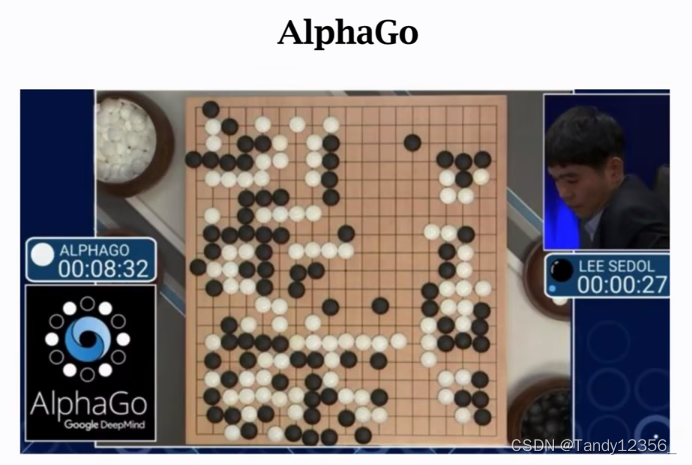
现在我们来分析AlphaGo这个实例,看看深度强化学习是怎么样用来玩围棋游戏的

AlphaGo的主要设计思路:
首先是训练,要分3步来做:
1、behavior cloning:这是一种模仿学习,alphaGo模仿人类玩家,从16W局人类的游戏当中学习出一个策略网络。behavior cloning是一种监督学习,其实就是多分类,不是强化学习,AlphaGo使用behavior cloning来初步学习策略网络
2、使用强化学习来进一步训练这个策略网络,具体是用策略梯度算法,AlphaGo让策略网络做自我博弈,拿胜负结果来训练策略网络,强化学习可以让策略网络变得更强
3、训练一个价值网络,AlphaGo用的不是actor-critic算法,actor-critic算法要同时训练价值网络和策略网络,AlphaGo是先训练策略网络,然后用策略网络来训练价值网络
当AlphaGo和李世石下棋的时候用的不是策略网络,而是蒙特卡洛树搜索,搜索的时候要用到价值网络和策略网络,他们可以指导搜索,排除掉没有必要的搜索动作

策略网络的架构&如何训练策略网络:
17的含义:把当前黑色棋子的位置用1个矩阵来表示,把之前7步的黑色棋子的位置用另外7个矩阵来表示,为了表示黑色棋子,需要用到8个矩阵,同样,为了表示白色棋子还需要8个矩阵,前16个矩阵是对黑白棋子位置的描述,第17个矩阵如果是全1的话,就表示现在该下黑色棋子了,如果是全0的话,就表示现在该下白色棋子了
8这个数字是个超参数,是做使用试出来的
此时状态就可以用这个19*19*17的tensor来表示了
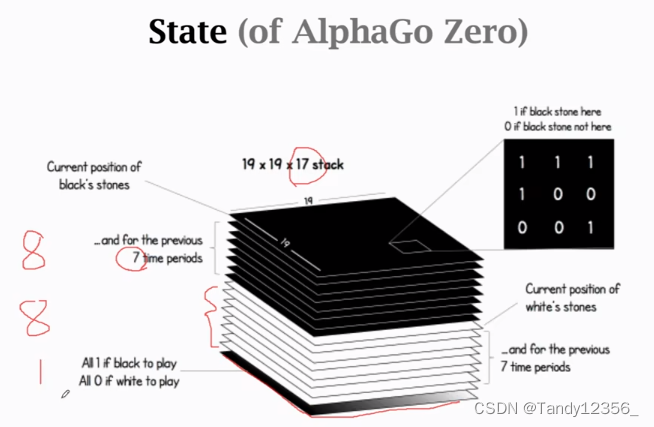
如何设计?
用一个tensor来表示AlphaGo的状态,把tensor作为状态网络的输入
最后使用1个或者多个全连接层输出一个361维的向量
输出层的激活函数必须使用softmax,因为输出的是一个概率分布
围棋最多有361个动作,所以神经网络的输出应该是一个361维的向量,输出向量的每一个元素对应的是一个放棋子的位置,也就是动作,向量的元素都是每个动作的概率值

