文章目录
- 1.什么是前缀索引
- 2.什么是索引选择性
- 3.创建前缀索引
- 3.1 一个小案例
- 3.2 前缀索引
- 3.3 一个问题
- 4. 回到开始的问题
- 5.小结
我们在项目的具体实践中,有时候会遇到一些比较特殊的字段,例如身份证号码。
松哥之前有一个小伙伴做黑龙江省的政务服务网,里边有一些涉及到用户身份证存储的场景,由于存储的数据大部分都是当地的,此时如果想给身份证号码建立索引的话,小伙伴们知道,身份证前六位是地址码,在这样的场景下,给身份证字段建立索引的话,前六位的区分度是很低的,甚至前十位的区分度都很低(因为出生年份毕竟有限,一个省份上千万人口,出生年份重复率是很高的),不仅浪费存储空间,查询性能还低。
那么有没有办法解决这个问题呢?我们今天就来聊一聊前缀索引,聊完之后相信大家自己就有答案了。
1.什么是前缀索引
有时候为了提升索引的性能,我们只对字段的前几个字符建立索引,这样做既可以节约空间,还能减少字符串的比较时间,B+Tree 上需要存储的索引字符串更短,也能在一定程度上降低索引树的高度,提高查询效率。
MySQL 中的前缀索引有点类似于 Oracle 中对字段使用 Left 函数来建立函数索引,只不过 MySQL 的这个前缀索引在查询时是内部自动完成匹配的,并不需要使用 Left 函数。
不过前缀索引有一个缺陷,就是有可能会降低索引的选择性。
2.什么是索引选择性
关于索引的选择性(Index Selectivity),它是指不重复的索引值(也称为基数 cardinality)和数据表的记录总数的比值,取值范围在 (0,1] 之间。索引的选择性越高则查询效率越高,因为选择性高的索引可以让 MySQL 在查找时过滤掉更多的行。
那有小伙伴要问了,是不是选择性越高的索引越好呢?当然不是!索引选择性最高为 1,如果索引选择性为 1,就是唯一索引了,搜索的时候就能直接通过搜索条件定位到具体一行记录!这个时候虽然性能最好,但是也是最费空间的,这不符合我们创建前缀索引的初衷。
我们一开始之所以要创建前缀索引而不是唯一索引,就是希望能够在索引的性能和空间之间找到一个平衡,我们希望能够选择足够长的前缀以保证较高的选择性(这样在查询的过程中就不需要扫描很多行),但是又希望索引不要太过于占用存储空间。
那么我们该如何选择一个合适的索引选择性呢?索引前缀应该足够长,以便前缀索引的选择性接近于索引的整个列,即前缀的基数应该接近于完整列的基数。
首先我们可以通过如下 SQL 得到全列选择性:
SELECT COUNT(DISTINCT column_name) / COUNT(*) FROM table_name;
然后再通过如下 SQL 得到某一长度前缀的选择性:
SELECT COUNT(DISTINCT LEFT(column_name, prefix_length)) / COUNT(*) FROM table_name;
在上面这条 SQL 执行的时候,我们要注意选择合适的 prefix_length,直至计算结果约等于全列选择性的时候,就是最佳结果了。
3.创建前缀索引
3.1 一个小案例
举个例子,我们来创建一个前缀索引看看。
松哥这里使用的数据样例是网上找的一个测试脚本,有 300W+ 条数据,做 SQL 测试优化是够用了,小伙伴们在公众号后台回复 mysql-data-samples 获取脚本下载链接。
我们来大致上看下这个表结构:

这个表有一个 user_uuid 字段,我们就在这个字段上做文章。
Git 小伙伴们应该都会用吧?不同于 Svn,Git 上的版本号不是数字而是一个 Hash 字符串,但是我们在具体应用的时候,比如你要做版本回退,此时并不需要输入完整的的版本号,只需要输入版本号前几个字符就行了,因为根据前面这一部分就能确定出版本号了。
那么这张表里边的 user_uuid 字段也是这意思,如果我们想给 user_uuid 字段建立索引,就没有必要给完整的字符串建立索引,我们只需要给一部分字符串建立索引。
可能有小伙伴还是不太明白,我举一个例子,比如说我现在想按照 user_uuid 字段来查询,但是查询条件我没有必要写完整的 user_uuid,我只需要写前面一部分就可以区分出我想要的记录了,我们来看如下一条 SQL:

大家看到,user_uuid 我只需要给出一部分就能唯一锁定一条记录。
当然,上面这个 SQL 是松哥测试过的,给定的
'39352f%'条件不能再短了,再短就会查出来两条甚至多条记录。
通过上面这个例子我们就可以看出来,如果给 user_uuid 字段建立索引,可能并不需要给完整的字符串建立索引,只需要给一部分前缀字符串建立索引。
那么给前面几个字符串建立索引呢?这个可不是拍脑门,需要科学计算,我们继续往下看。
3.2 前缀索引
首先我们通过如下 SQL 来看一下 user_uuid 全列索引选择性是多少:
SELECT COUNT(DISTINCT user_uuid) / COUNT(*) FROM system_user;

