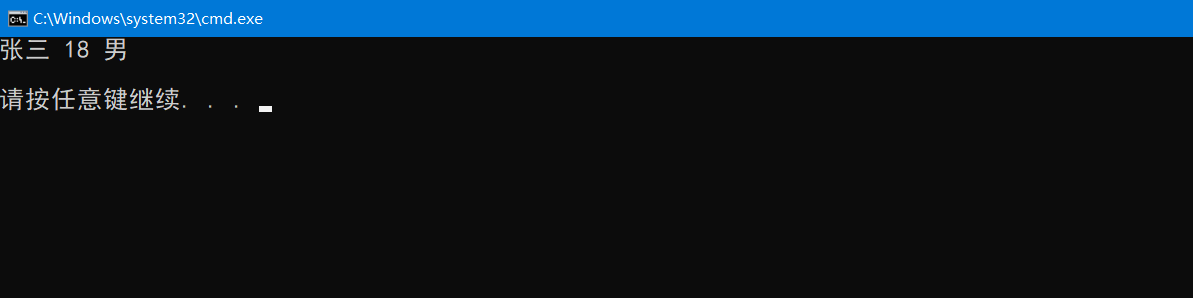
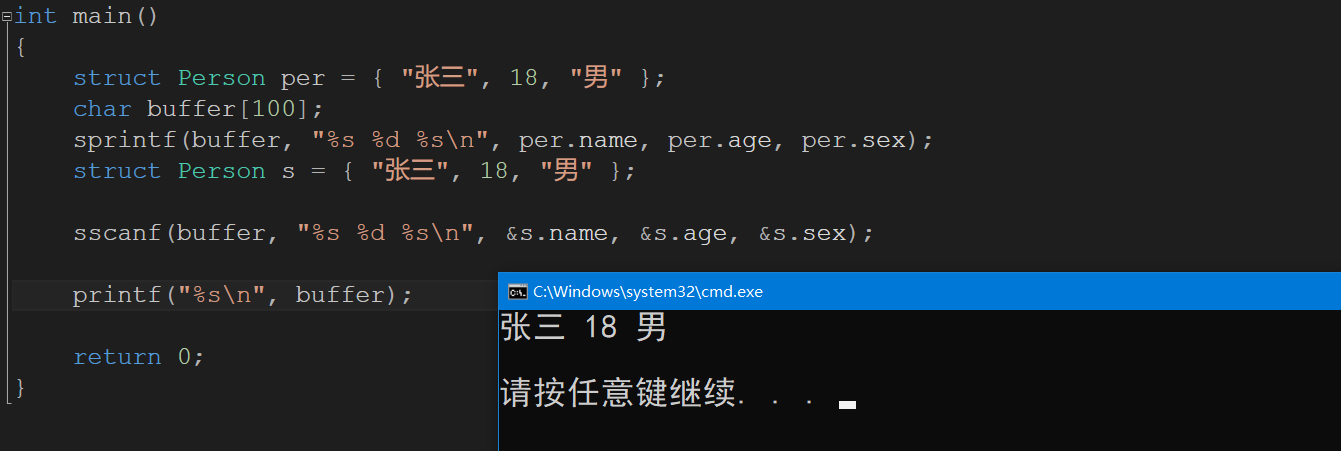
既然我们可以格式化转化成数组,那么我们可以改变回来吗? sscanf就是从字符串中按照一定的格式读取出格式化的数,

int main()
{
struct Person per = { "张三", 18, "男" };
char buffer[100];
sprintf(buffer, "%s %d %s\n", per.name, per.age, per.sex);
struct Person s = { "张三", 18, "男" };
sscanf(buffer, "%s %d %s\n", &s.name, &s.age, &s.sex);
printf("%s\n", buffer);
return 0;
}
文件的随机读写
在最开始的时候,我们使用fgetc来读取数据,我们并没有说它是如何实现的,包括上面的几组元素我们都没有谈,现在我们需要谈的必要了.
