课程资料来自李宏毅老师油土鳖频道的BERT家族教程:上,下。
这两章主要是如何在pre-train的模型上做fine-turn,如何利用大模型来做自己的task。
目录
前言
什么是预训练 What is pre-train model
如何微调 How to fine-tune
入参
出参
每句生成一个class:
每个token都有一个class:
从输入做Copy
生成句子
针对预训练模型参数的策略
Weighted Features不同的layer也可以综合
为什么Fine-tune?
预训练是怎么做出来的 How to pre-train
HW4 Self-Attention
数据集
算法处理过程
前言
思想:让机器稍微了解人类的语言后,然后再针对具体的任务做训练。通过大量的无标注资料让机器先pre-train,然后用少量的有标注资料fine-tune。
 哈哈,李老师讲了大家在硬凑芝麻街的任务来命名模型。时间顺序是LMo/BERT/ERNIE/Groover。
哈哈,李老师讲了大家在硬凑芝麻街的任务来命名模型。时间顺序是LMo/BERT/ERNIE/Groover。
什么是预训练 What is pre-train model
核心思想:输入token得到vector。
岁月史书:
①过去是同样的token就会有同样的vector,比如Word2Vector(13年)/Glove(14年)。【这里可以看下向量表征,了解更详细的发展历程】
存在的问题:
-
不会有上下文间交互,无法处理一语多义👉 见②;
-
对于没见过的单词不知道怎么去处理 👉 英文可以根据字母编码,例如fastText(17年),中文可以根据图像编码(利用象形文字的特点),如Su的方法(17年)。
②现在是Contextualized Word Embedding,喂一整个句子进去,一般会比较deep(10~20层),每层的网络选择也比较多,比如LSTM(ELMo在用)/Self-Attention(BERT用的)/Tree-based(想要利用文法的资讯,但其实效果普普,只有文法特别严谨,比如公式,的时候才有效果)。