可以看到,结果为 1。全列选择性为 1 说明这一列的值都是唯一不重复的。
接下来我们先来试几个不同的 prefix_length,看看选择性如何。
松哥这里一共测试了 5 个不同的 prefix_length,大家来看看各自的选择性:
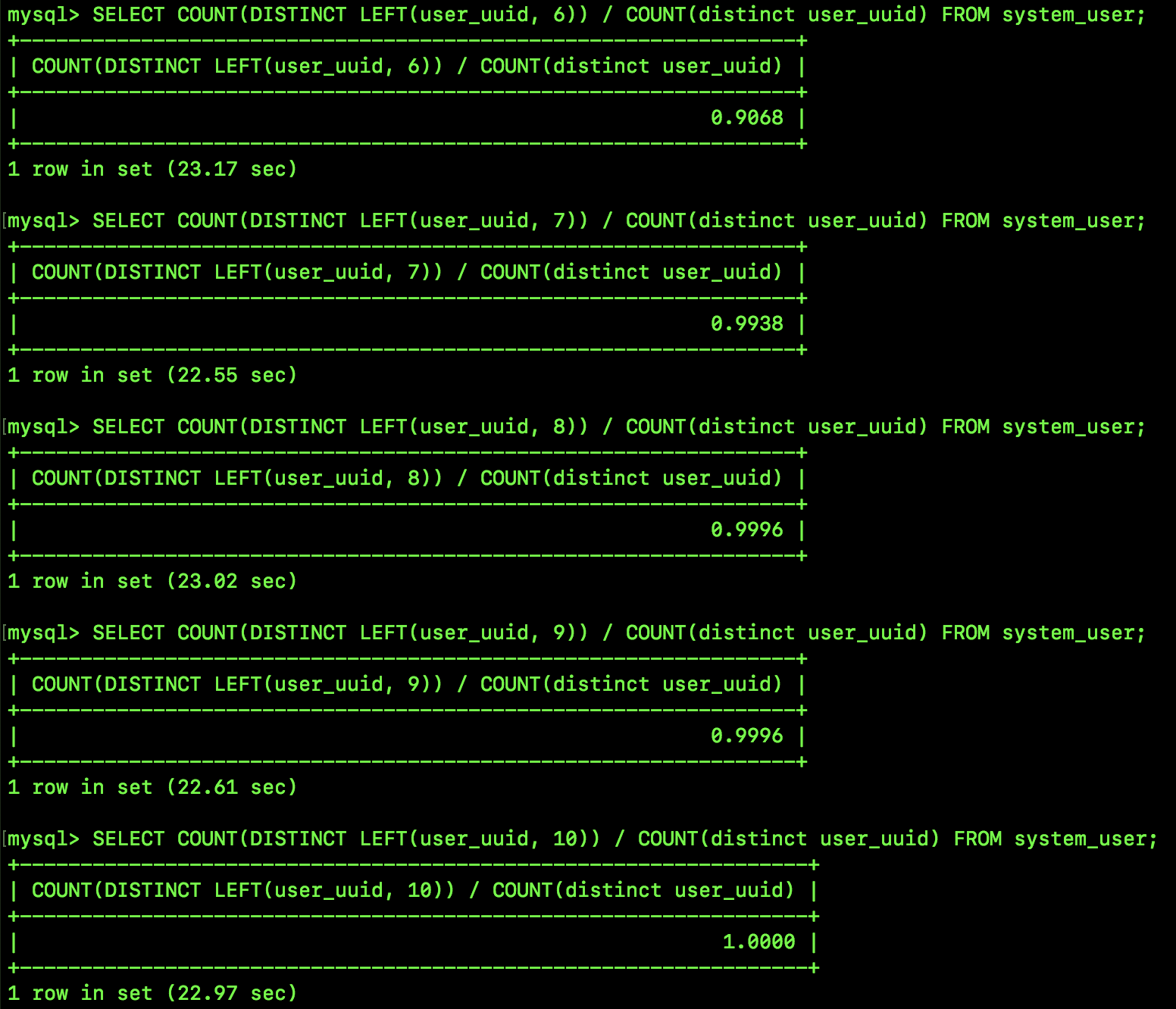
8 和 9 的选择性是一样的,因为在 uuid 字符串中,第 9 个字符串是 -,所有的 uuid 第九个字符串都一样,所以 8 个字符和 9 个字符串的区分度就一样。
当 prefix_length 为 10 的时候,选择性就已经是 1 了,意思是,在这 300W+ 条数据中,如果我用 user_uuid 这个字段去查询的话,只需要输入前十个字符,就能唯一定位到一条具体的记录了。
那还等啥,赶紧创建前缀索引呗:
alter table system_user add index user_uuid_index(user_uuid(10));
查看刚刚创建的前缀索引:
show index from system_user;