由于从头训练神经网络耗时太长,所以先直接从人类你记录的比赛当中初步学习

behavior cloning只需要让策略网络去模仿人的动作就可以了,不需要奖励,也不是强化学习,模仿学习和强化学习的区别就是有无奖励

使用tensor来表示棋盘上的格局:
把动作at*=281做one-hot encode,变成了一个361维的向量,这个向量是全0的,只有第281个元素是1,把这个one-hot encode记作向量yt
使用CrossEntropy来衡量人类玩家的动作yt与策略网络的预测pt之间的差异,作为损失函数
其实你仔细想一下behavior cloning就是多分类,棋盘上有361个位置,其实就是有361个类别,策略网络的输出就是每一个类别的概率,人类玩家的动作是361当中的一个,把人类玩家的动作看作是ground-truth真实的标签,其实这个问题跟图片分类完全一样,图片分类有汽车、猫、狗的类别,而这里的类别是361个位置,图片分类中的target是猫、狗这样的标签,这里的target是人类玩家放棋子的位置,所以behavior cloning就是多分类,有361个类
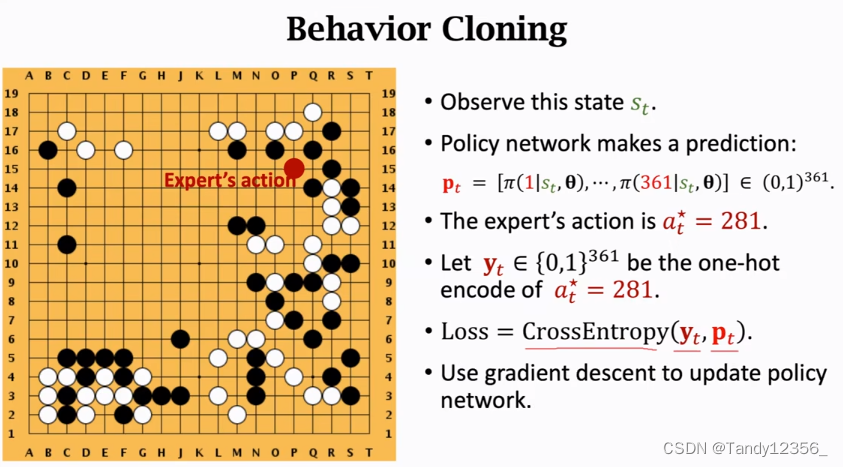
behavior cloning最大的缺陷是什么?
》当前状态st没有出现在训练数据当中(策略网络没有见过当前状态st)

在强化学习之后,即使当前棋盘上的状态很奇怪,策略网络也能应对自如
具体怎么样用强化学习来训练策略网络呢?
》AlphaGo让两个策略网络来做博弈,一个叫做Player另一个叫做Opponent
每下完一句围棋,把胜负作为奖励,靠奖励来更新Player的参数,Playe没下一步棋子,Opponent也要跟着走一步,相当于随机状态转移,Opponent也是用策略网络来控制的,但是Opponent的参数不用学习

那么怎么样定义奖励呢?
前面的奖励都是0,只有最后一个奖励要么是-1要么是1

如何直观理解?
》agent赢了则每一步都是好棋,agent输了则每一步都是臭棋,我们无法区分一句博弈里哪一步是好棋哪一步是臭棋,我们只能把每一步都同等对待,拿最终结果说话,给所有动作都有相同的回报
玩完一句游戏我们就知道ut的值了,要么是+1要么是-1,我们还可以指定策略网络Π的参数θ=θt,就可以计算近似的策略梯度了

这里的ut不是前面的ut,而是每个时刻的rt,所以需要连加

现在还有一个小问题就是策略网络有可能会犯错误而导致输掉比赛,也就是模型不稳定,比策略网络更好的办法是蒙特卡洛树搜索

为了做蒙特卡洛树搜索,还需要一个价值网络,这里的价值网络和之前的不太一样,这里的价值网络是对状态价值函数V的近似而不是对Q的近似

最新的AlphaGo Zero是让两个神经网络共享一个卷积层,这是因为这两个网络都需要把状态是19*19*17的tensor作为输入,底层的卷积从输入中提取特征,而这些特征对于两个神经网络都适用,所以呢让两个神经网络共享一个卷积层是很合理的
价值网络的输出是一个标量,是对当前状态s的打分,表示当前的胜算有多大

