C++入门(下)
对于C++的基础语法的讲解,由想要实现多次重复的函数,引出宏函数和inline的内联函数的对比,对于inline的讲解和运用,在后,C语言中的NULL和C++中独特的nullptr的相比两者的比较,最重要的是对于引用的讲解和使用,以及和指针相比的区别。还有auto关键字的使用
文章目录
- C++入门(下)
- 宏函数
- inline(内联函数)
- NULL和nullptr
- 引用
- 引用和指针的不同点
- auto关键字
宏函数
重复的调用同一个函数的时候,我们每创建一个函数,就会建立一个栈帧,这样对于空间来讲不友好,C语言中有宏函数这样的函数,来解决这一问题,下面是宏函数的特点与样例
优点:不需要建立栈帧,提高调用效率
缺点:复杂、容易出错,可读性差,不能调试
//宏函数实际上就是直接替换,宏函数书是不需要建立栈帧的,也就是可以直接展开的,所以宏函数的代码比较短,也相对复杂
/
#define Add(int x,int y) ((x)+(y)) //仅仅是x+y就需要这样书写,相对下面Add代码比较复杂
int Add(int x,int y){
return x+y;//宏函数本身就是为了节约空间才选择的宏函数
}
int main()
{
for(int i=0;i<100000;i++){
Add(i,i+1);//重复多次调用同一函数,我们就直接定义了宏函数来解决
}
return 0;
}
//但是由于不能调试,等等缺点,我们C++中出现了内联函数 inline关键字
inline(内联函数)
inline(内联函数),顾名思义,这一个关键字,可以在使用函数的时候,不用创建栈帧,有着宏函数的优点,也补足了宏函数的缺点,可以调试,简单,不复杂,可读性强
以inline修饰的函数叫做内联函数,编译时C++编译器会在调用内联函数的地方展开,没有函数调用建立栈帧的开销,内联函数提升程序运行的效率。
inline int Add(int x,int y){
return x+y;
}
//inline的使用,只需要在Add函数之前加上关键字inline即可使得Add函数为内敛函数
inline看起来都是优点,都是好处,但对于接下来的代码进行分析, 你就明白inline的缺点了,或者是适用的地方
//加入说,我们在main函数中或者是一个程序中有10000个地方需要使用Add函数 Add函数的编译后得到的汇编代码比如是50行,那么对于下面函数分析,只看Add函数这一部分,在整个程序中所需的汇编代码有多少行
//内联函数inline
inline int Add(int x,int y){
return x+y;
}
//如果是内联函数,由于我们不建立栈帧,也就是说,直接展开的方式使用Add函数,所以总汇编代码行数应该为:10000*50行
//使用正常的函数
int Add(int x,int y){
return x+y;
}
//在汇编代码中会调用这个函数 call Add.... 这样的话汇编代码行数为 10000+50
所以在这个上面我们就发现了,inline,使得汇编代码变大,也就是导致最后可执行程序变大,所以inline并不是说适用于所有情况
inline内联函数适用情况
- 适用于短小且频繁调用的函数
inline函数也并不是说,在函数头加上inline ,就一定会被编译器认定为内联函数
inline函数否决条件
- 比较长的函数
- 递归函数
结论:如果inline定义的函数,编译器会自行判定是否需要适用内敛函数,当函数体代码比较多,行数比较多的时候,编译器会默认为不能使用内敛函数,这也是为了使得最后生成的可执行程序大小没有那么夸张。
在默认为Debug版本下,inline不会起作用,为了方便调试
inline int Add(int x,int y){
cout<<"111111"<<endl;
cout<<"111111"<<endl;
cout<<"111111"<<endl;
cout<<"111111"<<endl;
cout<<"111111"<<endl;
cout<<"111111"<<endl;
cout<<"111111"<<endl;
cout<<"111111"<<endl;
return x+y;//这种情况就不会判定为inline内联函数
}
总结:
- inline是以空间换时间的做法,如果编译器将函数当成内敛函数,那就会在编译阶段,将函数体替换函数调用,缺点:可能会使得可执行文件变大(详情在上文),优点:减少调用开销,减少栈帧的创建,提高程序效率。
- inline只是一个对编译器的一个建议,向编译器发送一个请求,编译器可选择忽略这个请求
- 函数较长
- 递归函数
- inline适用的场景
- 函数规模较小(至于多小,取决于编译器的规定,不同编译器规定不一样)
- 频繁调用
- inline不建议声明和定义分离,放在两个文件的话,inline只是展开声明函数,就没有函数地址,所以找不到定义函数,链接就找不到这个函数
面试题:
宏的优缺点?