我们是不是可以认为在FILE结构体中,里面保存这一个指针,指向我们的数据,我们没读一次,这个指针都会移动相应的距离.我们来证明一下自己的观点.
int main()
{
FILE* pf = fopen("test.txt", "r");
fgetc(pf);
printf("pf->_ptr %p char %c\n", pf->_ptr, *pf->_ptr);
fgetc(pf);
printf("pf->_ptr %p char %c\n", pf->_ptr, *pf->_ptr);
fgetc(pf);
printf("pf->_ptr %p char %c\n", pf->_ptr, *pf->_ptr);
fclose(pf); //关闭文件
pf = NULL;
return 0;
}
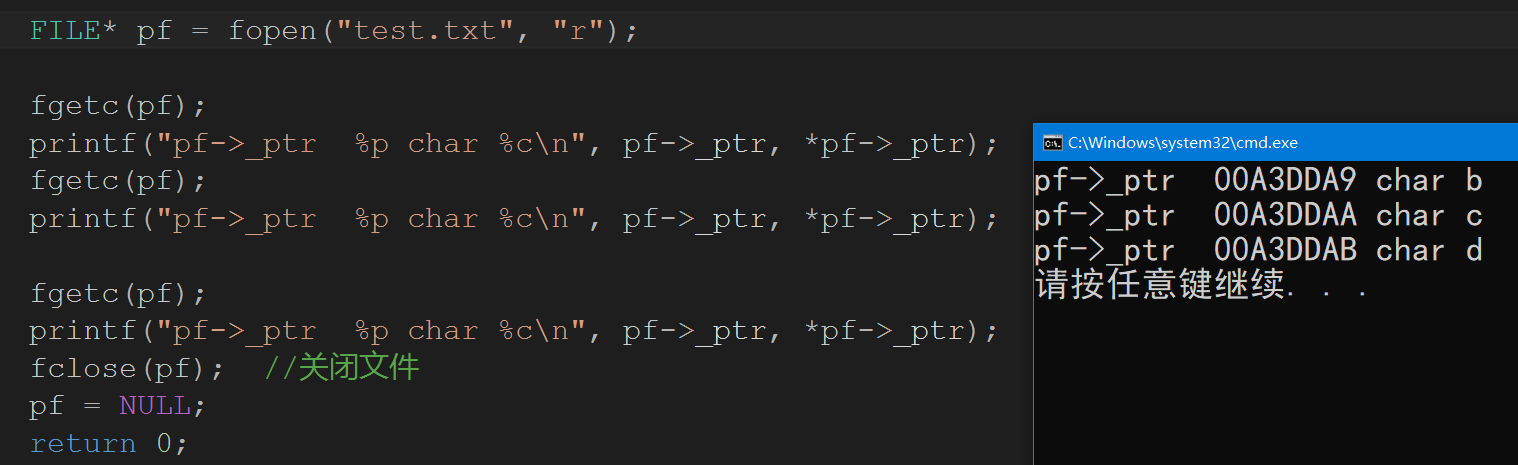
此时我们就明白了自己是对的,虽然我们并不了解底层,但是大致思路是没有错的,此时就引出的我们这个话题,文件的随机读写.前面一直都是从头开始读,我们写入的时候不是清空就是追加.那么我们是不是可以从文件的任意位置开始呢?实际上,C语言是支持的.文件的随机读写中,文件指针的位置通过在相应的位置加上偏移量,让文件指针随时随地指向想要读取的位置,实现随机读取。
fseek
这个函数是根据文件指针的位置和偏移量来定位文件指针,我们看一下.

