文章目录
- SAPJNet: Sequence-Adaptive Prototype-Joint Network for Small Sample Multi-sequence MRI Diagnosis
- 摘要
- 方法
- Sequence-Adaptive Transformer
- 原型优化策略
- 实验结果
SAPJNet: Sequence-Adaptive Prototype-Joint Network for Small Sample Multi-sequence MRI Diagnosis
摘要
问题提出:
- 多序列磁共振成像(MRI)图像具有互补信息,可以大大提高诊断的可靠性
- 小样本多序列MR图像的自动诊断是一项具有挑战性的任务:不同的表示。序列之间的差异和包含特征之间的弱相关性使得从网络中提取的表示趋于发散,这不利于鲁棒分类。样本量小体现在原型的稀疏分布上,使得网络只学习粗略的划分,这对于类间隔小的医学图像来说是不够的。
方法:
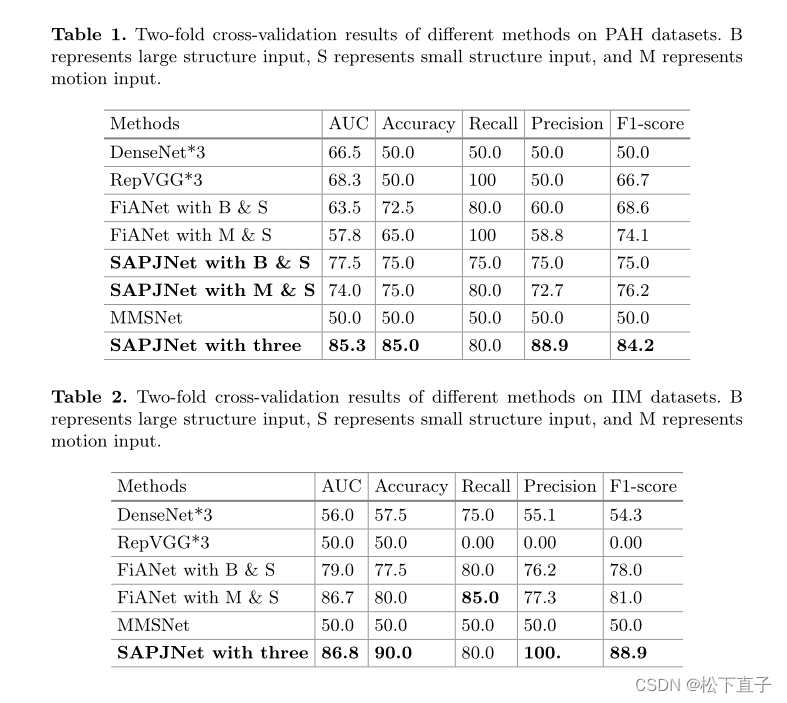
本文首次提出了一种同时适应多序列和小样本条件的网络(SAPJNet),实现了小样本多序列MR图像的高质量自动诊断,对提高临床诊断效率有很大帮助。1) SAPJNet的序列自适应转换器(SAT)通过过滤序列内特征和聚合序列间特征生成联合表征作为疾病原型。2) SAPJNet的原型优化策略(POS)通过逼近类内原型和疏离类间原型来约束原型分布。SAPJNet在肺动脉高压(PAH)的风险评估、特发性炎症性肌病(IIM)的分类和膝关节异常的识别三个任务中取得了最佳的表现,在总体比较方法的准确性上至少提高了10%、10%和6.7%。
方法
多看图就能看懂
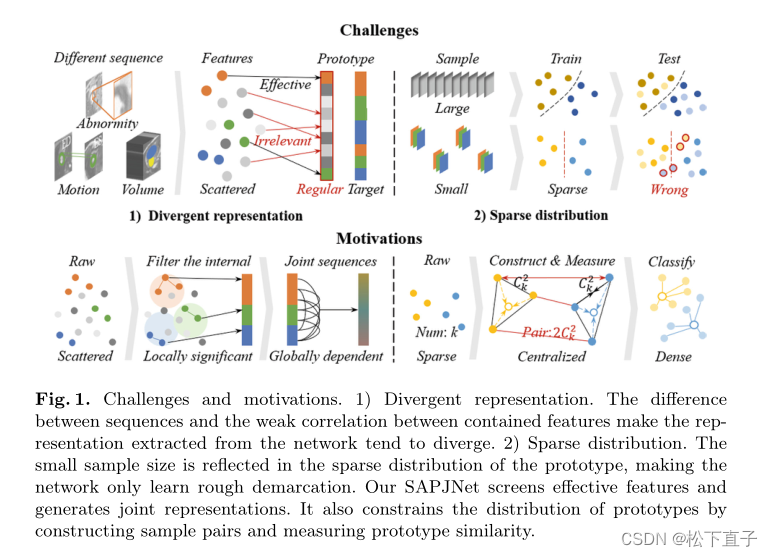
1)发散表征信息:序列之间的差异和包含特征之间的弱相关性使得从网络中提取的表示趋于发散