优点:
1.增强代码的复用性。
2.提高性能。
缺点:
1.不方便调试宏。(因为预编译阶段进行了替换)
2.导致代码可读性差,可维护性差,容易误用。
3.没有类型安全的检查 。
C++有哪些技术替代宏?
- 常量定义 换用const enum
- 短小函数定义 换用内联函数 inline
NULL和nullptr
NULL和nullptr是表示不一样的意思,下面一个小程序就可以验证
NULL是宏定义 是0 或者是(void*)0,而nullptr是空地址(指针)
void ac(int) {
cout << "int" << endl;
}
void ac(int*) {
cout << "int*" << endl;
}
int main()
{
ac(0);
ac(NULL);
ac(nullptr);
return 0;
}
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-o7ca3v7L-1682251314257)(C:/Users/红颜/AppData/Roaming/Typora/typora-user-images/image-20230421105700926.png)]](https://img-blog.csdnimg.cn/81736bd5253f4fc2886a251df1ce9de9.png)
引用
&在C语言中为取地址符,只有取地址的意思,在C++中不但有取地址的意思,也有另一个重要的含义:引用
引用的概念就是,一人多名,我可以叫你小王,也可以是why,这两个称呼的方式都是指的你,在程序中,表达的意思就是,我对你这个变量进行引用,得到一个称呼,这两个称呼都是指向你这个变量,类似指针,但是比指针更加方便理解
类型& 引用变量名(对象名) = 引用实体;
//类型& 引用变量名(对象名) = 引用实体; 这是引用的适用格式
int main()
{
int a = 10;
int& b = a;//给a一个引用,称为b,也就是说,ab都是指向同一个空间,数值为10,
cout<<b<<" "<<a<<endl;//10 10
b++;//引用类似于指针,当b数值变的时候,会直接影响到a