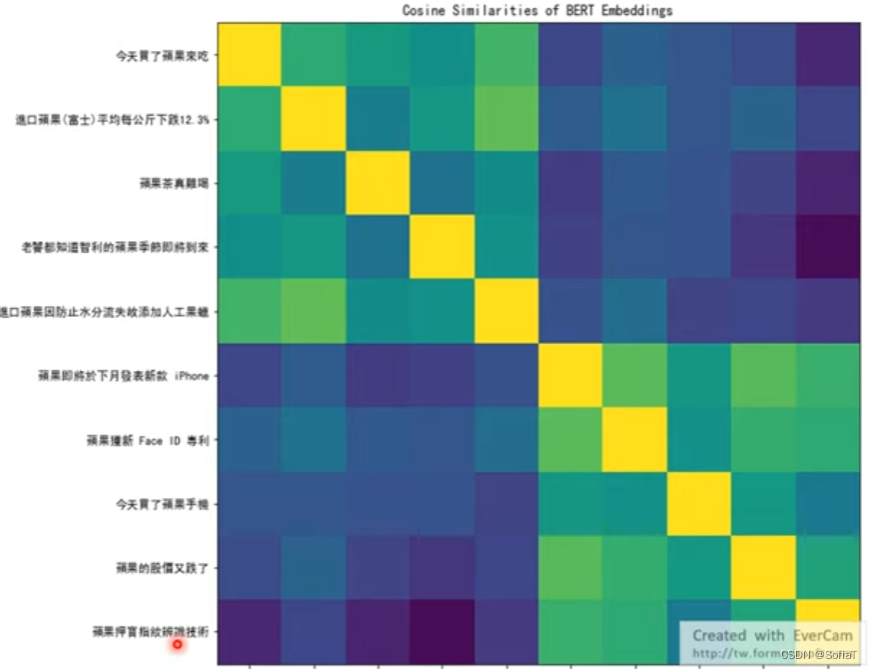 就比如这个例子,前五个是苹果(水果)与后五个苹果(iPhone),他们的cosine相似度就有区别,可视化这个方法是work的。
就比如这个例子,前五个是苹果(水果)与后五个苹果(iPhone),他们的cosine相似度就有区别,可视化这个方法是work的。
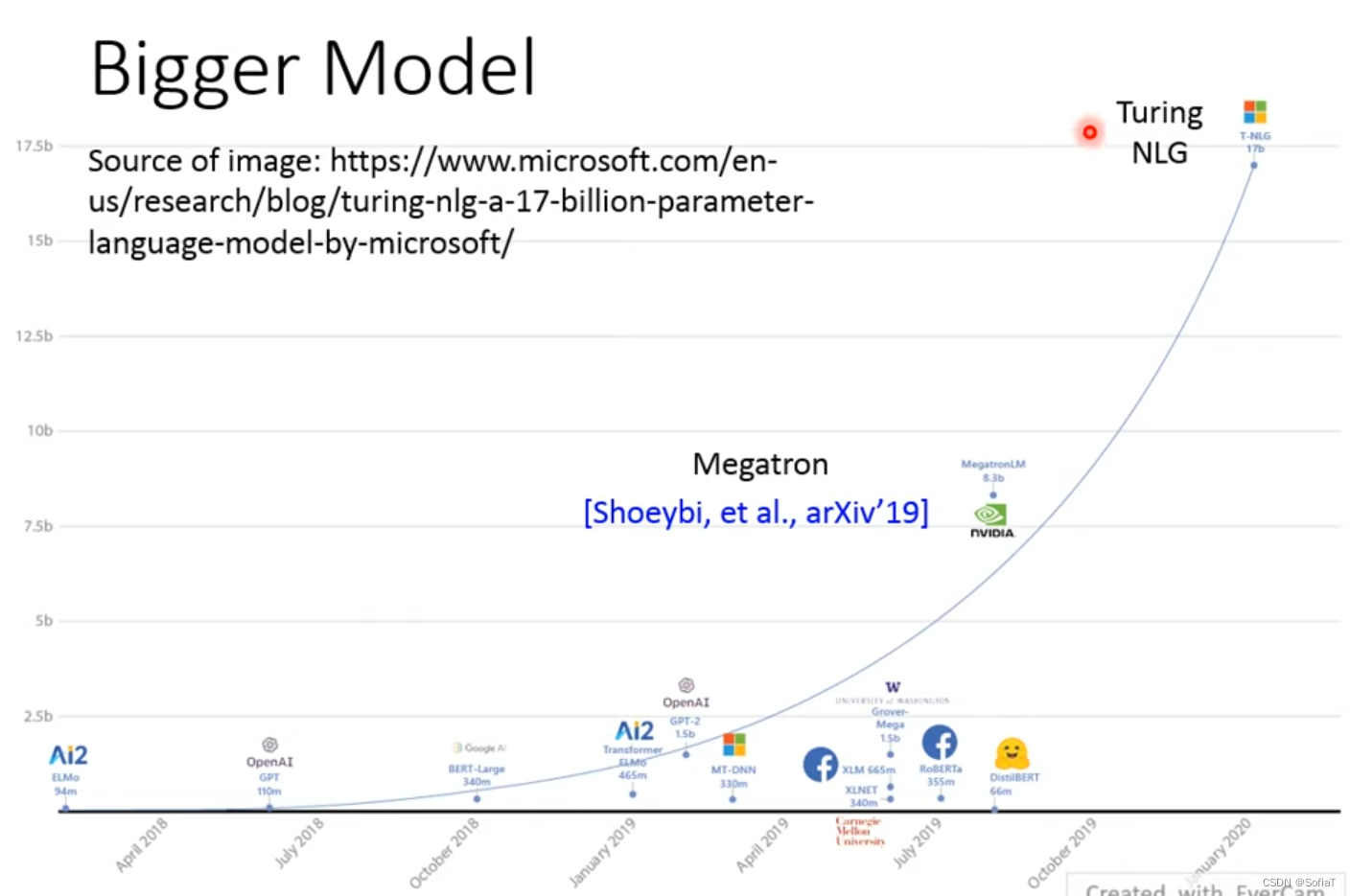
但是现在模型越来越大,如上图,只有大公司可以用了。可以看看穷人Bert:
 在其中ALBERT效果比较好,后期可以看看,至于是怎么压缩的,有一个总结。
在其中ALBERT效果比较好,后期可以看看,至于是怎么压缩的,有一个总结。
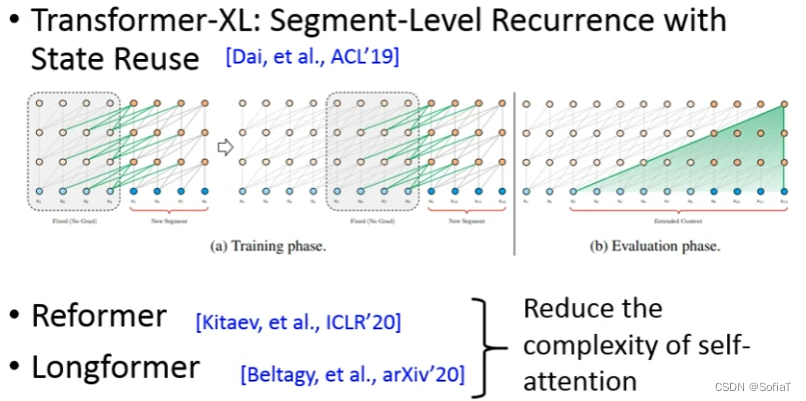
还有在sequence长度上做的,希望方法能够读更长的sequence,于是要降低self-attention的复杂度 :
 如何微调 How to fine-tune