可以看到,第二行就是我们刚刚创建的前缀索引。
接下来我们分析查询语句中是否用到该索引:
select * from system_user where user_uuid='39352f81-165e-4405-9715-75fcdf7f7068';

可以看到,这个前缀索引已经用上了。
具体搜索流程是这样:
- 从
user_uuid_index索引中找到第一个值为39352f81-1的记录(user_uuid 的前十个字符)。 - 由于 user_uuid 是二级索引,叶子结点保存的是主键值,所以此时拿到了主键 id 为 1。
- 拿着主键 id 去回表,在主键索引上找到 id 为 1 的行的完整记录,返回给 server 层。
- server 层判断其 user_uuid 是不是
39352f81-165e-4405-9715-75fcdf7f7068(所以执行计划的 Extra 为 Using where)。- 如果不是,这行记录丢弃。
- 如果是,将该记录加入结果集。
- 索引叶子结点上数据之间是有单向链表维系的,所以接着第一步查找的结果,继续向后读取下一条记录,然后重复 2、3、4 步,直到在 user_uuid_index 上取到的值不为
39352f81-1时,循环结束。
如果我们建立了前缀索引并且前缀索引的选择性为 1,那么就不需要第 5 步了,如果前缀索引选择性小于 1,就需要第五步。
从上面的案例中,小伙伴们看到,我们既节省了空间,又提高了搜索效率。
3.3 一个问题
使用了前缀索引后,我们来看一个问题,大家来看如下一条查询 SQL:
select user_uuid from system_user where user_uuid='39352f81-165e-4405-9715-75fcdf7f7068';
这次不是 select *,而是 select user_uuid,小伙伴们知道,这里应该是要用到覆盖索引,我们来看看执行计划:
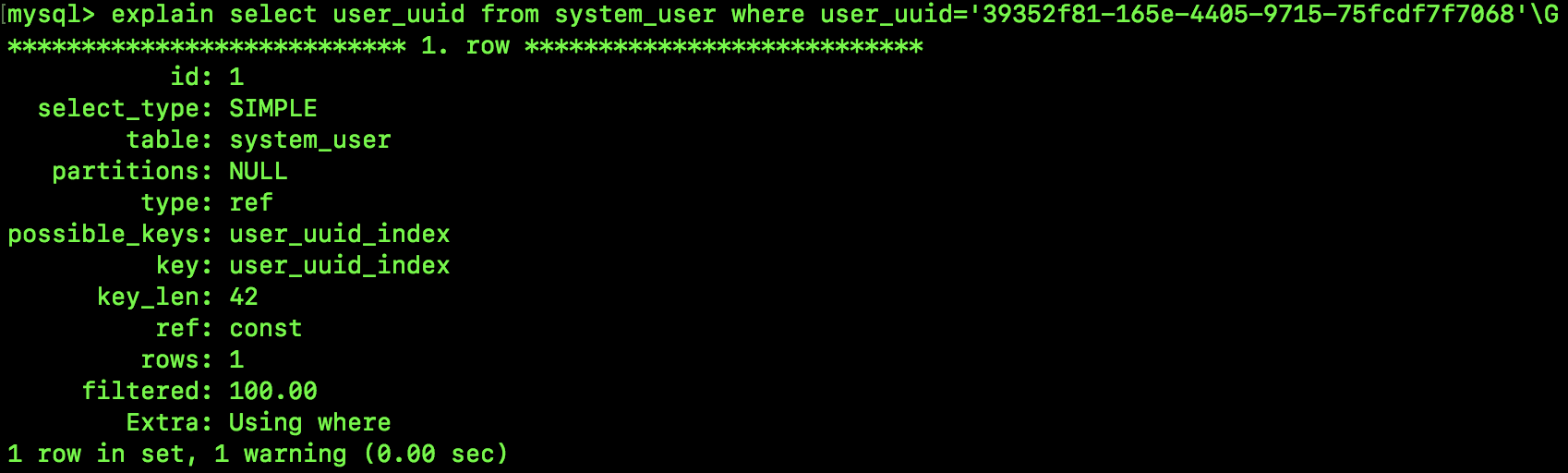
咦,说好的索引覆盖呢?(注意看 Extra 是 Using where 不是 Using index)。
大家想想,前缀索引中,B+Tree 里保存的就不是完整的 user_uuid 字段的值,必须要回表才能拿到需要的数据。所以,用了前缀索引,就用不了覆盖索引了。
4. 回到开始的问题
在本文一开始,松哥抛出了一个问题,如何给身份证建立索引更高效?
由于身份证前六位区分度太低,所以我们可以考虑将身份证倒序存储,倒序存储之后,为前六位或者前八位(可以自行计算选择性)建立前缀索引,这样的建立的索引选择性就会比较高,同时对空间的占用也会比较小。在查询的时候使用 reverse 反转身份证号码即可,像下面这样:
explain select * from user where id_card=reverse('正序的身份证号码');
5.小结
好啦,这就是前缀索引,感兴趣的小伙伴赶紧体验一把吧~