cout<<b<<" "<<a<<endl;// 11 11
return 0;
}
引用类型,需要和引用实体是同种类型,如:上述代码,即都需要int类型

引用特性
- 引用在定义时必须初始化
- 一个变量可以有多个引用
- 引用一旦引用一个实体,再不能引用其他实体
int main()
{
int a = 10;
int& b = a;
int& c = a;
int d = 20;
c = d;//再次引用的时候,实际上不是引用,只是将d的数值赋值给c,进而改变了abc的数值都为d:20
//所以C还是a从别名
cout << a << " " << b << " " << c << endl;
return 0;
}

引用做返回值
当引用做返回值来接收的时候,我们对于这个情况做分析
int add(){
static int n=0;
n++;
return n;
}
int main()
{
int ac=add();//这样ac数值为1
return 0;
}
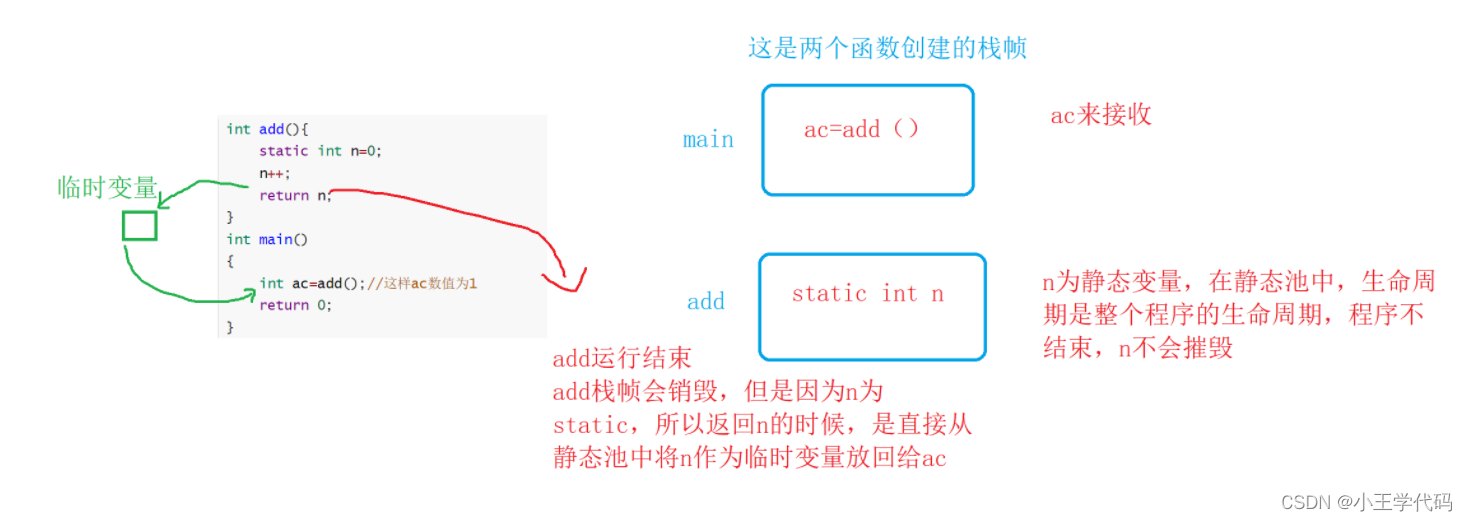
如果不是static变量的话,会如何呢?
int add(){
int n=0;
n++;
return n;
}
int main()
{
int ac=add();//这样ac数值为1
return 0;
}
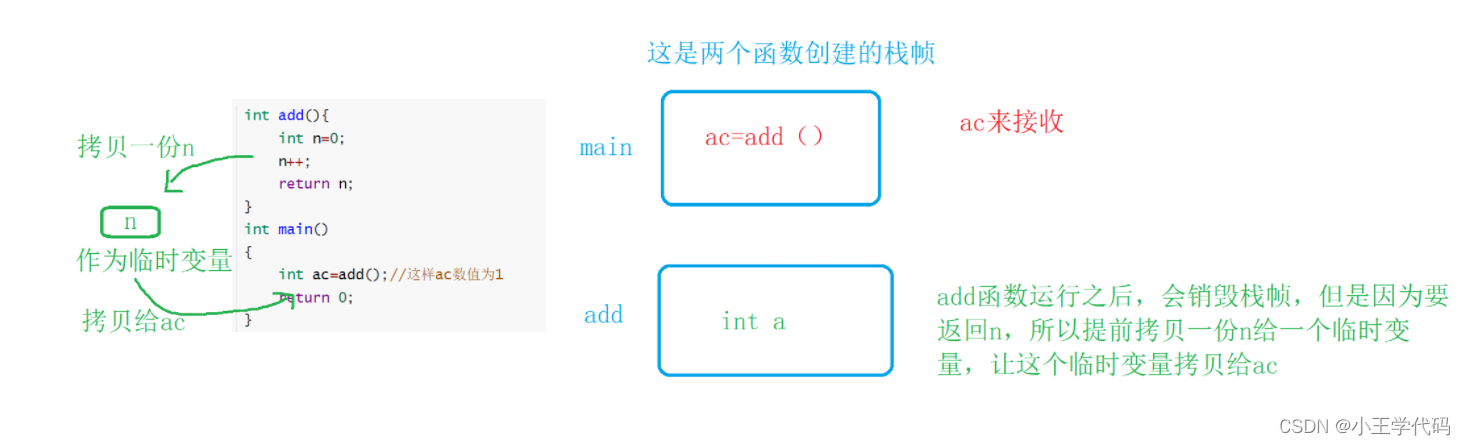
传引用作为返回值
在函数类型的后面加上&,引用操作符,然后进行分析程序结果
int& add() {
static int n = 0;//静态变量,存放在静态区,所以最后传出来的是静态区的n
n++;
return n;//所以返回的数值为1 返回给main函数的ans变量,过程为:用n的别名给了ans
}
int main()
{
//rand();
int ans = add();
cout << ans << endl;//输出结果为1
return 0;
}
//接下来对比一下没有static的临时变量
int& add() {
int n = 0;
n++;
return n;
}//那么就是 ans得到的也是n的空间,当栈帧没有被破坏的时候输出的是1(正确)如果栈帧被破坏,就输出随机值