如何微调 How to fine-tune
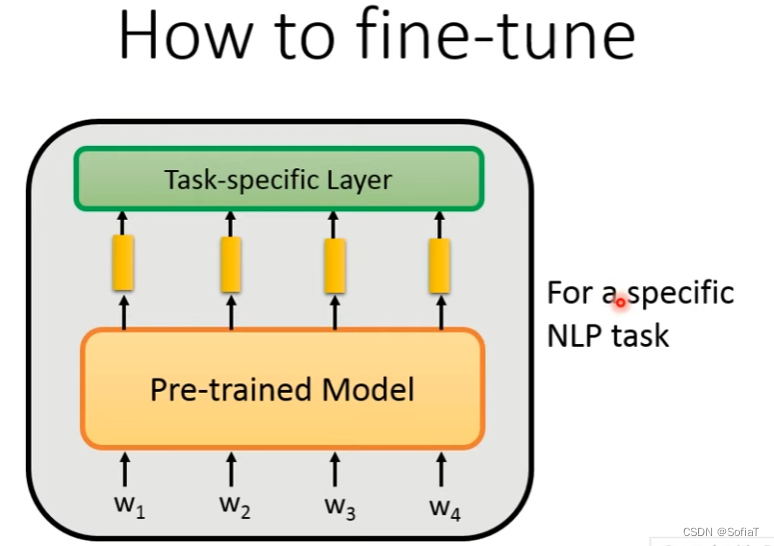
在NLP任务上改造方法,如下是NLP不同任务的输入输出,根据具体的入参和出参来进行改造。
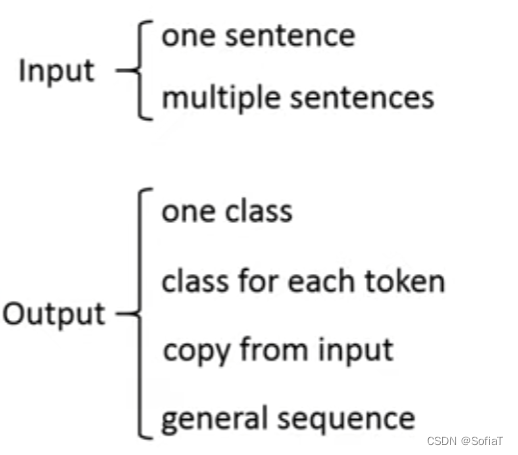
入参:一句or多句;出参:一整个句子分类/标注/从输入中选取/生成。
入参
一句的情况直接用原生bert就可以了,多句情况例子如QA/前提和假设,中间用[SEP]分割。
 出参
出参
每句生成一个class:
原来BERT的解法是用cls的符号,这样cls的符号对应的输出就是与整个句子有关的embedding,然后再加上别的层;或者是直接把所有的token做组合。
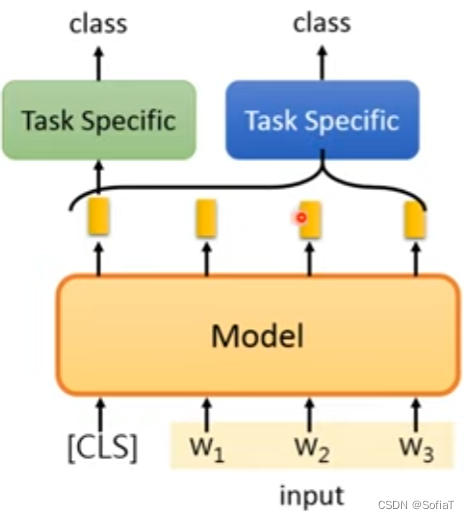
每个token都有一个class:
如下图所示:
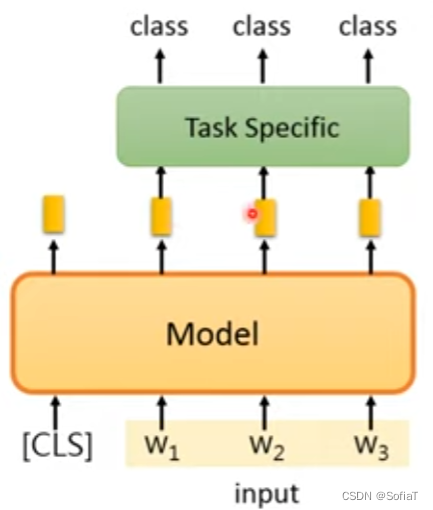
从输入做Copy