我们 先来解释一下他的参数,第二个参数offset是偏移量.基本单位是字节.第三个参数origin是起始位置.关于起始位置存在3种情况.下面同一测试一下.
| 宏 | 含义 |
|---|---|
| SEEK_SET | 文件开头 |
| SEEK_CUR | 当前位置 |
| SEEK_END | 文件结尾 |
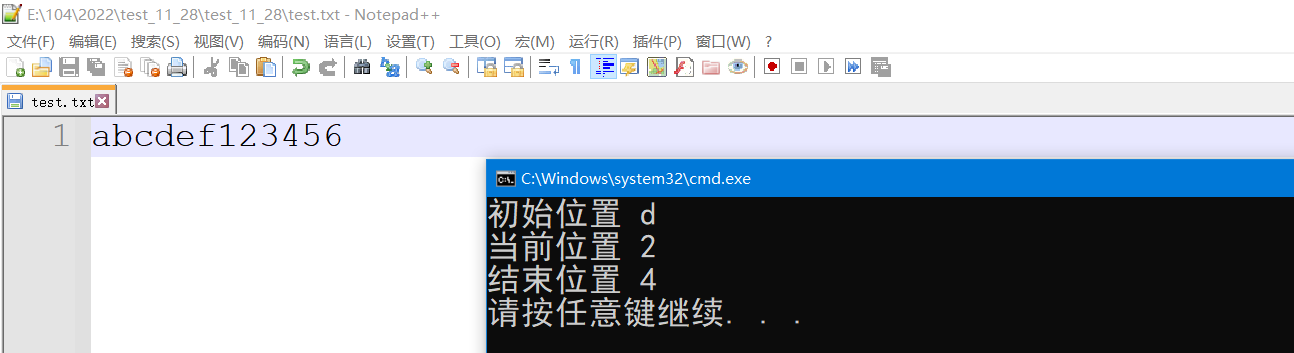
int main()
{
int ch = 0;
FILE* pf = fopen("test.txt", "r");
if (pf == NULL)
{
perror("fopen");
return 1;
}
// 初识位置偏移 3个
fseek(pf, 3, SEEK_SET);
ch = fgetc(pf);
printf("初始位置 %c\n", ch);
fseek(pf, 3, SEEK_CUR);
ch = fgetc(pf);
printf("当前位置 %c\n", ch);
fseek(pf, -3, SEEK_END);
ch = fgetc(pf);
printf("结束位置 %c\n", ch);
fclose(pf);
pf = NULL;
return 0;
}
ftell
这个函数是计算指针距离初始位置的偏移量.

int main()
{
int ch = 0;
FILE* pf = fopen("test.txt", "r");
if (pf == NULL)
{
perror("fopen");
return 1;
}
// 初识位置偏移 3个
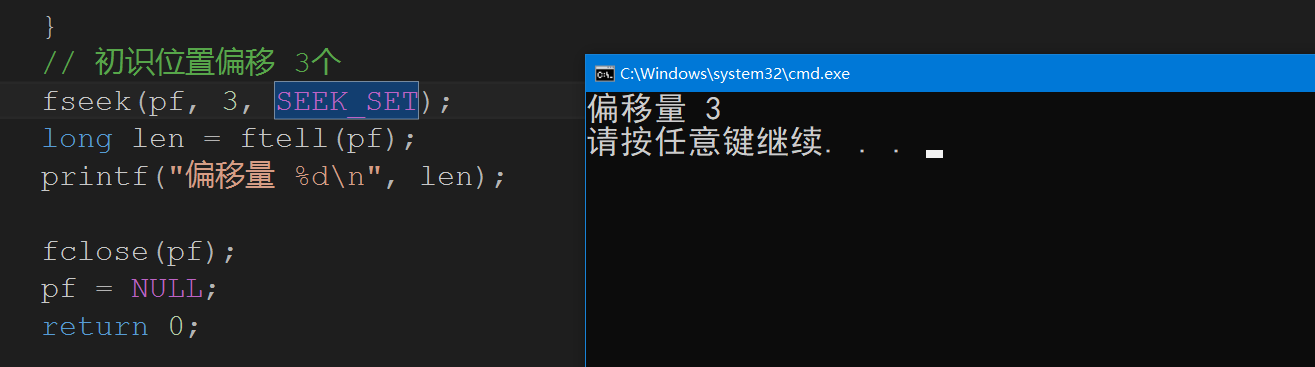
fseek(pf, 3, SEEK_SET);
long len = ftell(pf);
printf("偏移量 %d\n", len);
fclose(pf);
pf = NULL;
return 0;
}
rewind
让文件指针的位置回到文件的起始位置,都没什么难的.