策略网络和价值网络是分别训练的,而不是同时训练的,AlphaGo先训练策略网络Π,然后再训练价值网络V,价值网络V是靠策略网络Π帮助训练的,而actor-critic算法是同时训练两个网络
价值网络的学习就像是一个回归问题一样,把真实观测到的ut作为target,价值网络的预测是v(st,w)
那么哪里体现了策略网络辅助价值网络了呢?
训练价值网络V的时候在第一步要用策略网络做自我博弈

回顾一下:
1、首先使用模仿学习,根据人的棋谱来初步训练策略网络
2、使用策略梯度算法,来进一步训练策略网络
3、结束训练策略网络之后,再单独训练一个价值网络V
至此AlphaGo的训练结束了
那么实战的时候, AlphaGo使用的是策略网络还是价值网络呢?
》都不是,AlphaGo实战的时候使用的是蒙特卡洛树搜索。蒙特卡洛树搜索不需要训练,可以直接拿来跟人下棋,之前学习的两个神经网络就是为了帮助蒙特卡洛树搜索
人类下棋的时候要往后算好几步,这样赢得可能性更大,这就是为啥AI会向前看,而不仅仅是用策略函数来算出一个动作,比如你当前玩游戏可能会获得满足,但是在未来可能会没有通过考试,最终得不偿失,虽然这个动作在当下是最优的,但是在未来却未必如此

搜索的主要思想:
1、选择一个动作a,当然要根据动作的好坏程度,以不同的概率去选择,可行的动作很多不可能使用枚举算法,所以要排除不好的动作,只去搜索好的动作,使用的就是策略网络,来去排除不好的动作(概率值比较低的)
2、让策略网络做自我博弈,直到游戏结束,看这次是胜还是负
3、然后根据是胜还是复和价值函数这两个因素来给a打分
4、重复这个过程很多次,所以每个动作都有很多个分数
5、可以看一下哪个动作的总分最高,这个分数就能反映出动作的好坏,AlphaGo就会执行总分最高的动作
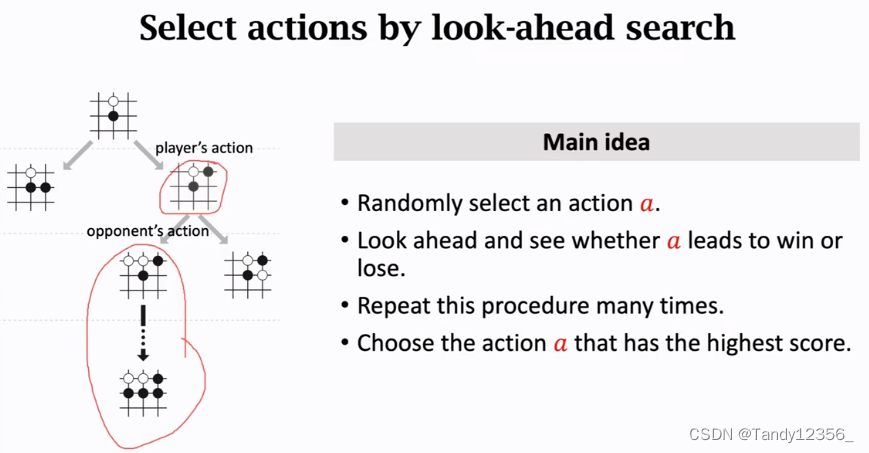
蒙特卡洛树搜索具体是这样做的:

分数由两部分组成:
1、Q(a),他是搜索计算出来的分数,叫做动作价值,其实在Go的例子中Q(a)就是一张表,记录了361个动作的分数
2、另一个是策略网络Π给a打的分数除以(1+N(a)) ,这里的N是动作a被选中的次数,动作越好策略网络Π给a打的分数就会越高,这一项就会越大,但是如果动作a已经被探索好多次了,分母N(a)就会变大,降低动作a的分数,这样可以避免探索同样的动作太多次,η是超参数需要手动去调整
以下过程都是Go在模拟
1、一开始所有的Q(a)都=0,一开始的时候完全由策略函数Π来决定探索哪个动作,做了很多次搜索之后N(a)的值会变大,使得第二项变得很小,这样策略函数Π就变得无关紧要了,这时候探索哪个动作完全由Q(a)来决定
2、
这里的对手相当于环境,这里的策略是状态转移函数,对手的动作会产生新的状态st+1,虽然我不知道对手怎么想的,即我不知道状态转移函数,但是可以使用Π来近似p