int main()
{
//rand();
int ans = add();//返回的也是n的别名,但是n的变量所在空间已经摧毁,所以n可以为1,或者为随机值
cout << ans << endl;//输出的结果可能为1(栈帧没有被破坏),或者是随机值
return 0;
}
当传引用且用int&来接受时
直接看代码,进行讲解,
int& add(int x) {
int n = x;
n++;
return n;
}//那么就是 ans得到的也是n的空间,当栈帧没有被破坏的时候输出的是1(正确)如果栈帧被破坏,就输出随机值
int main()
{
//rand();
int& ans = add(10);
cout << ans << endl;
add(20);
cout << ans << endl;
return 0;
}

让我们再来测一测,是不是传引用,再用引用类型接收,两个变量代表两个相同的地址
int& add(int x) {
int n = x;
n++;
cout << &n << endl;
return n;
}//那么就是 ans得到的也是n的空间,当栈帧没有被破坏的时候输出的是1(正确)如果栈帧被破坏,就输出随机值
int main()
{
//rand();
int& ans = add(10);
cout << &ans << endl;
add(20);
cout << &ans << endl;
return 0;
}
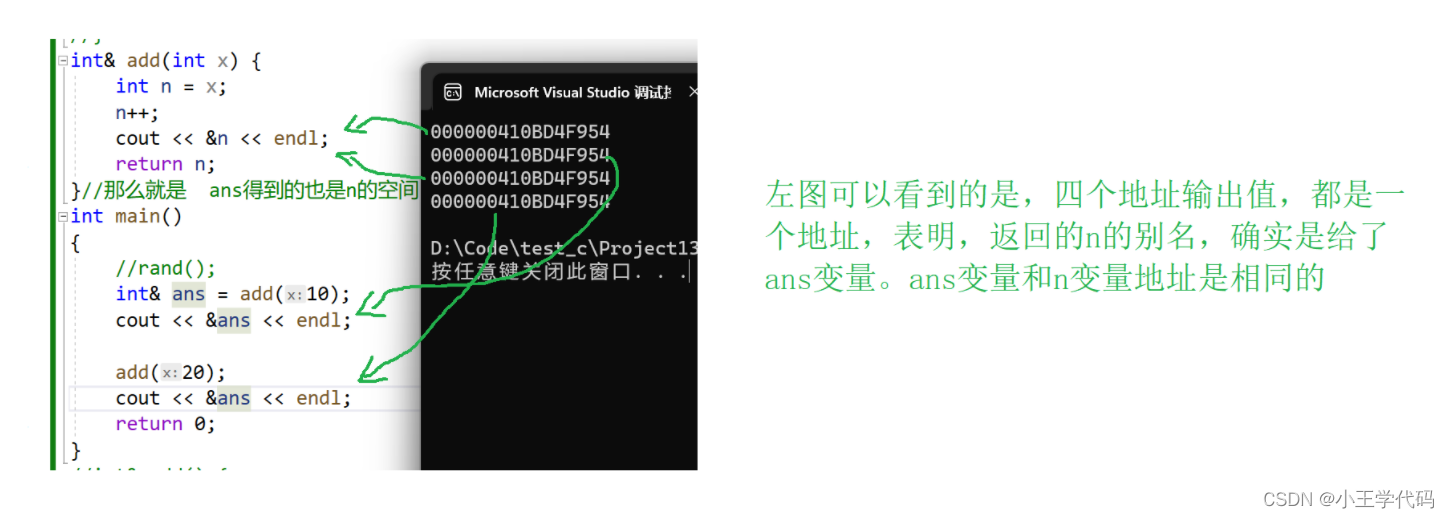
可以用引用的地方:
- 引用做参数(输出型参数)(减少拷贝,提高效率)
- 引用做返回值(减少拷贝,提高效率)可以修改返回值(下面总结有相关代码)+获取返回值
权限可以缩小or平移,但是不能放大
我们知道的是int a的权限大于const a的权限,总结一点为引用过程中,权限可以平移或者进行缩小,但是不能进行放大,临时变量具有常性。
//正确用法
int main()
{
int x=0;
int& y=x;
const int& z=y;//可以const 放小权限 这个是正确的用法
//如果说我们改变y或者x的数值,z会不会随之变化呢?