比如提取式QA,输入有一篇文章Document和一个问题Query,输出有两个integer是答案的上标s和下标e,答案范围就是从ds到de 。BERT里面原生的具体做法是做点乘(非常的simple)然后softmax看最大概率的那个向量就是了:
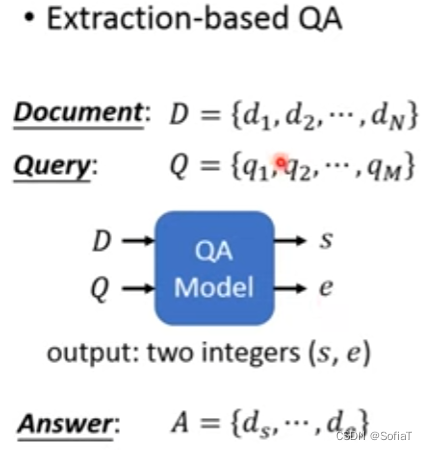
如果觉得太简单也可以加LSTM层。
生成句子
比如seq2seq模型:
 但是decoder都完全没有pre-train过,效果并不好。
但是decoder都完全没有pre-train过,效果并不好。
还有v2版本的,利用pre-train的encoder自己decoder: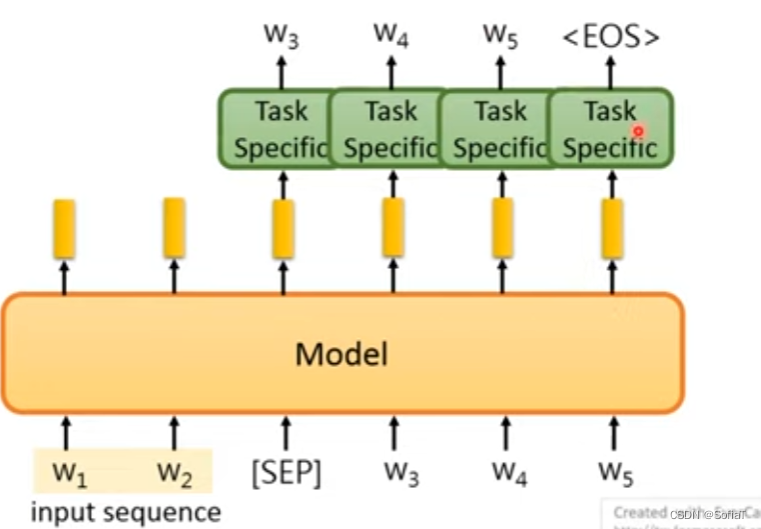
针对预训练模型参数的策略
固定模型参数,只调整fine-tune部分;pre-train和fine-tune都调整。具体任务要看具体performance。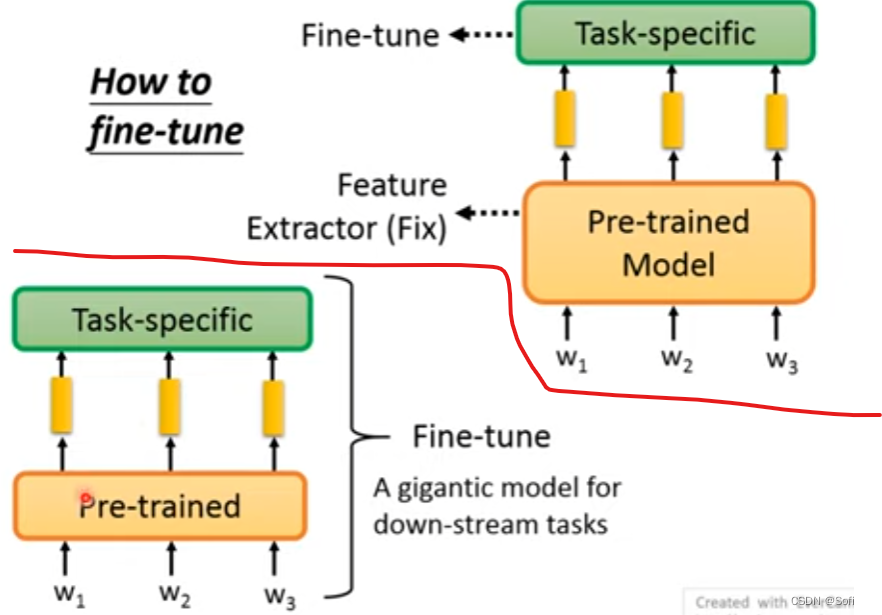