3、评估
从状态st+1开始,后面就让策略网络来做自我博弈,双方都由策略网络控制,双方挨个放棋子,一直到分出胜负为止,此时得到奖励rt,赢了+1,输了-1,这个奖励rt可以用来评价状态st+1的好坏
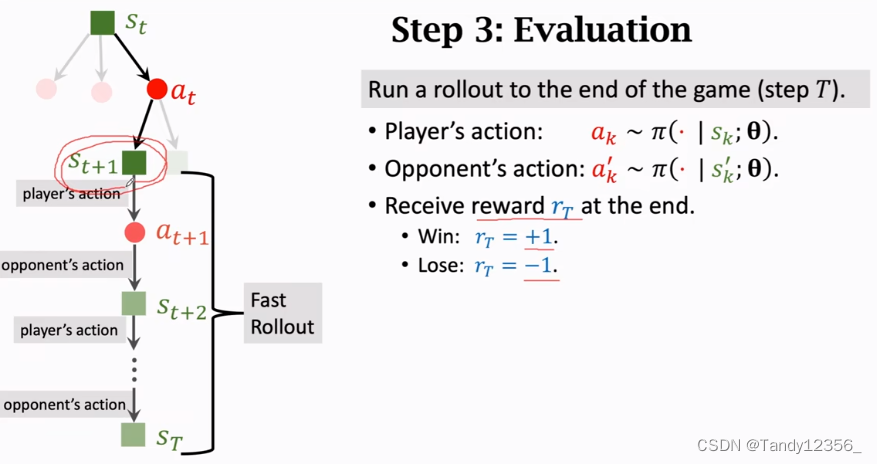
除了用奖励来评价st+1,Go还用V来评价,价值网络V是之前训练出来的,直接把状态st+1输入进来

由于这个模拟会重复很多次,所以每个状态下都会有很多记录,每个动作at都会有很多个这样的子节点,所以at就会对应很多条记录,把at下面所有的记录做一个平均,作为at新的价值Q(at)

解释以下Go算这个Q的目的,蒙特卡洛树搜索的第一步selection的时候要选出最好的动作来搜索,做选择的时候就要用到这个Q值,Q值就是所有记录的V值的平均

假设已经做了成千上万次搜索了,这时候哪个动作好已经很明显了,限制AlphaGo可以做真正的决策了
一个动作a的Q值和Π越大,N(a)就越大,所以N(a)可以反应动作的好坏,AlphaGo的决策很简单,就是选中N值最大的动作,执行这个动作

AlphaGo每走一步,都要进行成千上万次的模拟,每次模拟都会重复以上四步,通过成千上万次的模拟AlphaGo就有了每个动作的Q分数和N分数,AlphaGo会选中N值最大的动作,执行这个动作,真正地下一步棋,为了走这一步棋,AlphaGo已经进行了成千上万次的模拟
当李世石走完一步,再次轮到AlphaGo的时候,他会再次重来一次蒙特卡洛树搜索,这次会重新把Q和N初始化为0,然后做成千上万次模拟

简单小结一下:
训练价值网络就是在做回归
虽然可以使用策略网络来下棋,但是更好的办法是蒙特卡洛树搜索

老版本是模仿人类玩家,新版本是模仿蒙特卡洛树搜索


如果是在虚拟环境的话,behavior-cloning可能是有害的,但是在物理世界当中,还是很有必要的,因为这样可以最大化地减少损失
新版本的AlphaGo是如何训练策略网络的?
1、观测到状态st
2、让策略网络做一个预测,输出每个动作的概率值,把策略网络的输出记作向量p,他是一个362维的向量
3、做蒙特卡洛树搜索,做很多次模拟,会得到每一个动作被选中的次数Na,对这361个数Na做归一化,让他们变成概率值,记作n
4、我们希望策略网络做出的决策p接近搜索做出的决策n,即减小L
5、使用梯度下降减少Loss