2)稀疏分布。小样本量体现在原型的稀疏分布上,使得网络只能学习粗略的划分。
SAPJNet筛选有效的特征并生成联合表示。通过构造样本对和测量原型相似度来约束原型的分布。
Sequence-Adaptive Transformer
该算法从多序列MR图像中提取有效的联合表示,以解决大序列差异引起的表示分歧。不同的MRI序列所包含的特征在运动、结构或局部灰色异常方面具有不同的含义。SAT准确地提取这些特征,并生成原型,模仿医生对患者疾病类型或风险水平的总体评估。它从高维稀疏特征中挖掘有效成分并生成低维联合表示的能力得益于注意机制。它为每个输入单元分配可学习的键和值,以计算它们的相关表示。这些表征被聚合并转化为新的语义,在这种情况下,这些语义是疾病的类别或程度
为了探索不同序列特征之间的相关性,在多个差分编码器的连接处设计了几个特殊步骤和基本transformer结构。对于编码器输出的多通道特征,SAT首先将每个通道的二维全局特征平坦化,然后引入参数p来控制输入到自注意层的单元的维数和数量。例如,当p = 4时,单位d的维数为二维特征图大小的4倍,输入长度δ为编码器三个输出的通道数与切片数乘积的14。不同分辨率的数据集不需要特别设计p值,只需要将原型的维度保持在一般水平,例如128
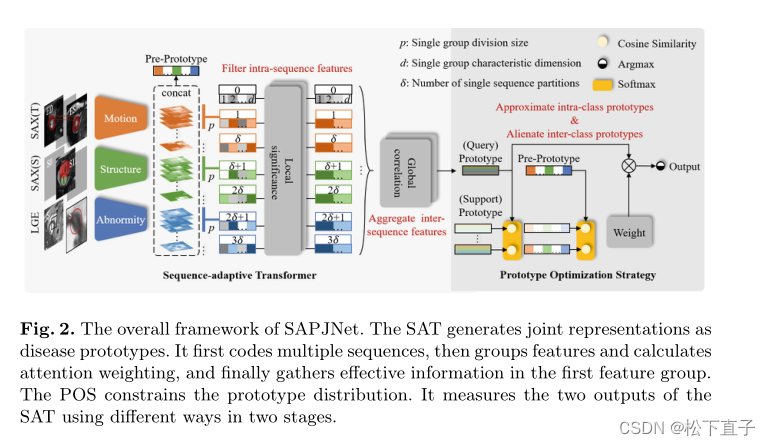
SAPJNet的总体框架。SAT生成联合表征作为疾病原型。首先对多个序列进行编码,然后对特征进行分组并计算注意力权重,最后在第一个特征组中收集有效信息。
POS限制了原型的分布。它在两个阶段使用不同的方法测量SAT的两个输出。
原型优化策略
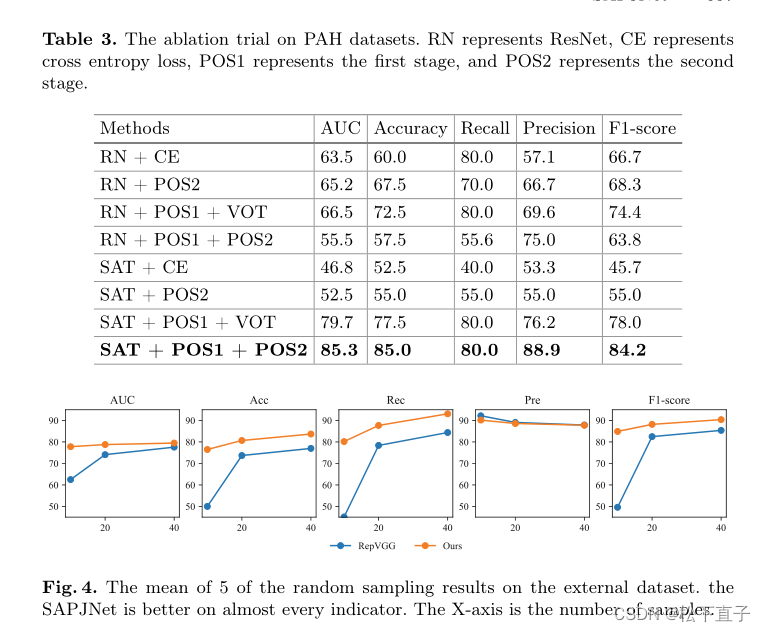
POS对原型分布进行约束,以解决小样本导致的稀疏分布问题。结合了两种不同的测量学习方法,同时获得了两种优势。