但是存在问题: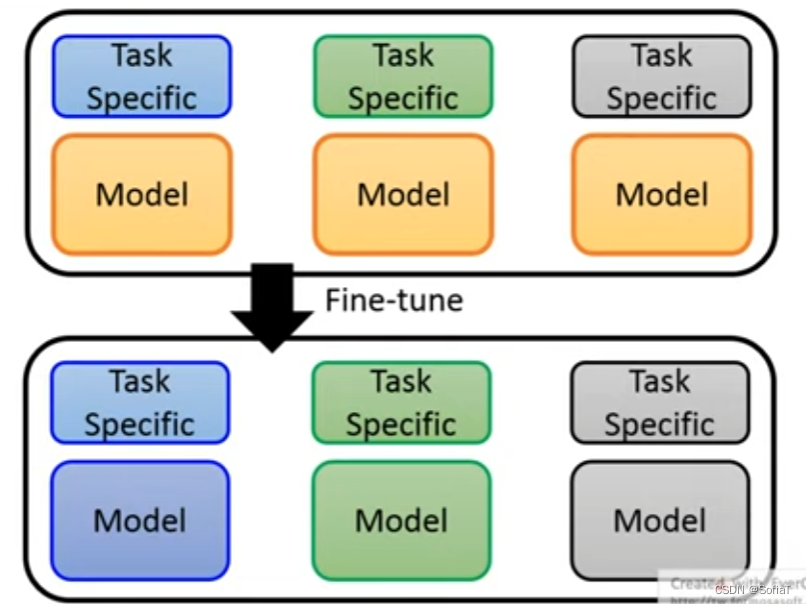
如果说,每一个任务都需要训练新的模型,存的参数非常巨大。所以又有Adaptor的思想:
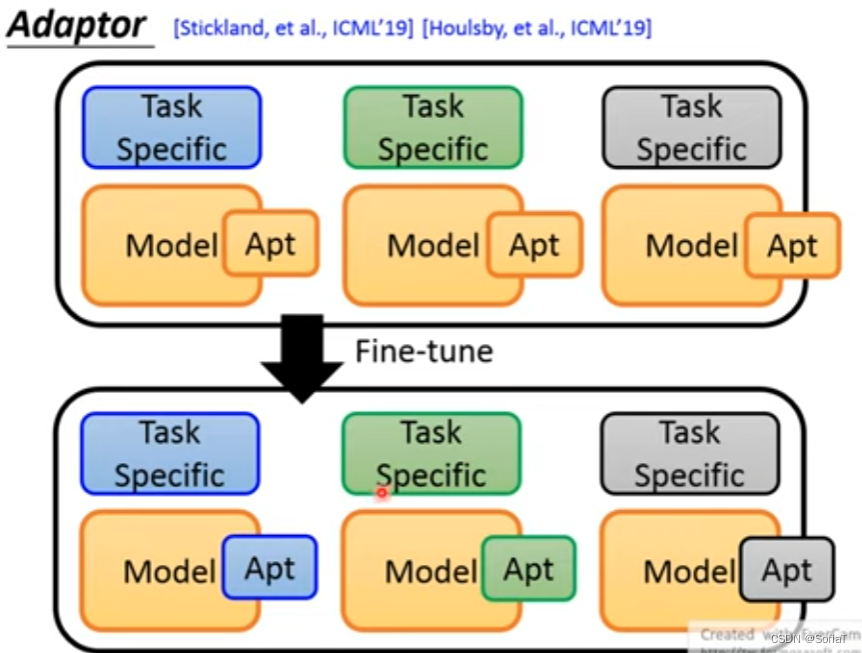 只要存Apt参数就足够了,具体实现示例如下,有圈圈的层就是要训练的部分:
只要存Apt参数就足够了,具体实现示例如下,有圈圈的层就是要训练的部分:
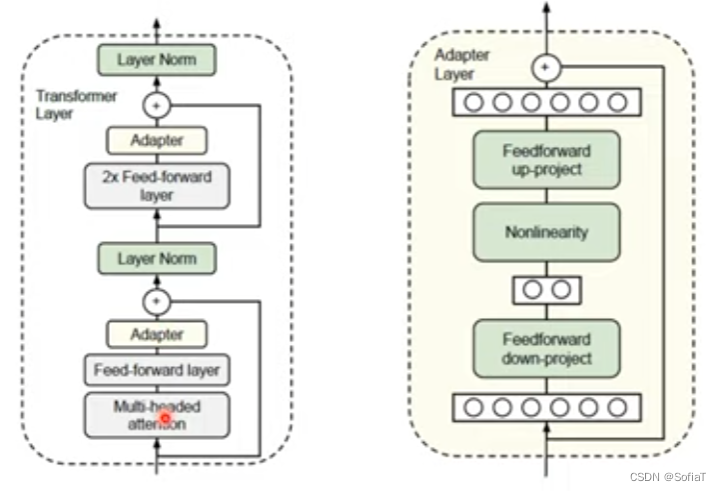
具体效果如图,橙色是base-line,就是fine-tune整个模型能达到的效果,参数量就是整个模型的参数。蓝色是adaptor,曲线越往右就参数越多,fine-tune最后倒数的层数越多,也就越接近全局fine-tune。实际adaptor怎么设计要插在模型哪里,还是有发展空间。
Weighted Features不同的layer也可以综合
之前说的都是最后的top-layer输出embeddings,也许每层抽取的资讯不一样,所以有人也会想把不同层的输出: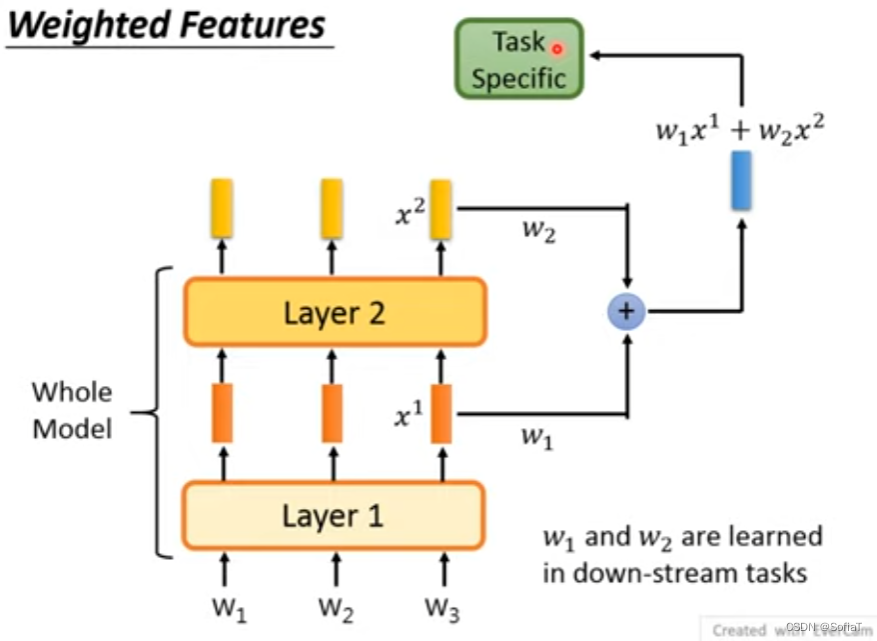