int main()
{
int ch = 0;
FILE* pf = fopen("test.txt", "r");
if (pf == NULL)
{
perror("fopen");
return 1;
}
// 初识位置偏移 3个
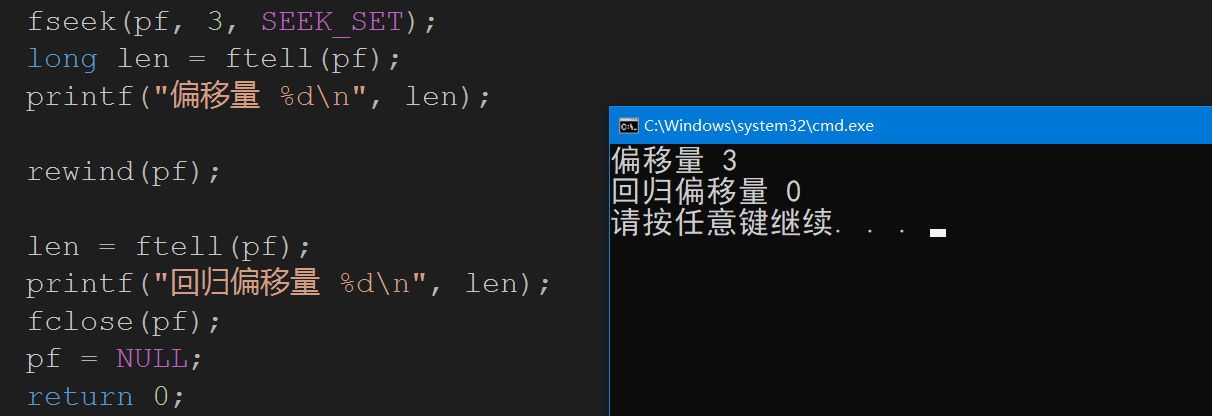
fseek(pf, 3, SEEK_SET);
long len = ftell(pf);
printf("偏移量 %d\n", len);
rewind(pf);
len = ftell(pf);
printf("回归偏移量 %d\n", len);
fclose(pf);
pf = NULL;
return 0;
}
文件结束标志
上面我们一直忽略了什么时候文件读取结束,这一点对我们来说还是比较重要的.这里做一个补充.
文本文件 & 二进制文件
我们通常可以看到的文件分为两种,上面谈过了.文本文件是我们肉眼可以看懂的文件,上面的我们都是文本文件进行的操作.下面我们试一下二进制文件.