//如图1所示:
y++;
return 0;
}
//正确用例 (权限问题)
int main()
{
double a=10.1;
int b=a;
const int& c=a;//输出结果为10.1 10 10 这是权限的缩小
return 0;
}
//错误用例
int func()
{
static int x = 0;
return x;
}
int main()
{
int& r = func();//初始化int不能赋值给int&类型(报错),实际上就是权限被放大,因为返回的是临时变量,临时变量返回是一个常量,所以应该是用const来接收
//应该修正为
const int& r=func();
return 0;
}
图1 表明y改变时,在也会变化

在语法上,我们知道引用是不开空间的,使用指针是需要开空间的,但实际上在汇编底层指令实现的角度来讲,引用是类似于指针的方式来实现的,也就是说,引用语法上是不需要开空间的,但是实际上底层是会开空间
引用和指针的不同点
- 引用的概念的得到一个变量的别名,指针存储一个变量的地址
- 引用在定义时必须实现初始化,即不能出现int& a; 指针是没有这个要求的
- 引用初始化得到一个变量的别名后,在逻辑上不能再次引用其他变量,再次引用的时候,实际上是赋值,即将这个变量的数值赋值给这个引用变量。指针是可以随意指向任意变量的
- 没有NULL引用,但是又NULL指针
- 在sizeof关键字中的含义不同,引用sizeof得到的是引用类型的字节大小,指针sizeof大小是根据编译器决定的,如果是x86 32位那就是4字节,如果是64位就是字节
- 存在多级指针,但是没有多级引用
- 引用的自加将引用的实体加一,指针自加是将指针向后偏移一个类型的大小
- 访问变量的方式不同,指针是需要显示解引用,引用是编译器自己处理
- 引用比指针使用起来更加安全,没有NULL指针的现象
总结
基本上任何场景都可以使用引用传参
但是要谨慎使用引用传参,处理函数作用域的时候,对象如果不存在了,就不能用引用返回,还在就可以用引用返回。因为如果是临时变量作为引用返回值,可能会存在返回随机值的风险。
比如static修饰的变量作为引用返回可以,但是如果是普通的临时变量,不能这样返回,语法上可以,但是不建议这样使用。