这里的w1/w2和Task Specific都可以被学出来。
为什么Fine-tune?
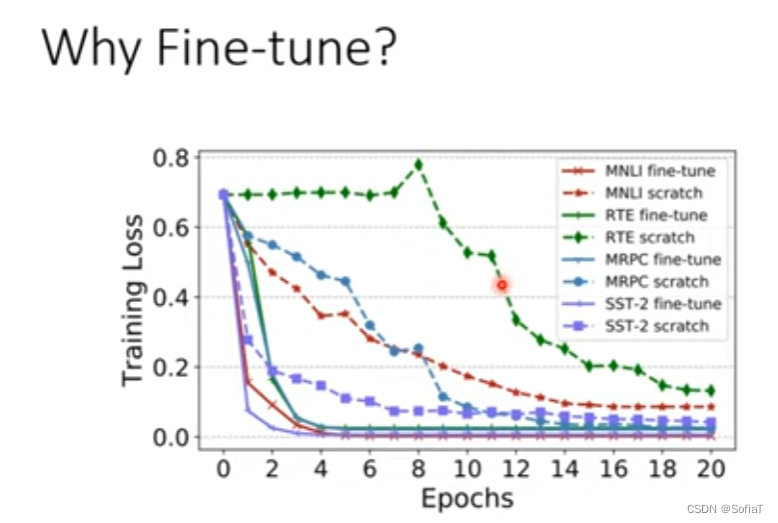 因为确实work,上图是network的size一致时跑epochs的效果 ,实线是有预训练,虚线是直接train from scratch。
因为确实work,上图是network的size一致时跑epochs的效果 ,实线是有预训练,虚线是直接train from scratch。
预训练是怎么做出来的 How to pre-train
这里开始就是下的视频部分,从这部分开始将大模型他们不同的预训练方法。
#还没看#
![[架构之路-174]-《软考-系统分析师》-5-数据库系统-7-数据仓库技术与数据挖掘技术](https://img-blog.csdnimg.cn/06763829bfcd4264be4d1f0adc547eb3.png)