struct Person
{
char name[15];
int age;
char sex[10];
};
int main()
{
int ch = 0;
FILE* pf = fopen("test.txt", "wb"); // 按照二进制写问文件
if (pf == NULL)
{
perror("fopen");
return 1;
}
struct Person p = { "张三", 18, "男" };
fwrite(&p, sizeof(struct Person), 1, pf);
fclose(pf);
pf = NULL;
return 0;
}
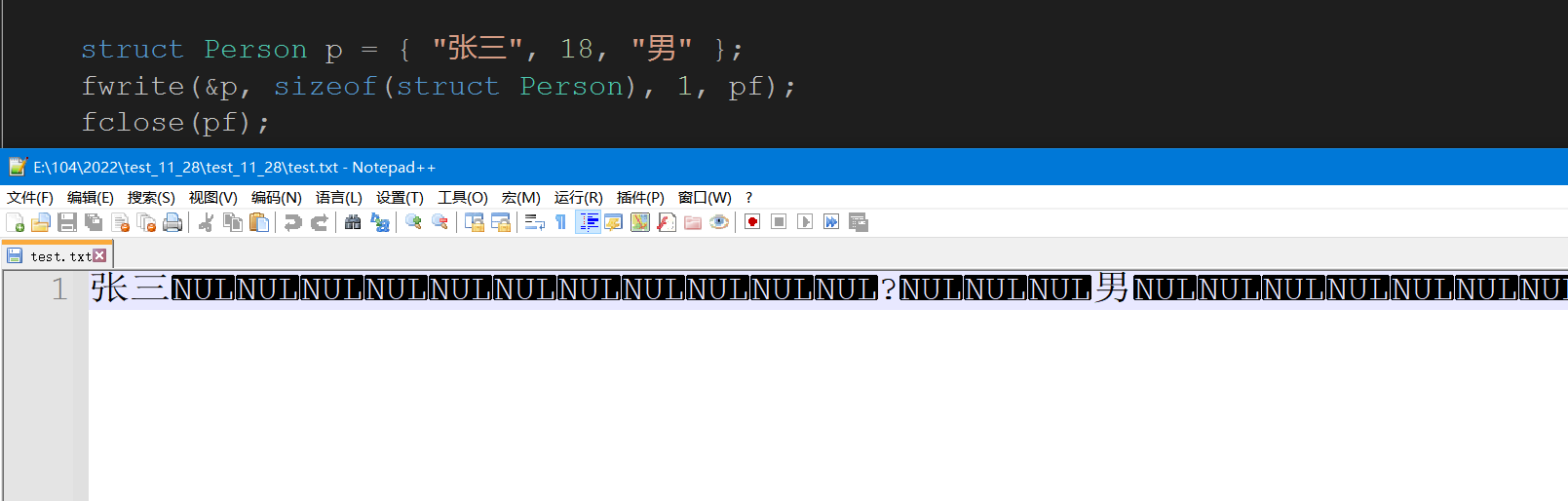
这里出现乱码是因为这里是二进制文件,我们打开的方式是文本形式,故编程了乱码.这里我们能读出来就可以了.
int main()
{
int ch = 0;
FILE* pf = fopen("test.txt", "rb"); // 按照二进制写问文件
if (pf == NULL)
{
perror("fopen");
return 1;
}
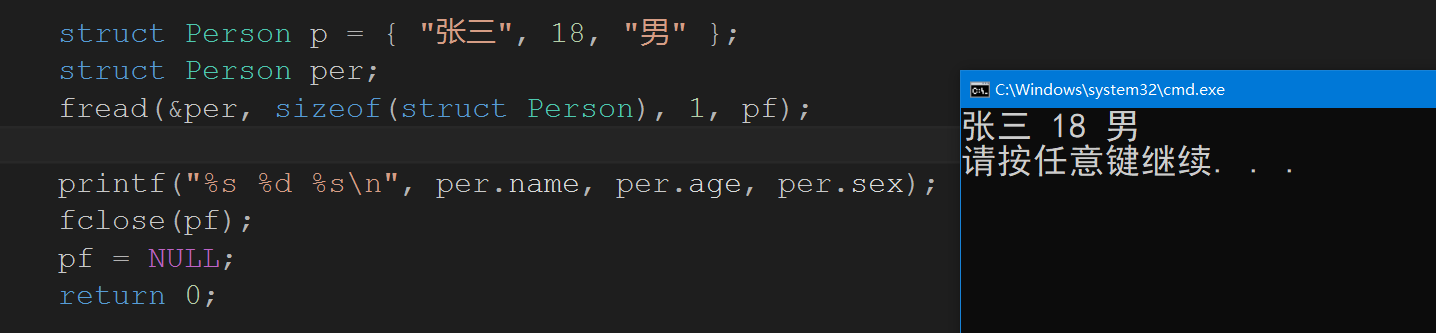
struct Person p = { "张三", 18, "男" };
struct Person per;
fread(&per, sizeof(struct Person), 1, pf);
printf("%s %d %s\n", per.name, per.age, per.sex);
fclose(pf);
pf = NULL;
return 0;
}
下面我在通过一个列子来区别一下二进制文件和文本文件.假设我们要存储一个数字10000,那么那么有两种存储方式.

