目录
一、redis是什么
二、Redis数据结构
2.1 Redis 的五种基本数据类型
2.1.1String(字符串)
2.1.2字符串列表(lists)
2.1.3字符串集合(sets)
2.1.5哈希(hashes)
2.2 Redis 的三种特殊数据类型
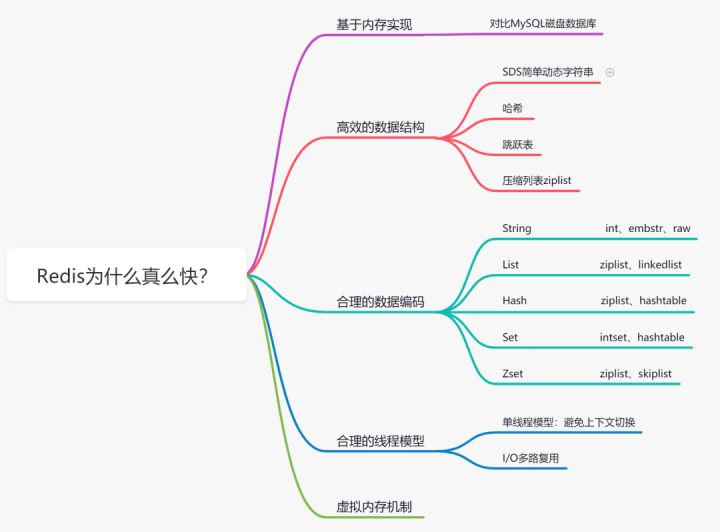
三、Redis为什么这么快
3.1 基于内存存储实现
3.2 高效的数据结构
3.3 合理的数据编码
3.4 合理的线程模型
3.5 虚拟内存机制
一、redis是什么
Redis,英文全称是Remote Dictionary Server(远程字典服务),是一个开源的使用C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
与MySQL数据库不同的是,Redis的数据是存在内存中的。它的读写速度非常快,每秒可以处理超过10万次读写操作。因此redis被广泛应用于缓存,另外,Redis也经常用来做分布式锁。除此之外,Redis支持事务、持久化、LUA 脚本、LRU驱动事件、多种集群方案。
二、Redis数据结构
redis是一种高级的key:value存储系统,其中value支持五种数据类型:
1.字符串(strings)
2.字符串列表(lists)
3.字符串集合(sets)
4.有序字符串集合(sorted sets)
5.哈希(hashes)而关于key,有几个点要提醒大家:
1.key不要太长,尽量不要超过1024字节,这不仅消耗内存,而且会降低查找的效率;
2.key也不要太短,太短的话,key的可读性会降低;
3.在一个项目中,key最好使用统一的命名模式,例如user:10000:passwd。它还有三种特殊的数据结构类型
- Geospatial
- Hyperloglog
- Bitmap
2.1 Redis 的五种基本数据类型
2.1.1String(字符串)有人说,如果只使用redis中的字符串类型,且不使用redis的持久化功能,那么,redis就和memcache非常非常的像了。这说明strings类型是一个很基础的数据类型,也是任何存储系统都必备的数据类型。
我们来看一个最简单的例子:
set mystr "hello world!" //设置字符串类型 get mystr //读取字符串类型字符串类型的用法就是这么简单,因为是二进制安全的,所以你完全可以把一个图片文件的内容作为字符串来存储。
另外,我们还可以通过字符串类型进行数值操作:127.0.0.1:6379> set mynum "2" OK 127.0.0.1:6379> get mynum "2" 127.0.0.1:6379> incr mynum (integer) 3 127.0.0.1:6379> get mynum "3"看,在遇到数值操作时,redis会将字符串类型转换成数值。
由于INCR等指令本身就具有原子操作的特性,所以我们完全可以利用redis的INCR、INCRBY、DECR、DECRBY等指令来实现原子计数的效果,假如,在某种场景下有3个客户端同时读取了mynum的值(值为2),然后对其同时进行了加1的操作,那么,最后mynum的值一定是5。不少网站都利用redis的这个特性来实现业务上的统计计数需求。
2.1.2字符串列表(lists)
redis的另一个重要的数据结构叫做lists,翻译成中文叫做“列表”。
首先要明确一点,redis中的lists在底层实现上并不是数组,而是链表,也就是说对于一个具有上百万个元素的lists来说,在头部和尾部插入一个新元素,其时间复杂度是常数级别的,比如用LPUSH在10个元素的lists头部插入新元素,和在上千万元素的lists头部插入新元素的速度应该是相同的。
虽然lists有这样的优势,但同样有其弊端,那就是,链表型lists的元素定位会比较慢,而数组型lists的元素定位就会快得多。
lists的常用操作包括LPUSH、RPUSH、LRANGE等。我们可以用LPUSH在lists的左侧插入一个新元素,用RPUSH在lists的右侧插入一个新元素,用LRANGE命令从lists中指定一个范围来提取元素。我们来看几个例子:
//新建一个list叫做mylist,并在列表头部插入元素"1" 127.0.0.1:6379> lpush mylist "1" //返回当前mylist中的元素个数 (integer) 1 //在mylist右侧插入元素"2" 127.0.0.1:6379> rpush mylist "2" (integer) 2 //在mylist左侧插入元素"0" 127.0.0.1:6379> lpush mylist "0" (integer) 3 //列出mylist中从编号0到编号1的元素 127.0.0.1:6379> lrange mylist 0 1 1) "0" 2) "1" //列出mylist中从编号0到倒数第一个元素 127.0.0.1:6379> lrange mylist 0 -1 1) "0" 2) "1" 3) "2"lists的应用相当广泛,随便举几个例子:
1.我们可以利用lists来实现一个消息队列,而且可以确保先后顺序,不必像MySQL那样还需要通过ORDER BY来进行排序。
2.利用LRANGE还可以很方便的实现分页的功能。
3.在博客系统中,每片博文的评论也可以存入一个单独的list中。2.1.3字符串集合(sets)
redis的集合,是一种无序的集合,集合中的元素没有先后顺序。
集合相关的操作也很丰富,如添加新元素、删除已有元素、取交集、取并集、取差集等。我们来看例子:
//向集合myset中加入一个新元素"one" 127.0.0.1:6379> sadd myset "one" (integer) 1 127.0.0.1:6379> sadd myset "two" (integer) 1 //列出集合myset中的所有元素 127.0.0.1:6379> smembers myset 1) "one" 2) "two" //判断元素1是否在集合myset中,返回1表示存在 127.0.0.1:6379> sismember myset "one" (integer) 1 //判断元素3是否在集合myset中,返回0表示不存在 127.0.0.1:6379> sismember myset "three" (integer) 0 //新建一个新的集合yourset 127.0.0.1:6379> sadd yourset "1" (integer) 1 127.0.0.1:6379> sadd yourset "2" (integer) 1 127.0.0.1:6379> smembers yourset 1) "1" 2) "2" //对两个集合求并集 127.0.0.1:6379> sunion myset yourset 1) "1" 2) "one" 3) "2" 4) "two"对于集合的使用,也有一些常见的方式,比如,QQ有一个社交功能叫做“好友标签”,大家可以给你的好友贴标签,比如“大美女”、“土豪”、“欧巴”等等,这时就可以使用redis的集合来实现,把每一个用户的标签都存储在一个集合之中。
2.1.4有序字符串集合(sorted sets)redis不但提供了无需集合(sets),还很体贴的提供了有序集合(sorted sets)。有序集合中的每个元素都关联一个序号(score),这便是排序的依据。
很多时候,我们都将redis中的有序集合叫做zsets,这是因为在redis中,有序集合相关的操作指令都是以z开头的,比如zrange、zadd、zrevrange、zrangebyscore等等
老规矩,我们来看几个生动的例子:
//新增一个有序集合myzset,并加入一个元素baidu.com,给它赋予的序号是1: 127.0.0.1:6379> zadd myzset 1 baidu.com (integer) 1 //向myzset中新增一个元素360.com,赋予它的序号是3 127.0.0.1:6379> zadd myzset 3 360.com (integer) 1 //向myzset中新增一个元素google.com,赋予它的序号是2 127.0.0.1:6379> zadd myzset 2 google.com (integer) 1 //列出myzset的所有元素,同时列出其序号,可以看出myzset已经是有序的了。 127.0.0.1:6379> zrange myzset 0 -1 with scores 1) "baidu.com" 2) "1" 3) "google.com" 4) "2" 5) "360.com" 6) "3" //只列出myzset的元素 127.0.0.1:6379> zrange myzset 0 -1 1) "baidu.com" 2) "google.com" 3) "360.com"2.1.5哈希(hashes)