//错误样例: int& add(int x) { int n=x; //这是一个临时变量n,返回的时,可能会出现随机值这样的情况 n++; return n; } //正确样例: int& add(int x) { static int n=x; //这是一个静态变量n,返回时,是从静态区中进行引用返回 n++; return n; }
- 引用作为返回值,可以被赋值
int& add(int x) { static int n = x; return n; } int main() { int& ans = add(10);//ans得到的是n的别名,ans也是引用,我们紧接着调用add函数add(20),然后进行将50赋值给这个函数。 add(20) = 50; //为什么可以赋值? //实际上,add函数是引用传参返回,这样我们当然可以将数值再次赋值给这个函数 cout << ans << endl;//ans的地址和add引用传参返回地址相同,输出数值为50 return 0; }
auto关键字
auto关键字的作用是,自动识别所需要的类型,也可以被用作增强for
#include<iostream>
#include<vector>
using namespace std;
int main()
{
int a = 10;
auto c = a;
//auto可以用作增强for循环使用,类似于Java中的Object
//c++ 中的可以识别变量类型的关键字
//typeid().name();
int arr[] = { 1,241,54,152,12,12,1 };
vector <int >v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
v.push_back(5);
for (auto i : arr) {
cout << i << endl;
}
auto d = &a;
cout << typeid(c).name() << endl;
cout << typeid(d).name() << endl;
return 0;
}
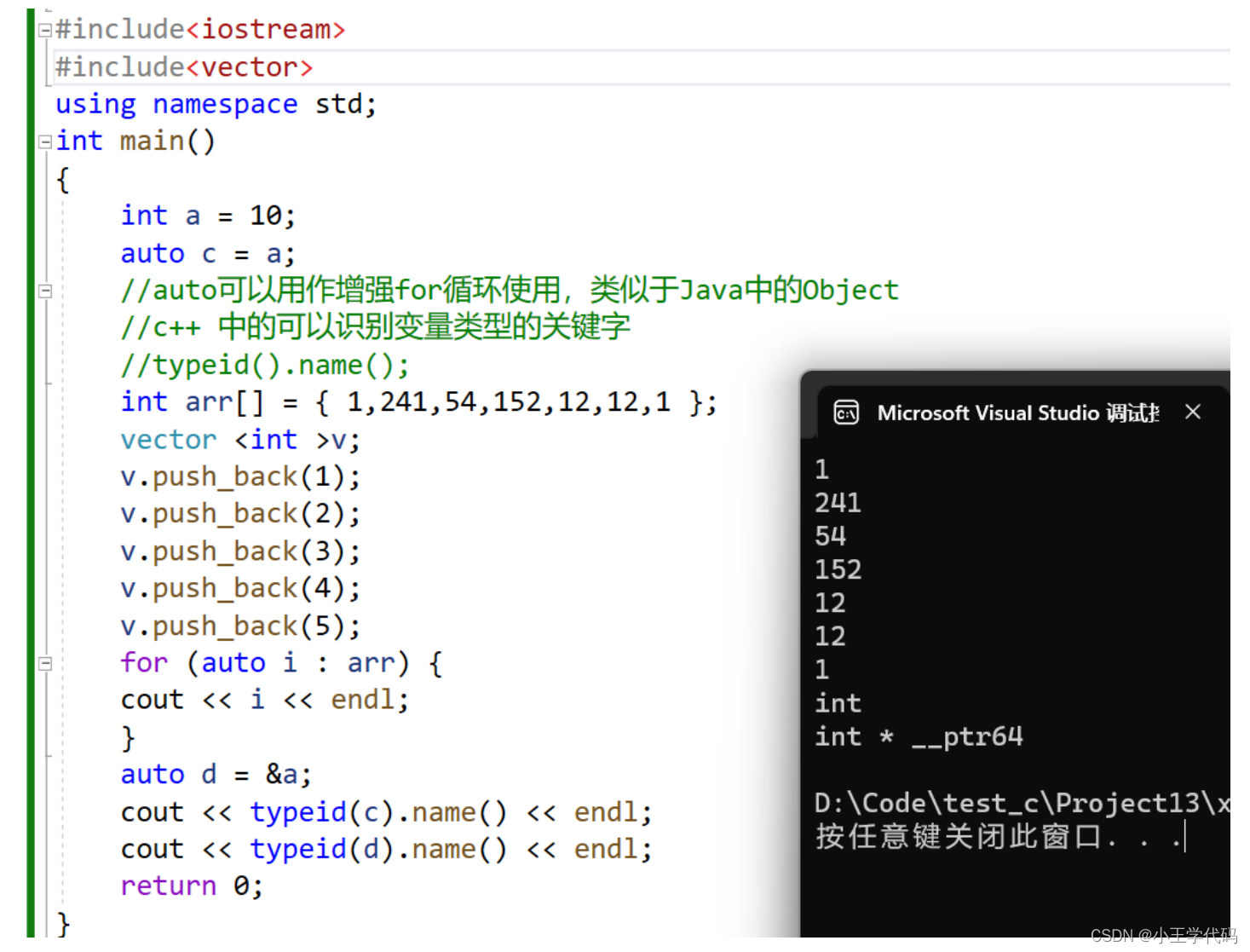
vector是STL里面的内容,现阶段不用管这个,这个地方只是展示一下auto增强for的用法,另外typeid(变量名).name()的用法,可以得到变量名的对应的类型