下面的就是二进制存储的方式.
int main()
{
int a = 10000;
FILE* pf = fopen("test.txt", "wb"); // 按照二进制写问文件
fwrite(&a, 4, 1, pf);
fclose(pf);
return 0;
}
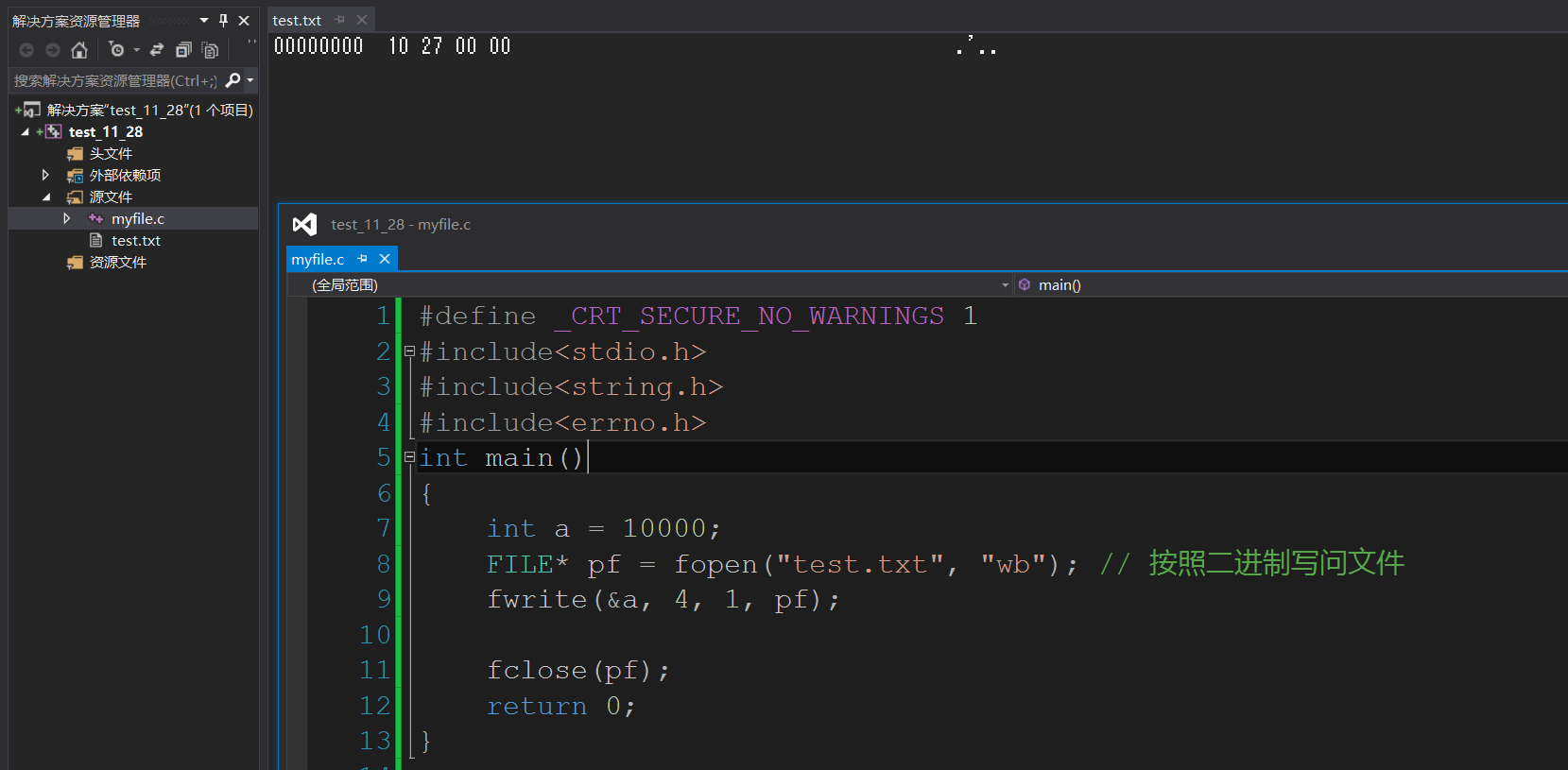
文件结束的判定
我们有很多读取的函数,但是总有一个时刻文件读取结束,那么什么时候读取结束呢?说了这么多,我还是没有和大家说如何判断文件读取结尾了,这里很简单的.