最后要给大家介绍的是hashes,即哈希。哈希是从redis-2.0.0版本之后才有的数据结构。
hashes存的是字符串和字符串值之间的映射,比如一个用户要存储其全名、姓氏、年龄等等,就很适合使用哈希。
我们来看一个例子:
//建立哈希,并赋值 127.0.0.1:6379> HMSET user:001 username antirez password P1pp0 age 34 OK //列出哈希的内容 127.0.0.1:6379> HGETALL user:001 1) "username" 2) "antirez" 3) "password" 4) "P1pp0" 5) "age" 6) "34" //更改哈希中的某一个值 127.0.0.1:6379> HSET user:001 password 12345 (integer) 0 //再次列出哈希的内容 127.0.0.1:6379> HGETALL user:001 1) "username" 2) "antirez" 3) "password" 4) "12345" 5) "age" 6) "34"2.2 Redis 的三种特殊数据类型
Geo:Redis3.2推出的,地理位置定位,用于存储地理位置信息,并对存储的信息进行操作。
HyperLogLog:用来做基数统计算法的数据结构,如统计网站的UV。
Bitmaps :用一个比特位来映射某个元素的状态,在Redis中,它的底层是基于字符串类型实现的,可以把bitmaps成作一个以比特位为单位的数组
三、Redis为什么这么快
3.1 基于内存存储实现
我们都知道内存读写是比在磁盘快很多的,Redis基于内存存储实现的数据库,相对于数据存在磁盘的MySQL数据库,省去磁盘I/O的消耗。3.2 高效的数据结构
我们知道,Mysql索引为了提高效率,选择了B+树的数据结构。其实合理的数据结构,就是可以让你的应用/程序更快。3.3 合理的数据编码
Redis 支持多种数据数据类型,每种基本类型,可能对多种数据结构。什么时候,使用什么样数据结构,使用什么样编码,是redis设计者总结优化的结果。
3.4 合理的线程模型
I/O 多路复用
多路I/O复用技术可以让单个线程高效的处理多个连接请求,而Redis使用用epoll作为I/O多路复用技术的实现。并且,Redis自身的事件处理模型将epoll中的连接、读写、关闭都转换为事件,不在网络I/O上浪费过多的时间。
什么是I/O多路复用?
- I/O :网络 I/O
- 多路 :多个网络连接
- 复用:复用同一个线程。
- IO多路复用其实就是一种同步IO模型,它实现了一个线程可以监视多个文件句柄;一旦某个文件句柄就绪,就能够通知应用程序进行相应的读写操作;而没有文件句柄就绪时,就会阻塞应用程序,交出cpu。
单线程模型
Redis是单线程模型的,而单线程避免了CPU不必要的上下文切换和竞争锁的消耗。也正因为是单线程,如果某个命令执行过长(如hgetall命令),会造成阻塞。Redis是面向快速执行场景的数据库。,所以要慎用如smembers和lrange、hgetall等命令。
Redis 6.0 引入了多线程提速,它的执行命令操作内存的仍然是个单线程。3.5 虚拟内存机制
Redis直接自己构建了VM机制 ,不会像一般的系统会调用系统函数处理,会浪费一定的时间去移动和请求。
虚拟内存机制就是暂时把不经常访问的数据(冷数据)从内存交换到磁盘中,从而腾出宝贵的内存空间用于其它需要访问的数据(热数据)。通过VM功能可以实现冷热数据分离,使热数据仍在内存中、冷数据保存到磁盘。这样就可以避免因为内存不足而造成访问速度下降的问题。