一方面,基于成对的方法可以通过构造正样本对和负样本对 来隐式扩展训练批,即充分利用监督信息。
在测量原型相似度的过程中,不同类别之间的距离不断扩大,而同一类别之间的距离不断缩小。
基于代理的方式使得它可以利用网络的最后一层来存储疾病的原型,从而实现网络的端到端训练和测试。
具体来说,POS在两个阶段使用不同的方式测量SAT的两个输出。这两个输出分别是:编码器集输出的由特征拼接的预原型和SAT输出的原型。前者是为了更快地将梯度传播到编码器而保留的。
第一阶段使用基于对的方法计算两个输出的损失。在n-way k-shot训练batch中,首先通过类内组合挖掘正样本匹配。样本被SAT转化为原型后,每个batch的损失计算如下:对于每个f(sbj),其与每个f(qai)的余弦相似度作为其属于不同类别的概率馈入交叉熵函数,其中f(·)表示SAT输出的预原型或真实原型
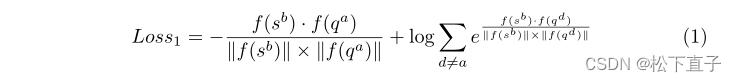
第二阶段采用附加的additive-angular-margin损失进行微调。
它保持测量原型的一致性,同时从样本配对中释放SAPJNet。它以全连接层作为品类原型的存储池,在训练中不断更新参数,不断优化最终的原型表示。描述了additive-angular-margin损失
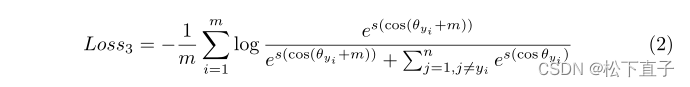
SAPJNet的总损失为Loss1 + βLoss2 + γLoss3。在不同阶段用不同的超参数进行调整。第一阶段α = β = 1, γ = 0,第二阶段α = β = γ = 1。Loss2具有与Loss1相同的形式,但其输入变量是由SAT改进的原型。
实验结果





![[C++]内存管理](https://img-blog.csdnimg.cn/3f9888a368d048d290d30d1df77578bd.png)