- 文本文件读取是否结束,判断返回值是否为EOF (fgetc),或者NULL(fgets)
- 二进制文件的读取结束判断,判断返回值是否小于实际要读的个数。
feof
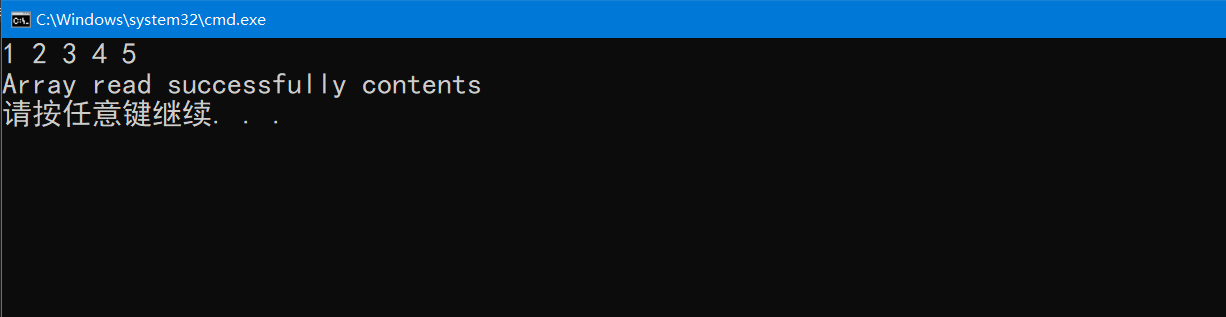
这个函数,不是为了判断文件的是否结束.而是当我们已经知道读取文件结束了,用来判断是什么原因导致文件结束了,例如是到文件尾了,还是读取错误了.我们用下这个函数,很简单.
int main()
{
// 写文件
int arr[5] = { 1, 2, 3, 4, 5 };
FILE* pf = fopen("test.txt", "wb");
if (pf == NULL)
{
perror("fopen");
return 1;
}
fwrite(arr, sizeof(int), 5, pf);
fclose(pf);
pf = NULL;
// 读文件
int a[5] = { 0 };
int count = 5;
int num = 0;
int i = 0;
//打开文件
pf = fopen("test.txt", "rb");
if (pf == NULL)
{
perror("fopen");
return 1;
}
num = fread(a, sizeof(int), 5, pf);
if (num == count) //读取五个元素后正好到达文件结尾
{
for (i = 0; i < count; i++)
{
printf("%d ", a[i]);
}
puts("\nArray read successfully contents");
}
else
{
if (feof(pf))
{
printf("Error reading test.txt:unexpected end of file\n");
}
else if (ferror(pf))
{
perror("Error reading test.txt");
}
}
fclose(pf);
pf = NULL;
return 0;
}

![[附源码]计算机毕业设计springboot车险销售管理系统论文](https://img-blog.csdnimg.cn/1789cd835d764ab4af7d7a575e31e784.png)
![[附源码]计算机毕业设计springboot房屋租赁信息系统](https://img-blog.csdnimg.cn/c2d0a4181baa488aa28e44e30014726f.png)



![[附源码]计算机毕业设计springboot高校社团管理系统](https://img-blog.csdnimg.cn/bd45fd0805a64cfdba5b153e3f6cf508.png)